






作者:沈磊(LakeShen),公众号:雷克分析
背景
Apache Calcite 作为一款开源的动态数据管理框架,由于其模块化、可扩展、以及不和任何计算引擎绑定的特性,目前在开源项目和商业化产品中已得到广泛的应用。不仅Apache Flink、Apache Druid、Apache Hive 等明星开源项目在使用 Calcite,腾讯天穹 Super SQL、阿里 MaxCompute、Dremio 等商业化产品的 SQL Planner 也都基于 Calcite 实现。Apache Calcite 俨然成为了 SQL Planner 层的黄金标准、事实趋势。
随着近些年大数据基础设施的不断发展成熟,SQL 已经无可争议地成为大数据计算引擎的主流语言,但与此同时,大量新兴计算引擎、数据库项目的出现,也产生了大量 SQL 方言,运维一个企业级大数据平台需要处理 SQL 的场景越来越多。学习和了解 Apache Calcite,既能帮助我们快速理解 SQL Planner 的原理机制,又能有助于我们利用 Calcite 快速解决以处理 SQL 为中心的各类日常问题(如实现一个SQL Parser、SQL Gateway、SQL Planner 等)。
我们计划从技术实战、原理讲解、源码分析等角度推出系列文章,来介绍如何利用 Apache Calcite 解决一些常见的具体问题,希望能对数据平台工具研发的同学有一些帮助。本文是系列文章的第一篇,将首先介绍 Apache Calcite 的架构设计,同时以一条 SQL 在 Calcite 中的处理流程为主线,对 SQL 解析、元数据验证、执行计划生成及优化、SQL 方言转换等模块的关键原理进行阐述,让读者对 Apache Calcite 有一个初步印象。关于各模块更深入的原理讲解和源码实战,会在后面的系列文章中分篇进行展开。
目标和收益
本文主要讲解 Apache Calcite 的架构设计以及 Calcite 内部 SQL 优化方式,阅读本文,能够从以下几点帮助到你:
