






一、问题定义及分类
图像匹配 [1–6](Image Matching)旨在将两幅图像中具有相同/相似属性的内容或结构进行像素上的识别与对齐。一般而言,待匹配的图像通常取自相同或相似的场景或目标,或者具有相同形状或语义信息的其他类型图像对,从而具有一定的可匹配性。
从定义出发,图像匹配主要包含匹配目标和匹配准则两个部分,即以什么信息为目标载体和以何种规则或策略进行匹配。
最直接的匹配目标便是整张图像或以截取的图像块(Image Patch),一般被称为基于区域 (Area-Based)的方法,其主要分为两种:i)直接根据图像或图像块灰度信息进行像素上的对齐,该方法主要思想是直接最小化图像信息差异,一般包括交叉相关法(或互相关法),相关系数度量法,互信息法等 [5,7–9];ii)基于图像域变换的图像匹配,其先将图像信息进行域变换,然后在变换域中对图像进行相似性匹配,包括傅里叶变换法, 相位相关法,沃尔什变换法等 [10–12]。基于区域的图像匹配方法对成像条件、图像形变(特别是要求图像对具有极高的重叠度)以及噪声极其敏感,同时具有较高的计算复杂度,从而限制了其应用能力。
为解决上述问题,基于特征(Feature-Based)的图像匹配方法得到了广泛研究 [5,13]。其首先从图像中提取的具有物理意义的显著结构特征,包括特征点、特征线或边缘以及具有显著性的形态区域 [14–18],然后对所提取的特征结构进行匹配并估计变换函数将其他图像内容进行对齐。尽管特征的提取需要额外的算力消耗,但针对整个基于特征的匹配框架而言,由于特征可以看做整张图像的精简表达,减少了许多不必要的计算,同时能够减少噪声、畸变及其他因素对匹配性能的影响,是目前实现图像匹配的主要形式,也是本文研究重点。
对于特征而言,点特征通常表示图像中具有显著特性的关键点(Key Point)或兴趣点(Interest Point) [19],因而最为简单且稳定,同时其他特征的匹配均可转化为基于点特征来进行,如线的端点、中点、或离散采样形式,形态区域中心等 [18,20–22]。因此,特征点匹配在图像匹配中是一个最为基本的问题,而我们所说的特征匹配(Feature Matching)通常意义上指基于特征点的匹配问题,待匹配的点一般由图像像素空间的坐标点表示,而相应的图像匹配则转化为从两幅图像中提取对应的点集并配对的问题。本文主要研究内容便是从特征匹配问题的本质特性出发,结合其他领域技术手段,围绕基于特征点的图像匹配方法展开深入研究,克服图像匹配问题目前面临的诸多挑战。
二、研究背景及意义
近年来,科技水平日益提高,形成了全球自动化的格局,随之而来的人工智能技术蓬勃发展,其主要目的是令机器联合计算机像人类一样感知、理解与行动。视觉感知作为最主要的感知技术之一,在此次人工智能热潮下占据着举足轻重的地位,因而推动着计算机视觉技术迅猛发展。同时,如何理解多个视觉目标之间的区别与联系,并根据特定的需求对感知的信息作相应的处理已然成为整个计算机视觉领域的研究热点之一,而特征匹配作为其中的一个基础而关键的过程,连接着具有相同或相似属性的两个图像目标,是低层视觉通往高层视觉的纽带,是实现信息识别与整合 [23–25] 以及从低维图像恢复高维结构 [26,27] 的有效途径。
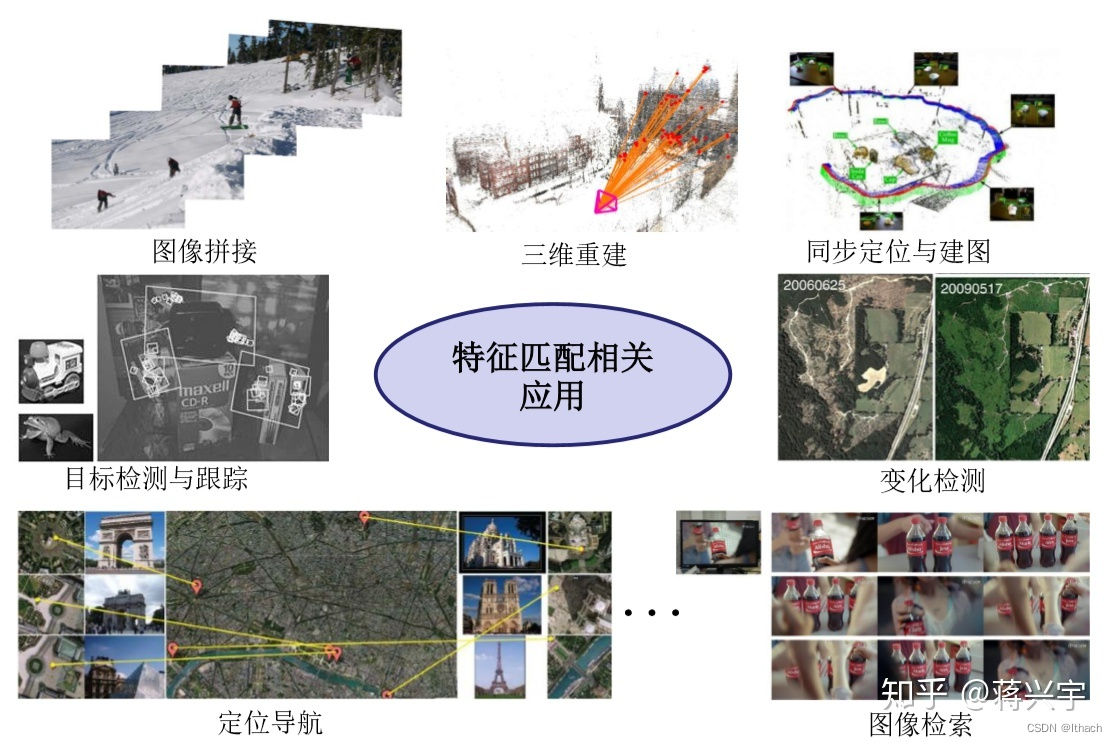
特征匹配的定义和任务目标极为简单且明确,它是一项底层视觉处理技术,直接对图像本身进行特征提取与配对,是许多具体大型视觉任务的首要步骤。据美国自动成像协会(Automated Imaging Association)统计,40% 以上的视觉感知应用依赖于图像匹配的精度与效率,包括计算机视觉、模式识别、遥感、军事安防以及医学诊断等各领域。具体来讲,根据数据获取条件或者成像条件的差异,特征匹配问题可以划分为不同时间、不同视角以及不同传感器,或者进行模板图像的匹配 [3,5],并且每一类型的图像获取形式都有着对应的应用目的:1)基于不同成像时间的特征匹配。主要是对同一场景或目标在不同时间拍摄的图像进行匹配,一般用于场景的变化检测,安防监控与目标跟踪,以及医学诊断治疗中病情跟踪等。2)基于不同视角的特征匹配。其主要目的是匹配从不同视角拍摄的同一目标或场景的序列图像进行匹配,旨在从低维的图像内容恢复高维结构,如恢复相机姿态并建立相机移动轨迹,目标或场景的三维重建,以及遥感全景影像拼接等。3)基于不同传感器的特征匹配。鉴于不同传感器所获取的图像有着各自的优势且包含不同的感知信息,因而对不同的图像信息进行整合并得到更全面的场景或目标表示是十分必要的,而特征匹配便是将包含多源信息的图像进行关键点配对并估计变换函数从而将图像进行逐像素对齐,便于后续的信息融合,因而又称为多源图像特征匹配。这类匹配常用于医学图像分析中多模图像匹配,安防及军事领域中如红外可见光配准,遥感图像处理中不同分辨率且包含不同光谱信息的影像配准与融合等。4)基于模板的特征匹配。这类匹配一般给定图像模板,然后将获取的图像与模板进行比较与匹配,常用于模板识别、差异检测或内容检索,如基于视觉的模式识别(字符识别,车牌识别)、图像检索,医学图像分析中病情诊断,标本分类以及遥感图像中航空或卫星图像在已知的其他地理信息地图中的匹配与定位等。
由此可见,特征匹配作为一项基础而关键的技术在诸多领域有着重要地位,因而对其展开深入研究有着重要实际应用价值。此外,作为许多高层视觉任务的底层输入,基于特征点的图像匹配问题也面临着多方面的挑战,其中包括准确性、鲁棒性(普适性)和高效性。
首先,特征匹配精度在许多基于匹配的精准估计应用上有着极高的要求,匹配误差会保留在后续处理环节中并逐渐累积从而严重制约最终视觉任务的有效实施。例如,根据特征点匹配结果求解相机运动参数从而恢复高维结构(Structure From Motion, SFM)的任务, 错误的匹配将产生相机姿态的错误估计,使得类似于三维重建 [27] 和同 步定位与建图 [28,29](Simultaneous Localization and Mapping,SLAM)等任务的结果 严重偏离于真实情形,同时图像融合、图像拼接和变化检测等 [23,25,30] 任务同样严重依赖于图像配准的结果。精度问题通常来自于两个方面——特征提取精度和特征匹配精度。特征点匹配一般需要对从图像中提取出来的关键点进行定位,即以像素坐标的形式表示,通常该坐标要精确到亚像素级且两个待匹配点集应具有较高的重复率,保 证所检测的特征点是真正意义上可匹配的 [13];**特征匹配精度则表现为所配对的两个特征点在真实空间中应当属于精确的同名位置,或者具有相同的语义特征,同时匹配结果中需要保证尽可能多的正确匹配以及尽可能少的错误匹配。**其次,设计一种鲁棒的特征匹配方法以满足多方面的需求是十分必要的。待匹配图像通常来自不同时间、不同视角和不同传感器,成像条件多样性不可避免地造成了图像的匹配难度,况且图像本身的局部形变或畸变,以及图像之间的复杂变换等因素同样对特征匹配问题造成了严重阻碍。除此之外,如何减少因噪声、畸变、重复图像内容以及遮挡等问题造成的错误匹配也是特征匹配中亟需解决的问题。另一方面,为了满足大规模以及具有实时性要求的视觉任务,特征匹配方法应当满足较少的时间和空间消耗。然而特征点的匹 配问题本质上是一个复杂组合优化难题 [31],为了将 N 个特征点与另外 N 个特征点对齐,尽管这两组点是完全可匹配的,同样也需要 N! 种排列组合,况且离群点和噪声的引入将大大增加问题的求解难度,因而在建模求解过程中,如何减少解的搜索空间,降低问题的计算复杂度也是特征匹配的重要难题。
