







数据容器
1.7数据容器
1.7.1简介
1.如何一个变量定义多个数据呢???
- 采用容器的变量的定义的方式。可以采用容器的定义的方式,集合等等
2.什么是数据容器?
可以存储多个python数据
3.常见的数据容器的类型
- list
- 元组
- str
- set集合
- dict字典

1.7.2列表list
1、简介
- 字面量
- 定义变量
- 定义空列表
# 定义列表1
a=[1,2,3,4,5,6,8]
print(a)
print(type(a))
# 保存多种数据类型
x=[1,1,2,'张三',True,False,None]
print(x)
# 空列表
print([])

2.列表嵌套
# 定义列表2
b=[1,2,3,4,5,6,8,[1,2,3,]]
print(b)
print(type(b))
1.7.3tuple元组
1.简介

2.列表可以修改,元组不可以被修改,元组相当于只读的list,一旦被定义了就不能被修改了。
3.定义的方式
- 字面量
- 直接赋值
- 类的方式

4.简单案例
- 多种方式的创建
- 定义空元组
# 元组创建
a=(1,2,3,'你好')
b=()
c=tuple()
print(a)
print(b)
print(c)
print(type(a))

5.定义单个的元组
- 定义单个元素的元组的时候需要注意定义的格式
- 传入的数据是一个的时候,后面必须多加一个逗号不然的话就自动的识别成了对应的int类型的数据了
# 定义单个元素的元组,注意语法格式!!!!
d=(1)
e=(1,)
print(d)
print(e)
print(type(d))
print(type(e))

6.元组的嵌套
# 元组嵌套
dd=((1,2,3,),4,5,6,(7,8,9))
print(type(dd))
print(dd)
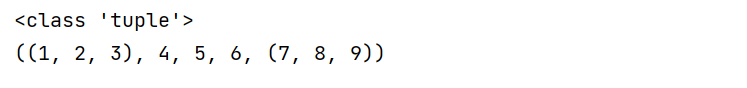
7.获取元组中的数据
- 取数据的方式和取list集合的数据中的是一样的就是不能修改而已
dd=((1,2,3,),4,5,6,(7,8,9))
print(dd[0])
print(dd[-1])
print(dd[0][0])

1.7.4字符串str
1.介绍
- 前面有使用和介绍

2.下标索引
- 正向和反向的遍历的方式
# str的遍历
s="hello word"
# 正向索引
print(s[0])
print(s[1])
print(s[2])
print(s[3])
print(s[4])
# 反向索引
print(s[-1])
print(s[-2])
print(s[-3])
print(s[-4])
3.字符串可以被修改?????不支持
- 如何修改字符串中的数据

除非采用重新定义的方式进行修改版字符串中的值
s='12122'
print(s)
1.7.5集合set
定义空字典,set中是不支持{}定义空的集合的。一定要注意。定义空的set的时候采用的是set()的方式进行定义的。。
1.学什么

2.分析原先的数据容器
- set不允许重复的。。。
3.定义

# 定义
s={1,2,3,4,5,6}
y=set()
z={} #这个定义的是空的字典并不是空的set要注意
print(s)
print(y)
print(z)
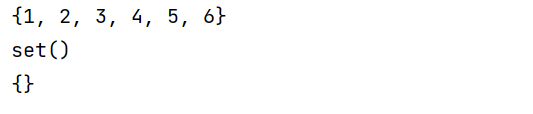
4.如何访问?????
- 不支持下标的索引,可以修改。因为是无序的,所以索引就失效了。
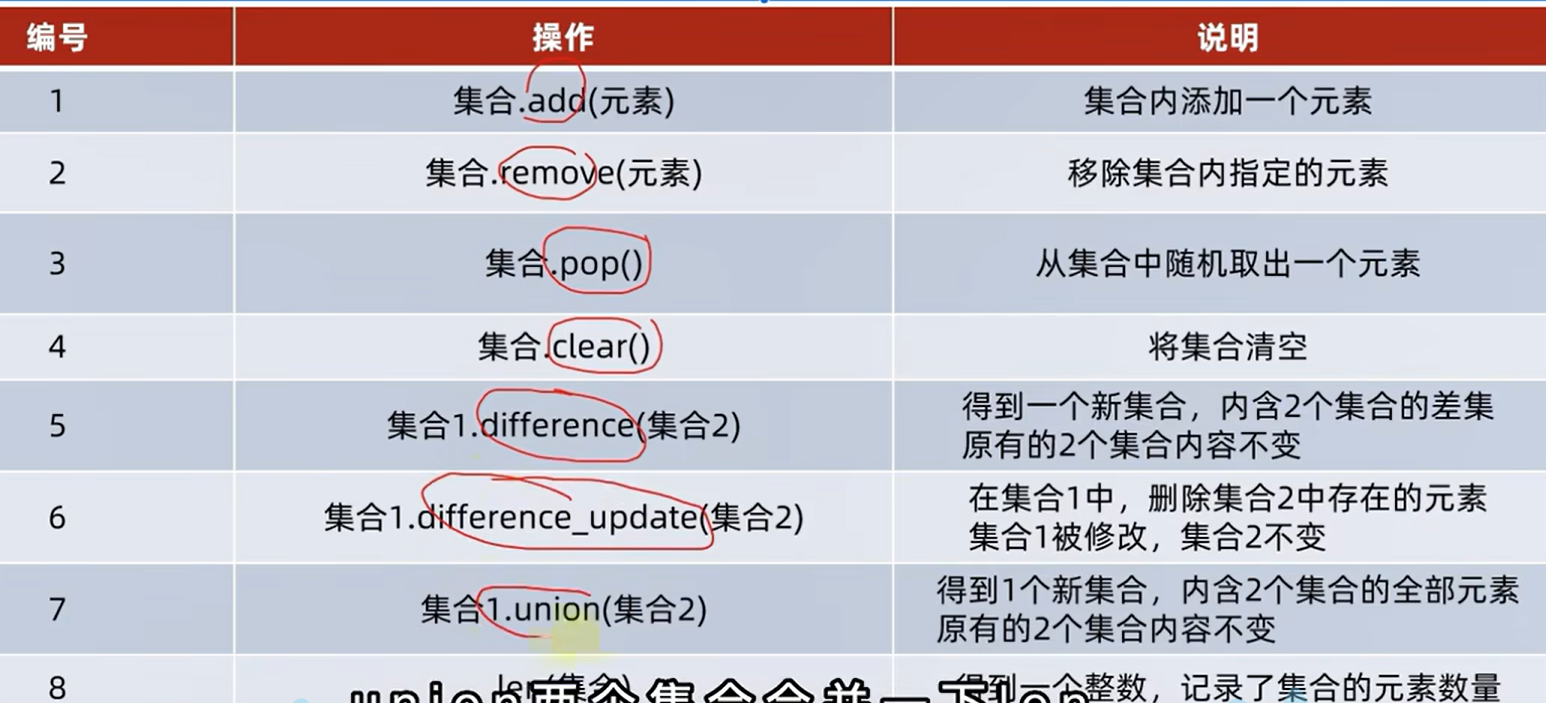
5.集合的基本操作
# 添加新元素,相同的会自动的省略掉
y.add(1)
y.add(1)
y.add(2)
y.add(3)
y.add(4)
y.add(5)
print(y)
# 移除元素
y.remove(1)
print(y)
# 取出元素,无参数的,随机取一个
y.pop()
print(y)
# 清空set
y.clear()
print(y)

