







爬取携程用车信息,用的比较传统的模拟浏览器行为方式,主要用payload进行request请求,一步步获取最后的用车列表
1:缓存清理问题:
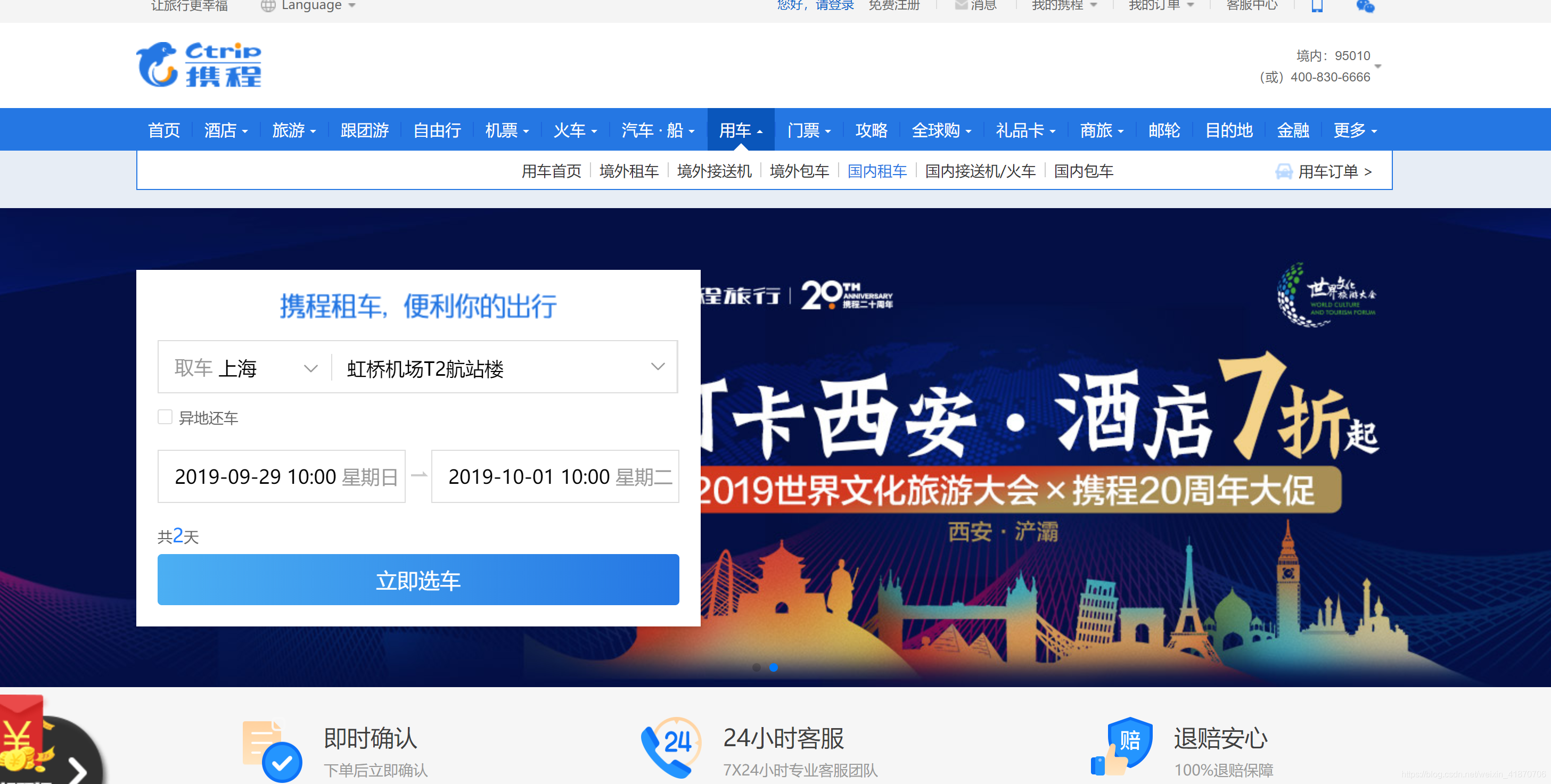
根据模拟浏览器行为方式,我们需要从这个页面来选择我们的【租车点】,【租车时间】,【还车时间】,浏览器才能跳转到下一页面,获取下一步的具体租车列表信息。
这里遇到的问题就是通过F12我要根据network中页面请求顺序,找到可以获得租车点的返回信息的请求页面,这个页面上我们应该获得的是下一个页面用到的一些数据参数----一张对应表(全国的租车点city和每个city相对应的租车点比如上海--虹桥机场T2航站楼,上海--虹桥机场T1航站楼...)
