







数据结构十大经典算法
本篇参考以下三位博主写的博文
1、算法学习总结(2)——温故十大经典排序算法
2、排序算法整合(冒泡,快速,希尔,拓扑,归并)
3、史上最容易理解的《十大经典算法(动态图展示)》而整理出的一篇,可谓是集精华于一身的鸿篇巨制哈哈哈(开玩笑),还是乖乖学习吧
♡
\color{red}{\heartsuit}
♡
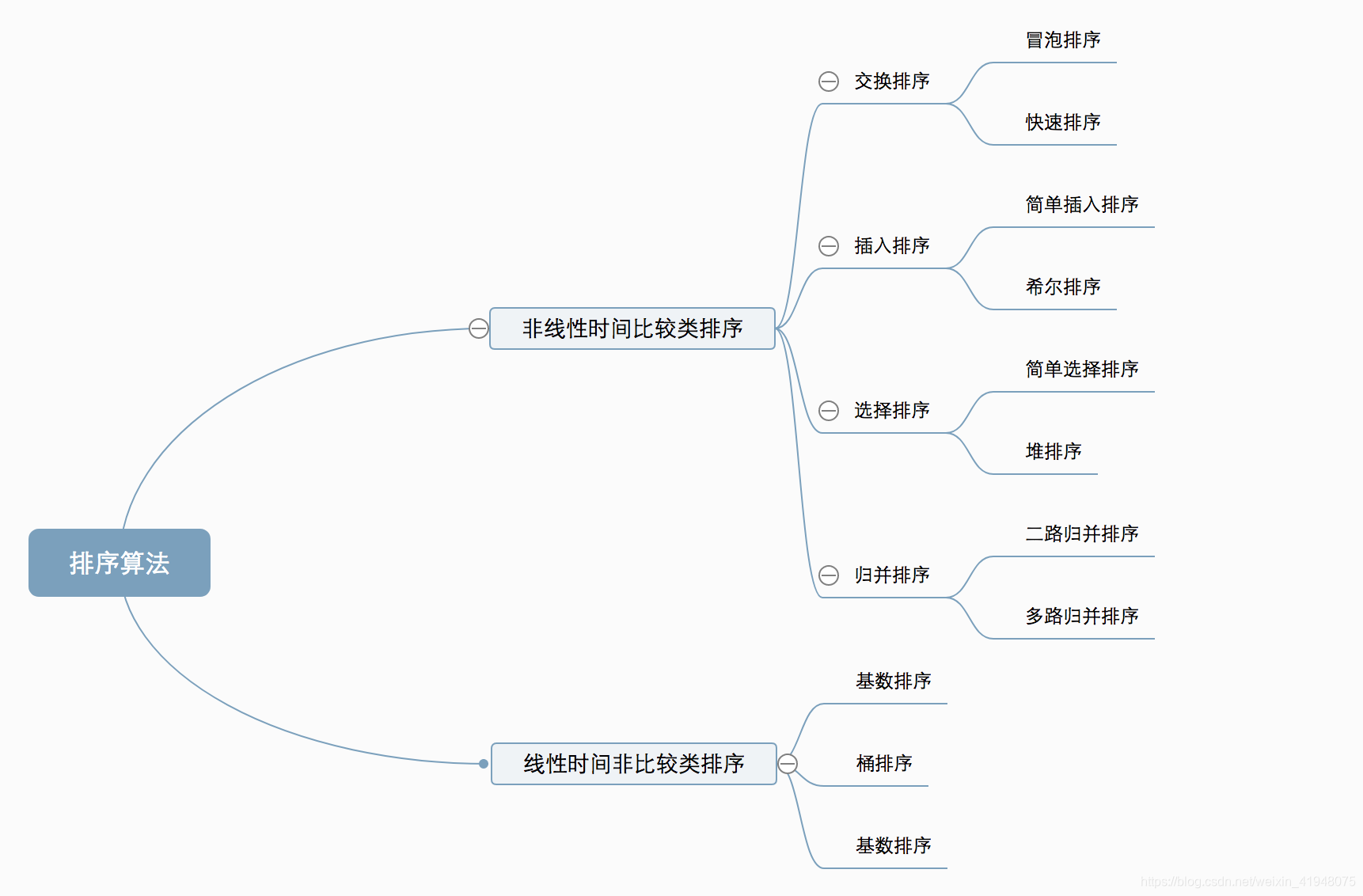
一、算法的分类
二、术语说明
♢
\color{red}{\diamondsuit}
♢稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
♢
\color{blue}{\diamondsuit}
♢不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
♢
\color{green}{\diamondsuit}