6.集合的差集
- 取的是两个集合的差集。取出的是集合1有但是集合2没有的就是取的差集,集合本身是不变的,得到的是一个新的集合
- 不会对集合本身产生改变的
# set的差集
a={1,2,3}
b={1,4,5,6}
# 差集的获取,difference
print("差集,",a.difference(b))
print(f"a,{a}")
print(f"b,{b}")

2.消除2个集合的差集,difference_update方法
- 集合1会被修改但是集合2不会被修改。在集合1中消除和集合2中存在的相同的元素。
#消除差集,此时集合a会受到改变的
a={1,2,3}
b={1,4,5,6}
print("消除差集,",a.difference_update(b))
print(f"a,{a}")
print(f"b,{b}")

3.集合合并,不改变本身,得到一个新的,union
# 集合合并,不改变本身,得到一个新的,union
a={1,2,3}
b={1,4,5,6}
print("集合合并,",a.union(b))
print(f"a,{a}")
print(f"b,{b}")
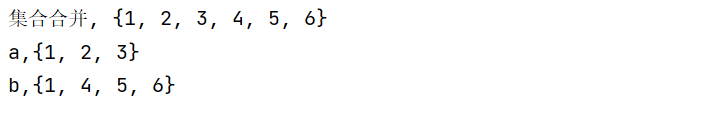
4.统计集合中的数量
- 注意集合本身是去重的
# 统计集合中的数量
a={1,2,3}
b={1,4,5,6}
print(len(a))
print(len(b))

5.集合的遍历
支持while循环,也就是不支持index访问的方式,但是支持对应的for循环的方式,类似对象的遍历的方式
# 集合的遍历
# 不支持while循环,也就是不支持index访问的方式,但是支持对应的for循环的方式,类似对象的遍历的方式
b={1,4,5,6}
for i in b:
print(i,' ',end='')

6.小结
7.set的特点

8.遍历

9.用处
- 可以进行去重啊
1.7.6字典dict
1.定义
- 生活中的字典

- py中的字典,key找对应的value的值

- 类似于json的数据的格式

2.定义
区别于set的定义的方式

# 字典的定义
# 字面量的方式
stu={
"name":"张三",
"age":18,
"sex":"男"
}
print(stu)
# 定义空字典,set中是不支持{}定义空的集合的
em={}
em2=dict()
print(type(em))
print(type(em2))

3.定义重复的字典
- 集合和字典是非常相似的。
- key是不可以的,但是key对应的值是可以的,默认是自动去重的,默认的只能保存最后一个key对应的值。新的会把老的覆盖掉。
4.如何获取??/
- 采用的key获取的方式,不能采用index的方式进行获取对应的数据。
# 数据获取
print(stu['name'])
print(stu['age'])
print(stu['sex'])

5.字典的嵌套
- 嵌套的进行获取就可以
# 嵌套的字典
stu={
"name":"张三",
"age":18,
"sex":"男",
"score":{
"a":99,
"b":89,
"c":18
}
}
print(stu)
print(stu['score'])
print(stu['score']['a'])


