







Apache Hudi(Hadoop Upserts Deletes and Incrementals)是一个开源的大数据框架,主要用于处理大规模数据湖中的增量数据、数据更新和删除。Hudi 提供了一种高效的方式来处理数据流中的增量变化,特别适合需要更新、插入、删除操作的场景。它的核心理念是将传统的数据湖操作(如HDFS上的文件处理)与数据库的更新和增量数据处理能力结合起来,支持高效的写入、查询和管理大规模数据。
1. Hudi 的主要特性和功能
-
增量数据处理(Upserts)
Hudi 支持增量更新(upsert)操作,即在数据已存在的情况下,可以根据主键对已有数据进行更新。这对于实时数据流和需要频繁修改的场景特别有用。与传统的批量插入不同,Hudi 可以避免全量数据重写,只更新必要的部分,从而提高效率。 -
删除操作(Deletes)
传统的大数据处理框架通常不支持直接删除数据。Hudi 通过提供删除功能,允许用户在大数据环境中执行删除操作,这对于某些业务场景(例如数据隐私、GDPR 合规)非常重要。 -
事务支持(ACID)
Hudi 提供了基于表的事务管理,确保在多个并行任务中对同一数据的修改具有一致性和隔离性。这使得它能够提供类似于关系型数据库中的事务(ACID)特性,保证数据的一致性和完整性。 -
增量查询(Incremental Queries)
Hudi 可以高效地处理增量查询,即只读取自上次查询以来发生变化的数据。这对于需要高效地读取增量数据的应用场景(如实时分析、监控等)非常适合。 -
时间旅行查询(Time Travel)
由于 Hudi 保存了数据的历史版本,它支持查询某个特定时间点的数据,类似于“时间旅行”。这对于回溯分析、审计和错误恢复非常有用。 -
高效的写入和合并(Compaction)
在数据湖中,频繁的增量写入可能会导致大量的小文件。Hudi 提供了合并操作(compaction),将多个小文件合并为更大的文件,以提高读取性能和存储效率。 -
与大数据生态系统的兼容性
Hudi 可以与大数据生态系统中的多个组件兼容,如 Apache Spark、Hive 和 Presto 等。它能与这些工具无缝集成,允许用户在现有的工具链中直接使用 Hudi。
