







3HTTP 首部字段浏览
今日北京阳光格外柔暖,屋子里,手机上播放着自然的蝉鸣声音,揉了下眼睛,从桌子上拿起眼睛,并戴上,不在胡思乱想了,开始这篇的分享。 ---周末愉快2021-01-30
看过本文,你将收获,web开发下绝大多数情况,涉及的http字段。以及前后端交互时,参数格式的合理设置,例如form表单的提交,json格式的提交,和文件提交的 注意事项。
前文回顾:
接下来就是今天的HTTP的字段内容了。
HTTP报文首部
我们自上而下观看,http首部字段的在哪个结构里?下图是http报文结构,自然http首部字段在蓝色区域。

所以蓝色区域的报文首部又是怎样的结构?看下图
请求报文结构
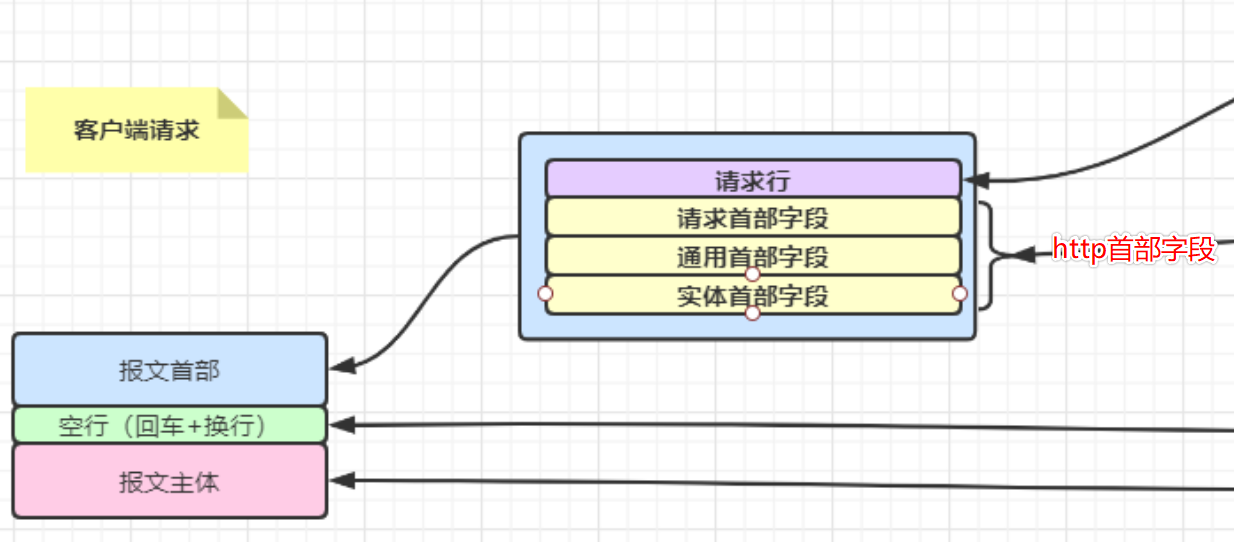
响应报文结构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7yjU6WCd-1612192831330)(C:\Users\46323\Desktop\素材\http\image\http响应首部字段的位置.png)]
总结起来,http首部字段,一共分为四类:
- 通用首部字段
- 请求首部字段
- 响应首部字段
- 实体首部字段
4种http首部字段类型的详细介绍
介绍前,先看下字段构成结构。
首部字段名字: 字段值 [,字段值2]
例如:
Content-Type: text/html
Keep-Alive: timeout=15,max=100
以下列举一些常见的的字段,建议大家,做到眼熟,即可,当工作中用到不至于萌萌哒就好
通用首部字段
通用首部字段是,请求报文,响应报文,两方都会使用的首部。下表为概览表
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 逐跳首部、连接的管理 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
开始逐行解释上表
Cache-Control
在解释前我们应该知道一位存在,叫做缓存服务器。看下图它的定位是这样滴:

既然这是通用首部字段,所以在请求端和响应端个有不同的含义,先看客户端的含义,注意,每个字段对应的值称为指令!