1.7.7list的下表索引
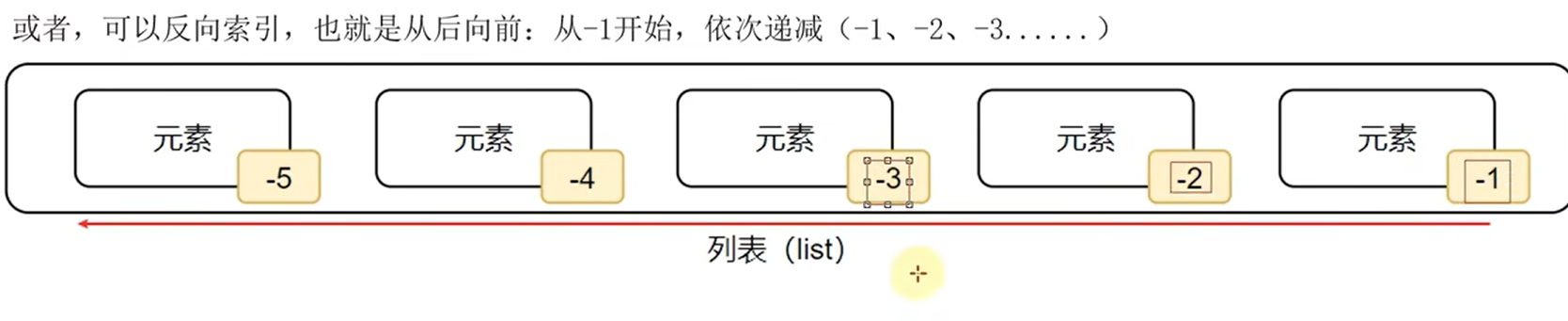
1.索引的分类
- 正向索引:第一个的下标的索引是0。依次开始递增的。
- 反向索引:从后面往前,-1开始的。
- 取嵌套索引中的数据
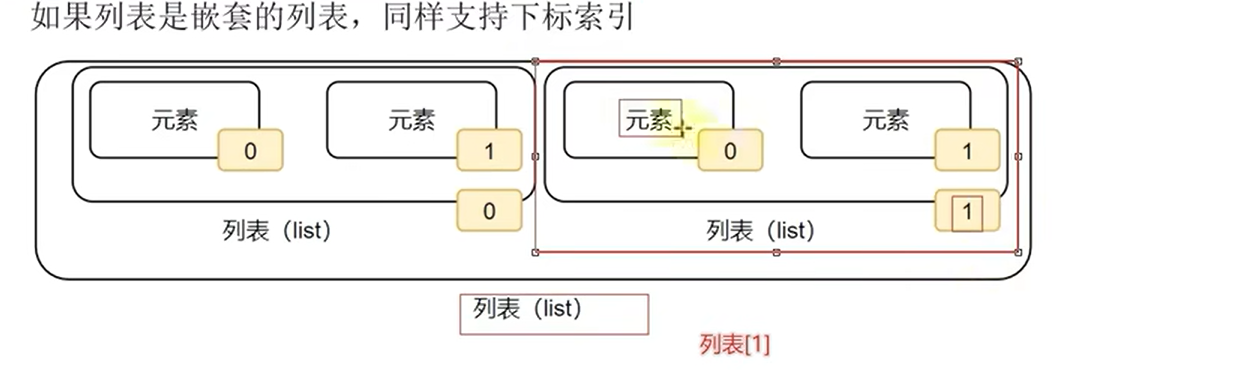
2.取索引对应的元素
mylist=['张三','李四','王五',[20,30,40]]
# 正向索引
print(mylist[0])
print(mylist[1])
print(mylist[2])
print(mylist[3])
# 反向索引
print(mylist[-1])
print(mylist[-2])
print(mylist[-3])
print(mylist[-4])
# 取嵌套中的数据
print(mylist[-1][0])
print(mylist[-1][1])
print(mylist[-1][2])

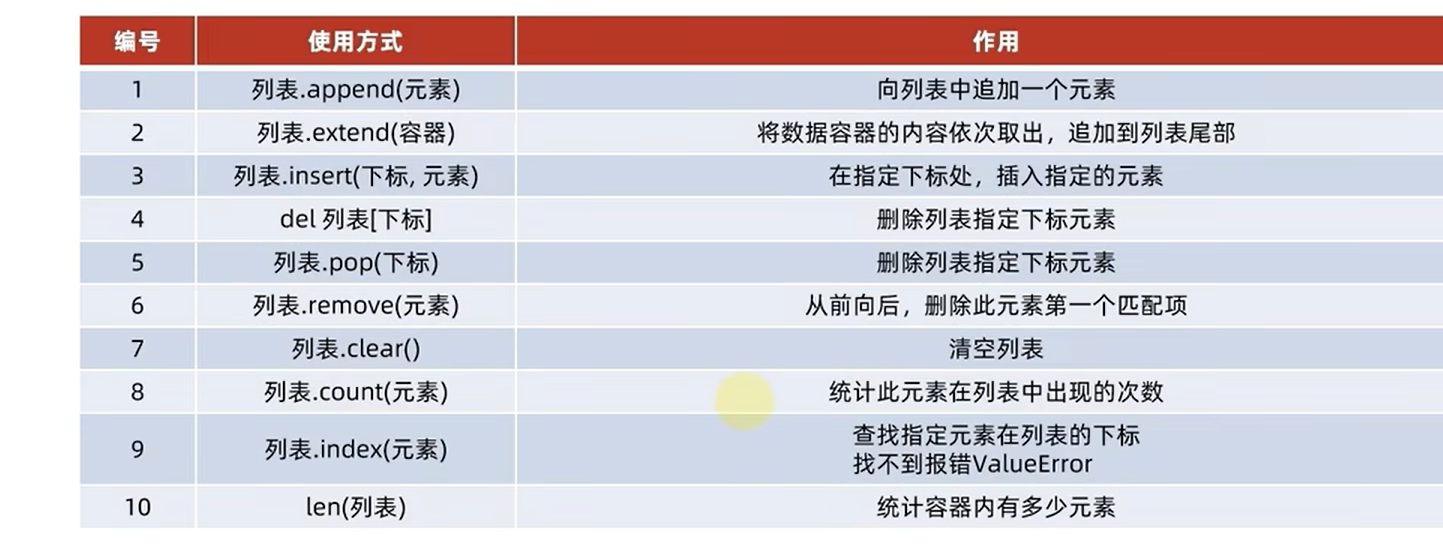
1.7.8list的常用操作
可以进行一个简单的操作的方式,增删改查以及统计个数等操作
补充:
函数和方法的区别,其实本质都是一样的,使用和调用的方式是有所区别的。后者是通过类对象进行调用的,不能直接进行调用。
1.查询

# list常用的方法
mylist=['张三','李四','王五','赵六']
index获取索引的值
# index获取索引的值
print(mylist.index("张三"))
2.修改指定下标的值
- 就是重新赋值的操作
#修改指定下标的值
print(mylist[1])
mylist[1]='李四修改'
print(mylist[1])
3.插入,指定的位置
#插入元素,可以在指定的位置插入指定的元素,索引是0开始的
mylist.insert(1,"陈二")
print(mylist)
4.追加到尾部
# 插入到尾部
mylist.append("网管")
print(mylist)
5.添加一批数据
- extend
# 插入多个元素
mylist2=[1,2,3]
mylist.extend(mylist2)
print(mylist)
6.删除指定位置的数据
del是关键字的方式进行数据的删除
# 删除指定位置的数据del
print(mylist)
del mylist[2]
print(mylist)

