







## README
声明:本笔记是基于黑马程序员网课《玩转Shell 编程》所学习整理
目录
shell 编程
一、shell 介绍
1、简介
-
shell 通过编写命令发送给Linux内核去执行,操作就是计算机硬件。所以shell是用户操作计算机硬件的桥梁。
-
shell 脚本:通过shell 命令和程序编程语言编写的文本文件
查看使用的shell解析器类型echo $SHELL
2、编写格式和执行规范
2.1 编写格式
(1)脚本文件后缀名规范
后缀名建议使用.sh结尾
(2)首行格式规范
首行需要设置shell 解析器的类型
#! /bin/bash
(3)注释格式
单行注释:# 注释内容 多行注释:
:<<! 注释内容1 注释内容2 !
2.2 执行方式
-
sh helloworld.sh -
bash helloworld.sh -
./helloworld.sh:用这种方式需要脚本文件有可执行权限
调整文件权限chmod
3、多命令处理
例:已知目录/root/ithema目录,执行batch.sh脚本,实现在目录下创建一个one.txt,并添加内容“Hello Shell”。
#! /bin/bash # 创建文件 touch /root/itheima/one.txt # 输出内容并保存到文件 echo "Hello Shell" >> /root/itheima/one.txt
二、shell 变量
-
系统环境变量
-
自定义变量
-
特殊符号变量
1、系统环境变量
是系统提供的共享变量,是Linux系统加载shell的配置文件中定义的变量,共享给所有的shell程序使用的。
配置文件分类
(1)全局配置文件
/etc/profile
/etc/profile.d/*.sh
/etc/bashrc
(2)个人配置文件
当前用户./bash_profile
当前用户/.bashrc
环境变量分类
系统级环境变量:加载全局配置文件中的变量,共享给所有用户使用的。
用户级环境变量:加载个人配置文件中的变量,共享给特定用户使用的。
查看环境变量
查看当前系统环境变量:env
查看shell 所有变量:set
常用系统环境变量
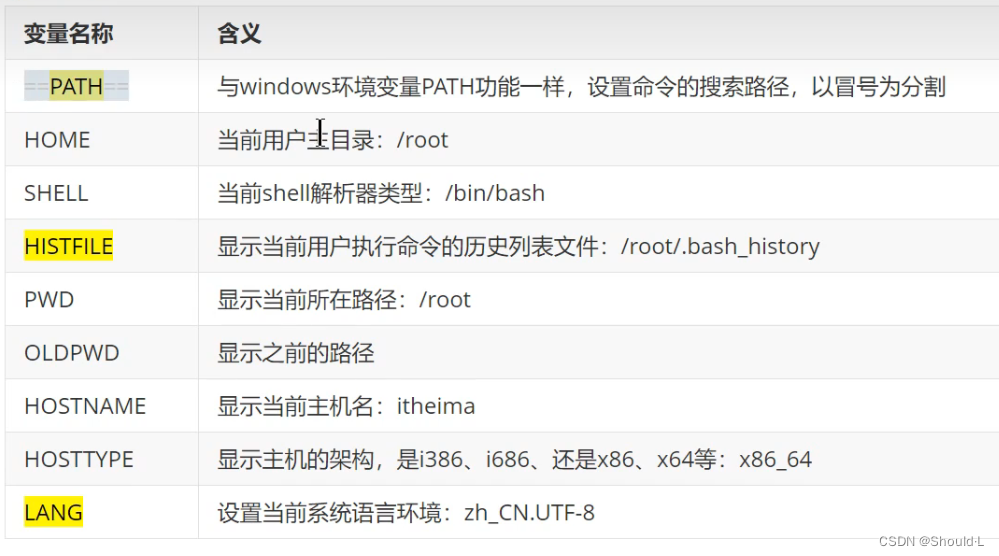
2、自定义变量
-
自定义局部变量
-
自定义常量
-
自定义全局变量
(1)自定义局部变量
定义在一个脚本文件中的变量,只能在这个脚本文件中使用。
规则:
-
变量名称可以有字母,数字和下划线组成,但不能以数字开头。
-
等号两侧不能有空格。
-
变量的默认类型都是字符串类型,无法直接进行数字运算。
-
变量名称不能使用关键字
定义:var_name=value
查询:
-
直接使用变量名查询:
$var_name -
使用花括号:
${var_name}
花括号方式适合拼接字符串
删除:unset var_name
(2)自定义常量
变量设置值以后不可修改的变量叫做常量,也叫只读变量。
定义:readonly var_name
(3)自定义全局变量
父子 shell 环境介绍
例如:有两个 shell 脚本文件 A.sh 和 B.sh
如果在 A.sh 中执行了 B.sh,那么 A.sh 就是父 shell,B.sh 就是子 shell
全局变量介绍:
全局变量在父子 shell 环境中均可使用
定义:export var_name1 var_name2
3、特殊符号变量
| 符号变量 | 含义 |
|---|---|
| $n | 用于接收脚本文件执行时传入的参数,接收第10个以上套上大括号。 |
| $0 | 用于获取当前脚本文件名称 |
| $# | 获取所有输入参数的个数 |
| $* 和 $@ | 获取所有输入参数。 1.不使用双引号括起来时,功能一样。 2.使用双引号时"$*"、"$@",获取的所有参数拼接为一个字符串。 |
| $? | 用于获取上一个shell命令的返回值/退出状态码,一般来说返回状态码为 0 表示返回成功。 |
| $$ | 用于获取当前 shell 环境的进程 id 号 |
三、环境变量进阶
1、定义系统环境变量
当前用户进入 shell 环境初始化的时候会加载全局配置文件 /etc/profile 里面的环境变量,供给所有的 shell 使用。
创建环境变量:
-
编辑
/etc/profile文件
# 增加命令:定义变量 VAR1=VAR1,并导出为环境变量 vim /etc/profile # ------------ /etc/profile -------------- # vim 命令模式,使用 G 跳转到文件末尾。(使用 gg 定位到文件首行位置) export VAR1=VAR1 # 按esc返回命令模式,使用 :wq 保存并退出文件
-
重载配置文件 /etc/profile,使修改生效。
source /etc/profile
-
读取环境变量 VAR1
echo ${VAR1}
2、加载流程原理
用户进入 Linux 就会初始化 Shell 环境,环境会加载配置文件中的环境变量。每个脚本文件都有自己的 Shell 环境。
分类:交互式与非交互式 Shell
| 类型名称 | 含义 |
|---|---|
| 交互式 Shell | 与用户进行互动,效果就是用户输入一个命令,Shell 立刻反馈响应。 |
| 非交互式 Shell | 不需要用户参与就可以执行多个命令,比如脚本文件。 |
分类:登录 Shell 和非登录 Shell
| 类型名称 | 含义 |
|---|---|
| Shell 登录环境 | 需要用户名/密码登录的 Shell 环境 |
| Shell 非登录环境 | 不需要用户名/密码进入的 Shell 环境或执行脚本文件。 |
初始化加载流程

3、shell环境相关操作
识别 Shell 环境类型
echo $0 在命令行中使用,表示识别环境语法。
输出
-bash表示 shell 登陆环境输出
bash表示非登录环境
(在脚本文件中使用此命令,表示获取脚本文件名)
切换 shell 环境
-