2. Hudi 的数据存储模式
Hudi 提供了两种主要的数据存储模式:
-
Copy on Write (COW)
在 COW 模式下,Hudi 将更新的数据写入新的文件版本。每当发生更新时,Hudi 会创建一个新的文件,包含更新后的数据。旧的文件会被标记为无效,最终通过Compaction操作被清理。COW 模式适用于对查询性能要求较高的场景,因为它能提供较高的读取效率。 -
Merge on Read (MOR)
在 MOR 模式下,Hudi 允许在文件中保留增量数据的写入。在读取数据时,Hudi 会合并最新的增量数据和原始数据。这种模式适用于写入频繁且读取相对较少的场景,能够优化写入性能,但读取性能可能不如 COW 模式。
3. Hudi 的架构与组件
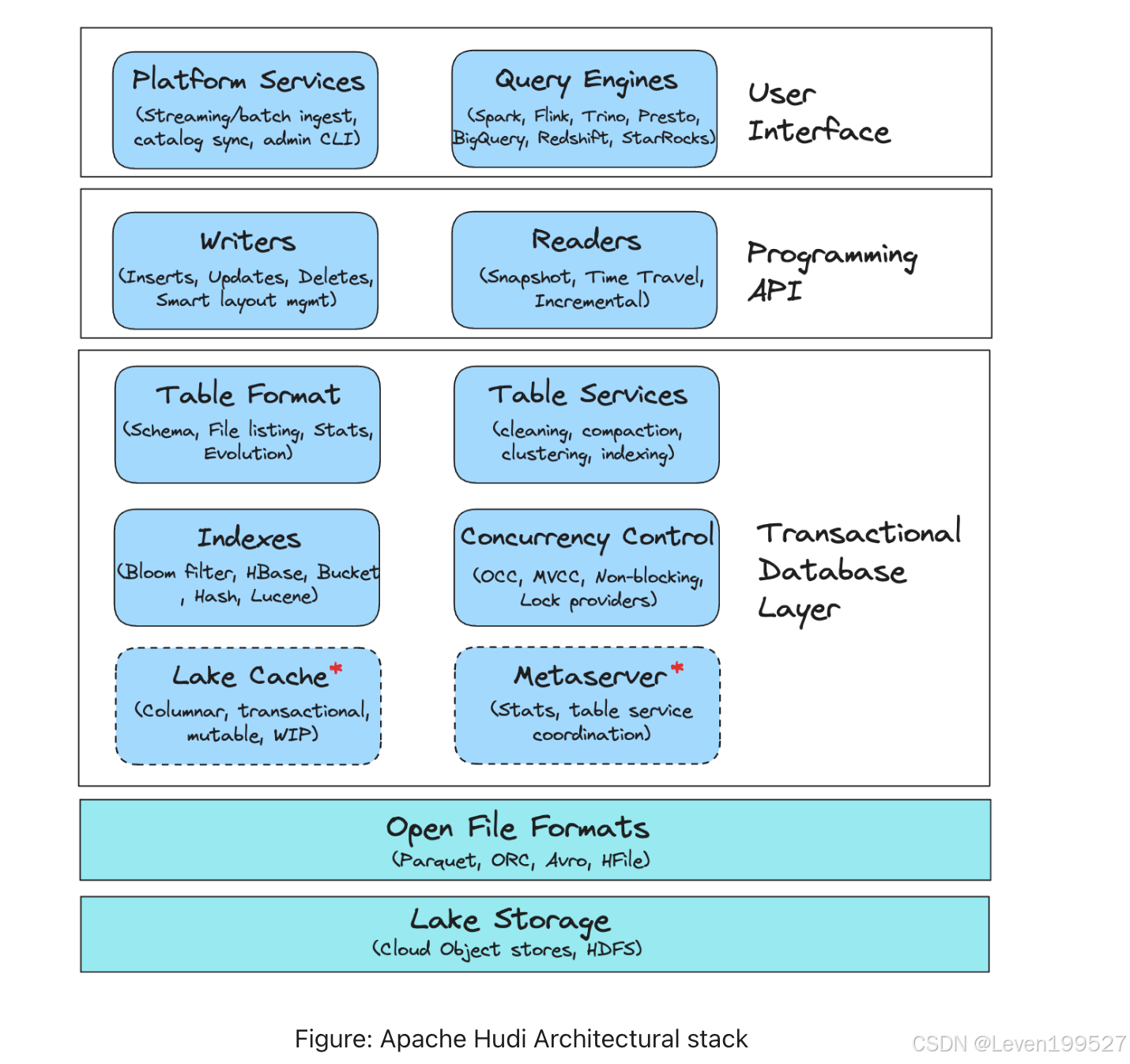
3.1 Lake Storage
存储层是存储数据文件(例如 Parquet)的地方。Hudi 通过 Hadoop FileSystem API 与存储层交互,从而实现与各种系统的兼容,包括支持快速追加操作的 HDFS,以及 Amazon S3、Google Cloud Storage (GCS) 和 Azure Blob Storage 等各种云存储。此外,Hudi 提供了自己的存储 API,可以依赖于独立于 Hadoop 的文件系统实现,从而简化与各种文件系统的集成。Hudi 增加了一个自定义的文件系统封装,为优化存储性能奠定了基础。
3.2 File Formats
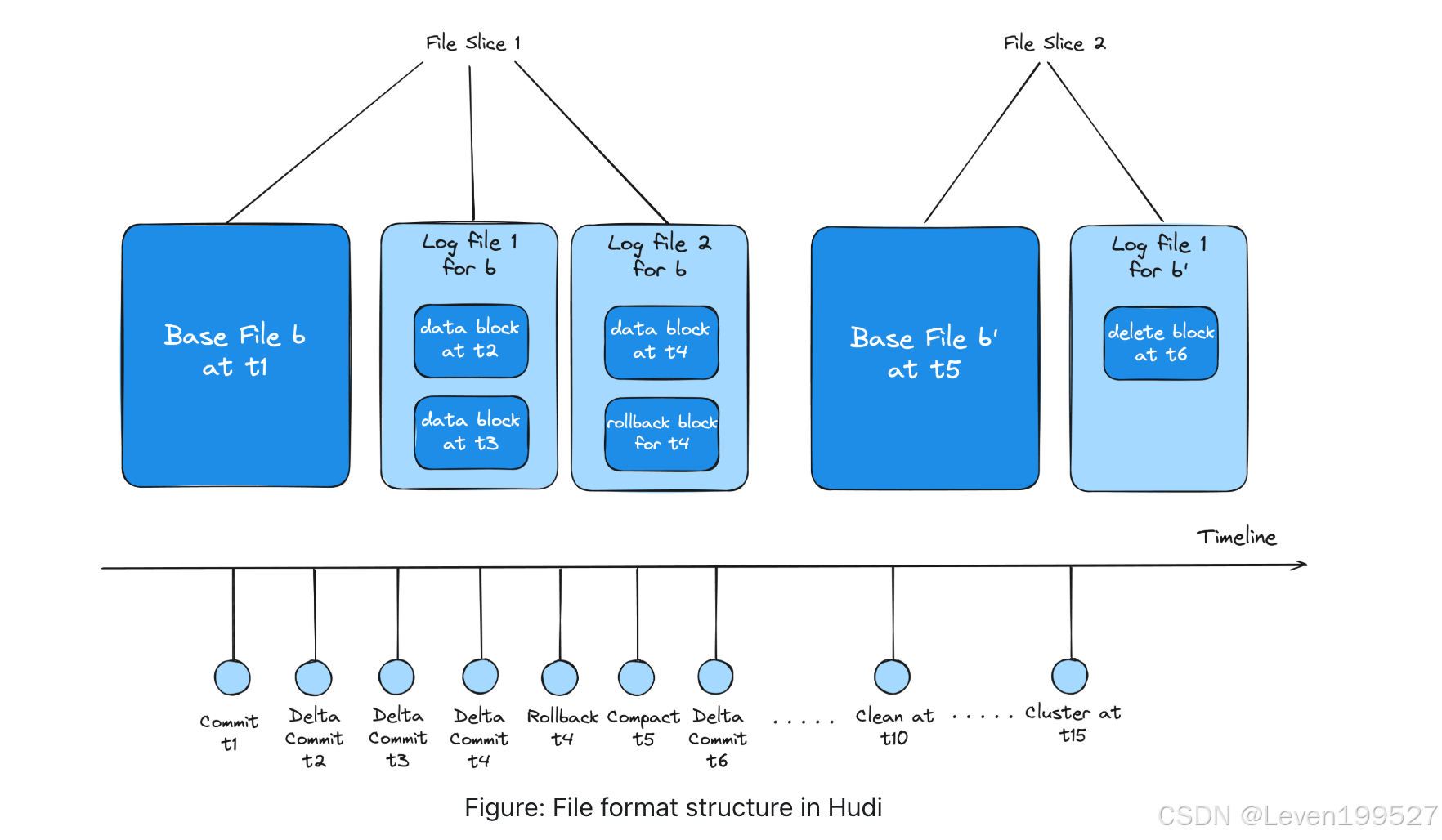
文件格式存储原始数据,并以物理形式存储在湖存储中。Hudi 基于文件组(File Groups)和文件切片(File Slices)的逻辑结构进行操作,这些结构由基础文件(Base File)和日志文件(Log Files)组成。基础文件经过压缩和优化以提高读取性能,并通过日志文件的追加功能提升效率。未来Hudi的更新计划将支持多样化的格式,例如非结构化数据(如 JSON、图像),并实现与事件流处理、OLAP 引擎以及数据仓库中不同存储层的兼容性。Hudi 的布局方案将所有更改编码为日志文件中的一系列块(包括数据块、删除块、回滚块)。通过将数据以开放文件格式(如 Parquet)提供,Hudi 使用户可以引入任意计算引擎以满足特定工作负载需求。
