







第五章、网络层知识点01
一、概念
网络层是OSI参考模型中的第三层,介于传输层和数据链路层之间,它在数据链路层提供的两个相邻端点之间的数据帧的传送功能上,进一步管理网络中的数据通信,将数据设法从源端经过若干个中间节点传送到目的端,从而向传输层提供最基本的端到端的数据传送服务。
二、主要功能
虚电路分组交换和数据报分组交换、路由选择算法、阻塞控制方法、X.25协议、综合业务数据网(ISDN)、异步传输模式(ATM)及网际互连原理与实现。
1、分组与分组交换:把从传输层接收到的数据报文封装成分组(Packet,也称为“包”)再向下传送到数据链路层。
2、路由:通过路由选择算法为分组通过通信子网选择最适当的路径。
3、网络连接复用:为分组在通信子网中节点之间的传输创建逻辑链路,在一条数据链路上复用多条网络连接(多采取时分复用技术)。
4、服务选择:网络层可为传输层提供数据报和虚电路两种服务,但 Internet的网络层仅为传输层提供数据报一种服务
5、流量控制:通过流量整形技术来实现流量控制,以防止通信量过大造成通信子网的性能下降。
拥塞控制:当网络的数据流量超过额定容量时,将会引发网络拥塞,致使网络的吞吐能力急剧下降。因此需要采用适当的控制措施来进行疏导。
6、网络互连:把一个网络与另一个网络互相连接起来,在用户之间实现跨网络的通信。
7、分片与重组:如果要发送的分组超过了协议数据单元允许的长度,则源节点的网络层就要对该分组进行分片,分片到达目的主机之后,有目的节点的网络层再重新组装成原分组。
三、路由选择
通信子网为网络源节点和目的节点提供了多条传输路径的可能性。网络节点在收到一个分组后,要确定向下一节点传送的路径,这就是路由选择。在数据报方式中,网络节点要为每个分组路由做出选择;而在虚电路方式中,只需在连接建立时确定路由。确定路由选择的策略称路由算法。
LS算法
ls算法的步骤流程
采用LS算法时,每个路由器必须遵循以下步骤:
1、确认在物理上与之相连的路由器并获得它们的IP地址。当一个路由器开始工作后,它首先向整个网络发送一个“HELLO”分组数据包。每个接收到数据包的路由器都将返回一条消息,其中包含它自身的IP地址。
2、测量相邻路由器的延时(或者其他重要的网络参数,比如平均流量)。为做到这一点,路由器向整个网络发送响应分组数据包。每个接收到数据包的路由器返回一个应答分组数据包。将路程往返时间除以2,路由器便可以计算出延时。(路程往返时间是网络当前延迟的量度,通过一个分组数据包从远程主机返回的时间来测量。)该时间包括了传输和处理两部分的时间——也就是将分组数据包发送到目的地的时间以及接收方处理分组数据包和应答的时间。
