







前言
我们经常会听到分支预测失败或者虚函数调用会影响计算性能,那么为什么它们会影响性能呢?带着这个疑问,我最近也看了一些博客和论文,这里结合之前看的一些点,整体做一个总结,和大家一起学习。
本文从 CPU 计算流程、虚函数、流水线执行 && 分支预测这些方面进行介绍,最后总体回答上面的问题,若理解有误,欢迎一起交流。
CPU 计算流程简介
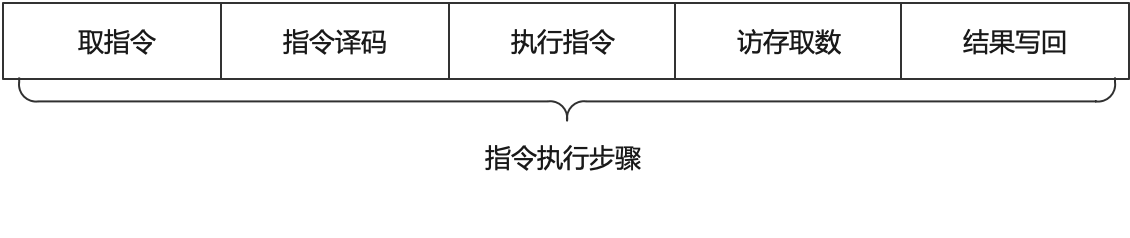
一个应用程序底层最终执行,都是要转换为机器指令进行运行。而 CPU 的核心就是从内存中获取指令并执行计算,CPU 指令计算流程一般分为五步:
- 取指令(Instruction Fetch) – 将内存中的指令读取到 CPU 中寄存器的过程,程序寄存器用于存储下一条指令所在的地址
- 指令译码(Instruction Decode)-- 指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
- 执行指令(Execute)-- 此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能。为此,CPU 的不同部分被连接起来,以执行所需的操作
- 访存取数 – 根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数。根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算。
- 结果写回 – 执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到 CPU 的内部寄存器中,以便被后续的指令快速地存取;在有些情况下,结果数据也可被写入相对较慢、但较廉价且容量较大的主存。
整体示意图如下:
为了弥补 CPU 计算和内存访问时间相差过大问题,在 CPU 和内存之间,一般还添加有 L1,L2,L3 缓存。CPU 计算只从寄存器中获取指令或者数据执行,寄存器和 L1 Cache 进行数据交互,如果 L1 Cache 中没有命中,那么去 L2 Cache 中进行获取,同理如果 L2 中没有缓存,那么就去 L3 缓存中获取,最后如果缓存中都没有,那么就去主存中获取,一般这种情况也会使用 prefetch 技术,来提前将相邻的数据加载到 cache,提升 cache 命中率。所以数据流向的顺序:主存 <-> L3 <-> L2 <-> L1 <-> 寄存器中。
下面是 CPU 存储模型示意图:

为了给大家一个更好的时间感官,下面以 CPU 周为单位的访问时间描述:

函数&&流水线执行&&分支预测介绍 什么是虚函数?
虚函数核心理念就是通过基类访问派生类定义的函数。使用一个基类类型的指针或者引用,来指向子类对象,进而调用由子类复写的个性化的虚函数,这是 C++ 实现多态性的一个最经典的场景。
在 C++ 中,在基类的成员函数声明前加上关键字 virtual 即可让该函数成为 虚函数,派生类中对此函数的不同实现都会继承这一修饰符,允许后续派生类覆盖,达到迟绑定的效果。即便是基类中的成员函数调用虚函数,也会调用到派生类中的版本。
纯虚函数是一种特殊的虚函数,在许多情况下,在基类中不能对虚函数给出有意义的实现,而把它声明为纯虚函数,它的实现留给该基类的派生类去做。这就是纯虚函数的作用。
在 Java语言 中, 所有的方法默认都是"虚函数"。因为 Object 类是所有类的父类,如果 Java 中不希望某个函数具有虚函数特性,可以加上final 关键字变成非虚函数。所有的非静态方法与非final方法本质上都是动态绑定的虚函数,动态绑定是 Java 的默认行为。
以 Java 代码为例,举个列子:
Animal animal = new Monkey();
animal.drink();
上述 Animal 动物的父类,Monkey 为子类。
CPU 流水线执行和分支预测
什么是 CPU 流水线执行?