综上所述,基于特征的图像匹配技术存在多方面的难题,有待进一步深入的研究,以满足众多视觉任务的应用需求,因而开展特征匹配相关的课题具有重要的理论研究与实际应用价值。
三、特征匹配研究现状
在进行特征匹配之前,我们首先需要从两幅图像中提取显著并且具有可区分性和可匹配性的点结构。常见的点结构一般为图像内容中的角点、交叉点、闭合区域中心点等具有一定物理结构的点,而提取点结构的一般思想为构建能够区分其他图像结构的响应函数 [15,32](Response Function)或者从特征线或轮廓中进行稀疏采样 [21]。为此,Morevec [19]于 1977 年首次提出了“兴趣点”的概念,并介绍了一种基于局部像素灰度差异的特征点检测方法。然而该方法存在方向、尺度、仿射和噪声上的敏感性,以及较大的时间需求。为此,大量研究者针对该问题提出了一系列的改进措施,其中著名 的 Harris [14] 角点检测器便是运用二阶矩或自相关矩阵来加速局部极值搜索并且保证方向的不变性,为了进一步减少导数的计算,一种基于局部区域像素灰度比较的快速特征提取方法被广泛应用于具有实时要求的视觉任务中,其中包括 SUSAN 算子 [32], 以及采取不同像素比较方法和比较范围的 FAST [16] 及其改进形式如:FAST-ER [33]、 AGAST[34] 等,同时还包括在实时视觉任务中应用极为广泛的 ORB 特征 [28,35]。基于像素比较的特征提取方法也称为二值特征,通常具有极高的提取效率并具有一定的方向不变性以及所提取的特征点具有较高的重复率,对后续的匹配具有重要意义,然而这类方法受尺度和仿射变换的影响较大。
针对上述问题,带有尺度信息的斑点特征成为特征提取的另一种形式,其最早是由Lindeberg 等人[36] 提出的高斯拉普拉斯(Laplace of Gaussian,LoG)函数响应来实现,并从中提出了尺度空间理论,其利用高斯响应函数的圆对称性和对局部团结构的极值响应特性以及对噪声抑制能力,通过不同高斯标准差实现在尺度空间上的极值搜索,从而提取对尺度、方向和噪声鲁棒的特征点并得到相应的尺度信息。为了避免大量的计算,D.Lowe 等人 [37,38] 介绍了一种高斯差分(Difference-of-Gaussian,DoG) 法来近似 LoG 的计算,并提出了著名的 SIFT 特征描述子。基于相同的思想,Bay 等 人 [39] 在 Hessian 矩阵的基础上结合箱式滤波以及图像积分对梯度进行快速计算,提出了SURF 算子,极大程度地提升了斑点特征的检测速度。此外,许多基于 SIFT 和 SURF 的改进方法也相继被提出,其中包括减少计算量、提升仿射鲁棒性等 [40–43]。为满足精确的匹配要求**,所提取的特征通常需要精确的位置信息并保证两个点集具有较高的可重复性和可匹配性。因此,大多特征提取方法中均会采用非极大值抑制(NMS)来提升局部特征点的显著性和稳定性,并且通过像素空间的插值方法估计特征点在亚像素空间的精确极值位置**,具体的特征提取相关综述请参考 [5,13,44–47]。
一旦两个可匹配的点集提取完成,图像匹配任务便转化为对两个特征点集进行配对。对此,目前已涌现出了许多开创性的工作及其后续的改进方案,主要从特征匹配的本质属性入手,从不同角度对特征匹配进行定义与假设,并结合相关技术手段对问题建模与求解。根据现有文献以及相关研究成果,特征匹配问题主要从直接和间接求解两个思路进行。**直接匹配的思想主要是将特征匹配问题抽离为两个点集对应的问题,直接从中估计正确的点点对应关系,而间接匹配一般先通过特征点的局部描述子的相 似程度建立初步的对应关系,然后根据几何约束剔除误匹配。**此外,由于深度学习 [48] (Deep Learning,DL)技术在深层特征层面强大的学习与表达能力,基于深度卷积网 络的特征匹配技术也得到了广泛关注 [4,49,50],为解决图像匹配问题提供了一个新的方向。本文将对上述解决特征匹配的技术路线中主要方法进行分析总结。
3.1直接匹配策略
i) 基于对应矩阵估计的特征匹配算法。
对应矩阵的估计需要结合变换函数的建模和参数估计而同时进行,一般用于点集配准问题。这类算法的目标通常是通过变换模型与对应矩阵的估计,将目标点集变换并映射到模板点集中,使得变换后两个点集中属于配对的点能够尽可能重合,因此其最小化目标函数一般包含目标点集变换后与模板点集的空间距离和指派矩阵的组合形式构成经验误差项,并且对应矩阵的相关约束条件和变换函数的平滑性、复杂性等将构成额外的惩罚项。为了实现目标函数的优化与求解,常用的方法是两个待求解变量在反复迭代更新中逐渐逼近其最优形式。因此,变换模型的选择也成为了基于对应矩阵估计的特征匹配方法的重点。对于静态场景图像而言,图像对或待匹配的两个点集一般满足多视图几何变换,即极线几何或单应等约束条件,其通常由一个 3×3 的矩阵表示,矩阵中不同元素结构和矩阵的自由度代表 着平移、尺度、旋转、仿射等基础变换,结合点集的齐坐标形式,可以反映点集间的这种静态几何变换的度量与建模。然而图像中一般存在局部形变、成像畸变或者动态目标等非刚性变换,此时静态场景中的全局几何形变模型将无法适用,常用的策略则是 采用插值理论中的几何形变模型,如径向基函数(Radial Basis Function, RBF),其中薄板样条(Thin-PlateSplines,TPS)和高斯径向基函数在非刚性点集配准中得到了广 泛应用 [51,52]。例如,Chui[53] 等人提出了一种基于 TPS 估计的鲁棒点集匹配(Robust PointMatching,RPM)框架,并且为了提升对数据退化的鲁棒性,Myronenko 等人 [54] 基于高斯径向基函数提出了一致性点漂移算法(Coherent Point Drift,CPD)。基于对应矩阵估计的特征匹配算法框架能够在刚性和非刚性匹配中均取得不错效果,但是当点集中存在大量离群点或数据退化严重时,算法性能将大大降低,甚至失效。此外,该模型框架本身属于一个复杂组合优化问题,其求解空间极其复杂,在迭代估计的过程中需要大量的时间消耗。