3、向网络中的其他路由器广播自己的信息,同时也接收其他路由器的信息。
在这一步中,所有的路由器共享它们的知识并且将自身的信息广播给其他每一个路由器。这样,每一个路由器都能够知道网络的结构以及状态。
4、使用一个合适的算法,确定网络中两个节点之间的最佳路由。
在这一步中,路由器选择通往每一个节点的最佳路由。它们使用一个算法来实现这一点,如Dijkstra最短路径算法。在这个算法中,一个路由器通过收集到的其他路由器的信息,建立一个网络图。这个图描述网络中的路由器的位置以及它们之间的链接关系。每个链接都有一个数字标注,称为权值或成本。这个数字是延时和平均流量的函数,有时它仅仅表示节点间的跃点数。例如,如果一个节点与目的地之间有两条链路,路由器将选择权值最低的链路。
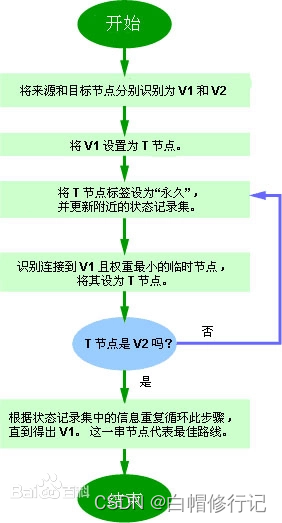
Dijkstra算法
Dijkstra算法执行下列步骤:1、路由器建立一张网络图,并且确定源节点和目的节点,在这个例子里我们设为V1和V2。然后路由器建立一个矩阵,称为“邻接矩阵”。在这个矩阵中,各矩阵元素表示权值。例如,[i, j]是节点Vi与Vj之间的链路权值。如果节点Vi与Vj之间没有链路直接相连,它们的权值设为“无穷大”。
2、路由器为网路中的每一个节点建立一组状态记录。此记录包括三个字段:
前序字段——表示当前节点之前的节点。
长度字段——表示从源节点到当前节点的权值之和。
标号字段——表示节点的状态。每个节点都处于一个状态模式:“永久”或“暂时”。
3、路由器初始化(所有节点的)状态记录集参数,将它们的长度设为“无穷大”,标号设为“暂时”。
4、路由器设置一个T节点。例如,如果设V1是源T节点,路由器将V1的标号更改为“永久”。当一个标号更改为“永久”后,它将不再改变。一个T节点仅仅是一个代理而已。
5、路由器更新与源T节点直接相连的所有暂时性节点的状态记录集。
6、路由器在所有的暂时性节点中选择距离V1的权值最低的节点。这个节点将是新的T节点。
7、如果这个节点不是V2(目的节点),路由器则返回到步骤5。
8、如果节点是V2,路由器则向前回溯,将它的前序节点从状态记录集中提取出来,如此循环,直到提取到V1为止。这个节点列表便是从V1到V2的最佳路由。
链路状态算法(也称最短路径算法)发送路由信息到互联网上所有的结点,然而对于每个路由器,仅发送它的路由表中描述了其自身链路状态的那一部分。