- 整体了解 Apache Calcite ,包括架构设计和核心模块。
- 从一条 SQL 处理流程的视角出发,通过对 Calcite SQL 解析、校验、关系代数转换、RBO 和 CBO、物化视图改写和方言转换整体流程的讲解,带你了解一条 SQL 的 Calcite 之旅。
- 了解 Calcite 物化视图改写的两种方式及各自优缺点。
- 了解 Calcite 中优化器设计的关键细节,以及如何实现对 SQL 方言的改写。
希望阅读完本篇文章后,你能够对 Calcite 整体使用流程有一个初步的认识,下面我们进入正文。
一、Apache Calcite 架构概述
1.1 Apache Calcite 诞生背景
Apache Calcite 自 2013 年 11 月首次在 Github 上进行代码仓库初始化,距今已有 9 年时间。Apache Calcite 前身其实是 optiq。optiq 最开始则是在 Hive 项目中进行使用,其主要目的是为 Hive 提供基于成本模型的优化器。 2014 年 5 月 optiq 独立出来,成为 Apache 社区的孵化项目,同年 9 月正式更名为 Apache Calcite。Calcite 的作者是 Julian Hyde,他早期还写过 Mondrian OLAP Engine 和 olap4j API,目前他不仅是 Calcite 的 VP,同时也是 Apache Arrow、Apache Drill、Apache Druid、Apache Kylin 等开源项目的 PMC。
Apache Calcite 设计的核心目标:“One planner fits all”,它期望在异构引擎、异构存储之上,提供统一的数据管理能力,同时还提供基于关系代数的优化器,它的内部各个模块都是可扩展的,也正是因为这种设计理念,Apache Calcite 才会被众多其他开源项目所使用。
1.2 Apache Calcite 架构设计