♢内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
♢
\color{grey}{\diamondsuit}
♢时间复杂度: 一个算法执行所耗费的时间。
♢
\color{purple}{\diamondsuit}
♢空间复杂度:运行完一个程序所需内存的大小。
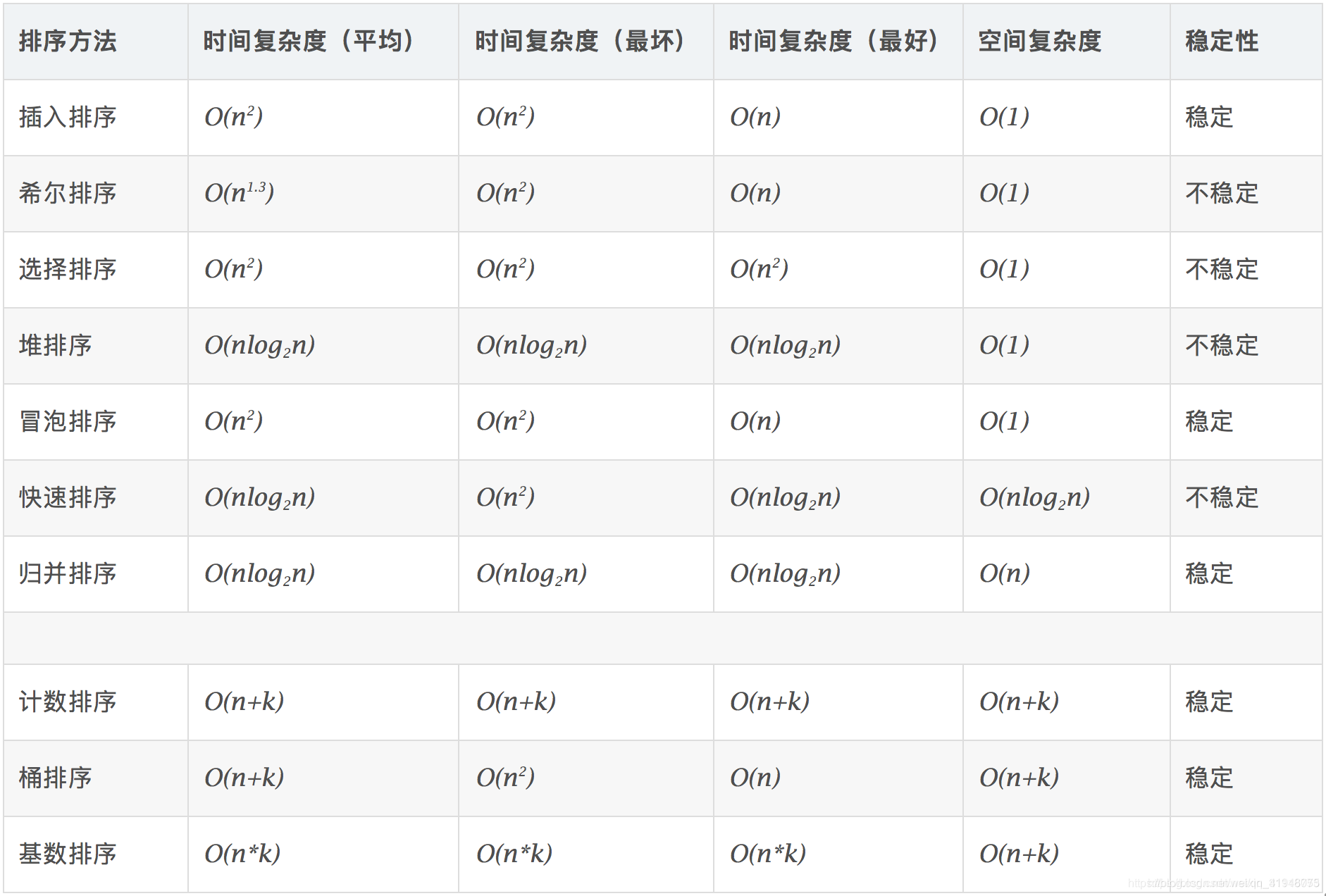
三、时间复杂度
♠
\color{pink}{\spadesuit}
♠
四、交换排序
1、冒泡排序
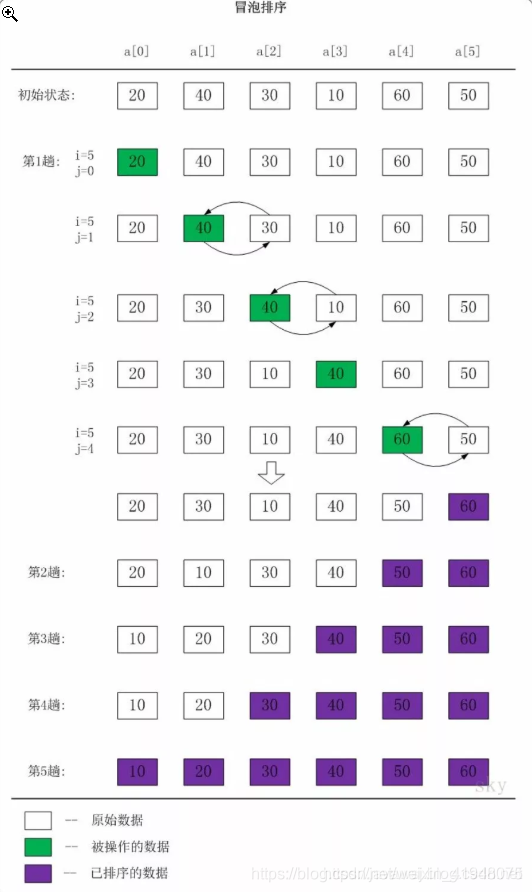
冒泡排序是一种简单的排序算法。它会遍历若干次要排序的数列,每次遍历时,它都会从前往后依次比较相邻两个数的大小;如果前者比后者大,则交换它们的位置。这样,一次遍历之后,最大的元素就在数列的末尾! 采用相同的方法再次遍历时,第二大的元素就被排列在最大元素之前。重复此操作,直到整个数列都有序为止!