例如:Cache-Control: private, max-age=0, no-cache
这里就有三个指令, private ,max-age, no-cache
下面开始解释指令的含义,注意这是客户端的含义
| 指令 | 参数 | 说明 |
|---|---|---|
| no-cache | 无 | 强制缓存服务器从服务端获取资源。(Cache-Control: no-cache) |
| no-store | 无 | 与no-cache一样,但预示着,信息含有机密不要缓存(Cache-Control: no-store) |
| max-age=[秒] | 必须 | 要是缓存没有超过xxx秒,缓存服务器麻烦你返给我资源。(Cache-Control: max-age=10) |
| max-stale (=[秒]) | 可选 | 接受过期的资源,也可以设置过期多少秒内的也接收。(Cache-Control: max-stale) |
| min-fresh=[秒] | 必须 | 请缓存服务器大哥,给我在xx秒内没有过期的资源。(Cache-Control: min-fresh= 13) |
| only-if-cached | 无 | 缓存服务器大哥,给返给资源吧,不用跟server确认任何信息,俺相信你!如果缓存中没有,那一定是天意,你返给504给我也行。 |
| no-transform | 无 | 缓存服务器大哥不要改变媒体类型,比如不要压缩图片。 |
上面的每个指令后都写 Cache-Control: xxx 太拖沓了。懒得写了哦!
服务端含义
注意: 下表的说明,用说话的口吻对 缓存服务器说的,而且说话的时机是,客户端向缓存服务器请求资源,并且缓存服务器对于这个请求也要转发给 服务端,以下就是服务端响应给缓存服务器的对话。
| 指令 | 参数 | 说明 |
|---|---|---|
| public | 无 | 缓存服务器小老弟呀,这份资源任何人都可以给 |
| private | 可省略 | 缓存服务器小老弟呀,记住当前请求资源的这个客户端,只有它能拿到你的缓存 |
| no-cache | 可省略 | 缓存服务器小老弟呀,你可以存,但每次用前跟我这个服务端确认下,因为我不允许你缓存过期的资源 |
| no-store | 无 | 缓存服务器小老弟呀,你不要缓存,因为这个资源有点机密哦! |
| no-transform | 无 | 同客户端一个含义。 |
| must-revalidate | 无 | 缓存服务器小老弟呀,你每次你要用我给你的这个资源时,必须跟我确认这个资源的有效性。如果在我这里无效,你返给客户端504,即使客户端用了max-stale 也不行! |
| max-age=[秒] | 必需 | 同客户端含义相同。 |
| s-maxage = [ 秒] | 必需 | 公共缓存服务器响应的最大Age值 |
至此cache-control 字段的常用指令讲完了,不要怕,不是每个字段都有这么多大指令的,你看小编我一点点写出来还没放松咧。