直接登录系统:shell 登录环境变量
-
su 切换用户登录
-
su 用户名 -l:shell 登录环境变量 -
su 用户名:shell 非登录环境变量
-
-
bash 切换
-
bash -l 文件名:shell 登录环境变量 -
bash 文件名:shell 非登录环境变量
-
四、Shell 字符串变量
1、字符串的三种格式
# 1、单引号方式:原样输出,引号内部的变量不解析
VAR1='abc'
# 2、双引号方式:引号内部如果有变量${}就解析
VAR2="abc"
# 3、不使用引号的方式:值内部不能使用空格,可以解析内部变量
VAR3=abc
获取字符串的长度:${#字符串变量}
2、字符串拼接
VAR1=abc
VAR2="hello world"
# 1、无符号拼接
VAR3=${VAR1}${VAR2}
# 2、双引号拼接
VAR3="${VAR1}${VAR2}"
# 3、混合拼接
VAR3=${VAR1}'&'${VAR2}
VAR4="${VAR1} ${VAR2}" # 中间有个空格
echo you are beautiful ${VAR3}:这里中间的空格是被允许的
3、字符串截取
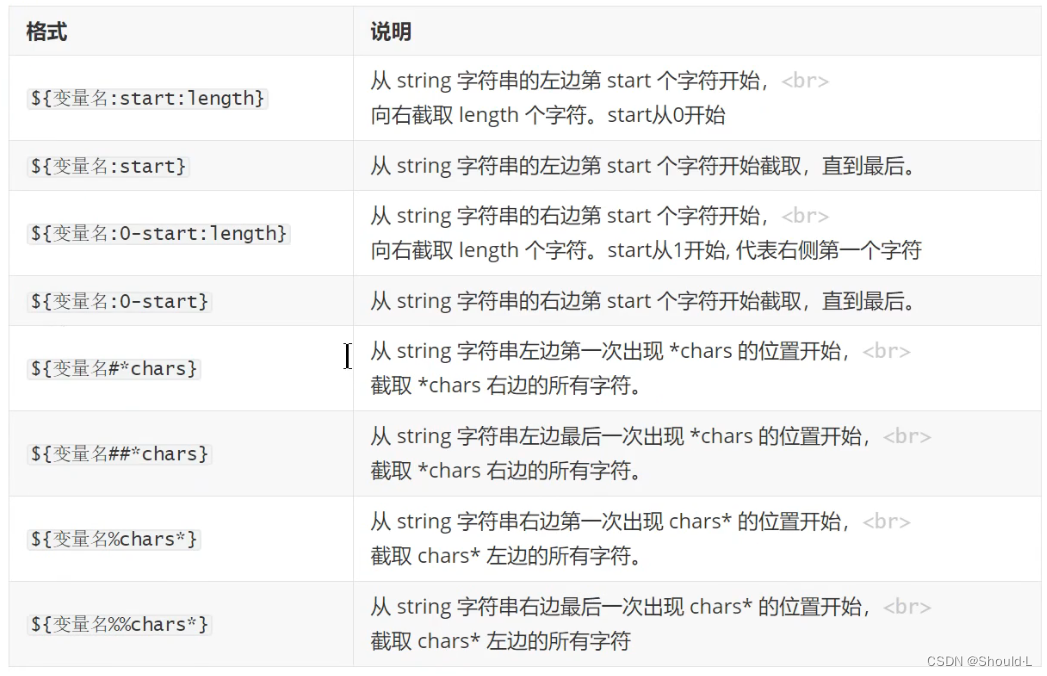
五、Shell 索引数组变量
-
Bash shell 只支持一维数组,不支持多维的。
定义:
array_name1=(item item ...) # 方式一 array_name2=([索引下标1]=item1 [索引下标2]=item2 ...) # 方式二 arr[3]=100 # 不定义直接赋值也能创建
获取数组
# 1、通过下标获取,必须使用{}
${arr[index]}
# 2、获取同时赋值给其他变量
item=${arr[index]}
# 3、获取数组的所有元素
$arr{@}
$arr{*}
# 4、获取数组的长度或个数
${#arr[@]}
${#arr[*]}
# 5、获取数组指定元素的字符长度
${#arr[索引]}
数组的拼接
使用@或者*获取数组所有元素后进行拼接
array_name=(${array1[@]} ${array2[@]} ...)
array_name=(${array1[*]} ${array2[*]} ...)
删除数组
unset array_name[index] # 删除数组的元素 unset array_name # 删除整个数组
(和删除变量的语法一样)
六、Shell 内置命令
Bash shell 自身提供的命令,而不是文件系统中的可执行文件。
使用 type 命令 来确定一个命令是否是内置命令。如果是脚本文件会返回文件路径。
内置命令比脚本文件执行的更快,因为脚本文件涉及IO操作。
1、alias 设置别名
用于给命令设置别名,给复杂命令改个简单的名字,提高工作效率。
alias # 显示当前环境中的别名列表 alias 别名="命令" # 定义别名 unalias 别名 # 删除别名(临时删除) unalias -a # 删除当前shell中的所有别名
2、echo 输出字符串
echo 字符串 # 默认输出换行字符串 echo -n 字符串 # 输出不换行字符串 echo -e '含有转义字符的字符串' # 输出字符串并解析转义字符
3、read 读取控制台输入
默认从终端控制台读取用户输入的数据,如果进行了重定向,那么可以从文件中读取数据。
read [-options] [var1 var2 ...] ## option 表示选项,var 表示用来存储数据的变量 ## option 和 var 都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY 中。 ## REPLY 保存 read 最后一个读入命令的数据。

三个read例子:
## 例1:输入多个变量
# --------- file1.sh -------------
#! /bin/bash
read -p "请输入姓名,年龄,爱好:" name age hobby
echo "姓名:${name}"
echo "年龄:${age}"
echo "爱好:${hobby}"
## 例2:读取一个字符
# --------- file2.sh -------------
#! /bin/bash
read -p "您确定要删除数据吗(请输入y/n):" -n 1 char
printf "\n"
echo "您输入的字符:${char}"
## 例3:限制时间输入
# --------- file3.sh -------------
#! /bin/bash
read -t 20 -sp "情输入密码(20秒内):" pwd1
echo
read -t 20 -sp "请再次输入密码(20秒内)" pwd2
printf "\n"
if [ $pwd1 == $pwd2]
then
echo "密码与验证密码一致,验证通过"
else
echo "密码与确认密码不一致,验证失败"
fi
4、exit 退出
用于退出当前 Shell 环境进程结束运行,并且可以返回一个状态码,一般使用 %? 可以获取退出状态码
exit # 默认返回状态码0,一般代表命令执行成功 exit 非零数字 # 数字范围0~255,一般代表命令执行失败
5、declare 设置变量属性
用于声明 Shell 变量,可用来声明变量并且设置变量的属性,也可用来显示 Shell 函数。
若不加任何参数,则会显示全部的 Shell 变量与函数(与执行 set 指令的效果相同)
# 设置变量属性 declare [+/-][aArxif][变量名=设置值]

6、declare 实现关联数组
关联数组也称键值对
declare -A 关联数组变量名=([字符串key1]=值1 [字符串key2]=值2 ...) # 创建普通索引数组 declare -a 关联数组变量名=(值1 值2 ...) declare -a 关联数组变量名=([0]=值1 [1]=值2 ...)