算法描述
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个;
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素就是最大的数;
- 针对所有的元素重复以上的步骤,除了最后一个;
- 重复步骤1~3,直到排序完成。
静态图演示
动态图演示
冒泡排序算法分析
最佳情况:T(n) = O(n) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
2、快速排序
快速排序(Quick Sort)使用分治法策略。
它的基本思想是:在数据序列中选择一个元素作为基准值,每躺从数据序列的两端开始交替进行,将小于基准值元素交换到序列前端,将大于基准值的元素交换到序列后端,介于两者之间的位置则成为基准值的最终位置。同时,序列被划分成两个子序列,再分别对两个子序列进行快速排序,直到子序列长度为1,则完成排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
静态图展示

动态图演示
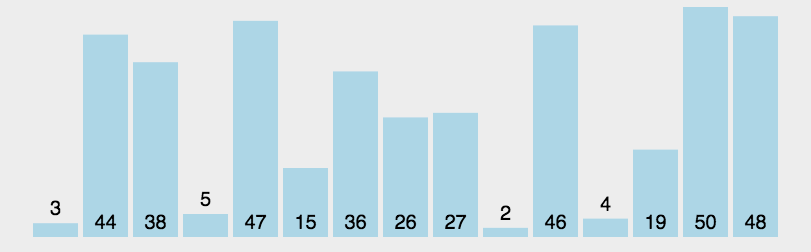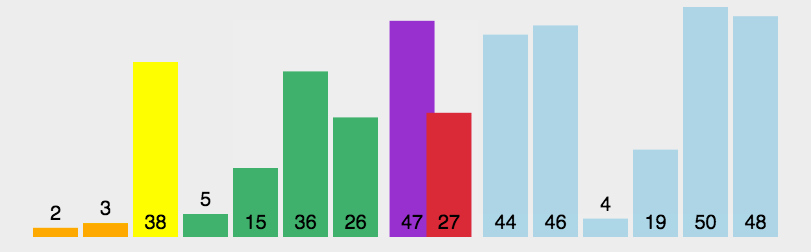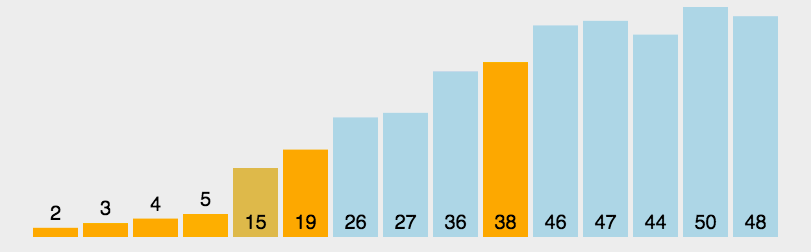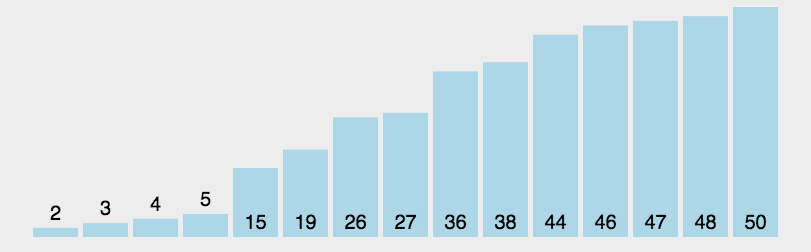
快速排序算法分析
最佳情况:T(n) = O(nlogn) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(nlog2n)
♢
\color{red}{\diamondsuit}
♢
五、插入排序
3、插入排序(Insertion Sort)