Apache Calcite 整体是按模块化进行设计,各个模块支持可扩展,比如 SQL 语法文件、元数据、Transformation Rule(逻辑转换规则)和 Implementation Rule(物理转换规则)、CBO 元数据获取的 Metadata Handler、自定义RelNode 和 SqlNode类型等等,同时 Calcite 底层也支持不同引擎的 SQL 方言转换。对于 SQL Planner 的优化框架,整体上 Calcite 已经搭建完成,我们可以直接自定义扩展所需要的差异化特性。下面是 Calcite 各模块的架构设计示意图:
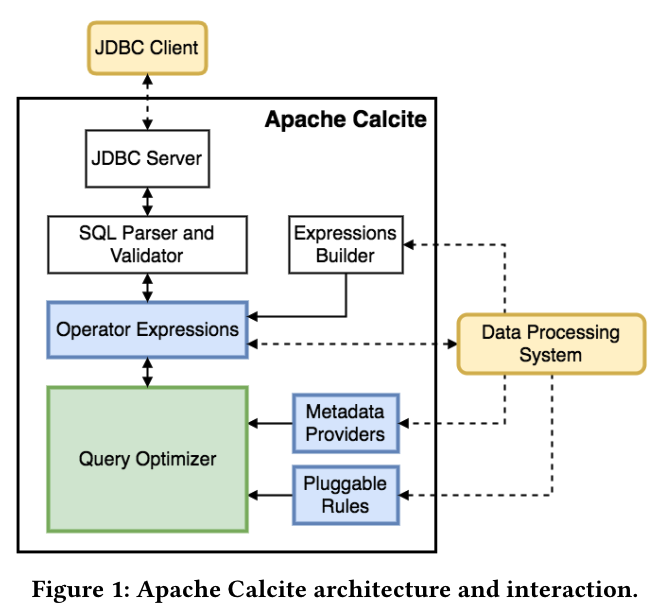
上图中的所有模块都可自定义实现,接下来让我们对各模块一一进行说明:
- JDBC Client 和 JDBC Server,主要负责一个 SQL 的请求响应和结果返回,可以基于 Calcite 子项目 Avatica 框架来进行实现。
- SQL Parser 和 Validator,Parser 主要负责对一个 SQL 进行解析,生成 AST 树。Validator 主要是验证 SQL 的元数据合法性。
- Operator Expressions,则是将一棵 AST Tree 转换为 RelNode关系代数的计划树,这样优化器才能识别和优化。
- Query Optimizer是Calcite 优化器模块,有 RBO 和 CBO 优化器,即对 Query 的关系代数计划树做优化。
- Metadata Providers,是CBO 优化器计算 Cost 时所需元数据的提供者,包括:Selectivity(选择率)、RowCount、DistinctRowCount 等等。
- Pluggable Rules,Calcite 优化规则模块,Calcite 主要有:Transformation Rule(逻辑优化规则)和 ConverterRule(Implementation Rule),用户可以自定义可扩展。
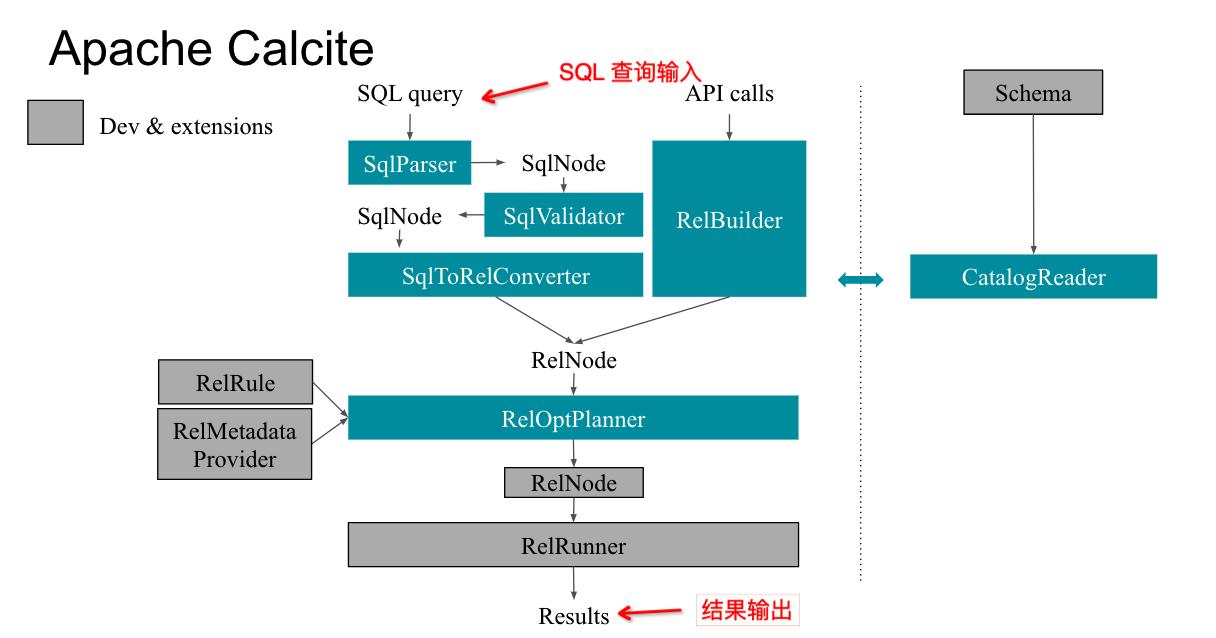