之前这块一直没有理解,看了下面这个汽车装配的例子才理解。
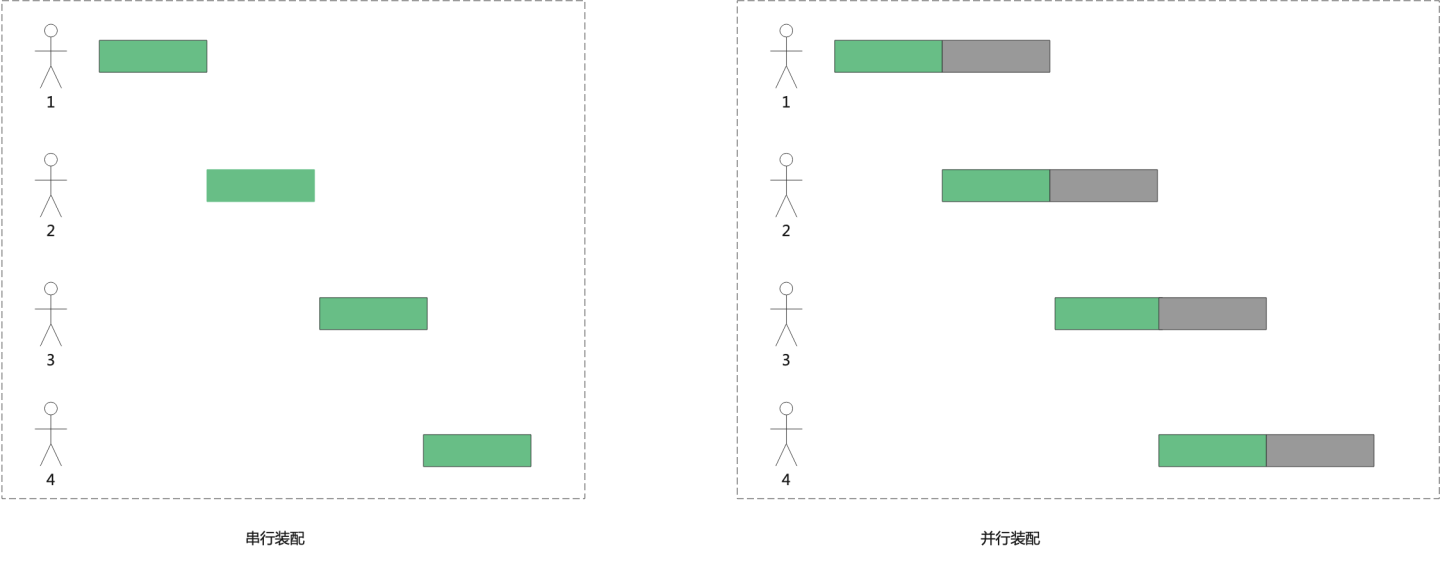
这里先以汽车装配为例来解释流水线的工作方式,假设装配一辆汽车分为四个步骤:
- 第一步冲压:制作车身外壳和底盘等部件。
- 第二步焊接:将冲压成形后的各部件焊接成车身。
- 第三步涂装:将车身等主要部件清洗、化学处理、打磨、喷漆和烘干。
- 第四步总装:将各部件(包括发动机和向外采购的零部件)组装成车。
一台汽车装配需要冲压、焊接、涂装和总装四个工人。最简单的方法是一辆汽车依次经过上述四个步骤之后,下一辆汽车才开始新的装配,即同一时刻只有一辆汽车在装配。
在上述情况,某个时段中一辆汽车完成装配后,其它三个工人都处于闲置状态,显然这对资源极大浪费,于是一种新的工作方式产生,即在第一辆汽车经过冲压进入焊接工序的时候,立刻开始进行第二辆汽车的冲压,而不是等到第一辆汽车经过全部四个工序后才开始,这样在后续生产中就能够保证四个工人一直处于运行状态,不会造成人员的闲置。这样的生产方式就好似流水川流不息,因此被称为流水线。具体如下图所示:
现代 CPU 几乎都是使用 CPU 流水线来执行指令,CPU 流水线技术是一种将指令分解为多步,并让不同指令的各步操作重叠,从而实现几条指令并行处理,以加速程序运行过程的技术。指令的每步有各自独立的电路来处理,每完成一步,就进到下一步,而前一步则处理后续指令。
下面是一个 CPU 指令执行示意图:
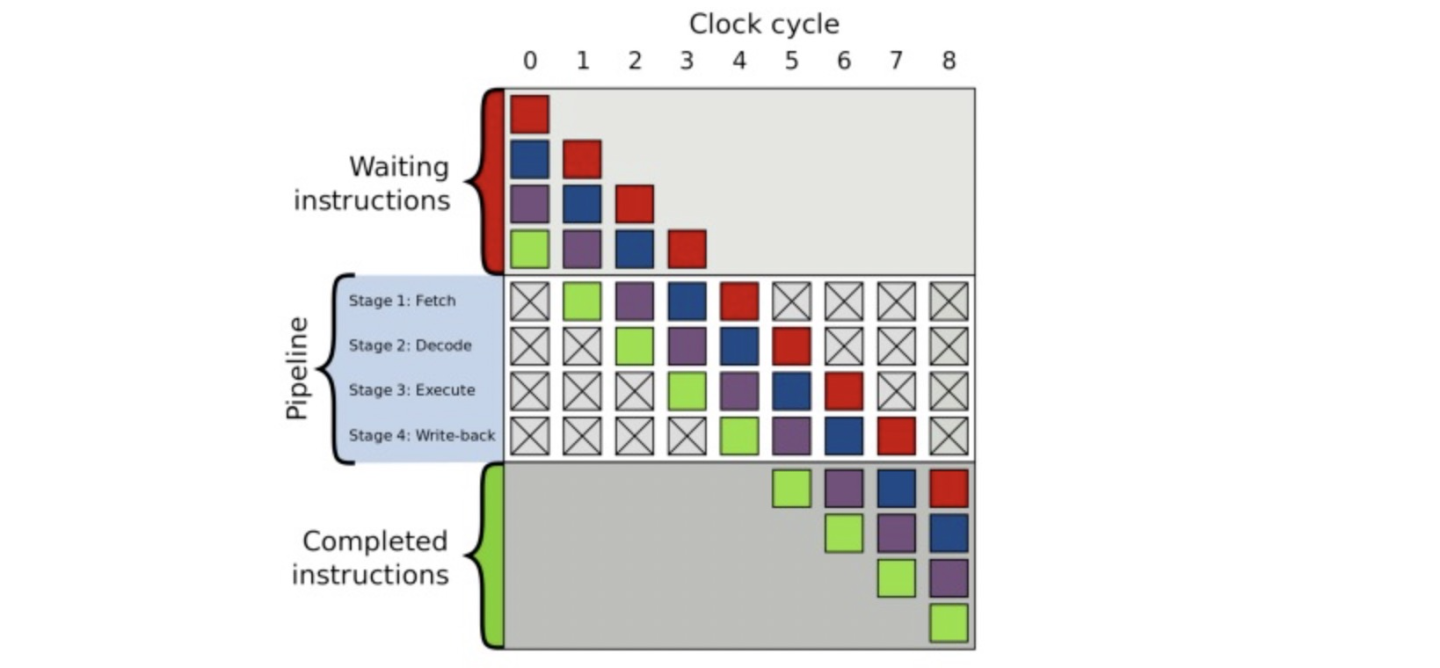