直接插入排序(Straight Insertion Sort)的基本思想是:把n个待排序的元素看成是一个有序表和一个无序表。开始时有序表中只包含1个元素,无序表中包含有n-1个元素,排序过程中每次从无序表中取出第一个元素,将它插入到有序表中的适当位置,使之成为新的有序表,重复n-1次可完成排序过程。
算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序;
- 取出下一个元素,在已经排序的元素序列中从后向前扫描;
- 如果该元素(已排序)大于新元素,将该元素移到下一位置;
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置;
- 将新元素插入到该位置后;
- 重复步骤2~5。
静态图演示
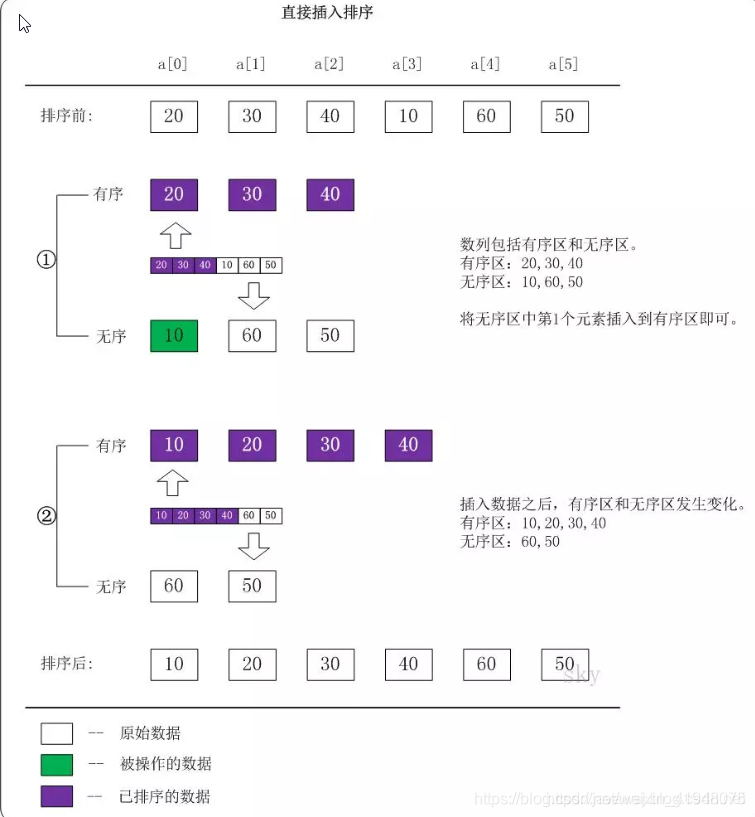
动态图演示
插入排序算法分析
最佳情况:T(n) = O(n) 最坏情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
4、希尔排序(Shell Sort)
1959年Shell发明,第一个突破O(n^2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔(Shell)排序又称为缩小增量排序,该方法因DL.Shell于1959年提出而得名。
希尔排序的基本思想是:
- 把记录按步长 gap 分组,对每组记录采用直接插入排序方法进行排序。
- 随着步长逐渐减小,所分成的组包含的记录越来越多,当步长的值减小到 1 时,整个数据合成为一组,构成一组有序记录,则完成排序。
我们先通过静态的演示图,更深入的理解一下这个过程。
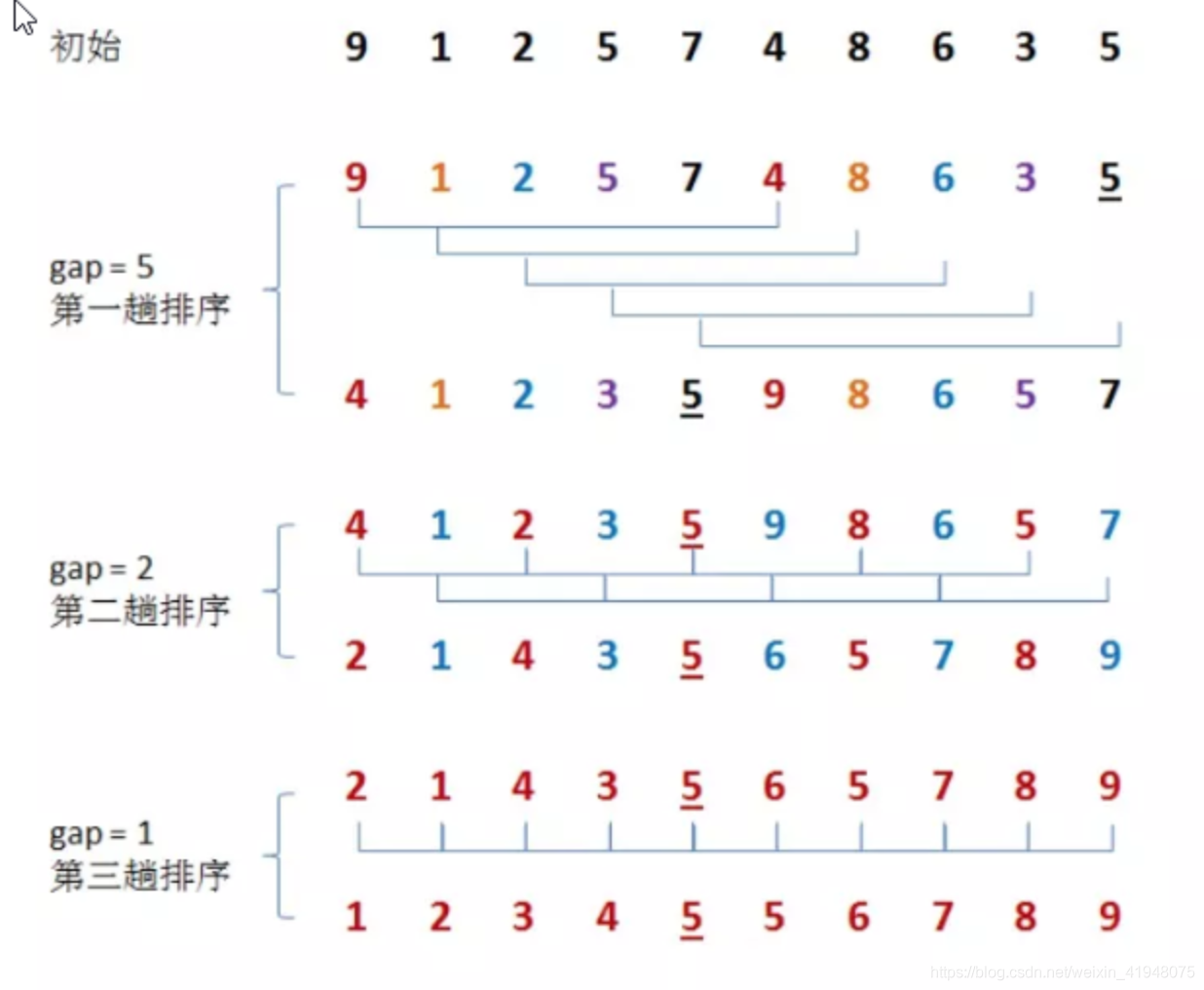
在上面这幅图中:
初始时,有一个大小为 10 的无序序列。