3.3 Transactional Database Layer
Hudi 的事务性数据库层由核心组件组成,这些组件负责基本操作和服务,使 Hudi 能够在数据湖仓存储中高效地存储、检索和管理数据。
3.3.1 Table Format
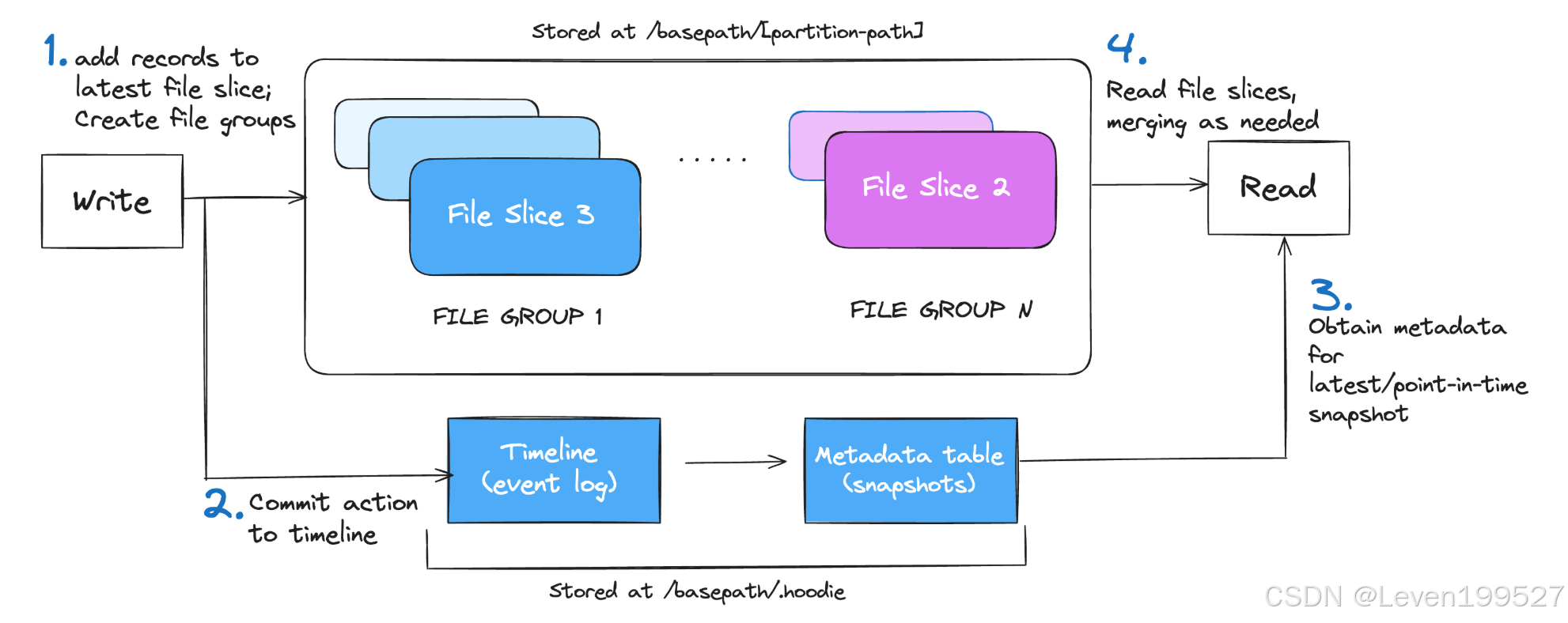
类比文件格式,表格式仅包含表的文件布局、模式和用于跟踪更改的元数据。Hudi 将表或分区中的文件组织为文件组(File Groups)。更新会记录在与这些文件组关联的日志文件(Log Files)中,以确保高效的合并操作。Hudi 的表格式主要涉及以下三个核心组件:
-
时间线(Timeline):Hudi 的时间线存储在 /.hoodie 文件夹中,是一个关键的事件日志,用于按顺序记录所有表操作,事件会保留指定的时间段。Hudi 独特地将每个文件组(File Group)设计为一个自包含的日志,通过增量日志(delta logs)能够重建记录状态,即使相关操作已被归档。此方法有效地根据表活动的频率限制了元数据的大小,这对于管理频繁更新的表至关重要。
-
文件组和文件切片:在每个分区中,数据以基础文件(Base File)和日志文件(Log File)的形式物理存储,并以文件组(File Groups)和文件切片(File Slices)这两个逻辑概念进行组织。文件组包含多个文件切片的版本,并被分割为多个文件切片。一个文件切片由基础文件和日志文件组成。文件组中的每个文件切片通过创建它的提交时间戳(commit's timestamp)唯一标识。
-
元数据表:Hudi 的元数据表实现为一个 "读时合并"(Merge-on-Read)表,能够高效处理快速更新,并具有较低的写放大(Write Amplification)。它利用 HFile 格式实现快速的键索引查找,存储关键信息,如文件路径、列统计、布隆过滤器(Bloom Filters)和记录索引。这种方法通过减少昂贵的云文件列表操作需求,简化了操作流程。Hudi 中的元数据表还充当了一个额外的索引系统,从而提升读写性能。
