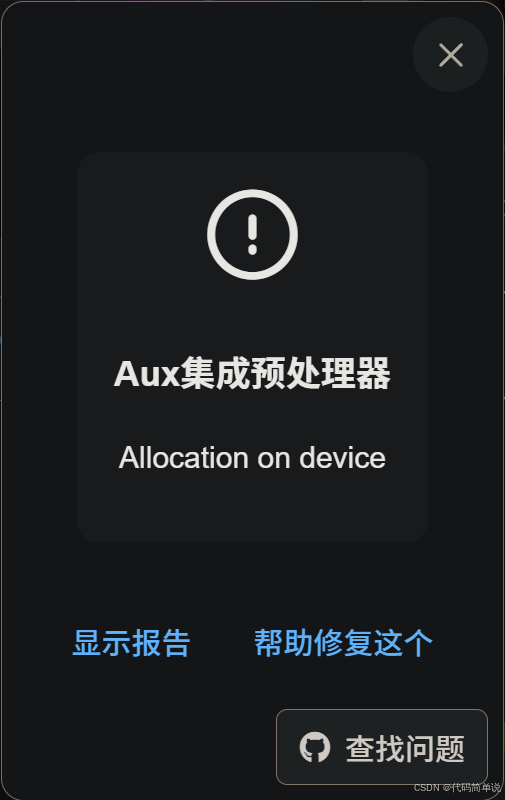
ComfyUI 提示Allocation on device 显存占满的解决方法及秋叶大佬整合包的优化方法 最近在玩ComfyUI的时候,发现一个让人崩溃的问题——VRAM一直占满,最终报错: Allocation on device 简单来说,就是显卡显存溢出了,导致程序无法继续运行。尤其是一些大模型或者复杂工作流,很容易让显存飙升到极限。那怎么办? 解决方案:加启动参数 直接在启动命令后加上 --disable-smart-memory,例如: python main.py --po










 订阅专栏 解锁全文
订阅专栏 解锁全文


















 5815
5815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