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。按照直接插入排序的方法对每个组进行排序。
在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
需要注意一下的是,图中有两个相等数值的元素 5 和 5 。我们可以清楚的看到,在排序过程中,两个元素位置交换了。
所以,希尔排序是不稳定的算法。
动态图演示
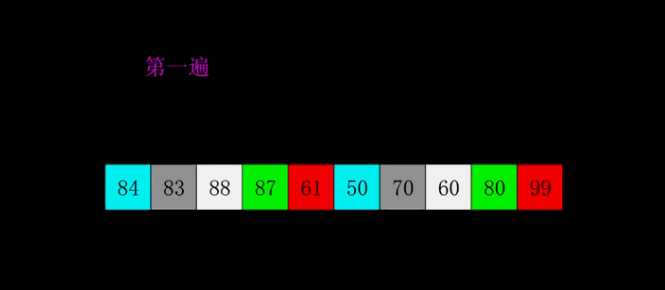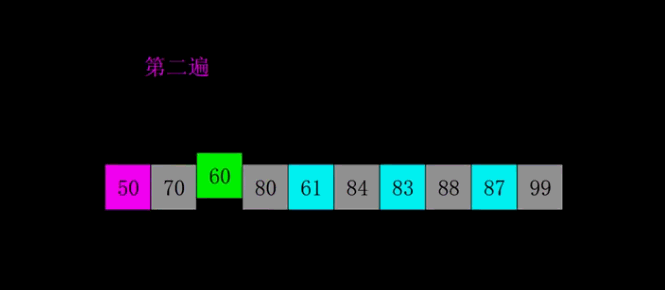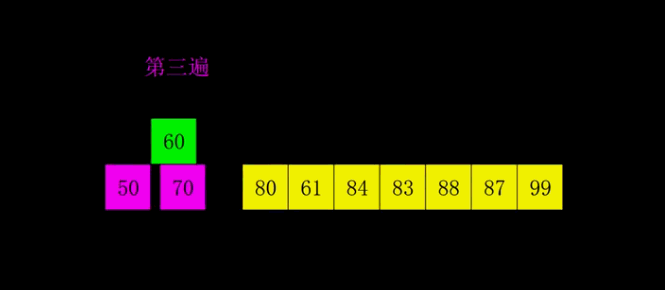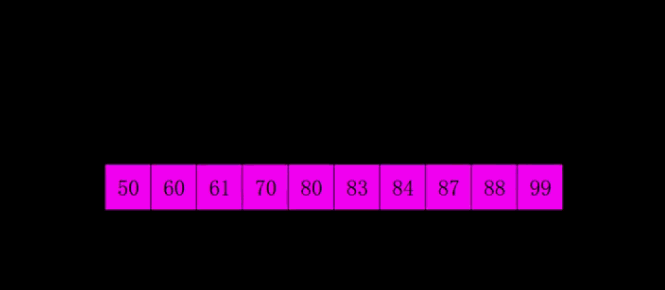
希尔排序算法分析
最佳情况:T(n) = O(nlog2n) 最坏情况:T(n) = O(nlog2n) 平均情况:T(n) =O(nlog2n)
♣
\color{red}{\clubsuit}
♣
六、选择排序
5、选择排序
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
算法描述
n个记录的直接选择排序可经过n-1趟直接选择排序得到有序结果。具体算法描述如下:
- 初始状态:无序区为R[1…n],有序区为空;
- 第i趟排序(i=1,2,3…n-1)开始时,当前有序区和无序区分别为R[1…i-1]和R(i…n)。该趟排序从当前无序区中-选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1…i]和R[i+1…n)分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区;
- n-1趟结束,数组有序化了。
动态图演示
选择排序算法分析
最佳情况:T(n) = O(n2) 最差情况:T(n) = O(n2) 平均情况:T(n) = O(n2)