以上我们是从 Calcite 模块组成视角来进行理解的,那么下面从 Calcite 底层核心源代码类调用流转逻辑来看。一个 SQL 的处理逻辑,会使用 SqlParser 将 SQL 解析为 SqlNode,使用SqlValidator 来进行 SQL 校验,使用SqlToRelConverter来将 SqlNode 转换为RelNode关系代数,使用 RelOptPlanner(具体有HepPlanner 和 VolcanoPlanner )来进行计划优化,同时可以通过扩展RelOptRule 、BuiltInMetadata 的实现,来自定义 SQL 优化器的逻辑。CalCite 这种可扩展的设计逻辑,极大的方便开发同学去自定义 SQL 引擎 Planner 逻辑,同时避免大家重复造轮子。
下图是 Calcite 底层核心代码调用流转示意图:
二、SQL 查询优化器概述
2.1 SQL 查询优化器的用途
SQL 作为一种声明式的查询语言,能够让很多技术以及非技术人员快速入门和掌握,用户能够使用 SQL 快速完成业务层的查询语义逻辑的编写。但单纯的 SQL 语言,是无法直接让底层的计算引擎识别和运行的。当 SQL 查询请求发送到底层数据库时,需要将 SQL 查询语句转换为底层数据库的计算引擎能够识别的模型约定定义(比如执行计划描述),最终让底层计算引擎按照预定的计算逻辑执行并返回结果。
对于 SQL 优化器的核心用途——将用户输入的 SQL 查询语句转换为计算引擎能够识别和计算的执行计划,由于最终转换的可以运行计划有很多种情形,所以优化器需要从中选取一个最优的执行计划,下发到计算引擎执行。这里所谓的“最优”既可以结合我们的先验经验来判定,同时也可以从一个执行计划使用到的物理资源进行考量,比如使用的 CPU、内存、磁盘 IO、网络 IO、CPU LRU Cache 等等。SQL 优化器的核心逻辑:就是对关系代数计划做等价转换,在不改变计划语义的情况下,尽可能最大限度对关系代数计划进行优化。
2.2 SQL 查询优化器的优化方式