Hudi 将更新记录存储到日志文件(Log Files)中的方法相比于像 Hive ACID 这样的系统更加高效,合并开销也更低。Hive ACID 需要将所有增量记录与所有基础文件(Base Files)进行合并,而 Hudi 的方法避免了这一昂贵的操作。
3.3.2 Indexes
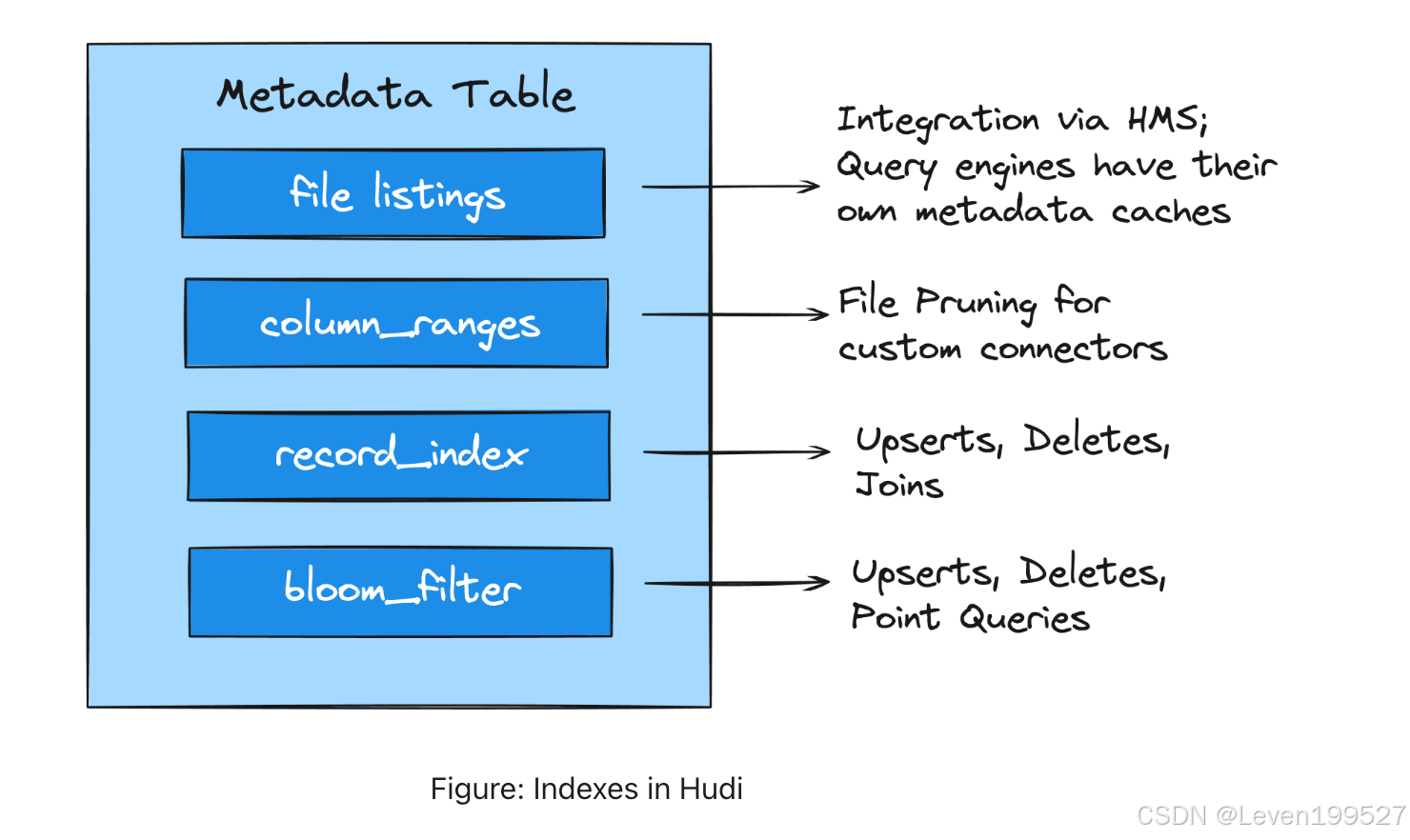
Hudi 的索引功能通过优化查询规划,最小化 I/O,提升响应速度,同时以较低的合并成本实现更快的写入性能。Hudi 的元数据表将索引的优势同时带给读者和写者。计算引擎可以利用元数据表中的各种索引,如文件列表(File Listings)、列统计(Column Statistics)、布隆过滤器(Bloom Filters)、记录级索引(Record-Level Indexes)和函数索引(Functional Indexes),快速生成优化的查询计划并提升读取性能。
除了元数据表索引外,Hudi 还支持 Simple 索引、Bloom 索引、HBase 索引 和 Bucket 索引,以高效定位包含特定记录键的文件组(File Groups)。此外,Hudi 提供诸如函数索引(Functional Indexes)和二级索引(Secondary Indexes)等读者索引,以进一步加速读取操作。Hudi 的表分区方案被巧妙地用于实现全局(Global)和非全局(Non-Global)索引策略
3.3.3 Table Services
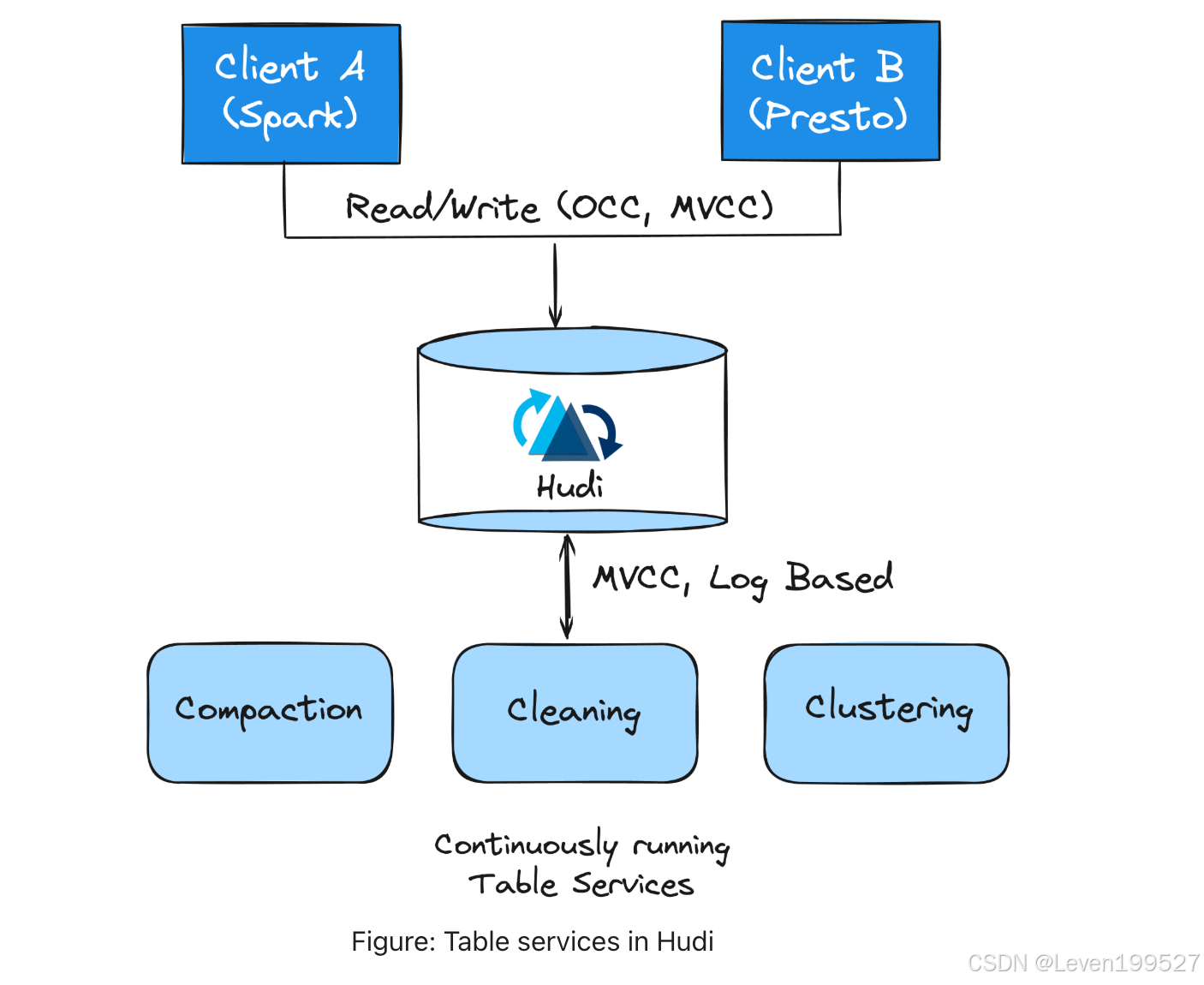
Apache Hudi 提供多种表服务(Table Services),以帮助维持表存储布局和元数据管理的高效性能。Hudi 的设计中内置了表服务,可以以内联模式(inline)、半异步模式(semi-asynchronous)或全异步模式(full-asynchronous)运行。此外,Spark 和 Flink 的流式写入器(Streaming Writers)可以以连续模式(Continuous Mode)运行,并通过智能共享底层执行器,与写入器异步调用表服务。