7.pop删除指定index位置的数据
- pop是采用的list的方法的方式进行数据的删除
- 可以得到要删除的数据的值
#pop方法删除指定位置数据的删除,有返回值的
print(mylist)
temp=mylist.pop(0)
print(f"被删除的数据是,{temp}")
print(mylist)
8.删除元素中第一个匹配项。传入的值是参数
# remove,从前往后删除第一个匹配的元素
print(mylist)
mylist.remove("网管")
print(mylist)
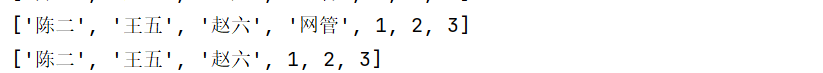
9.clear清空
# 清空
print(mylist)
mylist.clear()
print(mylist)
10.统计数量某个元素出现的数量。
# 统计某个元素出现的数量
mylist=[1,1,2,3,4,5,8,45,44,88,15]
print(mylist)
print(mylist.count(1))
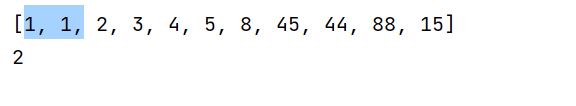
11.统计list所有元素的数量
# 全部元素的数量
print(len(mylist))

上面案例的完整代码
# list常用的方法
mylist=['张三','李四','王五','赵六']
# index获取索引的值
print(mylist.index("张三"))
#修改指定下标的值
print(mylist[1])
mylist[1]='李四修改'
print(mylist[1])
#插入元素,可以在指定的位置插入指定的元素,索引是0开始的
mylist.insert(1,"陈二")
print(mylist)
# 插入到尾部
mylist.append("网管")
print(mylist)
# 插入多个元素
mylist2=[1,2,3]
mylist.extend(mylist2)
print(mylist)
# 删除指定位置的数据del
print(mylist)
del mylist[2]
print(mylist)
#pop方法删除指定位置数据的删除,有返回值的
print(mylist)
temp=mylist.pop(0)
print(f"被删除的数据是,{temp}")
print(mylist)
# remove,从前往后删除第一个匹配的元素
print(mylist)
mylist.remove("网管")
print(mylist)
# 清空
print(mylist)
mylist.clear()
print(mylist)
# 统计某个元素出现的数量
mylist=[1,1,2,3,4,5,8,45,44,88,15]
print(mylist)
print(mylist.count(1))
# 全部元素的数量
print(len(mylist))
结果:
0
李四
李四修改
['张三', '陈二', '李四修改', '王五', '赵六']
['张三', '陈二', '李四修改', '王五', '赵六', '网管']
['张三', '陈二', '李四修改', '王五', '赵六', '网管', 1, 2, 3]
['张三', '陈二', '李四修改', '王五', '赵六', '网管', 1, 2, 3]
['张三', '陈二', '王五', '赵六', '网管', 1, 2, 3]
['张三', '陈二', '王五', '赵六', '网管', 1, 2, 3]
被删除的数据是,张三
['陈二', '王五', '赵六', '网管', 1, 2, 3]
['陈二', '王五', '赵六', '网管', 1, 2, 3]
['陈二', '王五', '赵六', 1, 2, 3]
['陈二', '王五', '赵六', 1, 2, 3]
[]
[1, 1, 2, 3, 4, 5, 8, 45, 44, 88, 15]
2
11
小结:
列表的小结

1.7.9list的案例

参考代码
# list列表案例
# 定义
mylist=[21,25,21,23,22,20]
print(f'初始化,{mylist}')
# 添加到尾部
mylist.append(31)
print(f'添加后,{mylist}')
# 追加列表
mylist.extend([29,33,30])
print(f'追加列表后,{mylist}')
# 取出第一个元素
print(mylist[0])
# 取出最后一个元素
print(mylist[-1])
# 查找31,的下表位置
print(mylist.index(31))

1.7.10list列表的遍历
- for循环的方式进行遍历数据
# list的遍历
mylist=[21, 25, 21, 23, 22, 20, 31, 29, 33, 30]
# 遍历
for i in range(0, len(mylist)):
print(mylist[i])

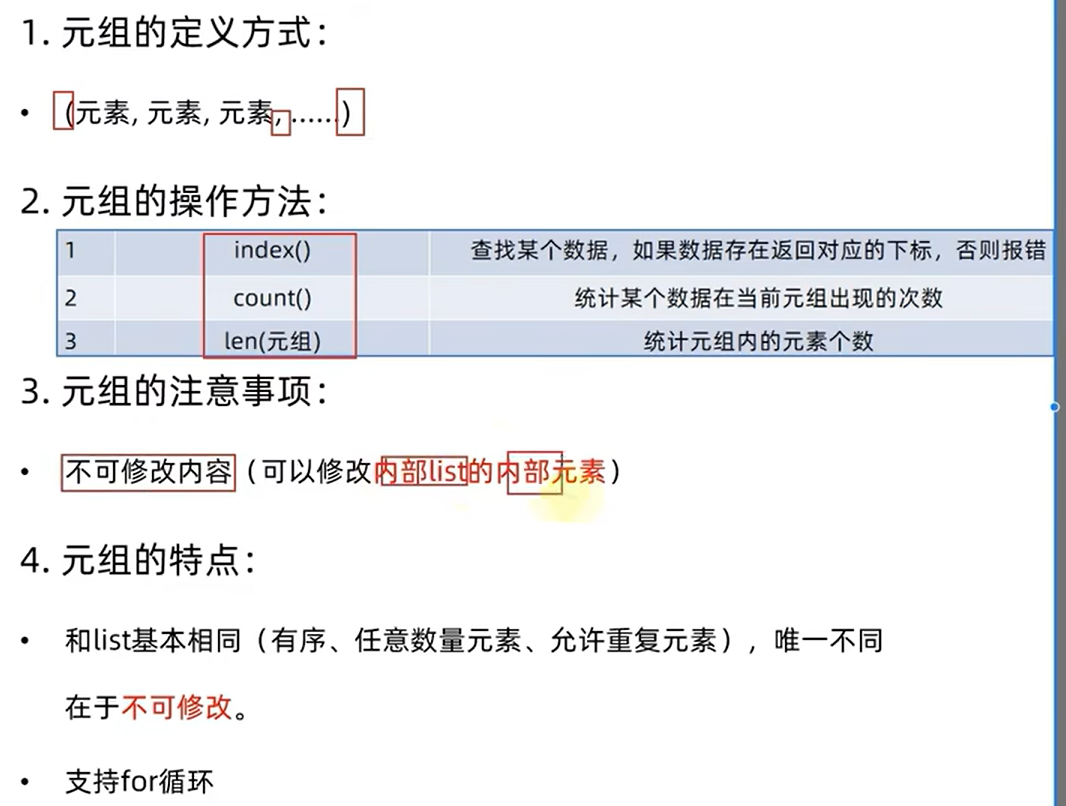
1.7.11元组的基本操作
1.index,查找下表。第一次出现时候的下表。下标从0开始的
2.count统计某个元组数据出现的次数
3.len,统计元组内元素的个数
# 元组的基本操作
dd=((1,2,3,),4,5,6,(7,8,9),4,8)
print(type(dd))
print(dd)
#index,查找下表。第一次出现时候的下表。下标从0开始的
print(dd.index(4))
# count统计某个元组数据出现的次数
print(dd.count(4))
# len,统计元组内元素的个数
print(len(dd))

