






转载加自整理:

基础概念:
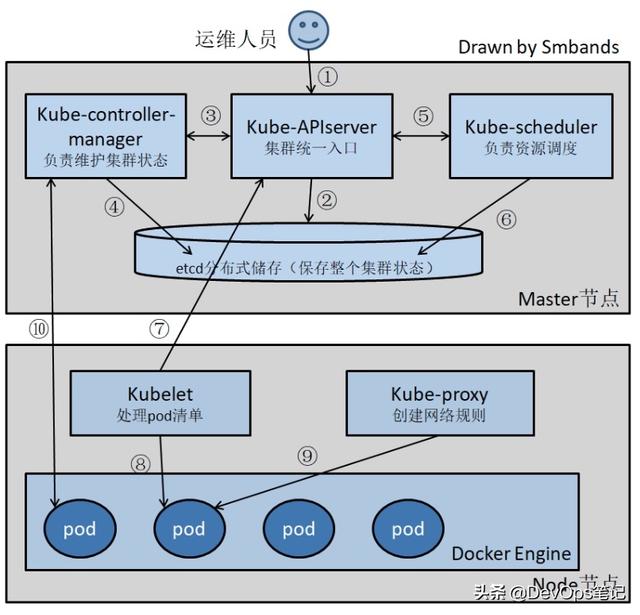
1.master:Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master
master上的组件:
1.Kubernetes API Server(kube-apiserver)
Kubernetes API,集群的统一入口,各组件协调者,以HTTP API提供接口服务,Kubernetes里所有资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
2.Kubernetes Controller Manager(kube-controller-manager)
Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的大总管
3.kube-scheduler
负责资源调度(Pod调度)的进程
Node
具体"干活"的,工作负载节点,在Kubernetes集群中除了master节点外的机器被称为Node。每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,其上的工作负载会被Master自动转移到其他Node节点上。
运行在Node上的组件:
1.kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,负责Pod对应容器的创建、启停等任务。同时与Master密切协作,实现集群管理的基本功能,获取Node节点上Pod的运行状态等
2.kube-proxy
在Node节点上实现Pod网络代理,实现Kubernetes Service的通信和负载均衡机制的重要组件。
3.docker
Docker引擎,负责本机的容器的创建和管理工作
注:
Node可以在运行期间动态增加到Kubernetes集群中
Etcd
Etcd是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为Etcd数据提供备份计划。Etcd是一个高可用的键值存储系统
Replication Controller
简称RC,RC是Kubernetes系统中的核心概念之一。它能够保证Pod持续运行,并且在任何时候都有指定数量的Pod副本,在此基础上提供一些高级特性,比如滚动升级和弹性伸缩
注
在我们定义了一个RC并将其提交到Kubernetes集群中后,Master上的Controller Manager组件就会得到通知,定期巡检系统中当前存活的目标Pod,并确保目标Pod实例的数量刚好等于此RC的期望值,如果有过多的Pod副本在运行,系统就会停掉一些Pod,过少则会再创建一些Pod。相比传统的IT环境,如果程序意外挂掉,需要手工重启,但是在k8s通过RC,就大大减少这些手工运维工作
ReplicaSet
ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,所以我们通常不需要直接使用 ReplicaSet。
注:
1.Replication Controller由于与Kubernetes代码中的模块Replication Controller同名,并且“Replication Controller”无法准确表达它的本意,所以在Kubernetes1.2中,升级为另外一个新概念——Replica Set,官方解释为“下一代的RC”
2.我们很少单独使用Replica Set,它主要被Deployment这个更高层的资源对象所使用。
Deployment
应用管理者,是用于部署应用的对象,Deployment内部使用了Replica Set来实现的,我们可以把Deployment看做RC的一次升级
注:
创建Deployment对象后,master会根据Deployment对象的配置文件去描述应用,应用名称,使用的镜像名称,需要几个实例,多少内存,多少CPU资源
有了配置文件就可以通过Kubernetes提供的命令行客户端 - kubectl 去管理这个应用了。kubectl 会跟 Kubernetes 的 master 通过RestAPI通信,最终完成应用的管理。
比如我们刚才配置好的 Deployment 配置文件叫 app.yaml,我们就可以通过