ii) 基于图模型的特征匹配算法。
图模型的构建为特征匹配问题提供了一个新颖的思路,将待匹配特征点看作图的顶点,点点之间连接成边,便可以通过图论的相关理论对特征点匹配问题建模与求解,因此也称为图匹配(Graph Matching)[55,56]。图匹配方法主要分为精确图匹配和非精确图匹配,精确方法主要将图匹配看作一个子图同构问题,严格要求图结构的相似性,从而导致其求解难度以及解决实际问题的不适用性,而非精准匹配弱化了图结构的相似度量,在实际问题中更加灵活,目前图匹配的研究重点主要围绕非精确匹配进行。另一方面,图匹配的本质目标是从两个点集中搜索具有相似图结构的最大子集,其关键步骤主要有图的构建和图模型优化求解。
图的构建主要在于边的定义以及邻接矩阵(Adjacent Matrix)和关联矩阵(Affinity Matrix)的构建,低阶边的定义通常只包含两点之间的直接距离,而高阶边则由三个或三个以 上的顶点来定义,同时邻接矩阵有全连接形式以及 ϵ− 近邻、K-近邻和三角连接等稀疏形式两种类型,关联矩阵则用以表征图结构之间的亲和性,主要包含顶点亲和(一阶亲和性)和边亲和(二阶亲和性),不同构图形式将影响模型的求解效率和精度。另外基于图理论的特征匹配模型的研究重点一般是优化方法的探索 [57,58],主要将图匹配问题看做一个二次分配的问题 [56,59](Quadratic Assignment Problem,QAP),现有的求解形式通常是将模型转化为一个能量最小化问题,主要分为基于梯度(Gradient Based)的优化方式以及通过拉普拉斯矩阵(Graph Laplacians)在主特征的基础上进行谱方法(Spectral Based)的求解,例如谱匹配(Spectral Matching,SM) [60] 和移动图匹配 [61](Graph Shift,GS)、蒙特卡罗法 [62](Monte Carlo)、随机行走法 [63] (Random Walk)以及基于聚类的匹配方法 [64] 等。总而言之,基于图理论的特征点匹配方法能够从全局结合局部结构的相似性对特征点集进行结构划分并配对,是实现特征匹配的一个具有较强理论研究意义的途径,然而由于其 QAP 和 NPC 属性,因而具有较高的计算复杂度,同时噪声和离群点的影响会直接制约图匹配算法的有效性。因此,研究图匹配算法的快速优化求解以及针对噪声和离群点的鲁棒建模来提高匹配精度与效率是目前图匹配的研究重点。
3.2 间接匹配策略
间接匹配策略一般分为两个阶段,第一个阶段先根据待匹配的特征点构建具有特定属性的描述子(Feature Descriptor),从而为每个特征点赋予各自的特征向量,然后根据描述子的相似程度建立粗略的对应关系。常用的特征描述方法主要分为基于局部图像梯度统计的浮点型描述子和基于像素灰度比较的二值型描述子,前者极具代表性的便是 SIFT 描述子 [37,38],其通过对局部像素进行网格划分并统计 8 个方向上的梯度 同时确定梯度主方向,随后将其排列为一个能够描述该特征点的高维向量。SIFT 能够取得较为满意的匹配效果,并且对光照、方向、尺度以及图像质量具有一定的鲁棒性。 为了进一步提升 SIFT 的实现速度以及准确性,SURF 中引入了 Haar 响应策略,并以高斯函数进行局部加权,统计扇形区域导数方向进行特征描述。Yan 等人 [42] 提出了 一种基于特征降维的改进形式 PCA-SIFT,以及其他改进如:C-SIFT [41]、ASIFT [40]、 DSP-SIFT [65] 等。基于像素比较的二值特征描述方法,主要包含不同的采样策略和采样范围,比如:Michael 等人 [66] 于 2010 年在特征点局部矩形区域内针对不同的采样形式进行了对比测试,提出了一种 BRIEF 二值描述方法;次年,Stefan 等人 [67] 提出了一种基于变尺度同心圆采样形式的特征描述方法 BRISK,并且随后的 Alexandre 等人 [68] 提出了一种基于视网膜采样的二进制特征描述子 FREAk。不同特征提取和不同描述方法的相互组合可以得到不同的初始匹配构建效果,如 ORB 特征在FAST的基础上根据 Harris 响应进行前 N 个可靠特征挑选,随后采取灰度质心法确定其主方向, 并利用 BRIEF 特征描述方法,结合学习的策略确定二进制编码方式,是目前最为快速的建立初始匹配方法之一。总之,**二值型描述子最终通过汉明距离对描述子的相似度进行度量,相对而言具有较高的实现速度,而浮点型描述子则一般采用欧式距离进行相似度度量,具有较高稳定性。**针对特征描述的相关综述及其特征提取描述和匹配性能对比,同样可以参考 [13,44–47]。
此外,对于已经存在的两个具有物理形状的待匹配的点集而言,比如从二维形状中离散而来的特征点集,该点集一般会脱离图像本身,因而基于图像信息的描述方法将不再适用,此时可以通过形状上下文 [21](ShapeContext,SC)来构建描述子,或者三维情况则通过自旋图 [69]、以及二维描述子的三维改进形式 [38,70](MeshDOG/MeshHOG)进行特征描述并建立初始匹配。不管怎样,这种粗略的对应由于仅利用了局部信息,同时噪声、离群点、遮挡和重复内容等原因,造成初始匹配中会存在大量的错误匹配关系,比如现有的基于描述子的特征匹配方法一般错误匹配比率高达 50% 以上 [17,45], 而如果设定更严格的阈值条件,正确比率会有很大提升,但同时也会牺牲大量的正确匹配。因此,在下一步中,则需要根据所建立的初始匹配的空间几何约束将误匹配剔除,同时保留尽可能多的正确匹配。