4.元组的遍历
for和while循环的方式和list的遍历是一致的。

5.元组是只读的不可以修改
强制修改。

6.元组中保存的list的数据是可以被修改的
aa=(1,2,3,[4,5,6])
print(aa)
aa[-1][0]=111
print(aa)

小结

1.7.12元组的案例

代码自己写吧
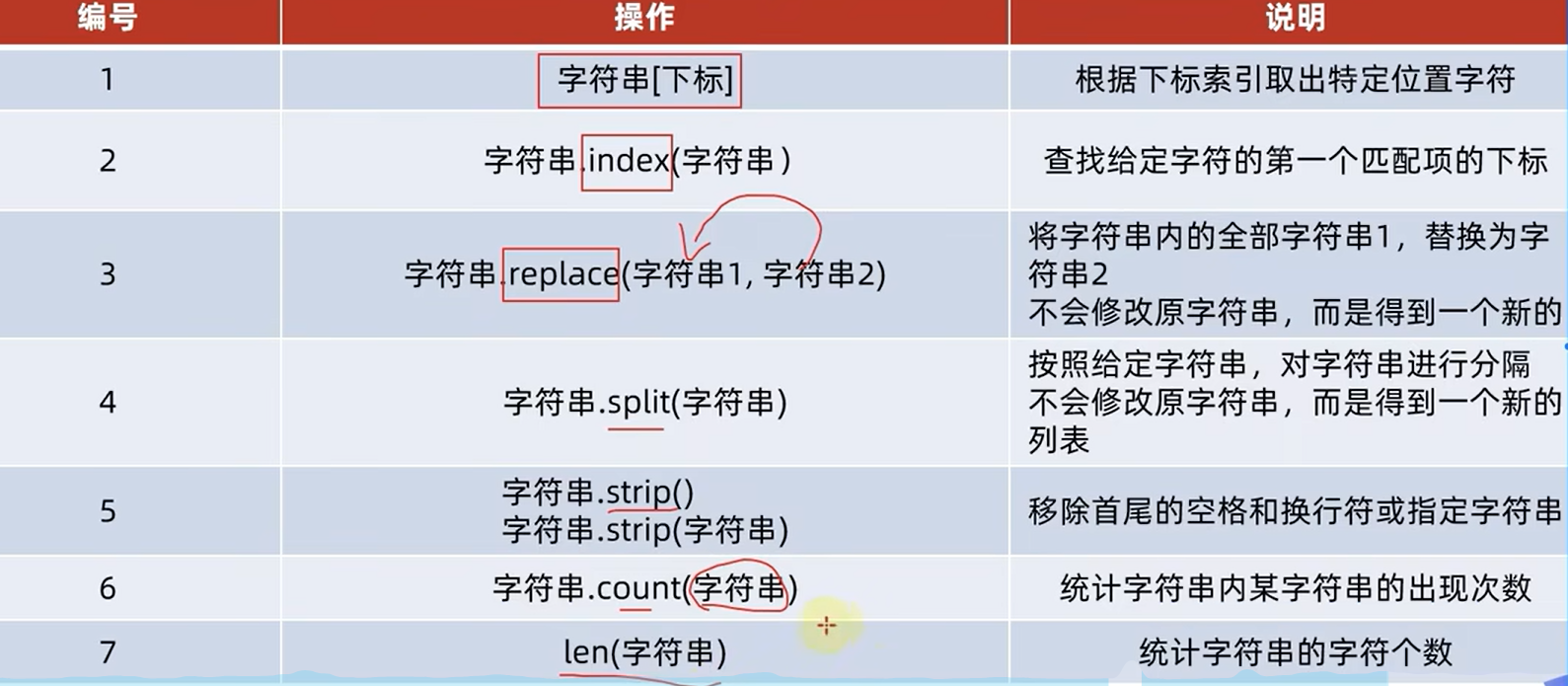
1.7.13str的基本操作
1.index方法,获取指定元素的索引的值
# index,获取某个元素第一次出现的索引
print('index,获取某个元素第一次出现的索引',s.index('o'))
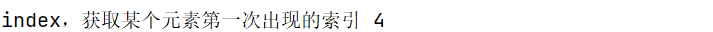
2.replace方法,实质是得到一个新的字符串,因为字符串本身是不允许修改的
- 第一个参数是要被修改的字符串
- 第二个参数是修改后的结果
# replace方法,实质是得到一个新的字符串,因为字符串本身是不允许修改的
print('replace方法,实质是得到一个新的字符串,因为字符串本身是不允许修改的',s.replace('zhangsan','张三'))

