






1.为什么要设计线程池
- 创建线程和销毁线程的花销是很大的,这些时间有可能比处理业务的时间还要长。这样频繁的创建线程和销毁线程,再加上业务工作线程,消耗系统资源的时间,可能导致系统资源不足
2.自定义线程池
- 自定义的线程池由三个部分组成:
- 线程池
- 阻塞队列
- 任务生产者
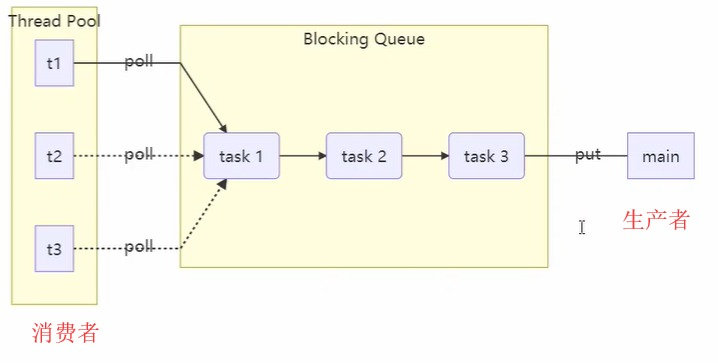
3.代码
- 结合视频学习:视频链接
- 下面是源码
package HighConcurrency.ThreadPool;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.HashSet;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class ThreadPool {
public static void main(String[] args) throws InterruptedException {
//设置线程池数量为2
TestPool testPool = new TestPool(2, 1000, TimeUnit.MILLISECONDS,10);
//开启五个任务
for(int i = 0 ; i < 5 ; i++){
int j = i;
testPool.excute(()->{
System.out.println(j);
});
}
}
}
//BlockingQueue是任务队列
class BlockingQueue<T>{
//1.任务队列(使用双向链表)
private Deque<T> queue = new ArrayDeque<>();
/**
* 线程池都要去从队列中获取任务,但是只能有一个获取成功,所以需要加锁
* 队列头和队列尾都需要加锁
*/
//2.锁
private ReentrantLock lock = new ReentrantLock();
/**
* 条件变量:
* 1.当任务队列中没有任务时,线程需要在waitSet中等待
* 2.当任务队列满了时,生成者需要一个条件变量进入等待状态
*/
//3.生产者条件变量
private Condition fullWaitSet = lock.newCondition();
//4.消费者条件变量
private Condition emptyWaitSet = lock.newCondition();
//5.容量
private int capcity;
public BlockingQueue(int capcity){
this.capcity = capcity;
}
/**
* 以上是五个属性
* 下面是几个方法
*/
//I.阻塞获取(指线程从阻塞队列中拉取任务)
public T take(){
//获取时需要加锁
lock.lock();
try{
//判断队列是否为空
while(queue.isEmpty()){
try{
//如果队列为空,那么就进入等待状态
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//如果队列不为空,那么将队列中的第一个任务出队,并返回该任务
T t = queue.removeFirst();
//这里是为了唤醒fullWaitSet.await()
//因为现在拉取了一个任务,队列不为满
fullWaitSet.signal();
return t;
}finally {
//释放锁
lock.unlock();
}
}
//II.阻塞添加(指生产者往阻塞队列中添加任务)
public void put(T element) throws InterruptedException {
//任务入队也需要加锁
lock.lock();
try{
//判断队列是否为满
while(queue.size() == capcity){
try{
//如果队列已满,则进入等待状态
fullWaitSet.await();
}catch (InterruptedException e){
e.printStackTrace();
}
}
//如果队列不满,那么将任务添加到队列中
queue.addLast(element);
//这里是为了唤醒emptyWaitSet.await()
//因为现在任务队列中有任务了,线程池可以由等待状态进入唤醒状态,从任务队列中拉取任务
emptyWaitSet.signal();
}finally {
//释放锁
lock.unlock();
}
}
//III.获取大小(获取阻塞队列的大小)
public int size(){
lock.lock();
try{
return queue.size();
}finally {
lock.unlock();
}
}
//IIII.带超时的阻塞获取
//因为前面的await方法会一直等待
//这里涉及一个带超时的方法
//参数:timeout是时间参数,unit可以进行时间的转换
public T poll(long timeout, TimeUnit unit){
//这里将超时时间timeout统一转换为纳秒
long nanos = unit.toNanos(timeout);
//获取时需要加锁
lock.lock();
try{
//判断队列是否为空
while(queue.isEmpty()){
try{
//如果nanos纳秒时间过去了,还没等到那么就返回null
//说明队列中没有任务可执行
if(nanos <= 0)
return null;
//如果队列为空
//这里不需要一直等
//这里返回的是剩余时间,重新复制给nonos,实现对nanos的更新
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//如果队列不为空,那么将队列中的第一个任务出队,并返回该任务
T t = queue.removeFirst();
//这里是为了唤醒fullWaitSet.await()
//因为现在拉取了一个任务,队列不为满
fullWaitSet.signal();
return t;
}finally {
//释放锁
lock.unlock();
}
}
}
//实现线程池
class TestPool{
//任务队列taskQueue
private BlockingQueue<Runnable> taskQueue;
//线程集合
//这里泛型类型不使用Thread,使用包装的Worker类型
private HashSet<Worker> workers = new HashSet<>();
//核心线程数
private int coreSize;
//获取任务的超时时间
private long timeout;
private TimeUnit timeUnit;
//这里包装成Worker内部类
class Worker extends Thread{
private Runnable task;
//构造方法
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
//执行任务
//1.当task不为空时,执行任务
//2.当task执行完毕,从任务队列获取任务
//(task = taskQueue.take()) != null)的目的是当任务执行完毕,从任务队列中获取
while(task != null || (task = taskQueue.poll(timeout,timeUnit)) != null){
try{
task.run();
}catch (Exception e){
e.printStackTrace();
}finally {
task = null;
}
}
//将当前worker对象从workers中移除
synchronized (workers){
workers.remove(this);
}
}
}
//构造方法
public TestPool(int coreSize, long timeout, TimeUnit timeUnit,int queueCapcity) {
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.taskQueue = new BlockingQueue<>(queueCapcity);
}
//执行任务
public void excute(Runnable task) throws InterruptedException {
//workers属于共享资源,需要加锁
synchronized (workers){
//当任务数没有超过coreSize时,直接交给Worker执行
//当超过coreSize时,加入任务队列暂存起来
if(workers.size() < coreSize){
Worker worker = new Worker(task);
//将新创建的线程加入线程集合中
workers.add(worker);
//线程执行任务
worker.start();
}else{
//如果任务数超过核心线程数
//进入任务队列
taskQueue.put(task);
}
}
}
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