Trailer
在报文前半部,指出报文主体后面有哪些字段 例如:
HTTP/1.1 200 OK
Date: Tue, 03 Jul 2012 04:40:56 GMT
Content-Type: text/html
…
Transfer-Encoding: chunked
Trailer: Expires
…(报文主体)…
0
Expires: Tue, 28 Sep 2004 23:59:59 GMT
Connection
两个作用
1 要求代理服务器,转发时删除某个字段,例如:
客户端 代理服务器 服务端
get / HTTP/1.1 get / HTTP/1.1
upgrade: HTTP/1.1
Connection: upgrade
如上删除了 upgrade字段
2 管理持久链接
Connection: Keep-Alive
表示长连接
Connection: close
表示告诉客户端,断开连接
http默认都是长连接
一言以蔽之:用于通知客户端或服务端相对的另一端,在发送完数据之后,不要断开 TCP 连接,之后还需要再次使用,除非显式的在报文头里,通过 Connection:close 这个首部,指定在传输结束之后会关闭此连接。
所以你应该有个疑问,产生,什么时候 Connection:close 就是该关闭,这就要提起Content-Length: 18\r\n 表示被传输的数据长度是 18,关于 Content-Length 表示的长度内容与实体数据不同情况我们后续说。
还是一起说了吧,毕竟知识最好是,成结构的,连贯的,排版不要了…
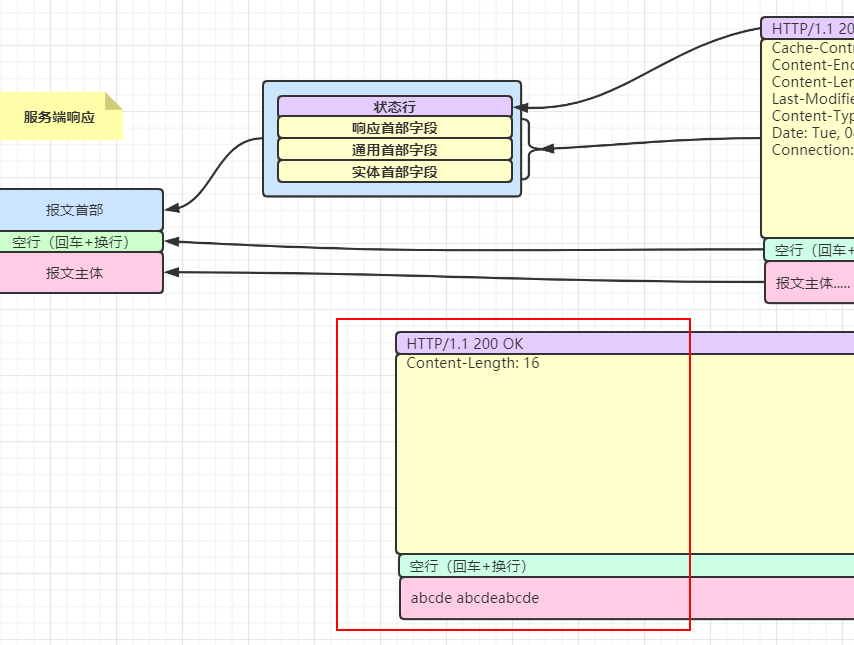
Content-Length 字段是4种分类中的,实体首部字段,表示服务端,返给客户端的 实体数据长度。举例一个响应报文:
HTTP/1.1 200 OK \r\n
Content-Length: 16\r\n
\r\n
abcde abcdeabcde
我们根据图来对照一下,请看红色框框特意将实体内容改为 15个字母+一个空格 ,所以Content-length为16
如果 内容长度 与 Content-Length 不同会怎么样

Content-length,算是讲完了,
但是关于实体数据的长度还没完,一定有这样的情况发生,有些动态生成的数据,如果全部生成在本地,或内存中后,再统一计算长度,显然不合理,最好就是边生成边传输,这就引出了
Transfer-Encoding
Transfer-Encoding: chunked // HTTP1.1中只有这个参数
这是一种传输方式,分块传输,将内容实体切割,包装一个个块进行传输。
传送情况如图:
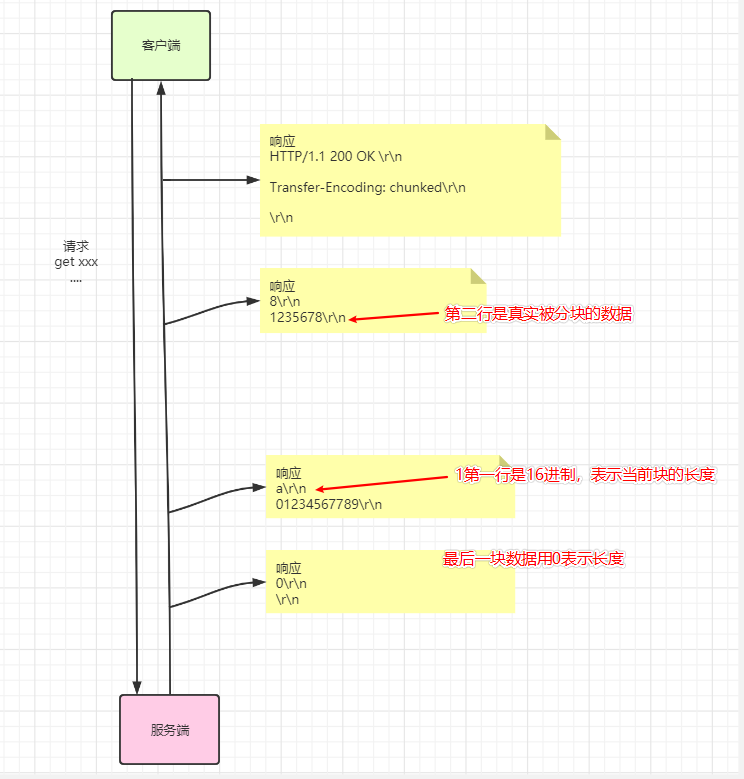
到这里,应该联想到
刚讲到的Trailer ,当使用Transfer-Endcoding 传输完成后,将实体数据的md5值传递过来!