常见的 SQL 优化方式有两种:RBO 优化(基于先验经验的启发式规则优化)和 CBO 优化(基于计算成本的优化)。RBO 主要是使用一些预定义的先验且有收益的优化规则集合,来对 SQL 进行优化,常见的有:常量折叠、谓词下推、列裁剪、关联子查询消除等优化规则。下图以谓词下推优化举例:
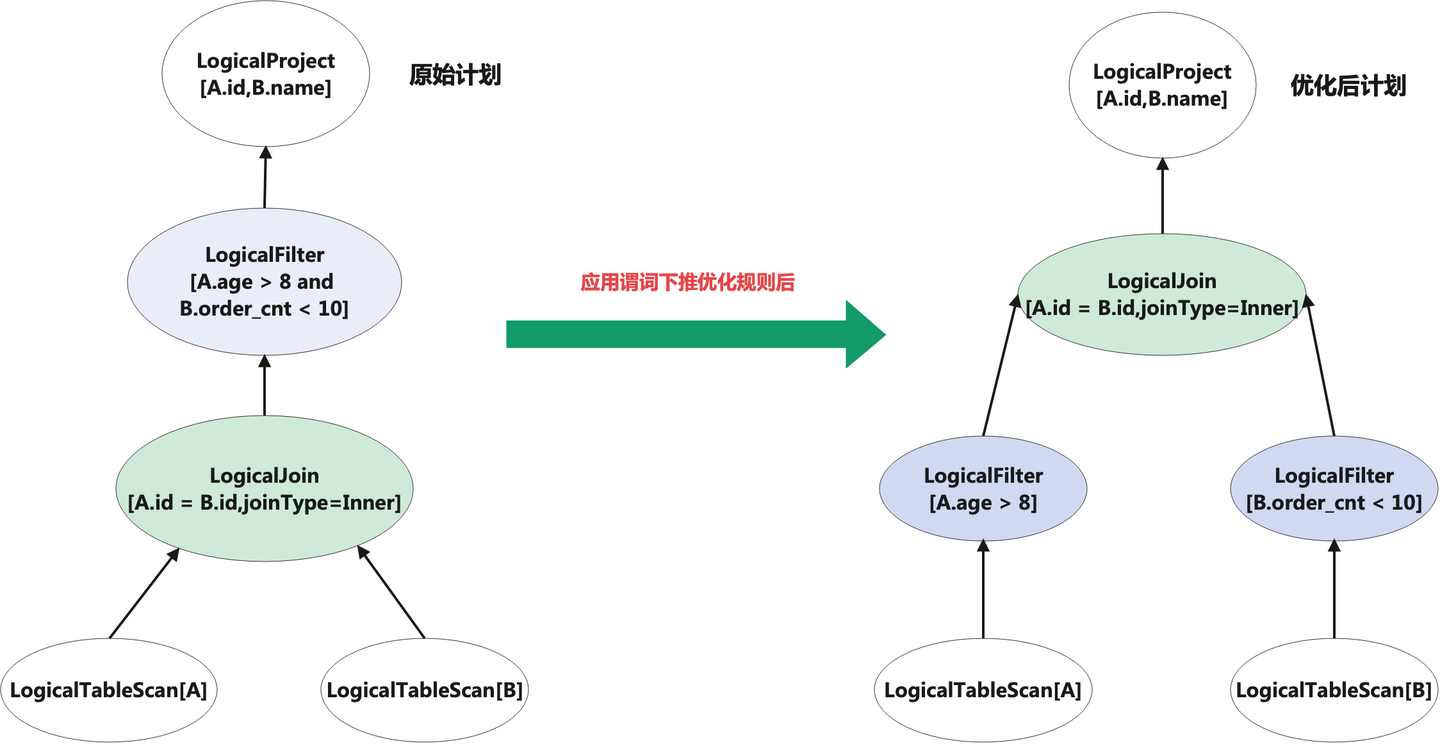
上图左边是原始 SQL 计划,可以看到,通过 Filter 谓词下推规则优化后,Filter 节点已经下推到了 Join 节点之下,这样能够提前对 Scan 节点的数据进行过滤,最终减少进入到 Join 算子的数据量,减少 Join 节点的计算成本。
当然,根据先验经验主义的优化方式也存在缺陷,比如在部分场景中,由于没有考虑到 SQL 在真实环境下的实际运行情况,其执行效率可能并不是最优的,所以就有了基于 Cost 的优化方式(CBO)。CBO 优化,则是在期望的物理特质下,通过对不同物理计划运行所需要的成本进行估算,使用动态规划,来选择一个计算成本最优的物理计划。一般 Cost 包括:CPU、内存、磁盘 IO、网络 IO 等等。
当然,随着技术的演进,现在在 RBO 优化阶段,其实也可以基于 Cost 来评估某些优化规则是否应该使用。这里以 Group By(聚合) 下推举例:
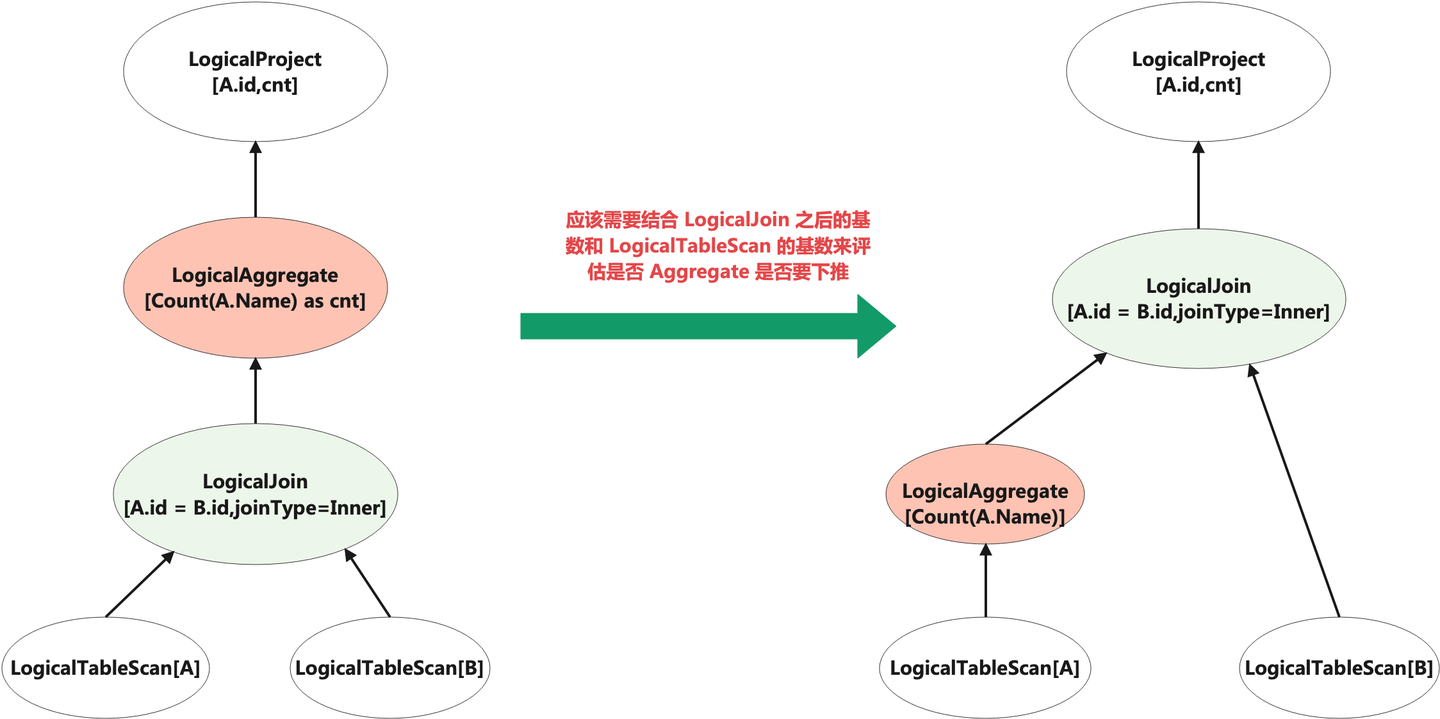
在上图中,如果 LogicalJoin 之后的基数(输出的行数)如果比 LogicalTableScan[A] 后的基数要小的话,Aggregate 不下推,其实会比下推更加节约资源。但完全进入 CBO 阶段,如果计划搜索空间过大的话,CBO 找出最优计划的耗时可能又很久。所以在使用 RBO 优化规则时,某些规则可以比较计划转换前后的 Cost ,来决定是否应用该规则。目前业界像 Oracle 和 MemSQL(SingStoreDB)在它们的优化器都已经按照这种方式进行实现。
2.3 SQL 查询优化器的框架类型