间接匹配策略将特征匹配问题转化为一个从初始匹配集剔除误匹配的问题,其中 N 表示具有 N 对已建立好初始对应关系的匹配对。一类经典的剔除误匹配同时估计参数模型的方法便是随机采样一致性 [71](RANdom SAmple Consensus,RANSAC),以及后续的改进形式如 MLESAC [72]、PROSAC [73]、SCRAMSAC [74]、USAC [75] 等,统称为基于重采样的方法。这类方法旨在初始匹配中通过反复地采样估计匹配点集间预定义的变换模型,来寻找满足其估计的模型的最大内点集作为正确的匹配对。该方法严重依赖于采样的准确性,显然当初始匹配中存在大量离群点时,所需采样次数显著提升,从而使得该方法的效率大大降低,同时变换模型一般无法预先定义,甚至一些非刚性情况无法建模,从而导致这类方法不再适用。另一类用于解决非刚性变换图像匹配的方法则是基于非参数插值或拟合的方法,其主要基于先验条件插值或回归学习出定义的非参数函数,将一幅图像中的特征点映射到另一幅图像中,然后通过核查初始点匹配集中每个匹配对是否与估计出的对应函数一致来剔除错误匹配。例如通过鲁棒估计对应函数用于离群点剔除的 ICF 算法 [76],以及利用非刚性变换模型在再生核希尔伯特空间 (Reproducing kernel Hilbert spaces, RKHS) 中的泛函表达形式及其稀疏近似形式,结合高斯混合模型 (Gaussian mixed model, GMM) 与正则化理论在这一匹配框架中取得了卓越的成效 [77–86],较为代表性的算法有基于向量场一致性点集匹配算法 VFC[81]、基于流形正则化点集匹配算法 MR-RPM [87]、基于局部线性迁移匹配算法 LLT[88] 等。该类方法在离群点较多或者点集中存在独立的运动结构以及其他具有极为复杂的变换时匹配精度会急剧下降。此外,一些松弛的方法,例如在建立初始匹配后利用图匹配相关的约束条件,通过局部结构一致性以及分段一致性的假设,对正确匹配进行鲁棒估计。比如基于局部保留的特征匹配方法 LPM [89]、 GLPM [90],基于网格划分运动一致性算法 [91](GMS),基于分层运动一致性的特征匹配方法 [92,93] 等。由于建立初始匹配通过描述子的相似度量构建,然后根据几何约束剔除误匹配,相比于直接匹配策略,这类方法能够使特征匹配问题得到高效解决。然而,如何快速建立包含正确对应的初始匹配,对匹配问题定义以及挖掘正误匹配之间的分布差异和特点,设计一种快速精确的误配剔除策略也是许多学者关注的重点。
3.3 深度学习策略
目前,深度学习方法因其对深层特征有着优越的学习和表达能力,以火爆的方式应用于计算机视觉的各个领域,其同样在图像匹配问题上崭露头角并取得了初步成效。深度学习在图像匹配中最合理的应用便是直接从包含相同或相似结构内容的图像对中学习到像素级别的匹配关系,其主要形式有以下几种:
1)以深度学习方法解决传统类似于 SIFT [37,38] 建立初始匹配中的一个或多个环节,又或者直接设计一个端到端的匹配网络,例如学习从图像中检测更精确可靠的特征点集、学习每个特征点的主要方向或主要尺度及其更具有区分性和可匹配能力的特征描述子 [94–96],一些代表方法如 LIFT [17]、NCN [50]、LF-Net [97]、SuperPoint [98] 等;又或者学习描述子之间更可靠的相似性度量准则等 [99,100]。这一系列的策略在某些方面已经证明了其相对于传统方法的优越性 [101,102],然而其中同样存在大量的错误匹配,依旧需要误匹配剔除策略进行后处理。
2)在双目立体匹配(Stereo Matching)中,直接从图像对中学习得到深图 [103,104],这种方法已在公共数据集 KITTI [105] 和 Middlebury [106] 中取得了统治性的结果,然而其一般依赖于两张图像具有较高的重合度并且经过校正与对齐,因而具有一定的局限性。
3)基于深度学习的图像块匹配 [99,107,108](Patch Matching)涌现出了大量的研究成果,其主要通过深度学习方法获取图像块之间的深层特征,并度量特征之间相似性来建立对应关系,这类方法一般用于提取好的特征点的描述子构建、图像检索、宽基线立体匹配 [103](Wide-Baseline Stereo Matching)以及图像配准 [99,109,110] 等方面。
深度学习在匹配中的另外的一种应用便是从两个点集中学习其局部和全局特征并建立可靠的点对应关系。由于三维点云数据的稠密特性是的其具有类似于图像的纹理细节信息,可以方便地通过深度卷积方式进行学习,因而应用较广 [111,112]。然而三维点云中的深度学习策略,并不适用于稀疏的特征点集匹配任务,为了解决这一问题,通过深度学习方法学习点集之间的几何拓扑结构也成为当前研究热点之一。其主要目的是学习两个图结构之间的相似性,或者通过局部邻域结构一致性学习来建立点集之间的配对关系 [49,50],又或者通过点集间的几何变换模型进行约束,即在建立匹配的过程中同时学习变换模型的参数 [113,114],如基于学习的可靠匹配搜索 [113](Learning to Find Good Correspondences,LFGC),其旨在从稀疏初始匹配集结合相机本征矩阵学习一个多层深度感知机,结合参数几何变换模型构建损失函数,实现模型估计同时剔除误匹配,或者基于局部结构一致性的图学习网络来挖掘潜在的正确对应关系 [50,115]。
除此之外,国内学者针对特征匹配问题也进行了较为系统的研究,例如国防科学技术大学赵键 [116] 和复旦大学宋智礼[2] 在他们各自的博士课题中分别针对点模式的匹配问题和图像配准技术及其应用进行了专门研究,华中科技大学马佳义 [3] 的博士课题研究了基于非参数模型的点集匹配模型框架,并提出了一系列的基于正则化理论的非参数建模和快速求解形式,哈尔滨工业大学于伟 [4] 的博士课题则研究了基于深度神经网络特征的图像匹配方法,主要解决深度学习框架下的深层特征表达与语义匹配问题,此外华中科技大学柳成荫 [117] 在其博士课题中,针对不同领域的应用需求,从多模与多视角非刚性图像配准问题展开了专门的研究。
综上所述,特征匹配方法的研究根据问题的定义以及求解策略有着大量的研究成果,然而由于应用场景的复杂性,造成目前的特征匹配方法存在多方面的局限,主要包括处理速度,匹配精度以及针对噪声和非刚性形变的鲁棒性。因此,本文的主旨便是对特征匹配问题进行系统与深入的研究,从不同的角度定义特征匹配问题,并采用有效的技术解决当前匹配算法的应用局限性。
四、特征匹配发展趋势
特征匹配问题由来已久,理论上的突破使得现有的方法具有一定的实际应用能力,然而面对诸多方面的应用需求,以及特征匹配问题本身的复杂特性,其依然是一个具有理论研究意义和实际应用价值的开放性话题,因此需要进一步地深入研究,同时深度学习技术的强大能力也使得特征匹配问题面临着进一步的突破。接下来,综合当前研究现状以及相关难题,特征匹配技术的发展趋势主要涉及以下几个方面:
传统方法的进一步推进