所以 CPU 分支预测器会根据分支预测器,提前预测下一条需要执行的指令,在 cmp 指令进入译码阶段时,就可以将下一条将要执行的指令送进取指令阶段,如果预测成功,极大的提升了 CPU 的使用率。
为什么虚函数调用和分支预测失败会降低 CPU 计算性能?
虚函数调用与普通函数的调用的区别在于:
- 普通函数是一次直接调用,直接调用的跳转地址在编译时是确定的。
- 虚函数调用是一次间接调用,需要在运行时才能从虚表获取地址再跳转。所以,虚函数首先会多一次寻址的时间开销;
- 虚函数是无法在编译期做内联优化的,由于虚函数跳转地址不确定,所以此处会有多个分支可能,这个时候需要分支预测器进行预测,如果分支预测失败,则会导致流水线冲刷,重新进行取指、译码等操作,对程序性能有很大的影响。
对于分支预测失败,将会导致后面流水线被冲刷,进而需要重新获取指令、译码,对性能造成严重的影响。
由前面可知,Pipeline 执行主要涉及 Fetch, Decode, Execute, Write-back 几个stages, 分支预测失败会浪费 Write-back之前的流水线级数。现代CPU流水线级数非常长,分支预测失败可能会损失20个左右的时钟周期,因此对于复杂的流水线,好的分支预测器非常重要。
虚函数调用虽然会多一次寻址,在总体影响性能的瓶颈点不在这,而是在于虚函数调用会有分支预测失败,而分支预测失败,会导致 CPU 流水线冲刷,这才是虚函数调用影响性能的主要原因。















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