3.3.3.1 Clustering
聚类服务(Clustering Service)类似于云数据仓库中的功能,允许用户通过排序键(Sort Keys)对经常被查询的记录进行分组,或者将较小的基础文件(Base Files)合并为更大的文件,以实现最佳的文件大小管理。该服务与其他时间线操作(如清理和压缩)完全集成,支持智能优化,例如跳过对正在进行聚类操作的文件组(File Groups)的压缩,从而节省 I/O 开销。
3.3.3.2 Compaction
Hudi 的压缩服务采用了日期分区和I/O限制等策略,将基础文件(Base Files)与增量日志(delta logs)合并以生成更新的基础文件。通过 Hudi 的文件分组和灵活的日志合并机制,它支持对同一文件组(File Group)进行并发写入。这使得即使在同时更新记录时,也能非阻塞地执行删除操作。
3.3.3.3 Cleaning
Cleaner 服务以时间线为基础进行增量清理,移除超过配置的增量查询保留期的文件切片(File Slices),同时为运行时间较长的批处理任务(例如 Hive ETL)预留足够的完成时间。这样,用户可以回收存储空间,从而降低成本。
3.3.3.4 Indexing
Hudi 的可扩展元数据表包含有关表的辅助数据。该子系统涵盖了多种索引,包括文件索引(files)、列统计(column_stats)和布隆过滤器(bloom_filters),从而支持高效的记录定位和数据跳过。在写入吞吐量与索引更新之间实现平衡是一个核心挑战,因为传统的索引方法(如在索引期间锁定写入)对于大型表来说不可行,原因是处理时间过长。Hudi 通过创新的异步元数据索引解决了这一问题,使得在不影响写入的情况下创建各种索引成为可能。这种方法不仅提高了写入延迟,还通过减少写入与索引活动之间的资源争夺,最大限度地减少了资源浪费。
3.3.3.5 Concurrency Control