6、堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
最小/大堆用于求最小/大值,堆序列用于多次求极值的应用问题。
算法描述
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
动态图演示

堆排序算法分析
最佳情况:T(n) = O(nlog2n) 最差情况:T(n) = O(nlog2n) 平均情况:T(n) = O(nlog2n)
直接选择排序算法有两个缺点:选择最小值效率低,必须遍历子序列,比较了所有元素后才能选出最小值,每躺将最小值交换到前面,其余元素原地不动,下一趟没有利用前一躺的比较结果,需要再次比较这些元素,重复比较很多。
堆排序改进了直接选择排序,采用最小/最大堆选择最小/最大值
♡
\color{red}{\heartsuit}
♡
七、归并排序
7、归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
算法描述
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
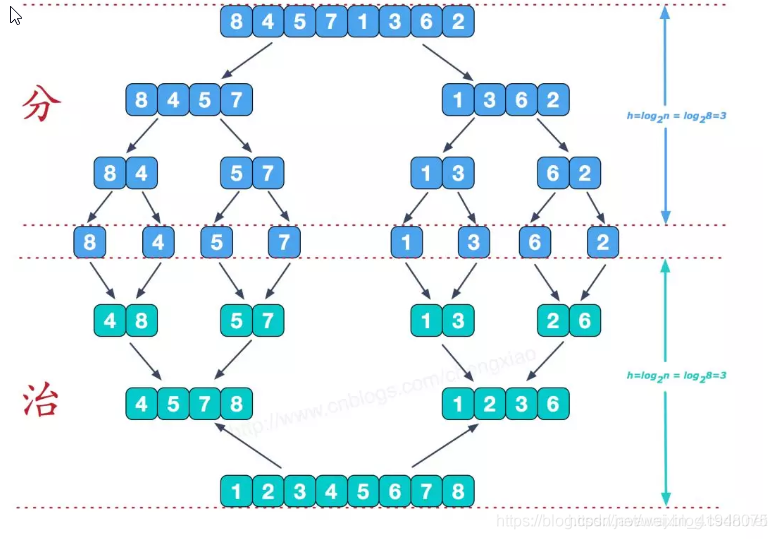
可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
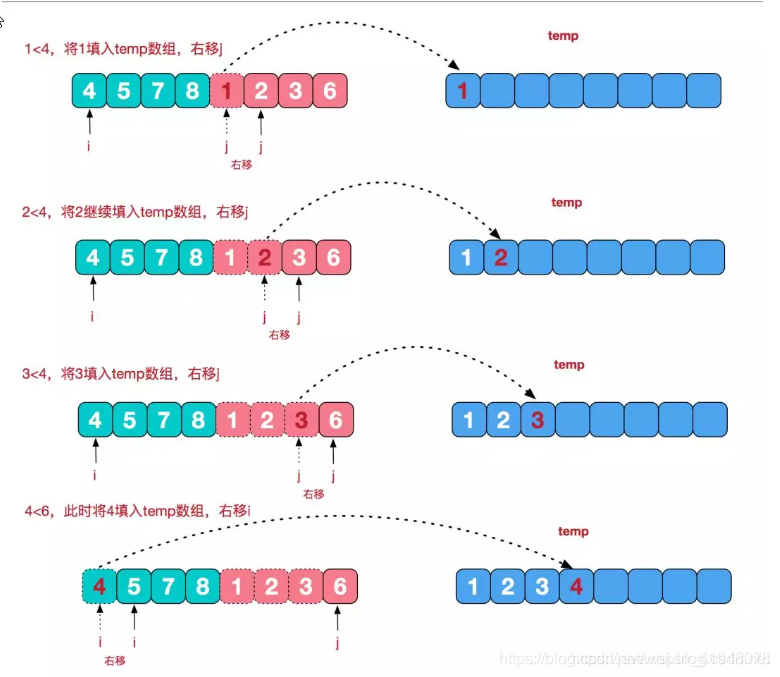
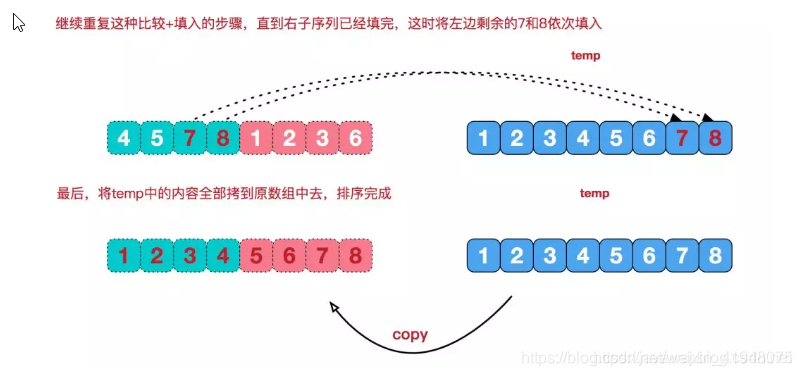
动态图演示
归并排序算法分析
最佳情况:T(n) = O(n) 最差情况:T(n) = O(nlog2n) 平均情况:T(n) = O(nlog2n)
线性时间非比较类排序
8、计数排序(Counting Sort)