七、Shell 运算符
1、算数运算符
expr 命令
求职表达式,不但可以实现整数计算,还可以结合一些选项对字符串进行处理,例如计算字符串长度,字符串比较,字符串匹配,字符串提取等。
# 计算语法 expr 算数运算符表达式 # 获取结果并赋值 result=expr 算数运算表达式
算数运算符
+ - * / % =:加减乘除 取余 赋值
2、比较运算符
整数比较运算符

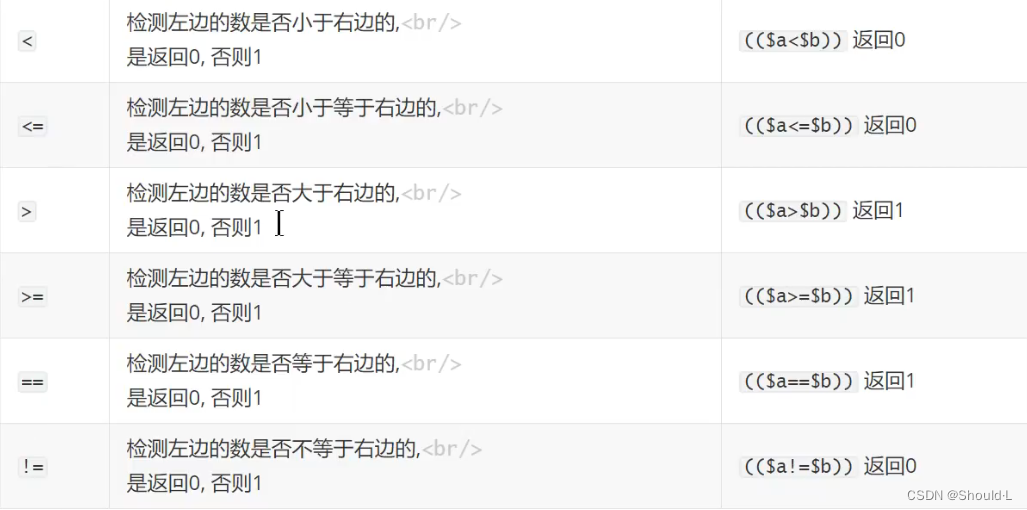
字符串比较运算符
字符串比较可以使用[[]]和[]两种方式
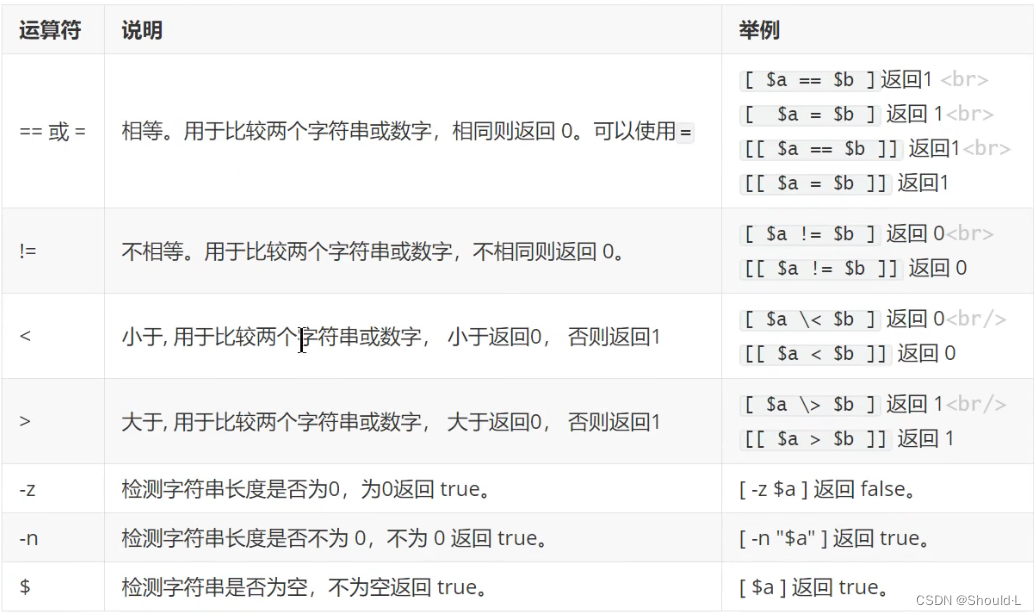
-
字符串比较没有
<=,可以通过[["a" < "b" && "a" = "b"]]实现
[[]] 和 [] 的区别
-
区别1:Word Splitting 的发生:将含有空格字符传进行分拆后进行比较。
-
[[]]不会有word spiltting 发生 -
[]有 word spiltting 发生
-
-
区别2:转义字符
-
单方括号内部的比较符需要转义,双方括号不需要。
-
3、布尔运算符
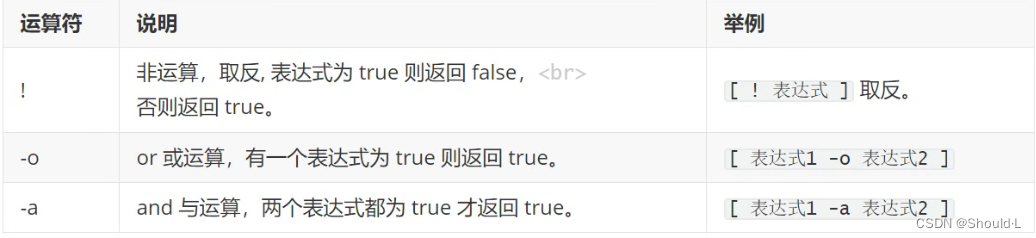
布尔运算符放在[]或与test命令配合使用才有效。
布尔运算符常与test命令配合使用。
4、逻辑运算符
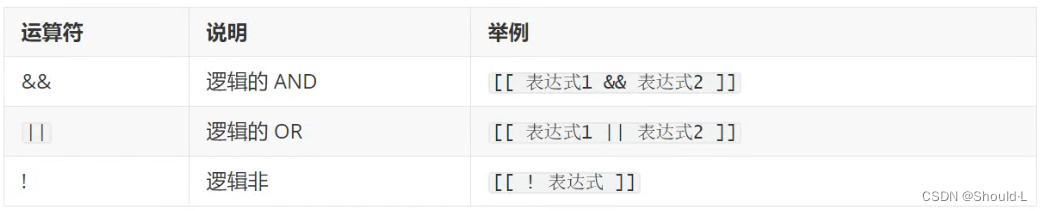
使用&&和||的运算符必须放在[[]]或(())中才有效,否则报错。
!可以用在[],[[]]中,不可用在(())
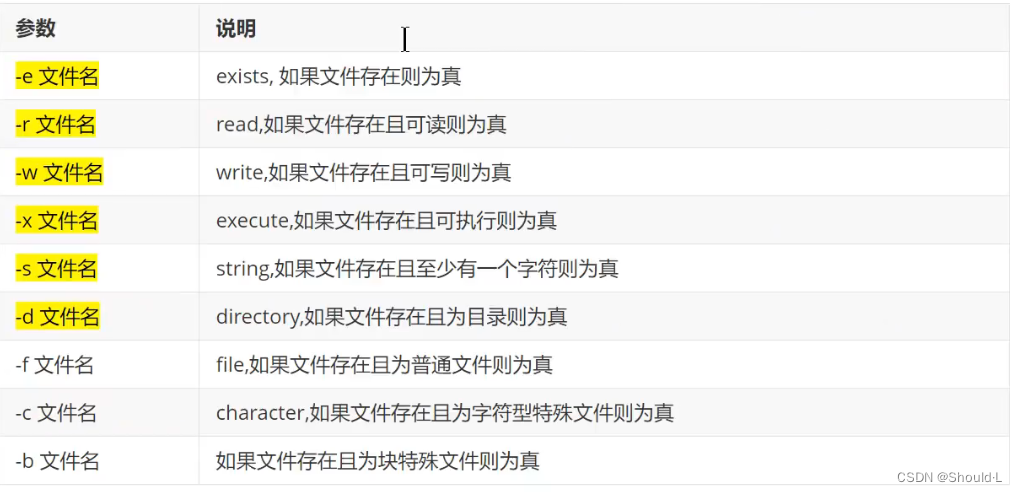
5、文件测试运算符
Linux 文件类型
-
-:普通文件
-
d:目录文件
-
l:链接文件
-
b:块设备文件(计算机硬盘)
-
c:字符设备文件(计算机的USB文件)
-
p:管道文件
文件检测运算符


举例
#!/bin/bash
file1="/root/operation1.sh"
file2="/root/operation2.sh"
# 检测文件是否可写
if [[-w $file1]]
then
echo "file1 文件可写"
else
echo "file1 文件不可写"
fi
八、Shell 的计算命令
1、expr 命令
表达式求值
见第七章第1节。
字符串语法
# 计算字符串长度 expr length 字符串 # 截取字符串 expr substr 字符串 start end # 获取第一个字符在字符串中出现的位置 expr index 被查找字符串,需要查找的字符 # 正则表达式匹配1,返回匹配字符的长度,否则返回0 expr match 字符串 正则表达式 # 正则表达式匹配2 expr 字符串 : 正则表达式
-
可以直接输出
-
计算表达式里面引用变量使用$,特殊字符需要转义,只能计算一个表达式。
2、(()) 命令
用来进行整数计算。

3、let 命令
进行整数运算,没有(())命令强大,let只能用于赋值运算,不能直接输出,不可以和条件判断一起使用。
let 赋值表达式
-
语法功能等价于
(()) -
多个表达式之间使用空格
-
对于类似
let a+b这样的写法,shell尽管计算了a+b但是却把结果丢弃了,如果echo let a+b会直接输出字符串a+b;若不想这样,可以使用let sum=a+bj将a+b的结果保存在变量sum中。
举例
#!/bin/bash
# 计算变量a-1赋值给变量b
let a=1+6
let b=a-1
# 计算变量a+变量b赋值给变量c
let c=a+b
# 打印所有变量
echo "a=${a},b=${b},c=${c}"
# 多个表达式计算赋值
let a=1+6 b=a-1 c=a+b
4、$[] 命令
只能进行整数运算,只能对单个表达式的计算进行输出。