并发控制定义了不同的写入者和读取者如何协调对表的访问。Hudi 通过将带有单调递增时间戳的提交记录发布到时间线,奠定了原子性保障的基础,同时明确区分了写入者(负责更新和删除)、表服务(专注于存储优化和记录管理)以及读取者(用于查询执行)。Hudi 提供了快照隔离功能,在这些不同操作中提供一致的表视图。它在写入者与表服务之间以及不同表服务之间采用无锁、非阻塞的多版本并发控制(MVCC),并在多写入者场景中使用乐观并发控制(OCC)进行早期冲突检测。从 Hudi 1.0 开始,引入了非阻塞并发控制(NBCC),允许多个写入者同时对表进行操作,同时实现非阻塞的冲突解决。
3.3.4 Lake Cache*
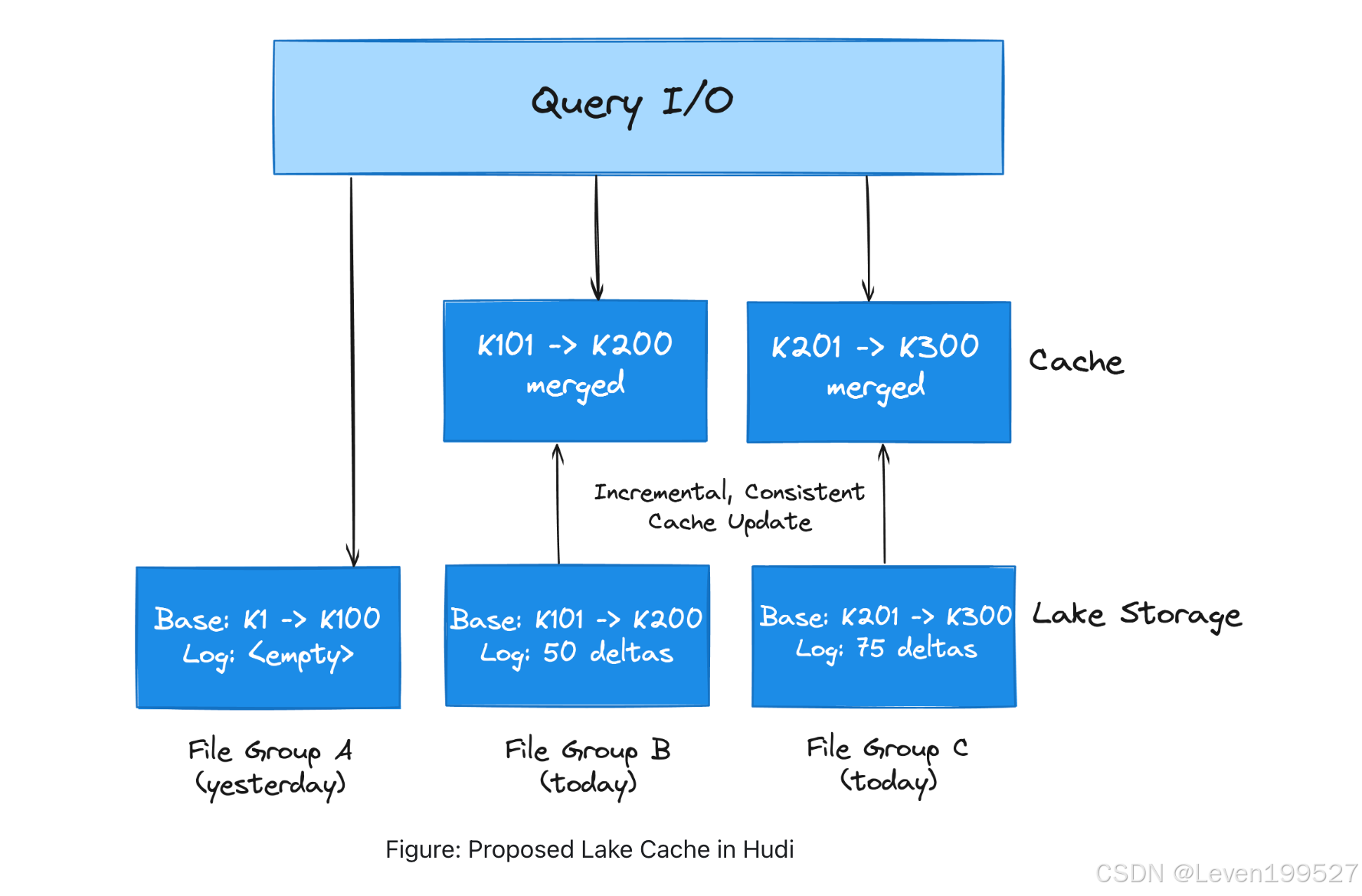
当今的数据湖在快速写入数据与优化查询性能之间面临权衡。写入较小的文件或记录增量日志可以提高写入速度,但更好的查询性能通常需要减少打开的文件数量并预先物化合并结果。大多数数据库使用缓冲池来降低存储访问成本。Hudi 的设计支持创建一个多租户缓存层,用于存储预合并的文件切片(File Slices),并通过 Hudi 的时间线轻松传递缓存策略。传统上,缓存通常位于查询引擎附近或内存文件系统中。将缓存层与 Hudi 的事务性存储集成,可以实现跨查询引擎的共享缓存,支持更新和删除操作,从而降低成本。
3.3.5 Metaserver*
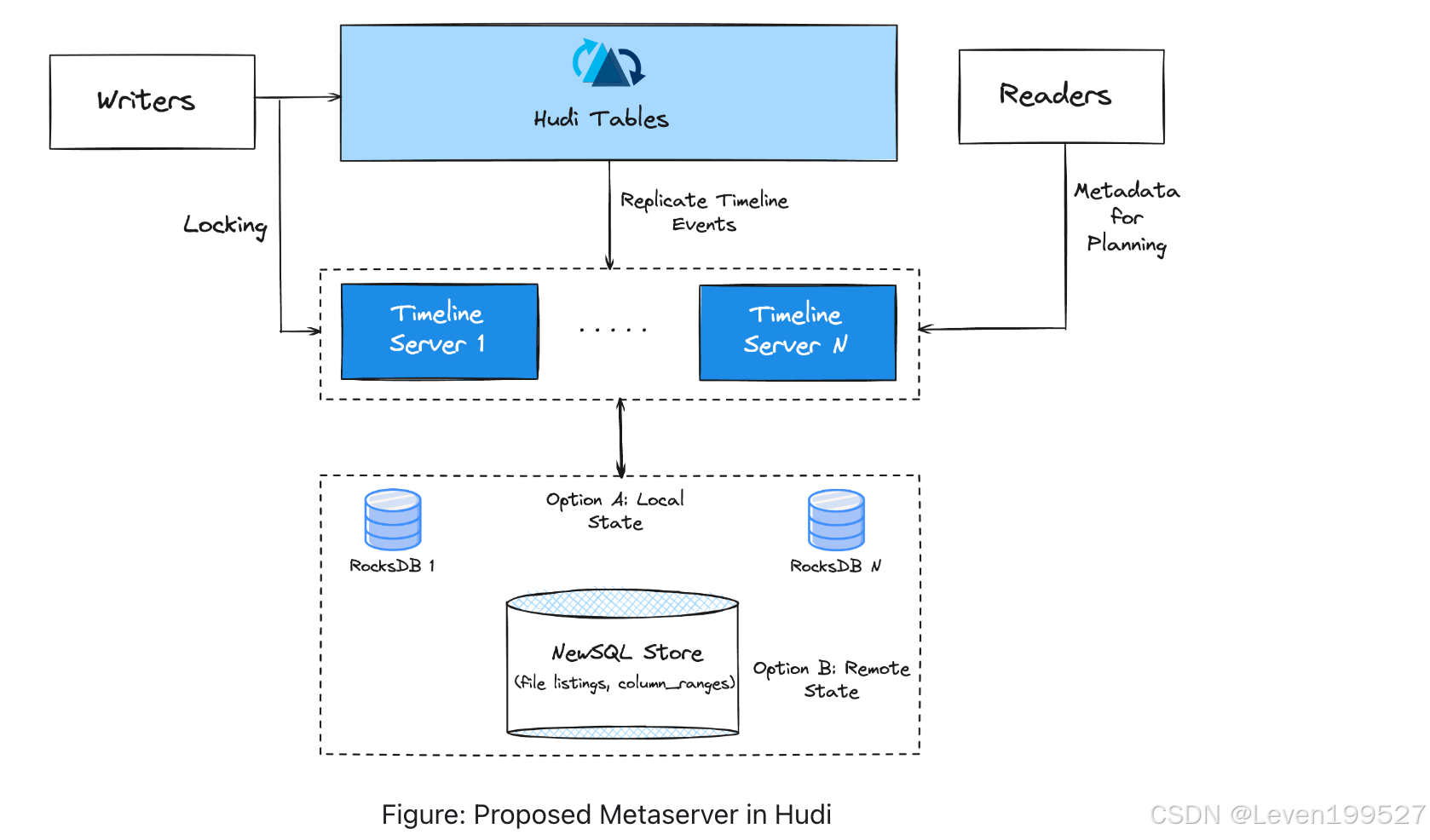
将表元数据存储在湖存储中虽然具有可扩展性,但相比于通过 RPC 调用可扩展的元服务器效率更低。Hudi 针对此问题引入了其元数据服务器(称为 "metaserver"),作为管理大量表元数据的高效替代方案。目前,嵌入在 Hudi 写入进程中的时间线服务器(timeline server)使用本地的 RocksDB 存储和 Javalin REST API 提供文件列表服务,从而减少了云存储的文件列表操作。从版本 0.6.0 开始,时间线服务器逐步向独立的时间线服务器方向发展,以实现水平扩展和增强安全性。
3.4 Programming APIs