根据图像匹配的概念可知,图像匹配技术可以应用于任何含有对相似或相同结构及内容信息的识别、检测、整合与应用的视觉任务中,尽管现阶段深度学习方法在许多视觉任务中逐渐取代了传统的基于图像匹配的思路,并取得了突出的成果,但图像匹配因其高鲁棒性、可扩展性、可解释性依旧是众多领域的主流方法。前面提到,匹配误差会保留在后续处理环节中并逐渐累积从而严重制约最终视觉任务的有效实施,错误的匹配将产生某些精确估计的错误计算会使得一些视觉任务结果严重偏离于真实情形。因而设计一种高精度和高效率的匹配方法,以满足当前具有实性或大规模的实际应用需求,是特征匹配后续发展的主要趋势。另外,一定程度上提升特征点的提取与描述能力,如提取更精确更具有重复性和可匹配能力的特征,更显著和可区分性的特征描述子,获取具有高内点比率和内点数量的初始匹配对,实现实时性的特征提取与匹配方法,以及研究更高效鲁棒的特征点匹配模型及其求解形式都会为特征匹配技术在实际应用中带来实质性的突破。
深度学习方法的引入
实现图像匹配方法的多样性,脱离传统的匹配方法,基于深度学习方法的图像匹配将会成为今后研究热点之一。通过深度学习方法解决图像匹配中特征检测、主方向或主尺度检测、特征描述、相似性度量与配对、误匹配剔除、变换模型估计等传统匹配步骤中的一个或多个环节,又或者直接设计一个端到端的匹配网络,从而进一步改善传统图像特征提取、特征描述以及特征匹配中存在的缺陷,比如:提取出更具有表现力和可精确匹配的特征结构,或者传统的特征描述方法仅基于直观的图像梯度或灰度信息统计而得到,因而需要学习一种更为深层且更具有区分力的特征描述方法,又或者基于欧氏距离的浮点型描述子和基于汉明距离的二值型描述子相似度度量形式存在一定的局限,从而需要学习得到一种更合理的度量形式得到更准确的匹配结果。
从图像匹配抽象出来的点集匹配和图匹配问题,会进一步启发基于图理论的深度网络的相关研究。基于稀疏点集的深度学习方法目前存在着两个方面的挑战,首先是 如何将几何数据(稀疏点集)建立成图,此图为 image 而非 graph,或者构建能够处理 几何数据的网络结构。原因在于现有卷积神经网络主要依托于 image 而进行,改变图像内容顺序将很大程度改变整张图像的结构信息,对网络输出结果造成极大影响,而几何数据本身具有无序性,即改变几何数据的排列顺序(如端点顺序),不会影响几何问题本身的任何属性。同时更高维的几何数据是几何问题中常见的数据类型,从高维数据到低维建图也存在严峻挑战。其次,现有深度理论在模式识别中具有显著成效。如何去寻找几何数据的或者空间点的近邻关系,判断其相对位置,识别多点之间的边、角等几何信息,是联合深度卷积理论解决传统几何问题的重要挑战。
协同匹配与增量匹配
近年来,多图像协同匹配和增量匹配相关成果初露锋芒 [118–120]。这类匹配在联合多张图像匹配信息,互相监督引导的概念上一定程度地提高了匹配的精度,为了满足这一特性,传统的匹配优化模型需要进一步地扩展,极大程度地增加了求解复杂度。尽管协同匹配与增量匹配在匹配精度和效率上难以取得合理的权衡,然而这一概念在解决多序列图像匹配应用方面依旧具有较大的研究价值。
首先如何对协同匹配问题进行有效建模和高效求解本身是一个极具有理论研究意义的问题,其次,这一理念契合人类视觉对多目标信息的联合挖掘与利用这一特性,同时多图像协同检测、分割、超分等视觉任务目前已取得了不错成效,证明这一理念是可行且有意义的。另外,以多序列图像和增量式为基础的视觉任务,如三维重建、SLAM、机器人导航定位等,目前依旧依赖于传统的两两图像对之间的单一匹配,协同匹配的引入可以简化这些任务中的匹配环节,同时提高匹配精度。同时,多图像的协同匹配保证了充足的数据量以及引入了更丰富的图像间的协同信息,而传统的手工方法难以挖掘其中深层且复杂的匹配信息,基于这一特性,运用深度学习方法解决多图像协同匹配与增量匹配则具有极为广阔的前景。
4.5 描述符匹配和错误对去除
描述符匹配和不匹配去除(也称为间接图像匹配)将匹配任务转换为两个阶段的问题。这种方法通常从通过局部图像描述符的相似度,从测量空间判断距离,得出初步对应关系开始。几种常见的策略,包括固定阈值(FT),最近邻(NN)也称为暴力匹配,相互神经网络(MNN)和神经网络距离比(NNDR),可用于构建假定的匹配集。然后,通过使用额外的局部和/或全局几何约束,从假定的匹配集中去除假匹配。我们将错误对去除方法简单地分为基于重采样的方法、基于非参数模型的方法和放松方法。在接下来的章节中,我们将详细介绍这些方法,并提供全面的分析。
4.5.1 假定匹配集构造
假设我们已经从考虑的两张图像I1和I2中检测并提取了M和N个需要匹配的局部特征。描述符匹配阶段通过计算M × N项的成对距离矩阵,然后通过上述规则选择潜在的真匹配。
FT策略考虑距离低于固定阈值的匹配。但是,这种策略可能比较敏感,可能会导致大量一对多匹配,而不是一对一对应的性质。这种情况导致特征匹配任务性能较差。
神经网络策略可以有效地处理数据敏感性问题,召回更多潜在的真匹配。这种策略已应用于各种描述符匹配方法中,但无法避免一对多的情况。在相互神经网络描述符匹配中,I1中的每个特征在I2中寻找其神经网络(反之亦然),相互神经网络的特征对成为假定匹配集中的候选匹配。这种策略可以获得较高的正确匹配率,但可能会牺牲许多其他的真实对应。NNDR认为第一神经网络和第二神经网络之间的距离差异是显著的。因此,使用带有预定义阈值的距离比可以在不牺牲大量真实匹配的情况下获得鲁棒和有前景的匹配性能。
然而,NNDR依赖于这些描述符的稳定距离分布,即使该方法在类似sift的描述符匹配中被广泛使用并表现良好。事实上,NNDR不再适用于其他类型的描述符,例如二进制或一些基于学习的描述符(Rublee et al 2011;Ono et al 2018)。
这些描述符匹配方法的最佳选择应取决于描述符的属性和特定的应用程序。例如,在高inlier比率的情况下,MNN比其他方法更严格,但可能牺牲许多其他潜在的真匹配。相比之下,NN和NNDR在特征匹配任务中更普遍,性能相对更好。
Mikolajczyk和Schmid(2005)提出了一个关于这些候选匹配选择策略的简单测试。尽管有多种方法可以用于假定特征对应构建,但仅使用局部外观信息和简单的基于相似度的假定匹配选择策略,将不可避免地导致大量不正确的匹配,特别是当图像发生严重的非刚性变形、极端的视点变化、低质量和/或重复的内容时。因此,在第二阶段迫切需要一种鲁棒、准确、高效的失配消除方法,以保留尽可能多的真实匹配,同时通过使用额外的几何约束将失配保持到最小。
4.5.2 基于重采样的方法
重采样技术(可以说)是一种流行的范式,由经典的RANSAC算法代表(Fischler和Bolles 1981)。基本上,假设两幅图像通过某种参数几何关系(如射影变换或极轴几何)耦合。然后,RANSAC算法遵循假设-验证策略:从数据中重复采样最小子集,例如,射影变换的四个对应点和基本变换的七个对应点,作为假设估计模型,并通过一致的inlier的数量验证质量。最后,将与最优模型一致的对应关系识别为inliers。