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。计数排序(Counting sort)是一种稳定的排序算法。计数排序使用一个额外的数组C,其中第i个元素是待排序数组A中值等于i的元素的个数。然后根据数组C来将A中的元素排到正确的位置。它只能对整数进行排序。
算法描述
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
动图演示
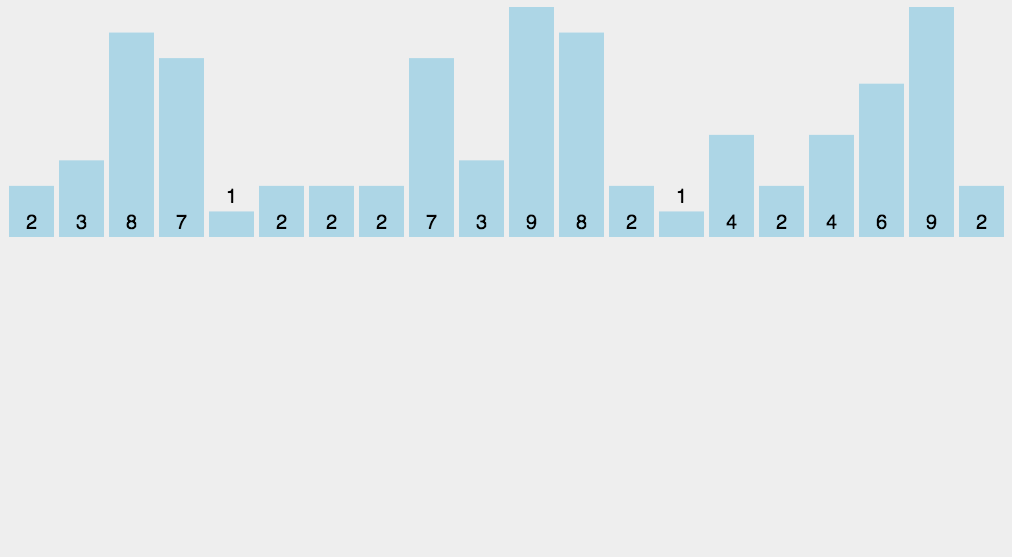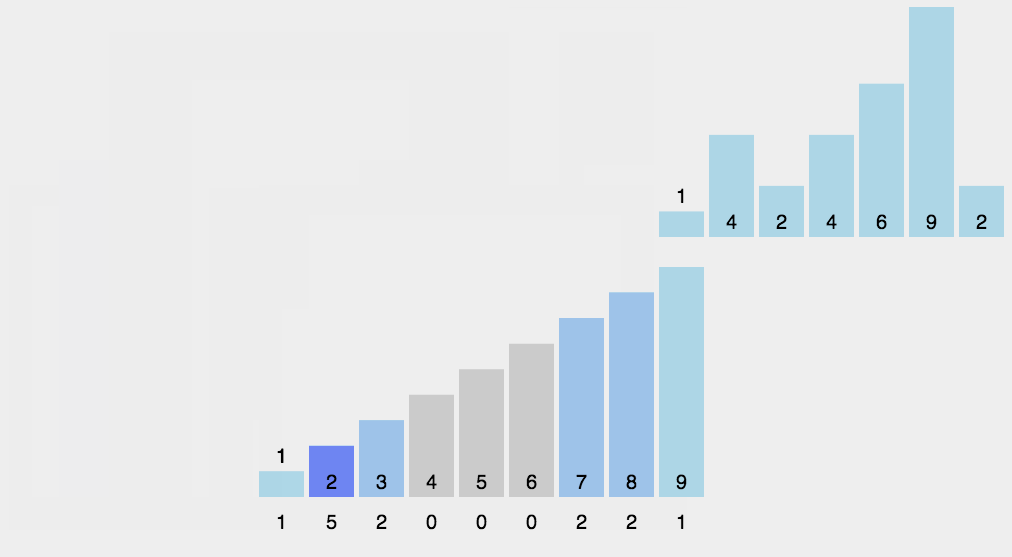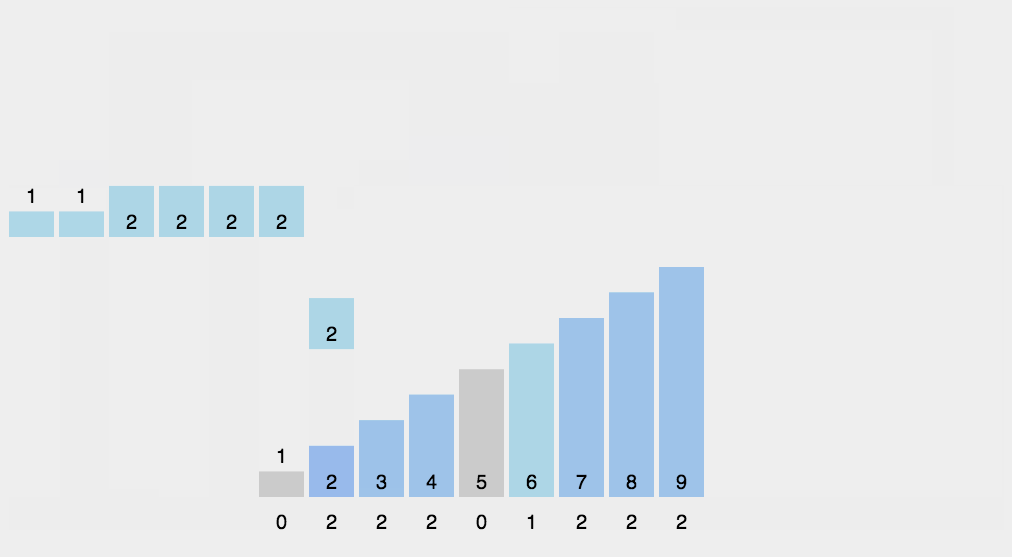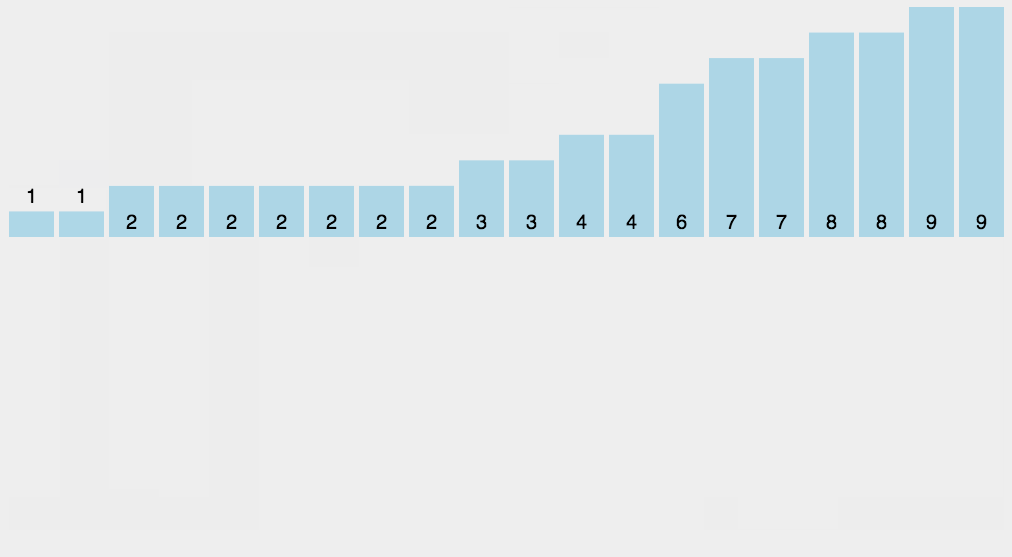
计数排序算法分析
当输入的元素是n 个0到k之间的整数时,它的运行时间是 O(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。最佳情况:T(n) = O(n+k) 最差情况:T(n) = O(n+k) 平均情况:T(n) = O(n+k)
9、桶排序(Bucket Sort)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排。
算法描述
- 人为设置一个BucketSize,作为每个桶所能放置多少个不同数值(例如当BucketSize==5时,该桶可以存放{1,2,3,4,5}这几种数字,但是容量不限,即可以存放100个3);
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序,可以使用其它排序方法,也可以递归使用桶排序;
- 从不是空的桶里把排好序的数据拼接起来。
注意,如果递归使用桶排序为各个桶排序,则当桶数量为1时要手动减小BucketSize增加下一循环桶的数量,否则会陷入死循环,导致内存溢出。