坑:在F12刷新了多次页面,也没有找到我想要的这个请求页面,后来发现,浏览器上第一次访问这个页面,携程会写入cookes,给客户机一个身份,而没有清理cookies,下一次访问他会直接走cookies来找这个列表,当你把本机cookies清理掉之后,再刷新页面之后会发现有个CityList的请求,这里就是我们所需要的城市 --租车点 对应表
2:sign加密问题
成功获取城市name 城市id 对应的下属租车点烈表之后,我们需要获取下图中每个租车点的车信息,
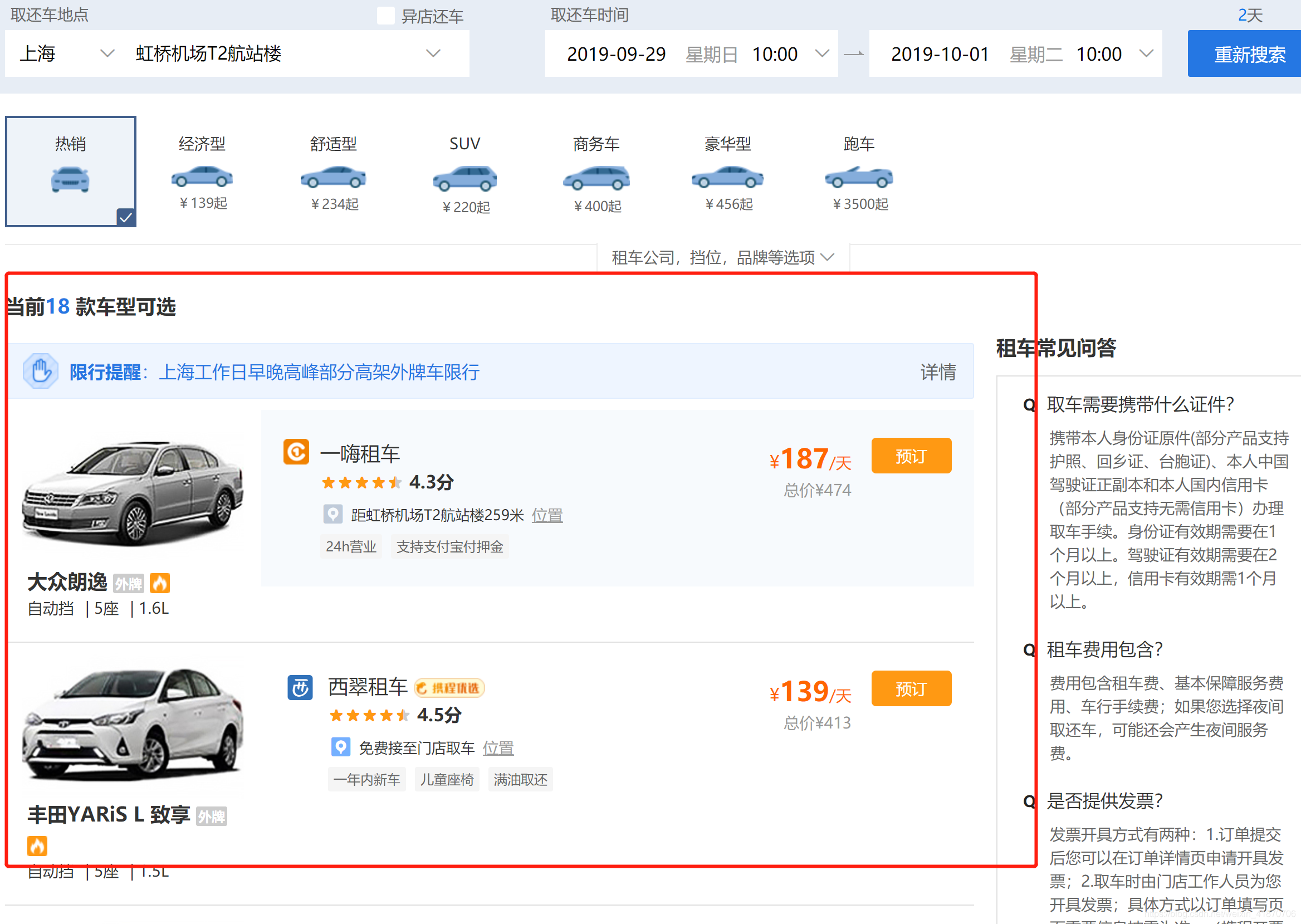 当F12追踪浏览器请求时,返现所有的信息都是在vehiclelist这个请求中获取得,二这个请求是以payload方式,而payload中参数进行分解,发现有个sign参数,随着租车时间不同一直在改变(租车城市和租车站点不变的情况下),这个时候,sign参数通过观察是一个的无规则的32位的数组成,32位就让人怀疑是不是经过了MD5加密生成的码,一般反扒中经常会出现这种加密方式,于是我又仔细的把页面中所有vehiclelist之前的各种相关请求参数都对照了一下(比如:)都没有发现除这个页面请求之前的其他页面有相同数字出现,于是我又从总体搜索 “sign”,最后在很多很多的nodejs里搜到了相关的一些信息,所以怀疑这个sign可能是调用了nodej里的加密算法,于是我将有关系的nodejs全部取出,在在线nodejs解析页面解析后,发现了一个命名为ad23b1.e36951d.js的nodejs的茫茫方法海中发现了类似相关的加密方法,该方法叫做getKey,里面传入了四个参数(取车时间,还车时间,取车城市cid,换车城市cid),这时候就要在python代码中调用这部分js方法代码了,具体怎么做可以搜一下。