为了提高RANSAC的性能,提出了多种方法。在MLESAC (Torr和Zisserman 1998, 2000)中,模型质量通过最大似然过程验证,尽管在某些假设下,它可以改善结果,并且对预定义阈值不太敏感。修改验证阶段的思想由于实现简单,在后续的许多研究中不仅得到了应用,而且得到了进一步的推广。由于提高效率的效果很吸引人,采样策略的改进也在不少研究中被考虑。从本质上讲,不同的先验信息被纳入,以增加选择全inlier样本子集的概率。具体来说,s在NAPSAC中,假设iinlier是空间相干的(Nasuto and Craddock 2002),或者在GroupSAC中存在一些分组(Ni et al 2009)。
PROSAC (Chum和Matas 2005)利用先验预测的较低概率,EVSAC (Fragoso等人2013)利用对应的极值理论对可信度进行估计。另一项开创性的工作是局部优化RANSAC (LO-RANSAC) (Chum et al 2003),其关键观察结果是,采用最小子集可以放大潜在噪声,并产生与实际情况相差甚远的假设。在得到迄今为止最好的模型时,通过引入局部优化过程来解决这个问题。在原来的论文中,局部优化是在一个内部RANSAC内部实现最小二乘拟合过程,缩小内离群值阈值。这具有大于最小值的采样,并且仅应用于当前模型的inliers。Lebeda等人(2012)讨论了LO-RANSAC的计算成本问题,并提出了一些实现改进。在Barath和Matas(2018)中,局部优化步骤使用图切割技术进行了扩展。许多改进RANSAC的策略被整合到USAC中(Raguram et al 2012)。
最近,Barath等人(2019b)在他们的MAGSAC中应用了σ-共识,通过在一定范围的噪声尺度上进行边缘化来消除对用户定义阈值的需求。此后,Barath等人观察到附近的点更有可能起源于相同的几何模型(2019a)通过从逐渐增长的邻域中抽取样本,提取局部结构进行全局采样和参数模型估计。在以上两种方法的基础上,他们引入了带有新的评分函数的MAGSAC++ (Barath et al 2020)。该方法避免了对非lieroutlier决策的要求,其中采用迭代重加权最小二乘方法求解m估计的新型边缘化过程,并将Barath等人(2019a)中的渐进增长抽样策略应用于ransac类鲁棒估计。
尽管重采样方法在计算机视觉的广泛应用中具有良好的效果,但仍存在一些根本性的缺陷。例如,理论所需运行时间随着离群率的增加呈指数增长。最小子集采样策略仅适用于参数模型,无法处理经过复杂变换的图像对,如非刚性图像对。这种情况促使研究人员开发脱离重采样范式的新算法。
4.5.3 基于非参数模型的方法
已经提出了一组基于非参数模型的方法。非参数模型不是简单的参数模型,而是在匹配中解决更普遍的先验问题,例如运动相干性,并且可以处理退化的场景。这些方法的区别在于不同的变形函数对变换进行建模,不同的方法对总体异常值进行处理。Pilet等人(2008)提出使用三角2-D网格来建模变形,使用定制的鲁棒估计器来消除异常值的有害影响。鲁棒估计器的思想也在Gay-Bellile等人(2008)的Huber估计器和Ma等人(2015)的L2E估计器中得到利用,尽管他们对变形的建模不同。Li和Hu(2010)提出了一种完全不同的方法,其中支持向量回归技术用于稳健估计对应函数并拒绝错配。
开创性的工作向量场共识(VFC) (Ma等人2013a, 2014)引入了一个新的非刚性匹配框架。变形函数被限制在再现核Hilbert空间内,并结合Tikhonov正则化来加强平滑性约束。估计是在贝叶斯模型中进行的,其中显式地考虑了鲁棒性异常值。
VFC算法及其变体(Ma et al 2015b, 2017a, 2019b)已被证明是有效的。
最近的趋势是开发宽松的匹配方法,其中几何约束变得不那么严格,以适应甚至复杂的情况,例如由宽基线图像对或物体进行独立运动引起的运动不连续。
某些转基因方法(Leordeanu和Hebert 2005;L i u和Y an 2010)可用于此类需求,并使用二次模型,其中包含对应的成对几何关系,以找到潜在正确的。
然而,结果往往是粗糙的。
Lipman等人(2014)考虑了分段仿射变形;然后,他们将特征匹配表述为一个有约束的优化问题,该问题寻求与大多数对应关系一致的变形,并施加有界的失真。Lin等人(2014,2017)提出了在一个特别设计的对应域中,用非线性回归技术估计的似然函数来识别真匹配,其中运动相干性是强制的,同时也允许不连续。这个概念对应于强制一个局部运动相干约束。Ma等人(2018a, 2019d)提出了一种局部保持匹配方法,其中用于匹配的全局失真模型放宽到关注每个对应的局部性,以换取通用性和效率。结果表明,该准则能够快速、准确地过滤错误匹配。Bian等人(2017)中出现了类似的方法,其中引入了基于局部支持匹配的简单准则来拒绝异常值。Jiang等人(2020a)将特征匹配作为一个具有异常值的空间聚类问题,自适应地将假定的匹配聚类为几个运动一致的聚类,以及一个异常值/不匹配聚类。Lee等人(2020)的另一种方法将特征匹配问题描述为马尔可夫随机场,使用局部描述子距离和相对几何相似性来增强鲁棒性和准确性。
4.6 学习匹配
在信息提取和表示或模型回归中,除了检测器或描述子外,基于学习的匹配方法通常被用来代替传统的方法。学习的匹配步骤大致可以分为基于图像的学习和基于点的学习。基于传统方法,前者旨在处理三个典型的任务,即图像配准(Wu et al 2015a),立体匹配(Poursaeed et al 2018)和摄像机定位或变换估计(Poursaeed et al 2018;Erlik Nowruzi等2017;Yin and Shi 2018)。该方法可以直接实现基于任务的学习,而不需要提前检测图像的显著结构(如兴趣点)。相比之下,基于点的学习更倾向于在提取的点集上进行;这种方法通常用于点数据处理,如分类、分割(Qi等人2017a, b)和配准(Simonovsky等人2016;Liao et al 2017)。研究人员还使用这些数据从假定的匹配集进行正确的匹配选择和几何变换模型估计(Moo Yi et al 2018;M a e t a l。2019年;Zhao等2019;Ranftl and Koltun 2018;Poursaeed等人2018)。
4.6.1 从图像中学习
基于图像学习的匹配方法通常使用cnn进行图像级潜在信息提取和相似度测量,以及几何关系估计。