所以图变了:

#### Date
表示报文创建的时间 例如:
Date: Tue, 03-Jul-12 04:40:59 GMT
Upgrade
一般用来升级协议,例如websocket ,就是通过http 协议来握手,客户都发送请求给服务端,例子如下:
请求如下:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://example.com
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
响应如下
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: chat
细心的你发下,请求和响应都含有 Connection 字段,没错!Upgrad 字段仅限制于两个临近的服务器之间。用来切换协议,所以,往往配合Connection 字段来配合。不要忘记呀,上面我们刚刚讲的Connection字段的含义呀,除了控制连接,另一个含义表示能删除某个字段。
请求首部字段
请求首部字段是从客户端往服务器端发送请求报文中所使用的字段,用于补充请求的附加信息、客户端信息、对响应内容相关的优先级等内容。
Accept
Accept 表示 客户端跟服务器说,我能处理的媒体类型
所以先解释下什么是媒体类型:
MIME: MIMEl类型就是设定,对应的文件按照后缀名进行分类,并关联对应的程序,浏览器会自动来处理打开使用该程序。举例:text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理。
具体MIME 类型对应什么扩展名可以查看这里
一般分为
-
文本文件
text/html, text/plain, text/css … //注意前者表示位超集
application/xhtml+xml, application/xml …
-
图片文件
image/jpeg, image/gif, image/png …
-
视频文件
video/mpeg, video/quicktime … -
应用程序使用的二进制文件
application/octet-stream, application/zip …
比如,如果浏览器不支持 PNG 图片的显示,那 Accept 就不指定,image/png,而指定可处理的 image/gif 和 image/jpeg 等图片类型。
若想要给显示的媒体类型增加优先级,则使用 q= 来额外表示权重值1,用分号(;)进行分隔。权重值 q 的范围是 0~1(可精确到小数点后 3 位),且 1 为最大值。不指定权重 q 值时,默认权重为 q=1.0。
Accept: text/html,application/xhtml+xml,application/xml;q=0.8
Accept-Charset
表示客户端,能处理的优先级,和用q增加权重比。
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8
Accept-Encoding
作用:告知服务器,客户端能处理的编码。
例子:
Accept-Encoding: gzip, deflate
如果request中没有Accept-Encoding 那么服务器会假设所有的Encoding都是可以被接受的,
Accept-Encoding: compress, gzip //支持compress 和gzip类型
Accept-Encoding: //默认是identity
Accept-Encoding: * //支持所有类型
Accept-Encoding: compress;q=0.5, gzip;q=1.0 //按顺序支持 gzip , compress
Accept-Encoding: gzip;q=1.0, identity; q=0.5, *;q=0 //按顺序支持 gzip ,
dentity总是可被接受的encoding类型(除非显示的标记这个类型q=0) , 如果Accept-Encoding的值是空 那么只有identity是会被接受的类型
- gzip
由文件压缩程序 gzip(GNU zip)生成的编码格式
(RFC1952),采用 Lempel-Ziv 算法(LZ77)及 32 位循环冗余
校验(Cyclic Redundancy Check,通称 CRC)。 - compress
由 UNIX 文件压缩程序 compress 生成的编码格式,采用 Lempel-
Ziv-Welch 算法(LZW)。 - deflate
组合使用 zlib 格式(RFC1950)及由 deflate 压缩算法
(RFC1951)生成的编码格式。 - identity
不执行压缩或不会变化的默认编码格式
Accept-Language
首部字段 Accept-Language 用来告知服务器用户代理能够处理的自然语言集(指中文或英文等),以及自然语言集的相对优先级。可一次指定多种自然语言集。
Accept-Language: zh-cn,zh;q=0.7,en-us,en;q=0.3
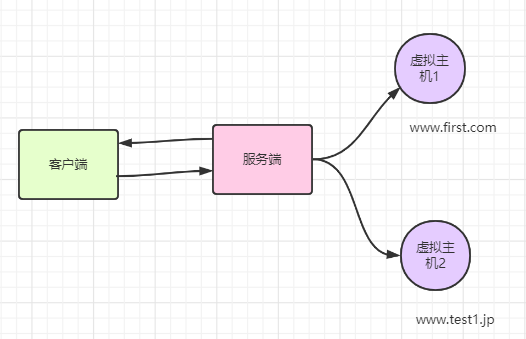
host
Host: www.first.com
这是唯一一个必须在请求中有的字段!!