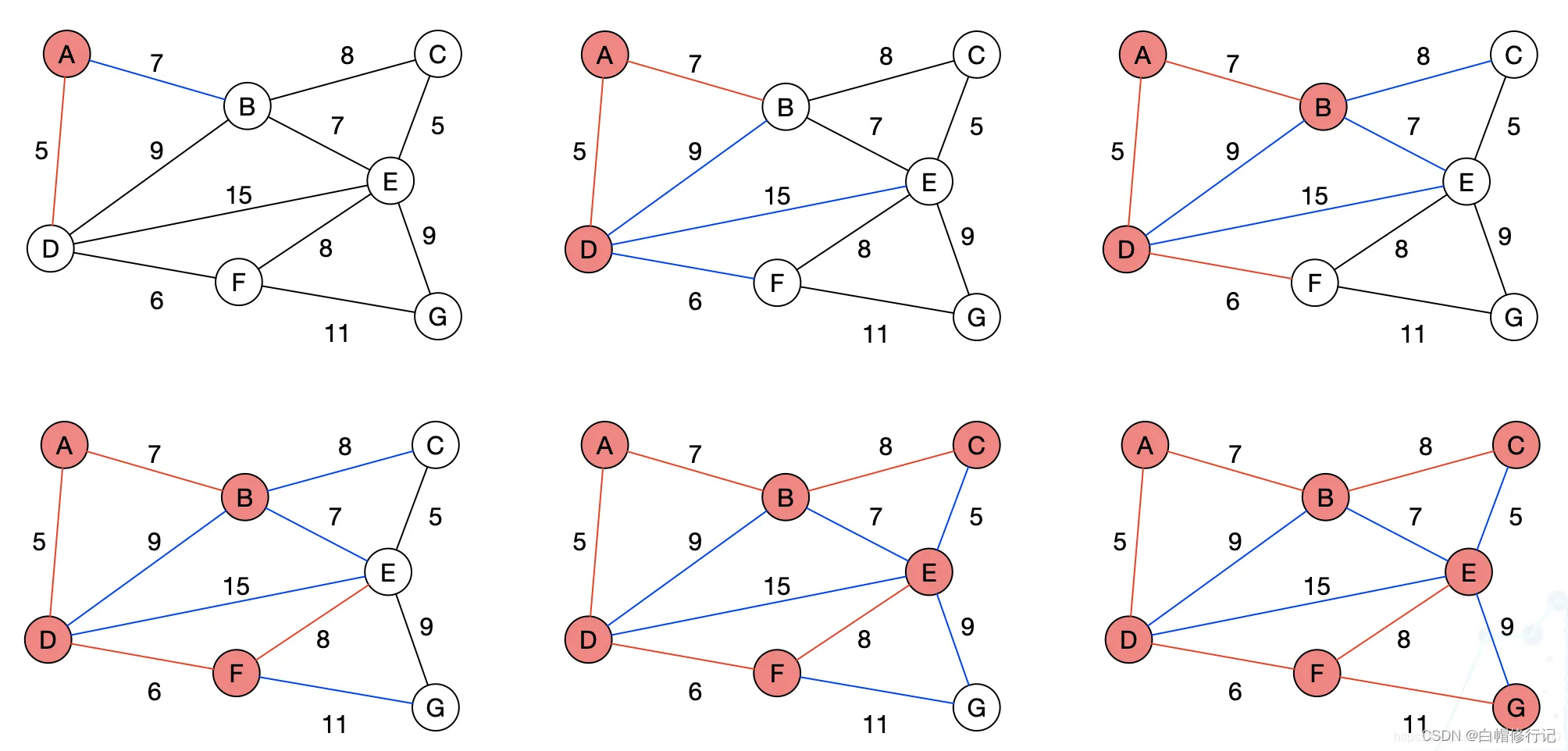
距离向量算法
距离向量算法(也称为Bellman-Ford算法)则要求每个路由器发送其路由表全部或部分信息,但仅发送到邻近结点上。从本质上来说,链路状态算法将少量更新信息发送至网络各处,而距离向量算法发送大量更新信息至邻接路由器。 ——由于链路状态算法收敛更快,因此它在一定程度上比距离向量算法更不易产生路由循环。但另一方面,链路状态算法要求比距离向量算法有更强的CPU能力和更多的内存空间,因此链路状态算法将会在实现时显得更昂贵一些。
四、IP数据报
IP协议控制传输的协议单元称为IP数据报(IP Datagram,IP数据报、IP包或IP分组)。IP协议屏蔽了下层各种物理子网的差异,能够向上层提供统一格式的IP数据报。lP数据报采用数据报分组传输的方式,提供的服务是无连接方式。IP数据报的格式能够说明lP协议具有什么功能。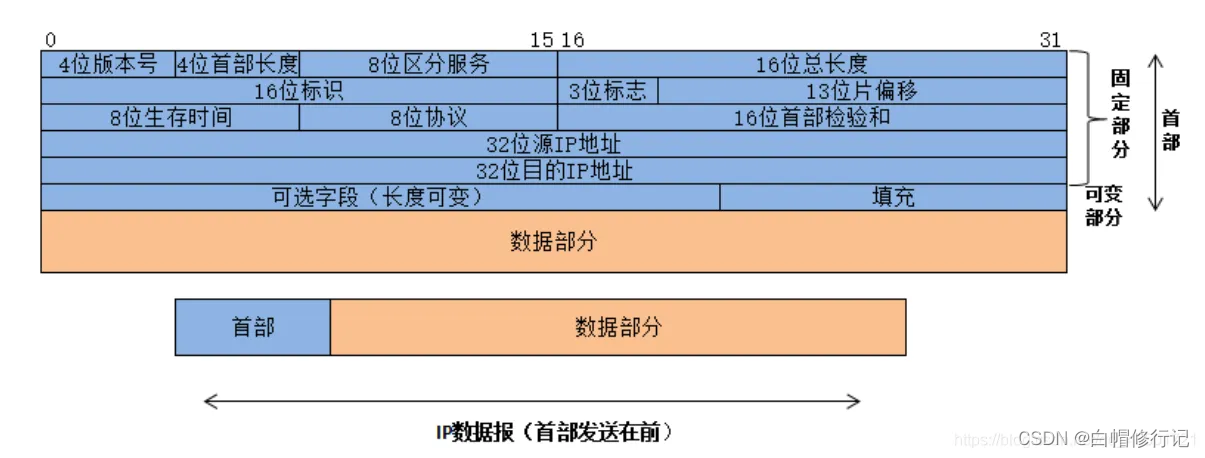
(1)版本 占4位,指IP协议的版本。通信双方使用的IP协议版本必须一致。广泛使用的IP协议版本号为4(即IPv4)。关于IPv6,还处于草案阶段。
(2)首部长度 占4位,可表示的最大十进制数值是15。请注意,这个字段所表示数的单位是32位字长(1个32位字长是4字节),因此,当IP的首部长度为1111时(即十进制的15),首部长度就达到60字节。当IP分组的首部长度不是4字节的整数倍时,必须利用最后的填充字段加以填充。因此数据部分永远在4字节的整数倍开始,这样在实现IP协议时较为方便。首部长度限制为60字节的缺点是有时可能不够用。但这样做是希望用户尽量减少开销。最常用的首部长度就是20字节(即首部长度为0101),这时不使用任何选项。
(3)区分服务 占8位,用来获得更好的服务。这个字段在旧标准中叫做服务类型,但实际上一直没有被使用过。1998年IETF把这个字段改名为区分服务DS(Differentiated Services)。只有在使用区分服务时,这个字段才起作用。
(4)总长度 总长度指首部和数据之和的长度,单位为字节。总长度字段为16位,因此数据报的最大长度为2^16-1=65535字节。
在IP层下面的每一种数据链路层都有自己的帧格式,其中包括帧格式中的数据字段的最大长度,这称为最大传送单元MTU(Maximum Transfer Unit)。当一个数据报封装成链路层的帧时,此数据报的总长度(即首部加上数据部分)一定不能超过下面的数据链路层的MTU值。