$[表达式]
-
对表达式进行计算,并取得计算结果
-
表达式内部不可以赋值给变量。
举例
echo "$[1+6],$[a-1],$[a+b]"
5、bc 命令
Shell 内置了整数运算,但是不支持浮点运算,bc命令可以很方便的进行浮点运算,还能进行进制转换与计算。
bc [option] [参数]
options
| 选项 | 说明 |
|---|---|
| -l | 使用标准数学库 mathlib |
| -i | 强制交互 |
| -w | 显示 POSIX 的警告信息 |
| -s | 使用 POSIX 标准来处理 |
| -q | 不显示欢迎信息(一般有很多欢迎信息) |
内置变量
| 变量名 | 作用 |
|---|---|
| scale | 指定精度 |
| ibase | 指定输入数字的进制,默认十进制 |
| obase | 指定输出数字的进制,默认十进制 |
| last 或者 . | 获取最近计算打印结果的数字 |
内置数学函数
| 函数名 | 作用 |
|---|---|
| s(x) | 计算x的正弦值,返回弧度 |
| c(x) | 计算余弦值,返回弧度 |
| a(x) | 计算反正切,返回弧度 |
| e(x) | 求e的x次方 |
| l(x) | 计算x的自然对数 |
| j(n,x) | 贝塞尔函数,计算从n到x的阶数 |
示例:shell 非互动式的管道运算
# 直接进行bc表达式计算输出 echo "expression" | bc [options] # 将 bc 结果赋值给 shell 变量 var_name=`echo "expression" | bc [options]` # 或者 var_name=(echo "expression" | bc [options])
-
expression 必须符合 bc 命令要求的公式,里面可以引用shell 变量
Shell 非互动式的输入重定向运算
将计算表达式输出给bc去执行,类似于文件输入,可以输入多行表达式
# 第一行反引号结束先不写 var_name=`bc [options] << EOF 第一行表达式 第二行表达式 ... EOF ` # 第二种方式 var_name=$(bc [options] << EOF 第一行表达式 第二行表达式 ... EOF )
-
var_name:是变量的名字
-
bc:执行 bc 的命令
-
EOF...EOF:是输入流的多行表达式
-
最后拼接成字符串返回var_name
九、流程控制语句
1、if else 语句
# 多行表达式
if 条件1
then
命令1
elif 条件2
then
命令2
else
命令3
fi
# 写成一行
if 条件; then 命令; fi
if 条件判断句的退出状态
Linux 中任何命令的执行都有一个退出状态码,无论是内部命令还是外部文件命令,当它退出的时候,都会返回一个比较小的整数值给调用它的程序,这就是命令的退出状态。
大多数命令状态0代表成功,非0代表失败。
通过$?取得命令的退出状态。
if 语句就是通过状态码来判断是否满足条件的。
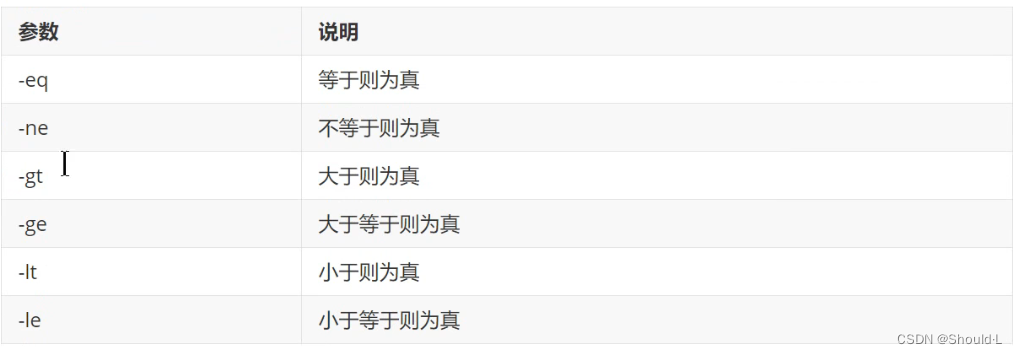
2、test 命令
用于检测某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
功能与[]一样(详见第七章第二节的比较运算符:整数比较、文件比较、字符串比较都用到方括号了)
整数比较
if test 数字1 [options] 数字2 then ... fi
[options] 见下表:
字符串比较

文件测试
3、case 语句
多分支条件判断
case 值 in
匹配模式1)
命令1
命令2
...
;;
匹配模式2)
命令1
命令2
...
;;
*)
命令1
命令2
...
;;
esac