一个服务器会分配多个域名,这是Host必须存在的意义
请求被发送至服务器时,请求中的主机名会用 IP 地址直接替换解决。但如果这时,相同的 IP 地址下部署运行着多个域名,那么服务器就会无法理解究竟是哪个域名对应的请求。因此,就需要使用首部
字段 Host 来明确指出请求的主机名。
if-Match
形如 If-xxx 这种样式的请求首部字段,都可称为条件请求。服务器接收到附带条件的请求后,只有判断指定条件为真时,才会执行请求。
只有当 If-Match 的字段值跟 ETag 值匹配一致时,服务器才会
接受请求,否则返回412
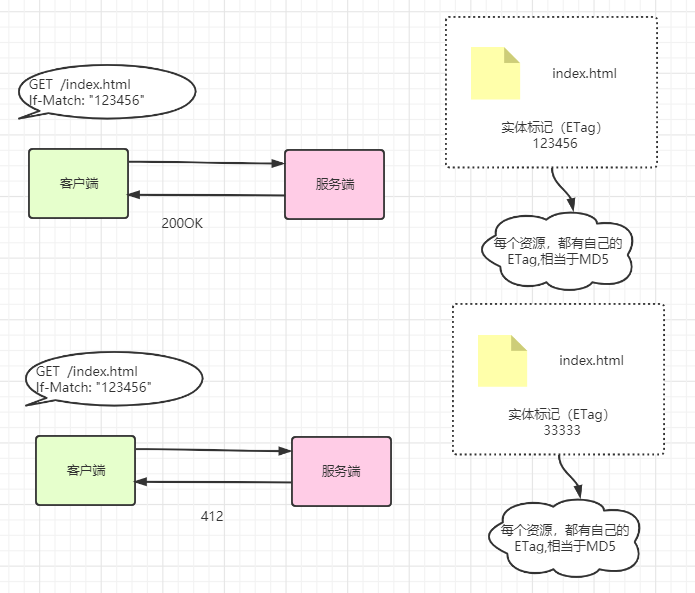
用星号(*)指定 If-Match 的字段值。针对这种情况,服务器将会忽略 ETag 的值,只要资源存在就处理请求。
If-None-Match
作用与If-Match 相反,专门匹配ETag 不相同的,服务器会正常返回,哎你说气人不!