当F12追踪浏览器请求时,返现所有的信息都是在vehiclelist这个请求中获取得,二这个请求是以payload方式,而payload中参数进行分解,发现有个sign参数,随着租车时间不同一直在改变(租车城市和租车站点不变的情况下),这个时候,sign参数通过观察是一个的无规则的32位的数组成,32位就让人怀疑是不是经过了MD5加密生成的码,一般反扒中经常会出现这种加密方式,于是我又仔细的把页面中所有vehiclelist之前的各种相关请求参数都对照了一下(比如:)都没有发现除这个页面请求之前的其他页面有相同数字出现,于是我又从总体搜索 “sign”,最后在很多很多的nodejs里搜到了相关的一些信息,所以怀疑这个sign可能是调用了nodej里的加密算法,于是我将有关系的nodejs全部取出,在在线nodejs解析页面解析后,发现了一个命名为ad23b1.e36951d.js的nodejs的茫茫方法海中发现了类似相关的加密方法,该方法叫做getKey,里面传入了四个参数(取车时间,还车时间,取车城市cid,换车城市cid),这时候就要在python代码中调用这部分js方法代码了,具体怎么做可以搜一下。
3:反爬虫问题--构造ip代理池
至此我们通过解析获得的租车列表,拿到我们想要的数据,但是这么大量的频繁的数据爬虫一定会引起携程反爬虫策略识别被封ip,这时候就需要构建一个ip代理资源池,在ip被封掉之后,有源源不断的其他ip补上
4:request请求卡住问题,程序不退出


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