3.4.1 Writers
Hudi 表可以作为 Spark/Flink 数据管道的目标(sink),并且 Hudi 的写入路径相比于传统的 Parquet/Avro sink 提供了多种增强功能。它将写入操作分为增量(insert、upsert、delete)和批量/大批量(insert_overwrite、delete_partition、bulk_insert)两类,每类操作都具备特定功能。
-
upsert 和 delete 操作高效地合并具有相同键的记录,并与文件大小控制机制集成。
-
insert 操作 则智能地跳过某些步骤(如预合并),以保持数据管道的性能优势。
-
bulk_insert 操作 为数据导入提供文件大小的精细控制。
批量操作通过多版本并发控制(MVCC)实现增量与批量处理之间的无缝过渡。此外,Hudi 的写入管道包含多种优化,例如使用 RocksDB 处理大规模合并操作以及支持并发 I/O,从而显著提升写入性能。
3.4.2 Readers
Hudi 为写入者和读取者提供了快照隔离功能,使得在主流查询引擎(如 Spark、Hive、Flink、Presto、Trino 和 Impala)以及云数据仓库中可以进行一致的表快照查询。它通过轻量级的处理方式优化查询性能,尤其是针对基础列式文件的读取,并集成了引擎特定的向量化读取器(例如 Presto 和 Trino)。这种可扩展的模型超越了对单独读取器的需求,并利用每个引擎的独特优化功能,例如 Presto 和 Trino 的数据/元数据缓存。
对于合并基础文件(Base Files)和日志文件(Log Files)的查询,Hudi 使用了可溢出映射(spillable maps)和惰性读取(lazy reading)等机制来提升合并性能。此外,Hudi 提供了读取优化(Read-Optimized)的查询选项,通过牺牲数据的新鲜度换取更快的查询速度。
最近,Hudi 增加了一些新特性,例如位置合并(positional merge)、对日志文件仅编码变更列的功能,以及支持将 Parquet 用作日志文件格式,从而进一步提升 MoR(Merge-on-Read)快照查询的性能。