3.split方法,分割字符串的

# split方法,分割字符串的
x='hello,world,hi,zhangsan'
print(x.split(','))
print(type(x.split(',')))

4.统计字符串中某个字符出现的次数,count
# 统计字符串中某个字符出现的次数,count
print(x.count('h'))
5.统计字符串的长度,len
# 统计字符串的长度,len
print(len(xx))
6.strip()
和Java中的trim类似,注意传参的时候
- 不传入参数的时候就是去掉头和尾的空格
- 传入参数的时候可以实现
1)不传入参数
# 去掉字符串头和尾的空格
x=" hi zhangsan "
print(x)
xx=x.strip()
print(xx)

2)传入参数
- 注意查看实现的效果图
# 去除指定的字符串,包含字串啊!!!
x="12hi 12 zhangsan21"
print(x)
xx=x.strip("12")
print(xx)
xx

小结
字符串的特点


1.7.14数据容器的切片操作
1.序列的定义

2.序列切片
- 从大的序列中获取一个比较小的序列的结果
3.方法
- 正向的切片
默认的步长就是1,得到的子集合和原先的是一样的数据类型的
# list切片
mylist=[0,1,2,3,4,5,6,7,8,9,10]
print(f"mylist,{mylist}")
# 三个参数写两个,默认的步长就是1。包含头但是不包含尾的
re=mylist[1:4]
print(f"mylist[1:4]结果为,{re}")
# 元组
# 得到的结果还是本身的数据类型
tu=(0,1,2,3,4,5,6,7,8,9,10)
re=tu[1:4]
print(f"tu[1:4]结果为,{re}")
# 字符串
s="123456789"
re=s[1:4]
print(f"s[1:4]结果为,{re}")

- 反向切片
# 反向切片的时候需要从大的开始,然后从小的进行结束,并且步长指定为-1
# list切片
mylist=[0,1,2,3,4,5,6,7,8,9,10]
print(f"mylist,{mylist}")
# 三个参数写两个,默认的步长就是1。包含头但是不包含尾的
re=mylist[::-1] #相当于把序列进行了反转的操作
print(f"mylist[::-1]结果为,{re}")
re=mylist[3:1:-1] #相当于把序列进行了反转的操作
print(f"mylist[3:1:-1]结果为,{re}")
# 元组
# 得到的结果还是本身的数据类型
tu=(0,1,2,3,4,5,6,7,8,9,10)
re=tu[3:1:-1]
print(f"tu[3:1:-1]结果为,{re}")
# 字符串
s="123456789"
re=s[3:1:-1]
print(f"s[3:1:-1]结果为,{re}")

小结

1.7.15字典中的常用操作
有则更新,无则新增
1.新增
2.更新元素
3.pop移除指定key的元素
4.clear清空所有元素
# 字典的操作
stu={
"name":"张三",
"age":18,
"sex":"男",
"score":{
"a":99,
"b":89,
"c":18
}
}
print(stu)
# 新增
stu['phone']='121212112'
print(stu)
# 修改
stu['sex']="女"
print(stu)
# 元素删除
stu.pop("sex")
print(stu)
# 全部删除
stu.clear()
print(stu)

5.获取全部的key
- 用处:可以做字典的遍历
# 获取全部的key
print(stu.keys())

6.字典遍历方式1-根据所有的key进行遍历所有的字典中的元素
# 字典的遍历1
keys =stu.keys()
for key in keys:
print('打印字典中的元素:',stu[key])

7.直接对字典进行for循环
- 注意每一次得到的都是key的值,需要对元素的值进行单独的获取
- 还是不可以进行while的循环,推荐for循环方式
# 字典的遍历方式2-直接进行遍历的方式
for i in stu:
print("直接遍历:",stu[i])