目前业界的 SQL 优化器框架类型有:Volcano、Cascades、Columbia、Orca 等优化器框架,比较主流的优化器框架为 Cascades,像微软的 SQL Server、阿里 ADB、PingCAP 的 TIDB、CockroachDB、StarRocks 这些商业化产品,其 SQL 优化器都是基于 Cascades 优化器框架的。
Columbia、Orca 这两款优化器框架都是在 Cascades 优化器基础上,做了部分改良和优化。以 Columbia 优化器框架举例,其在 Cascades 优化器基础上,对于搜索计划空间剪枝做得更好,不仅能够基于 Group 空间计划剪枝,同时也能够做全局计划剪枝,这样在一个可以接收并近似最优计划的前提下,通过剪枝来减少 Plan 空间搜索的时间,提升查询性能。Orca 则是能够作为独立的优化器在数据库系统之外运行,这样的好处在于优化器不需要和数据库系统紧密耦合在一起,但需要提供一种能够和数据库系统之间的交互通信机制来处理查询。
Cascades 优化器相对于 Volcano 优化器最大的区别在于:Volcano 优化器会先尽可能枚举所有的执行计划空间,然后再从中找出最优的执行计划。而 Cascades 优化器能够在搜索过程中,对空间搜索计划进行剪枝,使得搜索的执行计划空间不会像 Vocano 那么大,但也可以获得一个相对较好的执行计划,这样通过减少空间计划的搜索时间,来降低 SQL Planning 的耗时,从而提升查询性能。
2.4 一条 SQL 在 Apache Calcite 的优化旅程
在一个典型的 SQL 查询服务中,从用户输入一条 SQL 语句开始,到最终结果返回到 Client,一般会经过:Client 端 SQL 查询请求、服务端接收到 SQL 请求和内部作业构建、SQL 解析、SQL 校验、SQL 优化,继而形成物理计划。如果底层有自己的计算引擎,还可以将物理计划转换为执行计划,下发到计算节点并执行;如果底层计算引擎是其他引擎的话,可以将物理计划翻译成对应引擎的 SQL 方言,然后提交到对应引擎执行。
为了方便读者更具象地理解Aapche Calcite的每个模块的运作细节,本文选择了从第二种方式出发,以实现一个SQL优化改写器为例,来展开介绍一条SQL在 Apache Calcite是如何完成解析、优化与改写的。