3.5 User Interface
3.5.1 Platform Services
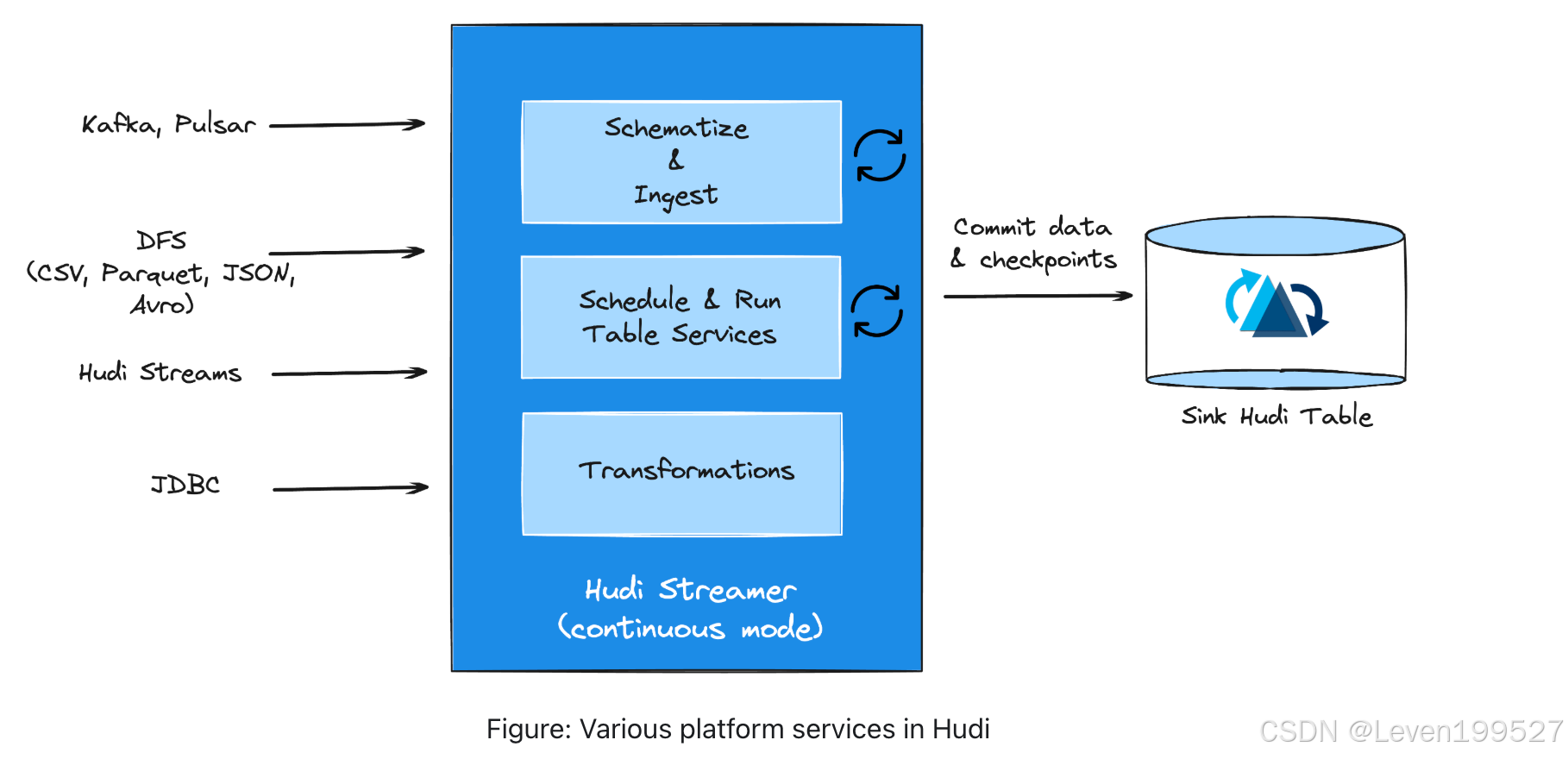
平台服务提供特定于数据和工作负载的功能,直接构建在表服务之上,与写入者和读取者进行交互。例如,Hudi Streamer 专门处理数据和工作负载,能够与 Kafka 流和各种数据格式无缝集成以构建数据湖。这些服务支持自动检查点管理、与主流模式注册表(包括 Confluent)的集成,以及数据去重功能。
Hudi Streamer 还提供回填(backfill)、一次性运行(one-off runs)和连续模式(continuous mode)操作的功能,支持 Spark/Flink 流式写入。此外,Hudi 提供了用于快照和增量导出 Hudi 表、导入新表的工具,以及提交后的回调(post-commit callback),以支持分析或工作流管理,从而增强生产级增量管道的部署能力。
除了这些服务,Hudi 还广泛支持多种目录服务,例如 Hive Metastore、AWS Glue、Google BigQuery 和 DataHub 等,使 Hudi 表能够同步到 Trino 和 Presto 等交互式引擎中进行查询。
3.5.2 Query Engines
Apache Hudi 与多种查询引擎兼容,以满足各种分析需求。在分布式 ETL 批处理场景中,Apache Spark 经常被使用,因其能够高效处理大规模数据。在流处理场景中,Apache Flink 和 Apache Spark 的 Structured Streaming 在与 Hudi 配合时提供了强大的支持。此外,Hudi 还支持现代数据湖查询引擎,例如 Trino 和 Presto,以及现代分析型数据库,例如 ClickHouse 和 StarRocks。
这种对计算引擎的多样化支持,使得 Apache Hudi 成为一个灵活且适应性强的平台,能够满足广泛的使用场景。


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