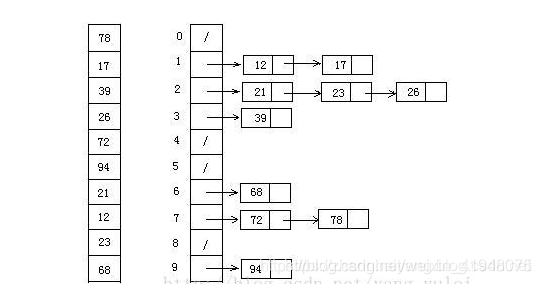
桶排序算法分析
桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。 最佳情况:T(n) = O(n+k) 最差情况:T(n) = O(n+k) 平均情况:T(n) = O(n2)
10、基数排序(Radix Sort)
基数排序也是非比较的排序算法,对每一位进行排序,从最低位开始排序,复杂度为O(kn),为数组长度,k为数组中的数的最大的位数;基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。
算法描述
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);
动图演示

基数排序算法分析
最佳情况:T(n) = O(n * k) 最差情况:T(n) = O(n * k) 平均情况:T(n) = O(n * k)。基数排序有两种方法:MSD 从高位开始进行排序 LSD 从低位开始进行排序 。基数排序 vs 计数排序 vs 桶排序。这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶
- 计数排序:每个桶只存储单一键值
- 桶排序:每个桶存储一定范围的数值
记不了这十个算法的童鞋先记住前7个即可,面试问的比较多也是前面的几个。面试问的可不止这么些,最近我比较勤劳在分类整理面试的常考点,分java、数据库、数据结构、计算机网络、软件测试来整理。想了解更多的可以去我的博客自己查看哦,也可以看下这几篇
MySQL的两种存储引擎
数据库事务的四大特性以及事务的隔离级别
List、Set、Map详解
BTree和B+Tree详解


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