每一个匹配模式必须以右括号结束,取值可以为变量或常数。
简单正则表达式支持如下通配符:

举例
#!/bin/bash
# 接收用户输出数字,根据数字范围输出。
read -p "请输入一个0-7的数字: " number
case number in
1)
echo "星期一"
;;
2)
echo "星期二"
;;
...... # 不写了,太累
0|7) # 正则表达式
echo "星期日"
;;
*)
;;
esac
4、while 语句
# 多行写法
while 条件
do
命令1
命令2
...
# 特殊跳出关键字
continue;
break;
done
# 一行写法
while 条件; do 命令; done;
# 无限循环
while
do
command
done
# 或者
while true
do
command
done
5、until 语句
与while循环在处理方式上正好相反,循环条件为false会一直循环。
until 条件
do
命令
done
条件如果返回值为1(表示false),则继续执行循环体内的语句。
6、for 循环
方式1
# 多行写法 for var in item1 item2 ... itemN do 命令1 命令2 ... done
方式2
for var in {start..end}
do
命令
done
方式3
for ((i=start;i<=end;i++))
do
命令
done
无限循环
for((;;)); do 命令; done
7、select 语句
用来增强交互性,它可以显示出带编号的菜单,用户可以输入不同的编号选择不同的菜单,并执行不同的功能,是Shell 独有的循环,非常适合终端这样的交互场景。
select var in menu1 menu2 ...
do
命令
done
-
select 是死循环,输入空值或者输入的值无效,都不会结束循环,只有遇到
break或者按下Ctrl+D才能结束循环
举例
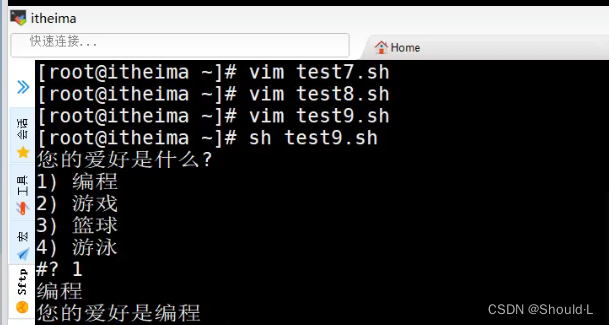
#!/bin/bash
echo “您的爱好是什么?”
select hobby in "编程" "游戏" "篮球" "游泳"
do
echo $hobby
break
done
echo "您的爱好是${bohhy}"
十、Shell 函数
1、系统函数
系统自带的函数,直接用。
basename 函数
用于获取文件名的函数,根据给出的文件路径截取文件名
basename [string/pathname] [suffix] # [string/pathname]:文件路径 # [suffix]:后缀名,如果写上此参数就是去掉后缀名输出文件名
dirname 函数
从指定的文件绝对路径,去除文件名,返回剩下的前缀目录路径
dirname 文件的绝对路径
补充
# 查看所有的函数,有内部实现 declare -f # 查看使用declare定义的函数列表 declare -F
2、自定义函数
# 函数的定义
[ function ] funname ()
{
命令
[return 返回值]
}
# 函数调用
funname [参数]
-
function可以不写。 -
return可以不写,如果不写将以最后一条命令运行结果作为返回值,return后跟数值 0~255 -
要保证定义函数写在前,调用函数写在后
举例
#!/bin/bash
# (1)无参无返回值函数
demo()
{
echo "执行了函数"
}
# (2)无参有返回值函数
sum()
{
echo "---求两个数的和---"
read -p "请输入第一个数字:" n1
read -p "请输入第二个数字:" n2
echo "两个数字分别是 $n1 和 $n2"
return $(($n1+$n2))
}
# 调用
demo
sum
echo "两个数的和为:$?"