8.统计字典中元素数量
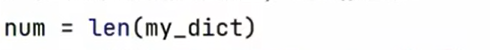
小结


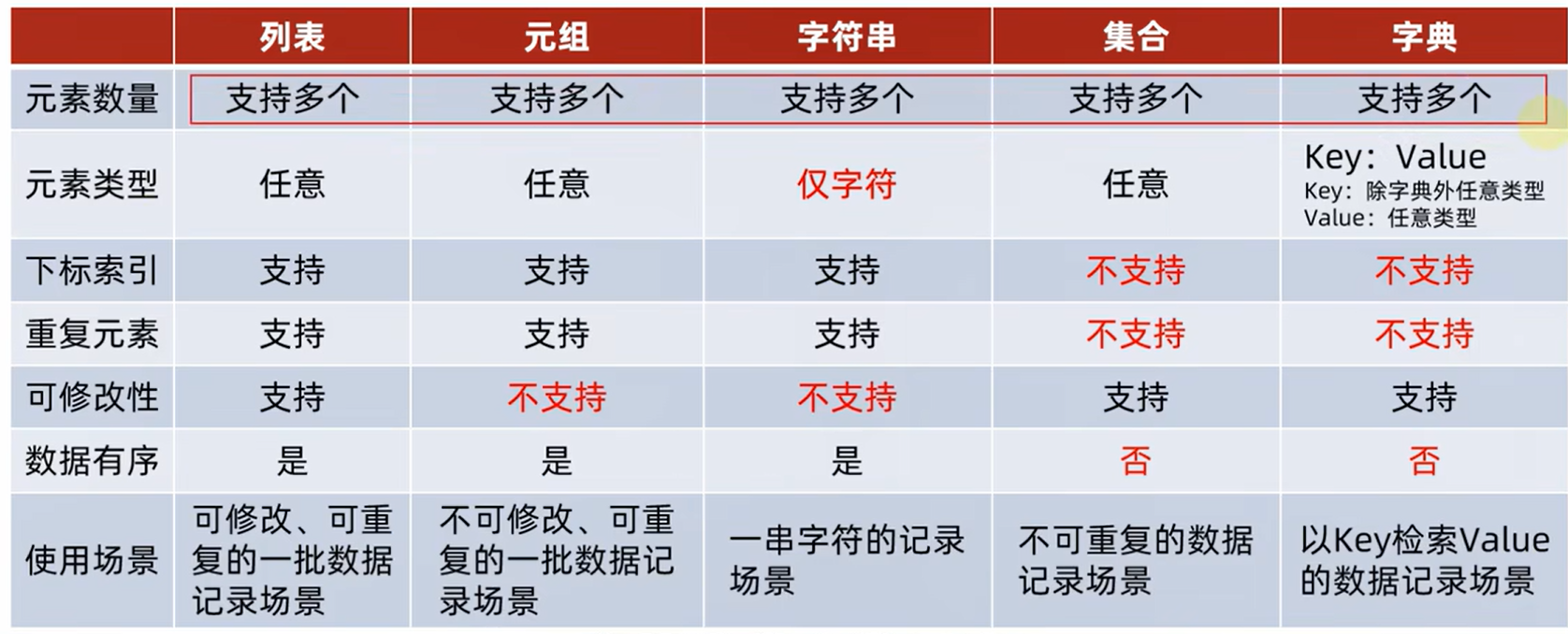
1.7.16数据容器的对比


1.7.17数据容器通用的操作
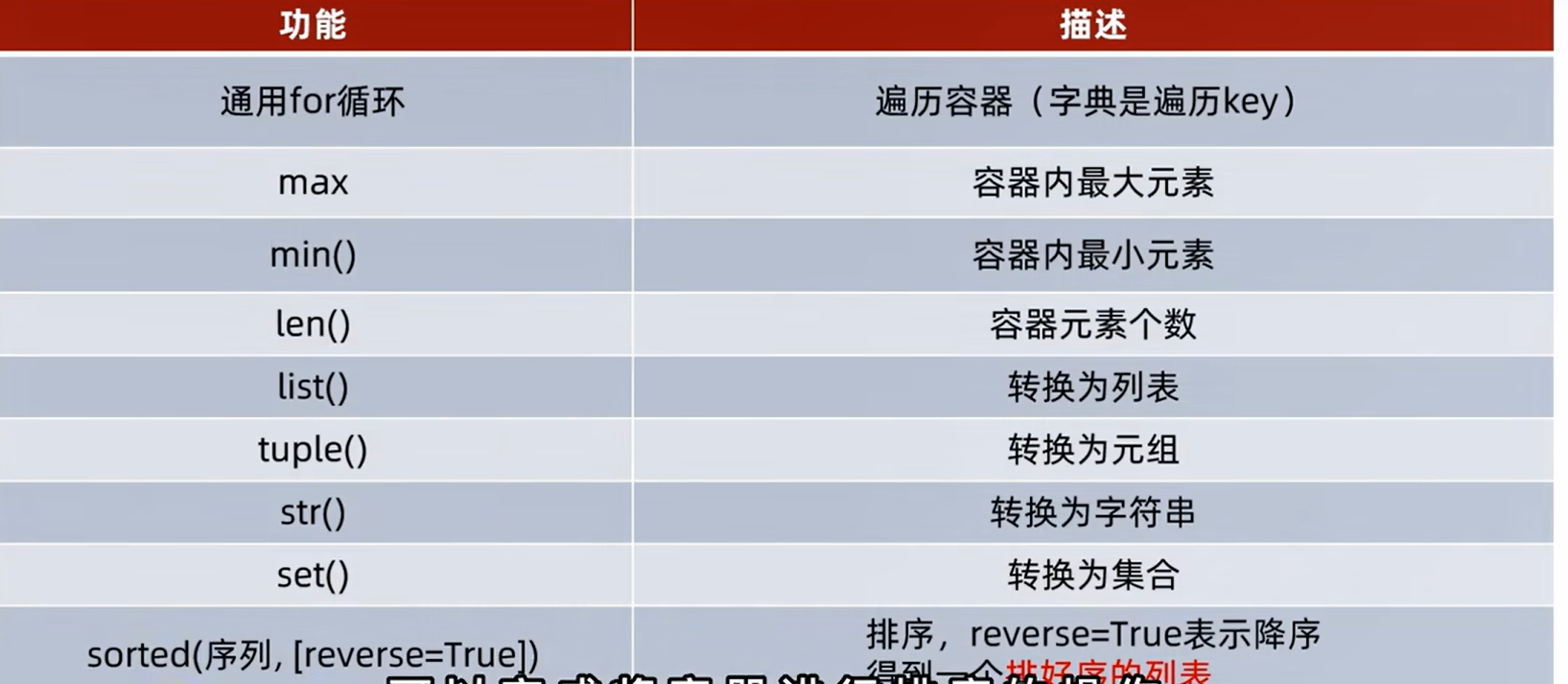
1.公用操作

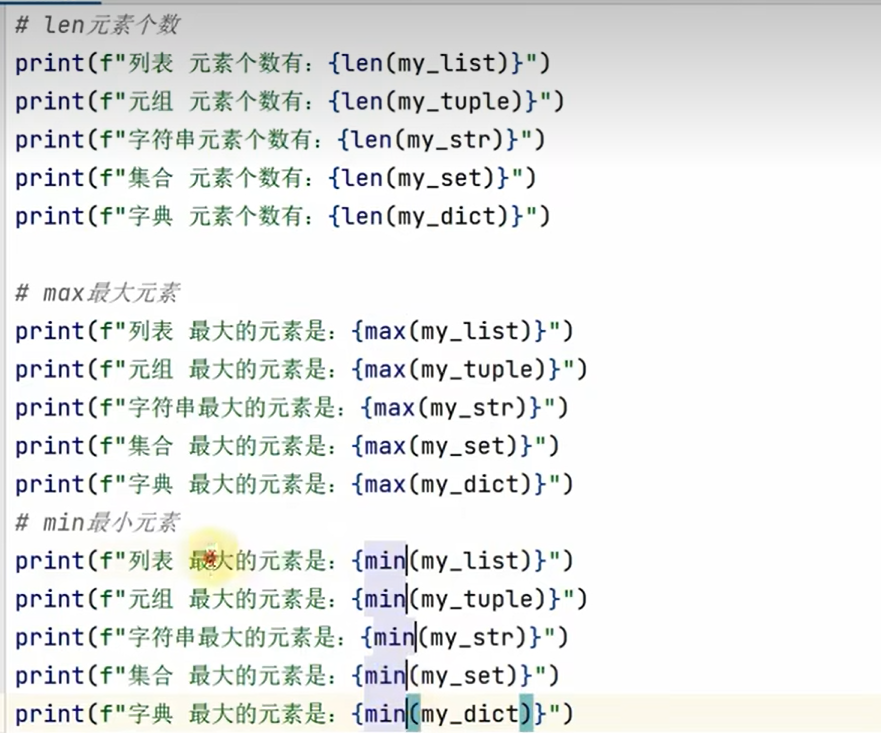
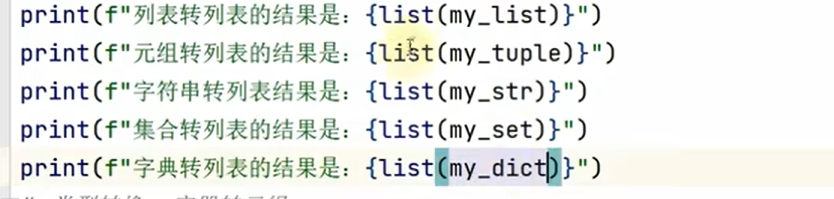
2.转换的
其实内容都是不变的就是变了表示的符号而已