If-Modified-Since
If-Modified-Since 字段指定的日期时间后,资源发生了更新,服务器会接受请求,简而言之:
客户端,要求返回的资源,一定是在xx天之后,修改过后的。服务器验证过会日期,的确被修改过,那么就正常返回,否则返回304
If-Unmodified-Since
If-Unmodified-Since: Thu, 03 Jul 2012 00:00:00 GMT
首部字段 If-Unmodified-Since 和首部字段 If-Modified-Since 的作用相反。它的作用的是告知服务器,指定的请求资源只有在字段值内指定的日期时间之后,未发生更新的情况下,才能处理请求。如果在指定日期时间后发生了更新,则以状态码 412 Precondition Failed 作为响应返回。
If-Range和Range
通常两个字段组合来用
GET /index.html
If-Range: "123456"
Range: bytes=5001-10000
如上报文所示,服务端接收到报文后,会验证下, index.html 这个资源是不是实体标记(ETag)为123456
如果是,则返给客户端 index.html 这个资源的第 5001-10000个字节的内容。如果实体表记ETag不匹配则服务端会,将整个资源返回给客户端
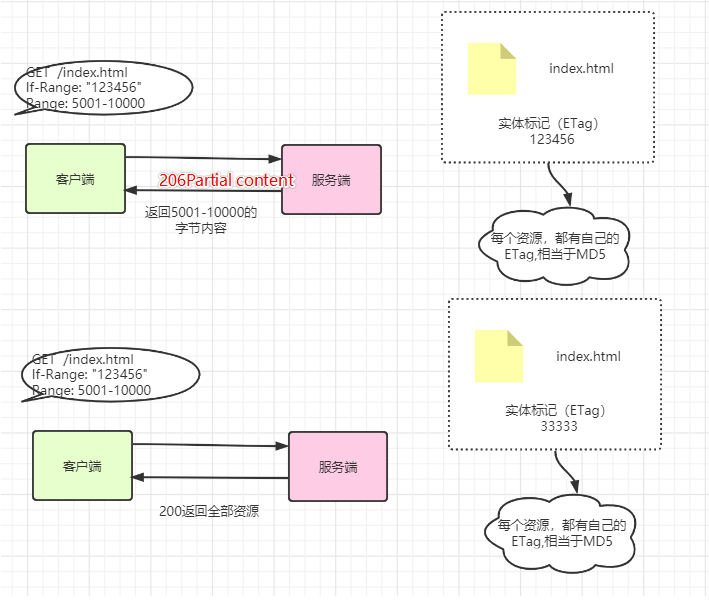
如果请求报文是这样的
GET /index.html
If-Match: "123456"
Range: bytes=5001-10000
则当ETag 不匹配的情况下,客户端需要发起第二次请求,请求整个文件。和If-Range 字段比较,多了一次请求
Referer
告知服务端,这个请求来自哪个Web页面发起的
GET /
Referer: http://www.hackr.jp/index.htm
User-Agent
用于传达浏览器的种类
//谷歌 ====useragent====:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36
//火狐 ==========useragent============:Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Gecko/20100101 Firefox/81.0
//后台java ========useragent============:Java/1.8.0_31
list.add("java");
响应首部字段
Accept-Ranges
如上所讲,请求首部字段,Range 表示发起范围请求。
首部字段 Accept-Ranges 是用来告知客户端服务器是否能处理范围请求,以指定获取服务器端某个部分的资源。
有两个值
Accept-Ranges: bytes //可以接受,但要求是字节
Accept-Ranges: none //表示不能
age
Age: 600
首部字段 Age 能告知客户端,源服务器在多久前创建了响应。字段值的单位为秒。
若创建该响应的服务器是缓存服务器,Age 值是指缓存后的响应再次发起认证到认证完成的时间值。代理创建响应时必须加上首部字段Age。
当直接访问服务器时
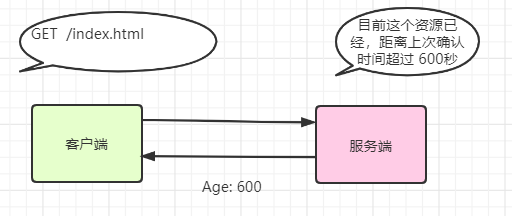
当为缓存服务器时

ETag
ETag: "82e22293907ce725faf67773957acd12"

首部字段 ETag 能告知客户端实体标识。它是一种可将资源以字符串形式做唯一性标识的方式。服务器会为每份资源分配对应的 ETag值。
强 ETag 值和弱 Tag 值
强 ETag 值,不论实体发生多么细微的变化都会改变其值。
ETag: "usagi-1234"
弱 ETag 值只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变 ETag 值。这时,会在字段值最开始处附加 W/。
ETag: W/"usagi-1234"
location
还记得我们之前说过的,状态码中的重定向吗?