有参函数
如何传递参数到函数体内

#!/bin/bash
funParam()
{
echo "第一个参数为:$1 !"
echo "参数总数为:$# 个"
}
# 调用
funParam 1 2 3 4 5
shell 程序和函数的区别
-
shell 命令(内置命令和外部脚本文件)在子shell 中运行,会开启独立的进程运行
-
shell 函数在当前shell 的进程中运行
十一、Shell 重定向
1、输出输出重定向
标准输入与标准输出
-
标准输入:从键盘读取用户输入的数据,然后再读进shell程序中使用。
-
标准输出:shell程序产生的数据,这些数据一般是呈现到显示器上。
默认输入输出文件
每个Unix/Linux 命令运行时都会打开三个文件
| 文件名 | 类型 | 文件描述符fd | 功能 |
|---|---|---|---|
| stdlin | 标准输入文件 | 0 | 获取键盘的输入数据 |
| stdout | 标准输出文件 | 1 | 将正确数据输出到显示器上 |
| stderr | 标准错误输出文件 | 2 | 将错误信息输出到显示器上 |
重定向输入输出
-
标准输入是数据默认从键盘流向程序,如果改变了它的方向,数据就从其他地方流入,这就是输入重定向
-
标准输出是数据默认从程序流向显示器,如果改变了它的方向,数据就流向其他地方,这就是输出重定向。
重定向的作用
输出重定向是指命令的结果不再输出到显示器上,而是输出到其他地方,一般是文件中,这样做的最大好处是把命令的结果保存下来,当我们需要的时候可以随时查询。
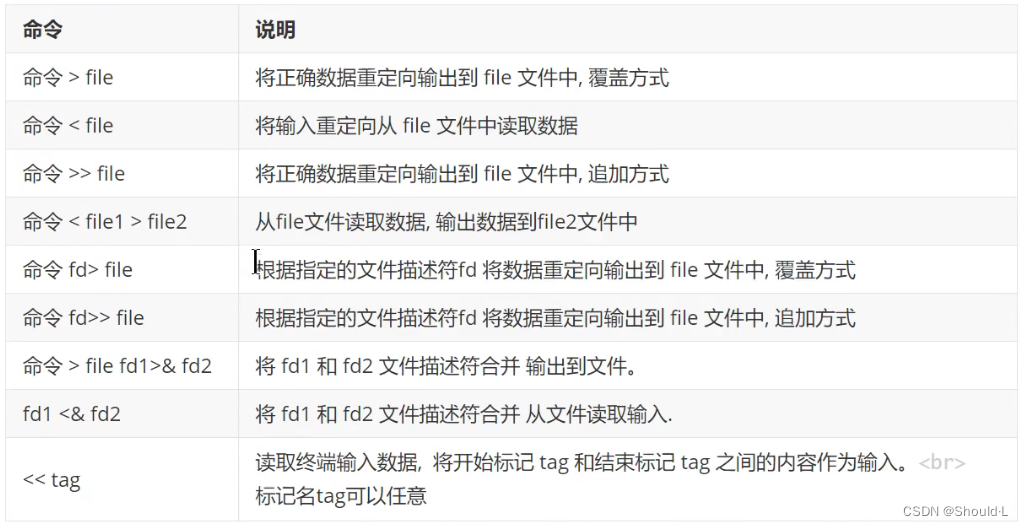
重定向语法
-
>代表的是覆盖输出,>>代表的是追加输出。 -
fd是文件描述符,fd>>中间不可有空格
2、wc 命令
用来对文本进行统计,包括单词个数、行数、字节数
wc [options] [文件名]
options:
| 选项 | 含义 |
|---|---|
| -c | 统计字节数 |
| -w | 统计单词数 |
| -l | 统计行数 |
举例
# 统计行数
wc -l < demo.txt
# 按行读取文件的数据
while read str; do echo "$str"; done < log.txt
# 按行读取并在每行开头输出行号
rownu=1; while read str; do echo "第${rownu}行: $str"; let rownu++; done < log.txt
# 统计从终端标记开始到标记结束之间的行数
wc -l << EOF
aa
bb
cc
dd
EOF
# 输出4
Shell 好用的工具
1、cut
可以切割提取指定列\字符\字节的数据
cut [options] filename
[options]:
| 选项参数 | 功能 |
|---|---|
| -f 提取范围 | 列号,获取第几列 |
| -d 自定义分隔符 | 自定义分隔符,默认为制表符 |
| -c 提取范围 | 以字符为单位进行分割 |
| -b 提取范围 | 以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志 |
| -n | 与 -b 连用,不分割多字节字符 |
提取范围说明:
| 提取范围 | 说明 |
|---|---|
| n- | 提取指定第n列/字符/字节后面所有数据 |
| n-m | 提取指定第n列/字符/字节到第m列/字符/字节中间的所有数据 |
| -m | 提取指定第m列或字符或字节前面所有数据 |
| n1,n2,... | 提前指定枚举类的所有数据 |
切割提取指定的单词
# 从文件中切割出指定关键词itheima # 先锁定文件中的特定行,再切割 cat cut.txt | grep itheima | cut -d " " -f 2
切割提取bash进程的PID号
# 先找进程列表,再拿出对应的行,再切出来 ps -aux | grep bash | head -n 1 | cut -d " " -f 8
切割提取IP地址
ifconfig | grep broadcast | cut -d " " -f 10
2、sed
流编辑器,是Linux下一款功能强大的非交互流式文本编辑器(vim是交互式),可以对文本文件的每一行数据匹配查询之后进行增、删、改、查等操作,支持按行、按字段、按正则匹配文本内容,灵活方便、特别适合于大文件的编辑。
它一次处理一行内容,将这行放入缓冲,然后才对这行进行处理,处理完后,将缓存区的内容发送到终端。
语法
sed [选项参数] [模式匹配/sed程序命令] [文件名] # 模式匹配,sed会读取每一行数据到模式空间中,之后判断当前行是否符合模式匹配要求,符合要求就会执行sed命令,否则就不执行;如果过不写匹配模式,那么每一行都会执行sed程序命令。
选项参数:

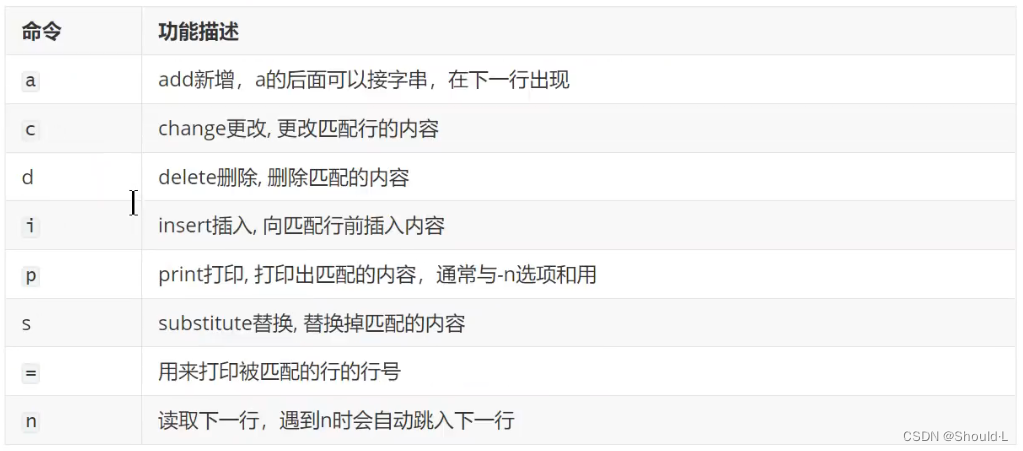
sed 程序命令功能描述:
特殊符号:
| 命令 | 功能描述 |
|---|---|
| ! | 取反 |
| {sed 命令1;sed 命令2} | 多个命令操作同一个的行 |
(1)增加
