






参考:B站:梗直哥讲AI
0 梯度下降
0.1 核心要素:
- 目的:找到误差最小的点。通过迭代找到目标函数的最小值,或者收敛到最小值。
![![[Pasted image 20220815161931.png]]](https://img-blog.csdnimg.cn/03aa71ba511b49448978eb7b3f927c21.png)
0.2 步骤:

1 步骤·拆解:
1.1 定义·代价函数 cost function
1.1.1 推导
1.1.1.1 定义预测函数 – y = w x y = wx y=wx
(这里研究只用了一个 w w w,为了在二维平面上更直观观察图像)
1.1.1.2 误差公式 – MSE
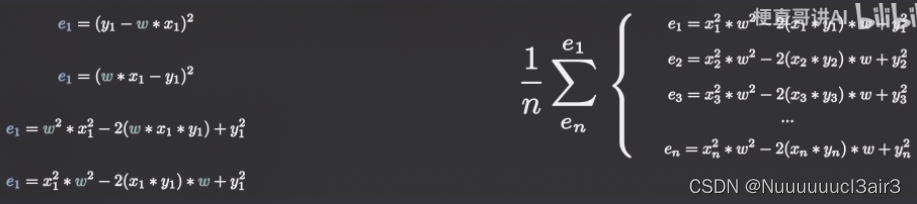
![![[Pasted image 20220815160400.png]]](https://img-blog.csdnimg.cn/e66810ea1cba481092d1f1ba80d3f0e5.png)
☝ 其中,
x
i
x_i
xi、
y
i
y_i
yi 都是已知的,如下图,分别用 abc 表示:
![[Pasted image 20220815160746.png]]
1.1.2 代价函数 ( cost function ):
![![[Pasted image 20220815161235.png]]](https://img-blog.csdnimg.cn/678ad5f20577426cb8f4c0ef2da99618.png)
1.2 明确·搜素方向 —— 梯度计算
1.3 学习率

1.4 不达目的不罢休 —— 循环迭代
2 梯度下降·变体
2.1 BGD ( Batch Gradient Descent )
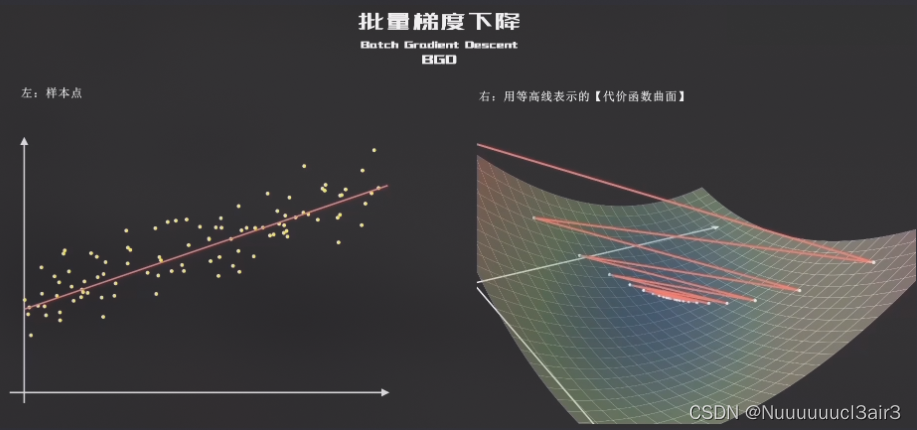
- 特点:
- 全部训练样本都参与了计算
- 梯度下降得非常平稳(走出了强迫症一般的漂亮曲线)
- 梯度下降最原始的形式
( 慢 but 稳如老狗 )
- 优点:保证算法精准度,找到全局最优点
- 缺点:训练的搜索过程很慢
2.2 SGD ( Stochastic Gradient Descent )
![![[Pasted image 20220815163635.png]]](https://img-blog.csdnimg.cn/8f9e0049b030473aa53930de716a828f.png)
- 优点:提升了计算速度
- 缺点:牺牲了精准度。虽然大方向没错,但下降得非常不平稳
2.3 MBGD ( Mini - Batch Gradient Descent )
也叫 最速下降法

- 特点:
- (相较于 BGD)没那么平稳,but 快 得多
- (相较于 SGD)没那么快,but 准确 得多
- 简洁高效
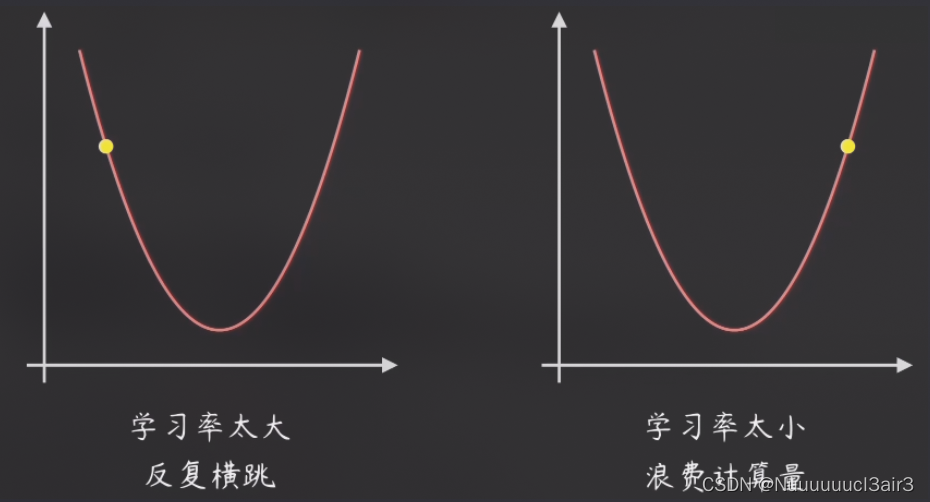
3 梯度下降法·缺点
-
对学习率的设定,非常敏感
-
除了效率极低的 BGD 外, SGD 、MBGD 未必能找到全局最优,很有可能陷入局部最优。
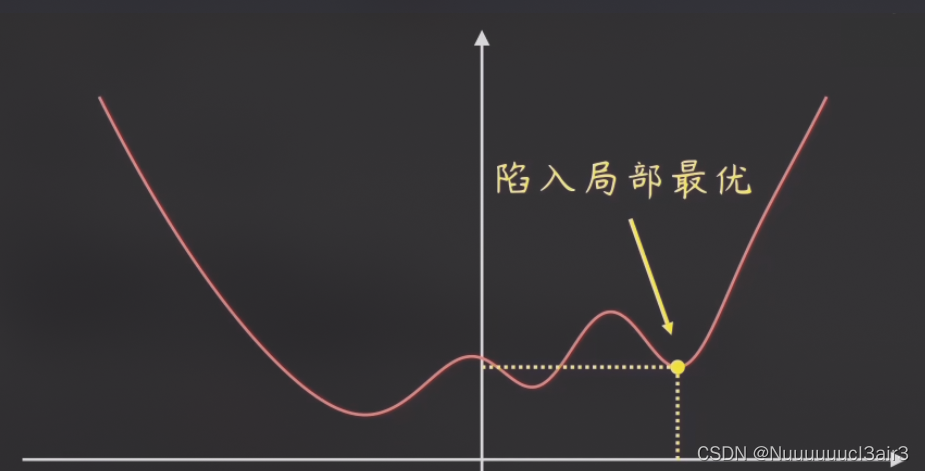
4 更优的梯度下降算法
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