当发生资源转移后,服务端需要告诉客户端应该重定向到哪个位置去,就由location字段值来表示
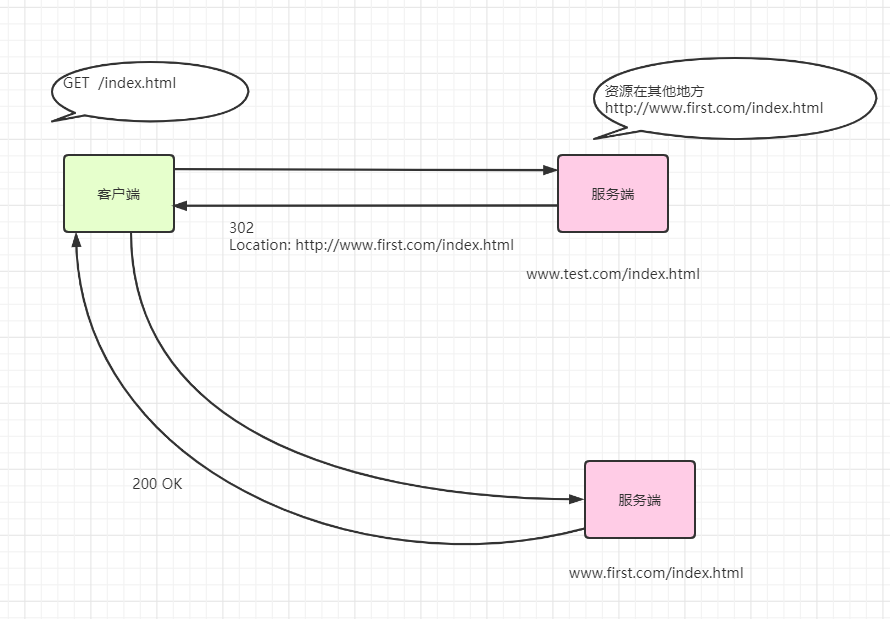
server
告知客户端,HTTP服务器应用程序的信息,不单单会标出服务器上的软件应用名称,还有可能包含版本号和安装时启用的可选项,一旦自己服务器使用的为旧版本,并且漏洞已经被放出来的,最好在隐藏此字段或者自己随意改个名称,以防有人使用已知漏洞攻击服务器。!
Server: Apache/2.2.17 (Unix)
Server: Apache/2.2.6 (Unix) PHP/5.2.5
实体首部字段
实体首部字段是包含在请求报文和响应报文中的实体部分所使用的首部,用于补充内容的更新时间等与实体相关的信息。
Allow
Allow: GET,POST
服务端要求,客户端请求某个资源只能 用,GET,POST,否则返回405 Method Not Allowed 作为响应返回。
Content-Encoding
值: gzip,compress,deflate,identity
服务端告知客户端,用的是哪种压缩方式压缩的。压缩的算法同,Transfer-Encoding字段一样,但是Transfer-Encoding 是通用首部字段。
这里插下我工作中用到的springboot项目中来处理文件流,返回给前端一个压缩文件。使用apache提供的工具类
org.apache.tools.zip.ZipOutputStream
来关联servlet的响应流,并设置了对应的压缩方法用的就是deflated
zipOutputStream = new ZipOutputStream(new BufferedOutputStream(response.getOutputStream()));
// 设置压缩方法
zipOutputStream.setMethod(ZipOutputStream.DEFLATED);
//以上代码,相当于做了一个压缩包,压缩包中的每一文件需要填充
bufferedInputStream = new BufferedInputStream(is); //is 为你的文件流
zipOutputStream.putNextEntry(new ZipEntry(fileName));
// 获取封装好的浏览器输出流
os = new DataOutputStream(zipOutputStream);
//
int index = 0;
// 浏览器真正响应是从这里开始
while ((index = bufferedInputStream.read()) != -1) {//刷出 此文件到浏览器上
os.write(index);
}
//此时的浏览器现象是一个压缩文件包,中包含了一个文件。
Content-Language
告知客户端,实体主体用的语言是(中文?,英文?)