"kubectl create -f app.yaml" 来创建这个应用啦,之后就由 Kubernetes 来保证我们的应用处于运行状态,当某个实例运行失败了或者运行着应用的 Node 突然宕机了,Kubernetes 会自动发现并在新的 Node 上调度一个新的实例,保证我们的应用始终达到我们预期的结果。
Pod
Pod 是一组容器(当然也可以只有一个)容器本身就是一个小盒子了,Pod 相当于在容器上又包了一层小盒子。Pod是Kubernetes的最小调度单位。
注:
Pod中的容器共享数据卷volume
Pod中的容器共享IP地址和端口
Service
Service是一组逻辑pod的抽象,为一组pod提供统一入口,用户只需与service打交道,service提供DNS解析名称,负责追踪pod动态变化并更新转发表,通过负载均衡算法最终将流量转发到后端的pod。Kubernetes里的每个Service其实也可以理解为我们的微服务架构中的一个微服务。
Service对外提供多种入口:
ClusterIP:Service在集群内的唯一ip地址,虚拟的IP,只能在 Kubernetes集群里访问。通过ClusterIP,负载均衡的访问后端的Pod
NodeIP+NodePort:Service会在集群的每个Node上都启动一个端口,通过NodeIP:NodePort访问后端的Pod
注:
1.Service负责服务发现,找到每个Pod,不管Deployment的Pod有多少个,不管它是更新,销毁还是重建,Service总是能发现并维护好它的ip列表。
2.kube-proxy是kubernetes核心组件,运行在集群中每一个节点上,负责监控集群中service、endpoint变更,维护各个节点上的转发规则,是实现servcie功能的核心部件。
Label
标签,一个Label是一个key=value的键值对。Label可以被附加到各种资源对象上,例如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label。
Volume
Volume(存储卷)Volume是Pod中能够被多个容器共享的磁盘目录。我们知道,默认情况下Docker容器中的数据都是非持久化的,在容器消亡后数据也会消失。因此Docker提供了Volume机制以便实现数据的持久化。Kubernetes中Volume的概念与Docker中的Volume类似,但不完全相同。
Kubernetes提供了非常丰富的Volume类型:
1.emptyDir:临时空间,Pod分配到Node时创建,无须指定宿主主机上对应的目录,在Kubernetes会自动分配当前Node的一个目录,当Pod被移除时,emptyDir中的数据也会永久删除。
hostPath:为Pod挂载宿主主机上的文件或目录。用于数据永久保存。在不同的Node上具有相同配置的Pod,可能会因为宿主机上的目录和文件不同而导致Volume上的目录和文件的访问结果不一致。
2.gcePersistentDisk:使用谷歌公有云提供的永久磁盘。数据永久保存。
NFS:NFS 是 Network File System 的缩写,即网络文件系统。Kubernetes 中通过简单地配置就可以挂载 NFS 到 Pod 中,而 NFS 中的数据是可以永久保存的,同时 NFS 支持同时写操作。k8s挂载NFS
3.Persistent Volume:简称PV,就是网盘,网络存储,不属于任何Node,但可以在每个Node上访问。
Namespace
命名空间,Namespace在很多情况下用于实现多租户的资源隔离。Namespace通过集群内部的资源对象"分配"到不同的Namespace中,形成逻辑上纷纷组的不同项目,便于不同的分组共享使用整个集群的资源的同时还能被分别管理。
secret:密钥对象,Secret是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。使用Secret的好处是可以避免把敏感信息明文写在配置文件里。在Kubernetes集群中配置和使用服务不可避免的要用到各种敏感信息实现登录、认证等功能,例如访问AWS存储的用户名密码。















 2198
2198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