3.排序操作
# 公用操作
l=[1,78,2,39,88,3,22]
print(l)
# 默认从小到大,字典排序的是key,排序后的结果放到list中
print(sorted(l))
# 从大到小,reverse=True表示反向排序
print(sorted(l,reverse=True))

4.小结
1.7.18字符串比较大小的方式
1.如何进行大小比较的
- 基于ascii表的
- 本质是基于码值的比较的

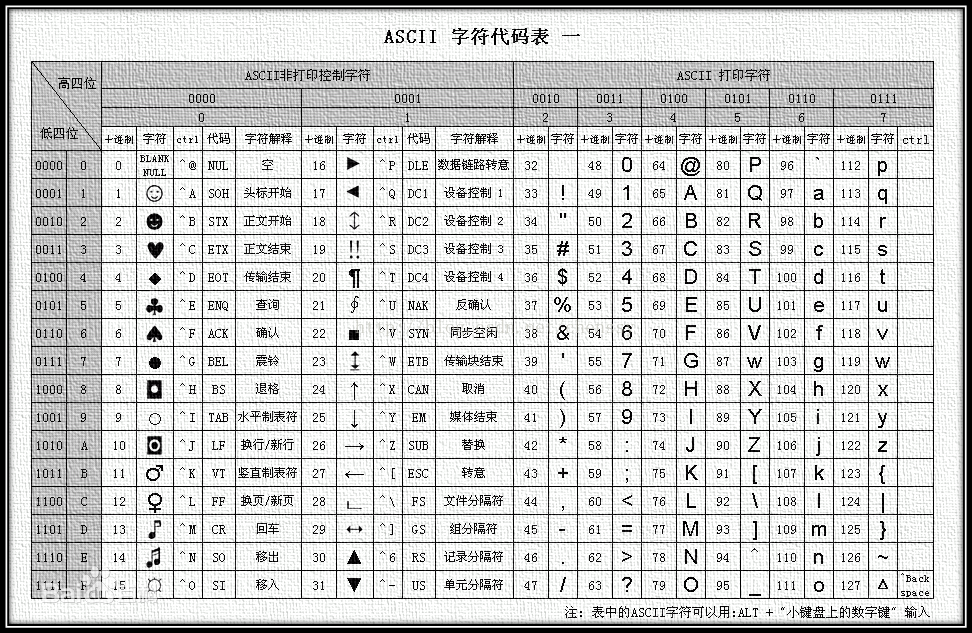
2.字符串的比较是按照位进行比较的
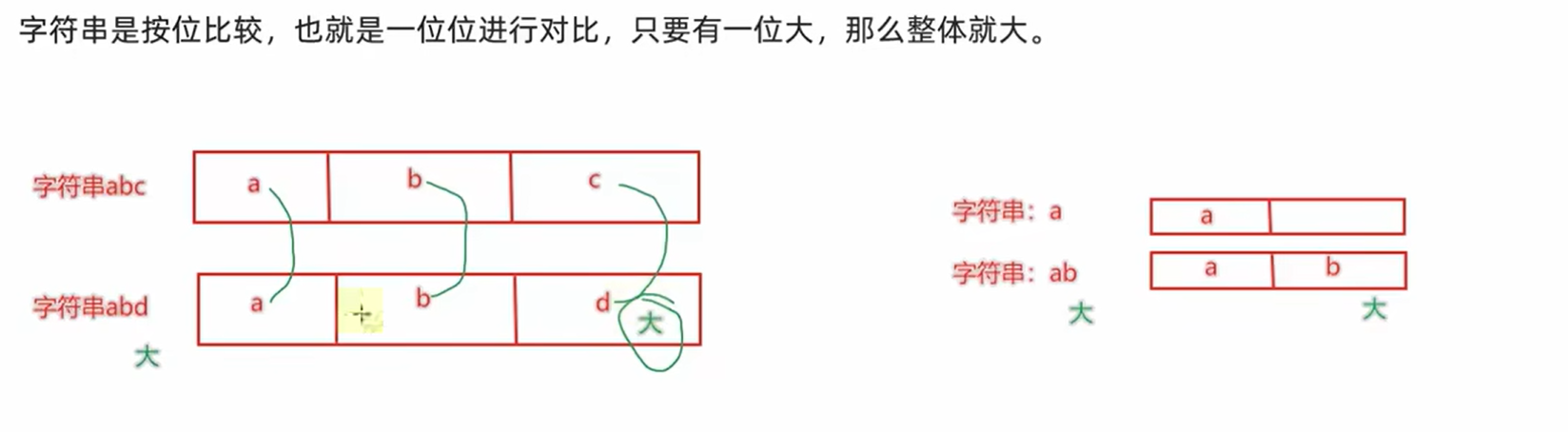
3.案例
# 字符串的比较
print('ab'>'abc')
print('ab'<'abc')

4.小结

















 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











