







 在使用Scrapy爬虫时遇到HTTP status code is not handled or not allowed的问题,可以通过在settings.py文件中添加HTTPERROR_ALLOWED_CODES = [302]来解决,将报错的状态码添加到列表中即可。本文还介绍了Scrapy框架的一些默认设置和Python数据科学相关的实用技巧。
在使用Scrapy爬虫时遇到HTTP status code is not handled or not allowed的问题,可以通过在settings.py文件中添加HTTPERROR_ALLOWED_CODES = [302]来解决,将报错的状态码添加到列表中即可。本文还介绍了Scrapy框架的一些默认设置和Python数据科学相关的实用技巧。
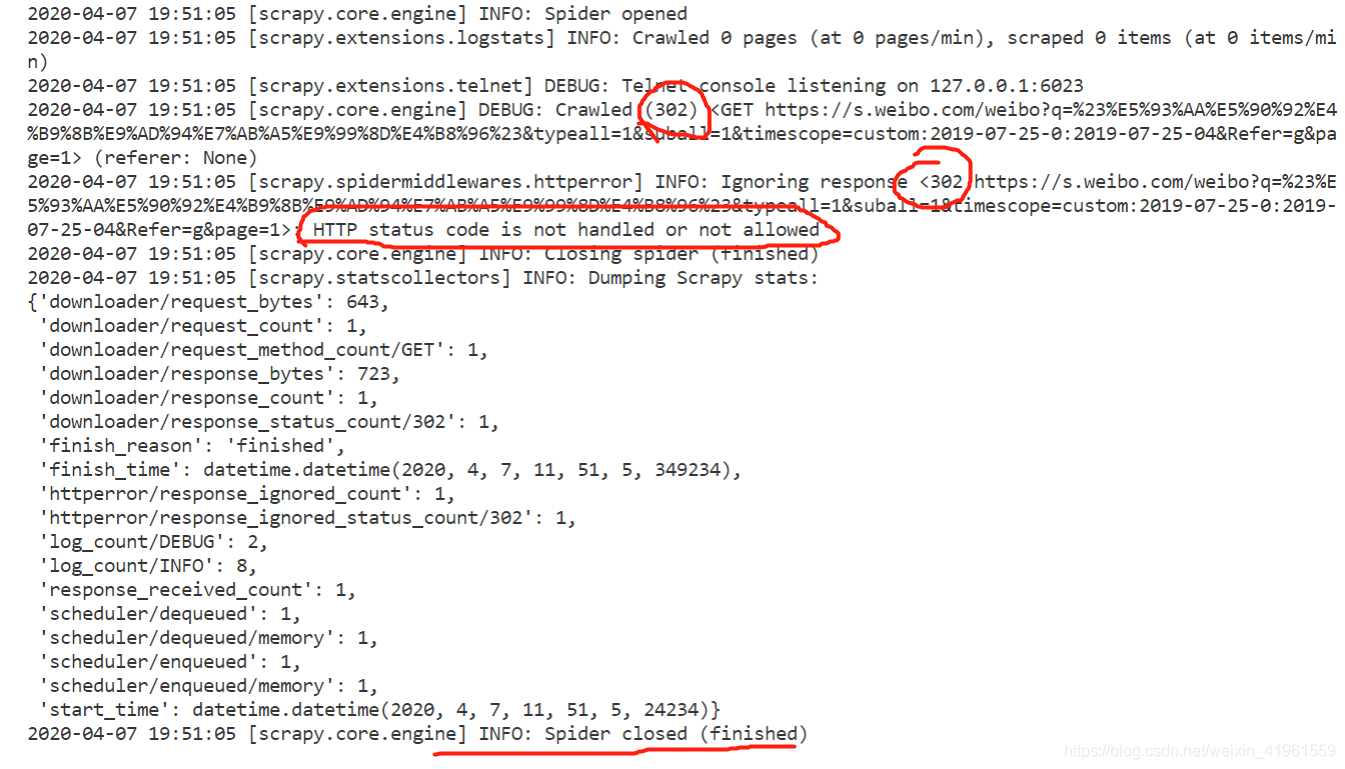
在scrapy爬虫的过程中出现 HTTP status code is not handled or not allowed 的问题导致爬虫无法继续,如下截图:
解决方式:
- 在settings.py文件中添加:
HTTPERROR_ALLOWED_CODES = [302]
- 截图中报错302,就在括号里添加302。若报错403就添加403。
附加说明:
- scrapy框架中有许多默认设置
- 可参阅:scrapy的settings设置(一)
相关笔记:
在scrapy爬虫的过程中出现 HTTP status code is not handled or not allowed 的问题导致爬虫无法继续,如下截图:
解决方式:
HTTPERROR_ALLOWED_CODES = [302]
附加说明:
相关笔记:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+