因此,基于补丁的学习(章节3.3:learningbased feature descriptors)经常被用作基于区域的图像配准和立体匹配的扩展。这是因为滑动窗口中的传统相似性度量可以很容易地用一种深度方式代替,即深度描述符。然而,研究人员在空间变换网络(STN) (Jaderberg et al 2015)和光流估计(FlowNet) (Dosovitskiy et al 2015)中使用深度学习取得的成功,引发了一波利用深度学习技术直接估计几何变换或非参数变形场的研究浪潮,甚至实现了端到端的可训练框架。
图像配准。对于基于区域的图像配准,早期通常使用深度学习作为经典配准框架的直接扩展,后期使用强化学习范式迭代估计变换,甚至直接估计变形场或位移场进行配准任务。最直观的方法是使用深度学习网络来估计目标图像对的相似度测量,以驱动迭代优化过程。这样,经典的度量度量,如类相关方法和MI方法等,可以用更优秀的深度度量来代替。例如,Wu等人(2015a)通过使用卷积堆叠自编码器(CAE)实现了可变形图像配准,从观察到的图像补丁数据中发现紧凑和高度鉴别的特征,用于相似度量学习。同样,为了获得更好的相似性度量,Simonovsky等人(2016)使用了由少数对齐的图像对训练而成的深度网络。此外,通过直接使用图像外观对变形模型进行patch-wise预测,设计了一种称为Quicksilver的快速可变形图像配准方法(Y ang et al 2017b),其中深度编码器-解码器网络用于预测大变形微分纯模型。受深度卷积的启发,Revaud等人(2016)引入了一种基于层次相关架构的密集匹配算法。该方法可以处理复杂的非刚性变形和重复的纹理区域。Arar等人(2020)介绍了一种基于具有几何保留约束的图像到图像转换网络的无监督多模态图像配准技术。
与度量学习不同,经过训练的代理用于强化学习范式的图像配准,通常用于估计刚性转换模型或变形场。Liao等人(2017)首次将强化学习用于刚性图像配准,使用人工智能体和贪婪监督方法结合注意驱动分层策略来实现“策略学习”过程,并找到产生图像对齐的最佳运动动作序列。Krebs等人(2017)还训练了一种人工智能体,它通过从大量合成变形图像对中训练来探索统计变形模型的参数空间,以应对可变形配准问题和难以提取可靠的真实数据的可变形场。Miao等人(2018)提出了一种用于医学图像配准的多智能体强化学习范式,其中自动注意机制用于接受多个图像区域。然而,强化学习通常用于预测回归过程的迭代更新,在迭代过程中仍然消耗大量的计算量。
为了减少运行时间并避免显式地定义不同度量,一次完成端到端注册受到越来越多的关注。Sokooti等人(2017)首次设计了深度回归网络,直接从一对输入图像中学习位移向量场。de Vos等人(2017)的另一种方法类似地训练了一个深度网络来回归和输出空间变换的参数,然后可以生成位移场来将运动图像扭曲到目标图像。然而,为了实现无监督优化,仍然需要图像对之间的相似度度量。最近,de Vos等人引入了深度学习框架(2019)用于无监督仿射和变形图像配准。经过训练的网络可以用来在一个镜头中记录一对看不见的图像。将深度网络作为回归器的类似方法可以直接从图像对中学习参数转换模型,例如Fundamental (Poursaeed et al 2018), Homography (DeTone et al 2016)和non-刚性变形(Rocco et al 2017)。
本文还提出了多种基于图像级学习的端到端配准方法。Chen et al (2019) 提出端到端可训练的深度网络,直接预测图像对齐的密集位移场。Wang和Zhang(2020)引入了DeepFLASH用于有效的可变形医学图像配准,该配准在低维带宽限制空间中实现,从而极大地降低了计算和内存请求。
为了同时增强变换模型的拓扑保持性和平滑性,Mok和Chung(2020)提出了一种高效的无监督对称图像配准方法,该方法最大限度地提高了异胚映射空间内图像之间的相似性,并同时估计正变换和逆变换。在Truong等人(2020)中,作者介绍了一种用于几何匹配、光流估计和语义对应的通用网络,通过研究全局和局部相关层的联合使用,可以实现高精度和鲁棒性。更多细节请参见注册特定评论(Ferrante and Paragios 2017;Haskins et al 2020)。
立体匹配。在过去的几年里,类似于配准,许多关于立体匹配的研究都集中在通过使用深度卷积技术和改进视差图来准确计算匹配成本(Zbontar and LeCun 2015;Luo等2016;Zbontar and LeCun 2016;《颤抖与狼2017》)。除了深度描述符,如DeepCompare (Zagoruyko and Komodakis 2015)和MatchNet (Han et al 2015)等,Zbontar和LeCun(2015)引入了深度Siamese网络来计算匹配成本,该网络被训练来预测图像补丁之间的相似性。他们进一步提出了一系列用于成对匹配二元分类的cnn (Zbontar and LeCun 2016),并将其应用于视差估计。类似于将匹配成本的计算转换为多标签分类问题,Luo等(2016)提出了一种高效的用于快速立体匹配的Siamese网络。此外,Shaked和Wolf(2017)通过使用提出的常数高速公路网络计算匹配成本和使用反射置信度学习进行视差估计来提高性能。
这一匹配任务的端到端深度方式近年来受到越来越多的关注。例如,Mayer等人(2016)在他们的分布式网络中训练了一个端到端CNN以获得一个精细的视差图,Pang等人(2017)用一个称为级联剩余学习(CRL)的两阶段CNN进行了扩展。最近,Chang和Chen(2018)引入了空间金字塔池化模块和三维卷积策略。该方法可以利用全局上下文信息来增强立体匹配。受到CycleGAN (Zhu et al 2017)的启发,为了处理域间隙,Liu等人(2020)提出了一种端到端训练框架,将所有合成立体图像转换为现实图像,同时保持极限。该方法通过域平移和立体匹配的联合优化来实现。Y ang et al(2020)的另一种方法是学习视差的小波系数,而不是视差本身,可以从低频子模块中学习全局上下文信息,从其他子模块中学习细节。此外,引导策略(Zhang et al 2019a;Poggi等人2019)用于立体匹配。
基于深度卷积技术的立体匹配在公共基准测试中一直占据主导地位。然而,cnn在立体匹配领域的应用受到输入图像对的限制,这些输入图像对一般是由双目摄像机捕获的,具有较窄的基线和极极整流。尽管如此,这些基于学习的立体匹配中的网络结构、基本思想以及一些技巧或策略可能对一般的图像匹配任务有很强的参考价值。
4.6.2 学习点