(5)标识(identification) 占16位。IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分片时,这个标识字段的值就被复制到所有的数据报的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报。
(6)标志(flag) 占3位,但只有2位有意义。
● 标志字段中的最低位记为MF(More Fragment)。MF=1即表示后面“还有分片”的数据报。MF=0表示这已是若干数据报片中的最后一个。
● 标志字段中间的一位记为DF(Don’t Fragment),意思是“不能分片”。只有当DF=0时才允许分片。
(7)片偏移 占13位。片偏移指出:较长的分组在分片后,某片在原分组中的相对位置。也就是说,相对用户数据字段的起点,该片从何处开始。片偏移以8个字节为偏移单位。这就是说,除了最后一个分片,每个分片的长度一定是8字节(64位)的整数倍。
(8)生存时间 占8位,生存时间字段常用的的英文缩写是TTL(Time To Live),表明是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在因特网中兜圈子,因而白白消耗网络资源。最初的设计是以秒作为TTL的单位。每经过一个路由器时,就把TTL减去数据报在路由器消耗掉的一段时间。若数据报在路由器消耗的时间小于1秒,就把TTL值减1。当TTL值为0时,就丢弃这个数据报。后来把TTL字段的功能改为“跳数限制”(但名称不变)。路由器在转发数据报之前就把TTL值减1.若TTL值减少到零,就丢弃这个数据报,不再转发。因此,TTL的单位不再是秒,而是跳数。TTL的意义是指明数据报在网络中至多可经过多少个路由器。显然,数据报在网络上经过的路由器的最大数值是255.若把TTL的初始值设为1,就表示这个数据报只能在本局域网中传送。
(9)协议 占8位,协议字段指出此数据报携带的数据是使用何种协议,以便使目的主机的IP层知道应将数据部分上交给哪个处理过程。
(10)首部检验和 占16位。这个字段只检验数据报的首部,但不包括数据部分。这是因为数据报每经过一个路由器,路由器都要重新计算一下首部检验和(一些字段,如生存时间、标志、片偏移等都可能发生变化)。不检验数据部分可减少计算的工作量。
(11)源地址 占32位。
(12)目的地址 占32位。















 286
286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