Content-Language: zh-CN
Content-Length
Content-Length: 13000
就是实体主体的长度,单位是字节。注意,当使用Transfer-Encoding:chunk时,就不能用Content-Length 字段。
Content-Location
Content-Location: http://www.test.com/index.html
给出的就是报文主体返回资源的URI,
Content-MD5
服务端告知客户端,报文主体的MD5值,
Content-MD5: OGFkZDUwNGVhNGY3N2MxMDIwZmQ4NTBmY2IyTY==
此值计算来自
报文主体 计算MD5值后,Base64编码后的结果。
其目的在于检查报文主体在传输过程中是否保持完整,以及确认传输到达。
客户端会对接收的报文主体执行相同的 MD5 算法,然后与首部字段 Content-MD5 的字段值比较
Content-Range
还记得上面提到的范围请求吗(Range),服务端响应后告知客户端,响应了实体的哪部分范围的数据,以及,实体总大小,
Content-Range: bytes 5001-10000/10000
Content-Type
与 客户端的请求中含有的 Accept字段 一样
Content-Type: text/html; charset=UTF-8
-
文本文件
text/html, text/plain, text/css … //注意前者表示位超集
application/xhtml+xml, application/xml …
-
图片文件
image/jpeg, image/gif, image/png …
-
视频文件
video/mpeg, video/quicktime … -
应用程序使用的二进制文件
application/octet-stream, application/zip …
其中特别想说的是,浏览器如何处理,服务端返回的文件流,其实浏览器能下载文件,会有弹框,还是响应报文描述的,浏览器接受到后触发下载事件,
// 设置响应头,以保证触发浏览器的下载事件
response.setHeader("Content-type", "application/octet-stream");
// 将文件名加入响应头中,并且设置浏览器为弹出框下载选项
response.setHeader("Access-Control-Expose-Headers", "Content-Disposition");//http规范中没有这个字段,必须加上前端才能拿到。
response.setHeader("Content-disposition", "attachment;fileName=xxx.txt");
如果是预览一个文件流在浏览器中则用
response.setHeader("Content-disposition", "inline;fileName=xxx.txt");
其实就是 Content-disposition: inline 浏览器接受到此值,会在浏览器内预览文件。
Last-Modeified
Last-Modified: Wed, 23 May 2012 09:59:55 GMT
首部字段 Last-Modified 指明资源最终修改的时间。一般来说,这个值就是 Request-URI 指定资源被修改的时间。
下面这几个字段,是我在平时工作中用到的
Cookie
关于cookie的标准制定,有些历史因素,目前,使用最广泛的 Cookie 标准却不是 RFC 中定义的任何一个。而是在网景公司制定的标准上进行扩展后的产物。
响应报文中cookie
Set-Cookie: status=enable; expires=Tue, 05 Jul 2011 07:26:31
请求报文中cookie
Cookie: xxxxxxxxx
如果你能看到这里了,不如点赞关注一波,我会认真分享每一篇博文。大家一起成长。
下期会分享HTTPS等安全方面进行分享。
我的公众号:茄子的笔记
赠人玫瑰,手有余香,你的关注,我的动力!
更多分享可见:
response.setHeader("Content-disposition", "inline;fileName=xxx.txt");
其实就是 Content-disposition: inline 浏览器接受到此值,会在浏览器内预览文件。
Last-Modeified
Last-Modified: Wed, 23 May 2012 09:59:55 GMT
首部字段 Last-Modified 指明资源最终修改的时间。一般来说,这个值就是 Request-URI 指定资源被修改的时间。
下面这几个字段,是我在平时工作中用到的
Cookie
关于cookie的标准制定,有些历史因素,目前,使用最广泛的 Cookie 标准却不是 RFC 中定义的任何一个。而是在网景公司制定的标准上进行扩展后的产物。
响应报文中cookie
Set-Cookie: status=enable; expires=Tue, 05 Jul 2011 07:26:31
请求报文中cookie
Cookie: xxxxxxxxx
如果你能看到这里了,不如点赞关注一波,我会认真分享每一篇博文。大家一起成长。
下期会分享HTTPS等安全方面进行分享。
我的公众号:茄子的笔记
赠人玫瑰,手有余香,你的关注,我的动力!
更多分享可见:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