从点中学习在特征提取、表示和相似度测量方面不像在图像中那样流行。基于点的学习,尤其是特征匹配,是近年来才引入的。这是因为在点数据上使用cnn比在原始图像上更困难,这是由于稀疏点的无序结构和分散性质。此外,使用深度卷积技术在多点之间操作和提取空间关系,如相邻元素、相对位置、长度和角度信息是具有挑战性的。然而,使用深度学习技术来解决基于分数的任务已经得到越来越多的考虑。
这些技术可以大致分为参数拟合(Brachmann et al 2017;Ranftl和Koltun 2018)和点分类和/或分割(Qi等人2017a, b;M o o Y i e t a l。2018;M a e t a l。2019年;Zhao等,2019)。前者受到经典RANSAC算法的启发,旨在通过cnn的数据驱动优化策略来估计转换模型,如基本矩阵(Ranftl和Koltun 2018)和极面几何(Brachmann和Rother 2019)。然而,后者倾向于训练分类器从假定的匹配集中识别真实匹配。为了提高性能,通常将参数拟合和点分类联合训练。
对于可训练的基本矩阵估计,Brachmann等人(2017)提出了一种可微分的RANSAC,称为DSAC,它基于端到端的强化学习。他们用概率选择代替确定性假设选择,以减少预期损失和优化可学习参数。随后,Ranftl和Koltun(2018)提出了一种可训练的方法从噪声中估计基本矩阵,它被抛为一系列加权的均匀最小二乘问题,其中鲁棒权是用深度网络估计的。与DSAC类似,Brachmann和Rother(2019)和Kluger等人(2020)也引入了使用学习技术来改进重新采样策略。它使用inlier计数本身作为训练目标,便于NG-RANSAC的自监督学习,并可以结合不可微任务损失函数和不可微最小求解器。而CONSAC (Kluger et al 2020)被引入作为多参数模型拟合的鲁棒估计量。利用神经网络对假设选择的条件抽样概率进行连续更新。
基于学习的错配去除方法是近年来发展起来的。Moo Yi等人(2018)首次尝试引入一种基于学习的技术,称为学习寻找良好对应(LFGC),其目的是在严格的几何变换约束下,将一组稀疏的假定匹配与图像本征一起训练出一个网络,并将测试对应标记为内线或异常值,同时输出摄像机运动。然而,LFGC可能会牺牲许多真实的对应来估计运动参数,无法处理一般的匹配问题,如变形和非刚性图像匹配。为此,Ma等人(2019a)提出了一个学习两类分类器的通用框架,用于不匹配去除,称为LMR,它使用少量图像和手工制作的几何表示进行训练。他们的方法在线性时间复杂度的情况下显示出良好的匹配性能。最近,Zhang等人(2019b)专注于基于顺序感知网络(OAN)的几何恢复,并在姿态估计方面取得了有前景的性能。Sarlin等人(2020)提出了SuperGlue,通过联合查找对应点和拒绝不可匹配点来匹配两组局部特征。该方法由图神经网络(Scarselli et al 2009)实现,用于可微传输问题的优化。类似图神经网络管道已被一个新兴的研究分支,即深度图匹配所采用(Wang et al 2019;Y u e t a l。2020年;Fey等人2020),其中提出并采用了交叉图卷积(Wang等人2019)、通道无关嵌入(Y u等人2020a)和基于样条的卷积(Fey等人2020)用于监督图对应学习。
尽管将cnn应用于点数据是困难的,但最新的技术在矩阵估计和深度回归器和分类器的点数据分类方面显示出了巨大的潜力,特别是对于具有挑战性的数据或场景。此外,自然语言处理中的多层感知方法和图卷积技术可以为匹配任务中处理这些分散的、非结构化的点数据提供很好的参考。
4.7 3D匹配
与二维匹配方法类似,三维匹配方法通常包括关键点检测和局部特征描述两个步骤,然后通过计算描述子之间的相似度来建立稀疏对应集。尽管大多数方法都使用局部特征描述符,这些描述符被设计为对噪声和变形具有鲁棒性,以在3-D实例之间建立对应关系,但各种经典和最近的工作都属于另一类。我们建议读者参考最近的调查(Biasotti et al 2016;V an Kaick et al 2011)在形状匹配领域的研究,因为对文献的详细回顾超出了本文的范围。
嵌入方法旨在利用一些自然假设(例如,近似等距)将复杂匹配问题参数化,使其具有较少的可处理自由度。Elad和Kimmel(2003)提出了一种传统的方法,通过将形状嵌入中间欧几里得空间来匹配形状。该方法将测地线距离近似为欧几里得距离,将原来的非刚性配准问题简化为中间空间的刚性配准问题。值得注意的是,另一项工作开发了同样使用嵌入空间的保形映射方法(Lipman和Funkhouser 2009;Kim等人2011;Zeng et al 2010)。
一种更直接的方法是通过最小化结构失真,在形状上的点(子集)之间找到逐点匹配。这个公式是由Bronstein等人(2006)提出的,他引入了一种高度非凸和不可微的目标和广义多维尺度优化技术。一些研究人员也试图减轻过高的计算复杂度问题(Sahillioglu和Y emez 2011;T e v s T a l。2011),同时考虑二次分配公式(Rodola et al 2012, 2013;Chen and Koltun 2015;Wang等人2011)的图匹配。
基于功能映射框架的方法家族首先由Ovsjanikov等人(2012)开发。这些方法不是在欧几里得空间中的点对点匹配,而是使用两个流形之间的函数映射来表示对应关系,可以用线性算子来表征。利用拉普拉斯-贝尔特拉米算子的特征基,可以将函数映射编码成紧凑形式。地图上的大多数自然约束,如地标对应性和算子可交换性,在这个公式中变成线性,导致一个有效的解决方案。这种方法在许多后续工作中被采用和扩展(Aflalo et al . 2016;Kovnatsky et al 2015;Pokrass等人2013;Rodolà等2017;Litany等人2017)。
三维配准案例中的点集学习也是一个研究热点。Y ew等人(2020)提出了用于刚性点云配准的RPM-Net,其中它通过学习融合特征来降低初始化的敏感性并提高收敛性能。Gojcic等人(2020)通过直接学习以全局一致的方式注册场景的所有视图,引入了一种端到端多视图点云配准框架。Pais等人(2020)介绍了一种用于3D点配准的学习架构,即3DRegNet。该方法可以从一组假定的匹配中识别出真实的点对应关系,并回归运动参数以将扫描图像对齐到一个共同的参考系中。Choy等人(2020)利用高维卷积网络检测高维空间中的线性子空间,然后将其应用于刚性运动和图像对应估计下的三维配准。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