# 指定行号前后添加数据(只是预览,并不是修改源文件) sed 'abc123' file.txt # 指定行号前后添加数据(添加,并修改源文件) sed -i 'abc123' file.txt # 在itheima的前面插入hello(i表示前面插入) sed '/itheima/ihello' file.txt # 在itheima的后面插入数据 sed '/itheima/ahello' file.txt # 在最后一行添加数据 sed '$ahello' file.txt # 在最后一行前面添加数据 sed '$ihello' file.txt
(2)删除
# 删除第二行 sed '2d' file.txt # 删除奇数行(从第一行开始每隔两行删除) sed '1~2d' # 删除指定范围的多行数据(1到3行) sed '1,3d' file.txt # 删除指定范围取反的多行数据 sed '1,3!d' file.txt # 删除最后一行 sed '$d' file.txt # 删除匹配itheima的行 sed '/itheima/d' file.txt # 删除匹配行到最后一行 sed '/itheima/,$d' file.txt # 删除匹配及其后面一行 sed '/itheima/,+1d' file.txt # 删除不匹配的行('|'需要转义) sed '/itheima\|itcast/!d' file.txt
(3)修改
# 将文件第一行修改为hello sed '1chello' file.txt # 将包含itheima的行修改为hello sed '/itheima/chello' file.txt # 将最后一行修改为hello sed '$chello' file.txt # 将文件中的itheima替换为hello(默认只替换每行第一个itheima) sed 's/itheima/hello/' file.txt # 将文件中的itheima替换为hello(全局匹配替换) sed 's/itheima/hello/g' file.txt # 将每行中第二个匹配替换 sed '/itheima/hello/2' file.txt # 替换后的内容写入新文件 sed '/itheima/hello/2w file2.txt' file.txt # 替换后的内容写入新文件,并只打印输出修改过的行 sed -n '/itheima/hello/2pw file2.txt' file.txt # 正则表达式匹配计算 # 匹配有i的行,替换t后面所有的内容,替换成空 sed '/i/s/t.*//' file.txt # 每行末尾拼接test # s替换 $结尾 &拼接 sed 's/$/& test/' file.txt # 每行行首添加注释'#' sed 's/^/&#/' file.txt
查询
# 查询含有itcast的行数据(-n和p成对出现) sed -n '/itcast/p' file.txt # 管道过滤查询:查询含有sshd的命令 # 这里使用 grep 会更强大一点,sed 编辑的能力更强一点 ps -aux | sed -n '/sshd/p' # 多个sed命令执行:将file.txt第一行删除并将itheima替换为itcast # -e 表示后面是单条命令 sed -e '1d' -e 's/itheima/itcast/g' file.txt # 单引号全括起来,中间用分号隔开 sed '1d; s/itheima/itcast/g' file.txt
sed 高级用法:缓存区数据交换
模式空间与暂存空间
-
sed 处理文件是逐行处理的,即读取一行输出一行
-
sed 把文件读出来,每一行存放的空间叫模式空间,会在该空间中对读到的内容做相应处理,最终显示的都是模式空间的数据
-
此外 sed 还有一个额外的空间即暂存空间,暂存空间刚开始里面只有个空行,记住这一点
-
sed 可以使用相应的命令从模式空间往暂存空间放入内容或从暂存空间取内容放入模式空间。
2个缓存空间传输数据的目的是为了更好的处理数据。
关于缓存区 sed 程度命令

示例
# 第一行粘贴到最后一行:
# 将模式空间第一行复制到暂存空间(覆盖方式),并将暂存空间的内容复制到模式空间中的最后一行(追加方式)
sed '1h;$G' file.txt
# 第一行删除后粘贴到最后一行(对同一行多次操作用大括号)
sed '1{h;d};$G' file.txt
# 第一行数据复制后粘贴替换其他行数据:
# 模式空间覆盖到暂存空间,然后将暂存空间替换模式空间第2行到最后一行
sed '1h;2,$g' file.txt
# 将前三行数据复制粘贴到最后一行
# 将前三行数据追加复制到暂存空间,将暂存空间的所有内容追加复制到模式空间最后一行
sed '1,3H;$G' file.txt
# 给每一行添加空行(-i 表示永久修改文件)
sed -i 'G' file.txt
# 删除文件里面的空行
# '/^$/'表示从开头到结尾中间啥也没有
sed -i '/^$/d' file.txt
3、awk
强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。
简单来说 awk 就是把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理,因为切开的部分使用 awk 可以定义变量,运算符,使用流程控制语句进行深度加工与分析。