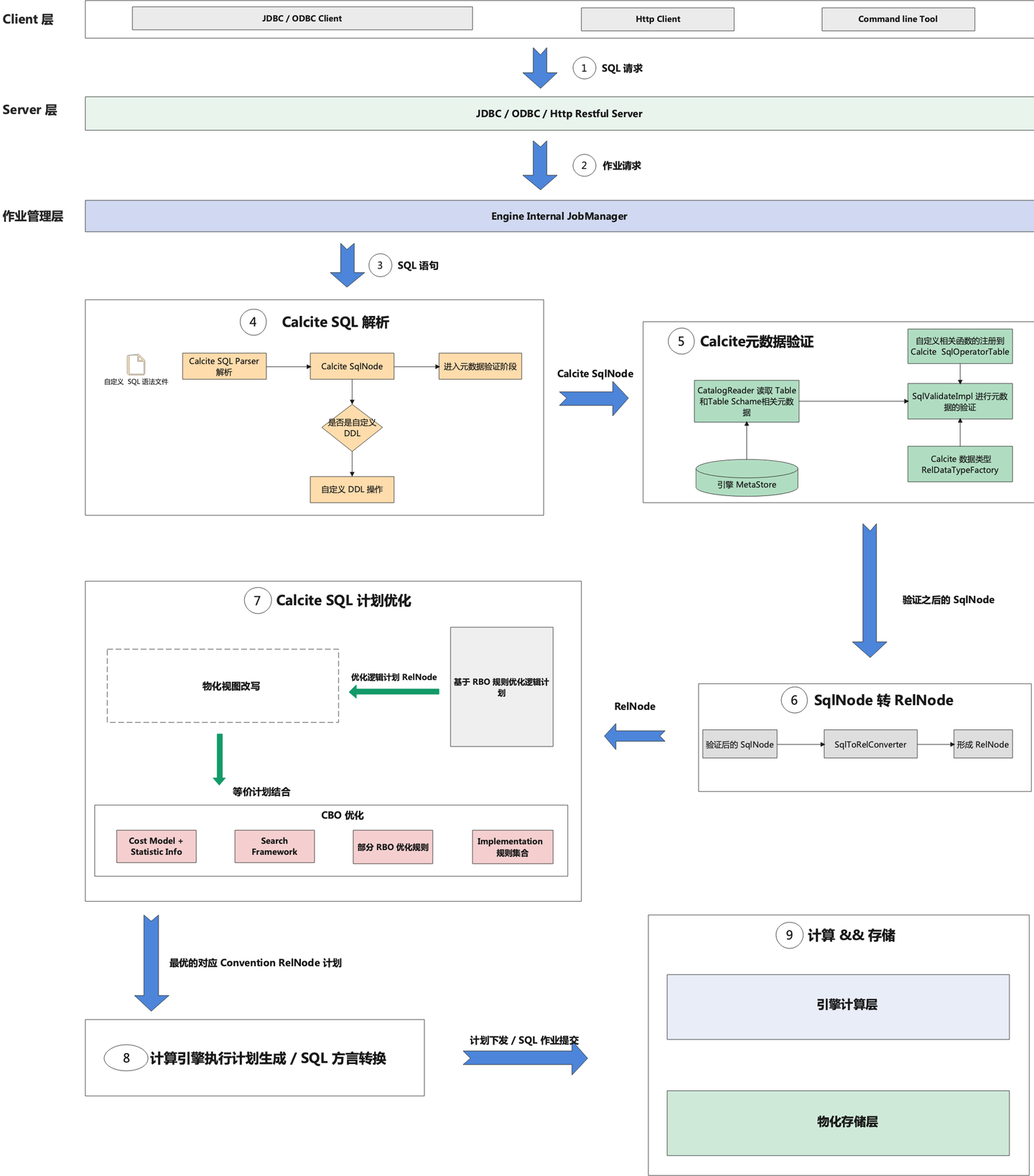
如上图所示,一条 SQL 整体处理流程分为以下几个步骤:
- 当 Client 层发起一条 SQL 请求时,请求会到 JDBC Server 端,JDBC Server 端底层一般可以是 GRPC 服务或者 HTTP 服务,在 Calcite 中,也可以使用 Calcite Avatica 来做 JDBC 服务端和 Driver 层的代码开发。
- 服务端接收到 SQL 请求后,会在内部构建出一个 Job 作业请求,同时提交到内部作业服务,之后会进入到 SQL 链路处理流程中。
- 在 SQL 处理流程中,第一步则是将 SQL 解析成一棵 SqlNode 的 AST 抽象语法树,这个过程中会做 SQL 词法和语法的校验。之后会进入到 SQL 验证阶段,SQL 验证阶段主要对 SQL 的语义进行验证,比如查询的数据表是否存在、函数是否存在、函数参数数据类型是否匹配等等。元数据验证完之后,其输出本质还是一棵 SqlNode Tree,接下来会将 SqlNode Tree 转换为一棵RelNode 关系代数 Tree,同时进入到 SQL 优化阶段。
- 在 Calcite 中,RBO 优化主要使用HepPlanner类来进行实现。CBO 优化,则是使用 VolcanoPlanner来进行实现,RBO 规则和 CBO 规则都支持自定义扩展。
- 经过 SQL 优化器的优化,会产出最优的物理计划。但此时仍然无法最终运行,我们还需要将物理计划转化为底层计算引擎的 SQL 方言,才能进行作业的提交和计算。
更多精彩内容,欢迎关注我的公粽号: 【雷克分析】 ,关注私信发送:命令、提效、数据库、提示词、calcite、论文,有学习资料等着你 ,欢迎关注
资料信息:














 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