语法
awk [options] 'pattern{action}' {filenames}
# [options] 选项参数
# pattern{action} 表示找到匹配内容时所执行的一系列命令
选项参数说明:
| 选项参数 | 功能 |
|---|---|
| -F | 指定输入文件拆分分隔符,默认空格 |
| -v | 赋值一个用户定义变量 |
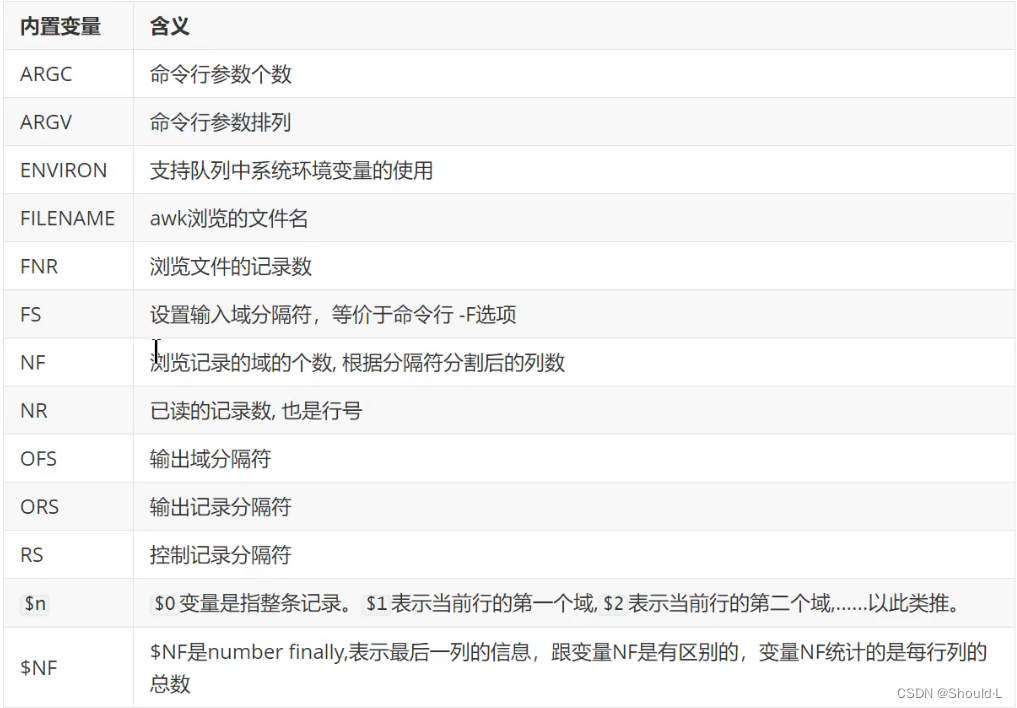
awk 内置变量
示例
# 默认每行空格切割数据(把空格切开都换成'&')
echo "abc 123 456" | awk '{print $1"&"$2"&"$3}'
# 搜索文件中有root关键字的所有行,打印
awk '/root/{print $0}' file.txt
# 在上一条的基础上,以:拆分并打印匹配行中第7列数据
awk -F ":" '/root/{print $7}' file.txt
# 打印文件每行属性信息(文件名,行号,每行列数,对应行内容)
awk -F: '{print "文件名:" FILENAME ",行号:" NR ",列数:" NF ",内容:" $0}' file.txt
# 拼接字符串(更好的方式)
awk -F '{printf ("文件名:%s,行号:%s,列数:%s,内容:%s/n",FILENAME,NR,NF,$0)}' file.txt
# 打印第二行信息
awk -F ":" 'NR==2{printf("filename:%s,内容:%s",FILENAME,$0)}' file.txt
# 查找以c开头的资源
ls -a |awk '/^c/'
# 打印第一列
awk -F: '{print $1}' file.txt
# 打印最后一列
awk -F: '{print $NF}' file.txt
# 打印倒数第二列
awk -F: '{print $(NF-1)' file.txt
# 打印10到20行的第一列
awk -F: '{if(NR>=10 && NR<=20){print $1}}' file.txt
# 多分隔符使用
echo "one:two/three" | awk -F "[:/]" '{$1"&"$2"&"$3}'
# 添加开始与结束内容(-e 多行显示)
echo -e "abc\nabc" | awk 'BEGIN{print "开始..."}{print $0}END{print "结束..."}'
# 拼接分割后的字符串(多个连续空格也都能识别为一个分割)
echo "abc ithema itcast" | awk '{print $1"&"$2"&"$3}'
# 使用循环拼接
echo "abc ithema itcast" | awk -v str="" '{for(n=1;n<=NF;n++) {str=str$n}} END{print str}'
# 操作指定数字运算
echo "2.1" | awk -v i=1 '{print $0+i}'
# 切割ip
# 匹配broadcast并输出这一行
ifconfig | awk '/broadcast/{print $0}' | awk '{print $2}'
# 显示空行行号
sed 'G' file.txt | awk '/^$/{print NR}'
文本操作四剑客区别
-
grep 用于查找匹配行
-
cut 截取数据,截取某个文件的列,按照列分隔,这个命令不适合截取文件中有多个空白字符的字段
-
sed 增删改查数据,用于在文件中以行来截取进行编辑
-
awk 截取分析数据,可以在某个文件中是以竖列来截取分析数据,如果字段之间含有很多空白字符也可以获取需要的数据。
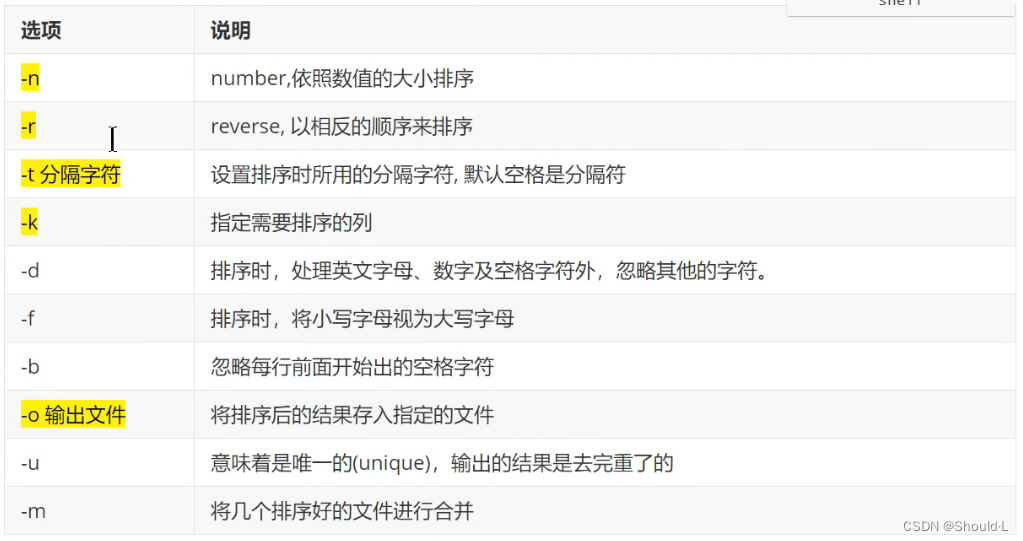
4、sort
排序,并将结果标准输出或重定向输出到指定文件
sort [options] 参数
选项说明:
示例
# ------ file.txt ------ # 张三 30 # 李四 95 # 波仔 85 # 波仔 85 # 波仔 86 # AA 85 # 波妞 100 # ------ ------ ------ -- # 第二列升序(n表示数字类型) sort -t " " -k2n,2 file.txt # 升序,去重(-u,两行一起匹配去重) sort -t " " -k2n,2 -uk1,2 file.txt # 升序,去重,保存 sort -t " " -k2n,2 -uk1,2 -o file2.txt file.txt # 降序 sort -t " " -k2nr,2 file.txt # ------ file3.txt ------ # 公司A,部门A,3 # 公司A,部门B,0 # ... # ----------------------- # 以','分割,先对第1列升序,再对第3列降序 sort -t "," -k1,1 -k3nr,3 file3.txt















 5238
5238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









