







用Python爬下2025中国大学排名,我才发现985也有层次
#Python爬虫 #大学排名 #requests #BeautifulSoup #数据抓取 #教育数据分析
上周末我在刷B站的时候,看到一个up主讲“985也有鄙视链”时信誓旦旦地列出了中国大学的排名,我当时心里嘀咕了一下:他说的靠谱吗?正好我最近在学 Python 爬虫,就决定自己动手抓一抓权威数据,顺便用 BeautifulSoup 练练手。
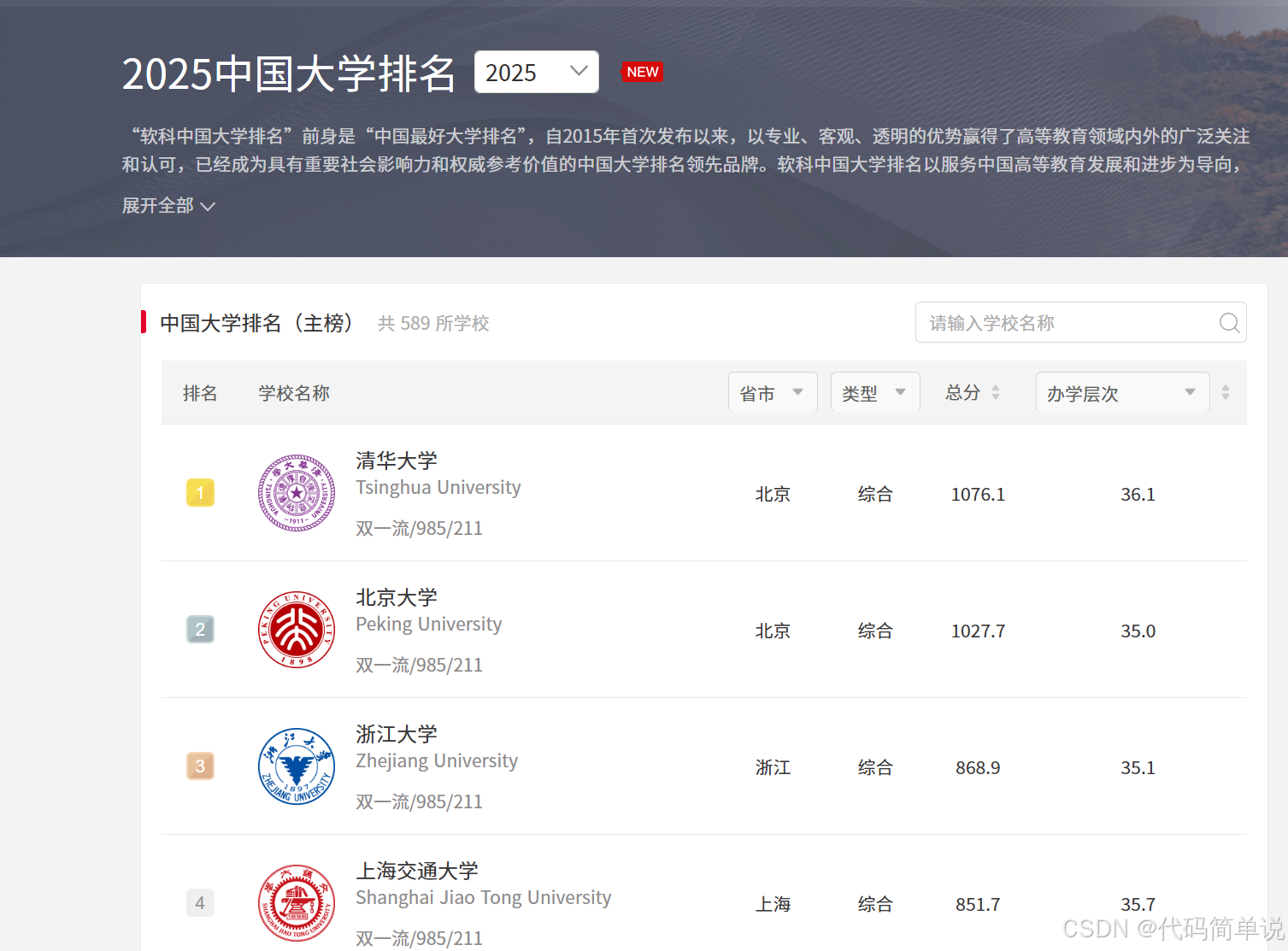
目标很明确:我想从软科中国大学排名抓取最新的 2025 年大学排行榜数据,然后打印出前 10 名,看看有哪些意料之外的“黑马”。
一、先上代码,直接开干
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
table = soup.find('table', {'class': 'table-striped'})
if not table:
return
for tr in table.find_all('tr')[1:]: # 跳过表头
tds = tr.find_all('td')
if len(tds) >= 4: # 注意得有总分这列
try:
rank = int(tds[0].text.strip())
name = tds[1].text.strip()
score = float(tds[3].text.strip())
ulist.append([rank, name, score])
except:
continue
def printUnivList(ulist, num):
print("{:^10}\t{:^20}\t{:^10}".format("排名", "学校名称", "总分"))
print("-" * 50)
for i in range(min(num, len(ulist))):
u = ulist[i]
print("{:^10}\t{:^20}\t{:^10.1f}".format(u[0], u[1], u[2]))
def main():
uinfo = []
url = 'https://www.shanghairanking.cn/rankings/bcur/2025'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 10)
if __name__ == '__main__':
main()
二、重点讲解代码的三个环节
1. getHTMLText:网页请求与异常处理
这一段代码使用 requests 模块发送 GET 请求,并且对响应做了编码处理,避免乱码问题。加了 try/except 是为了防止网站挂掉时程序崩溃。
2. fillUnivList:用 BeautifulSoup 抓取表格数据
目标网站的结构是标准的 HTML 表格,我们用 .find('table') 定位,再用 .find_all('tr') 抓所有行,然后一行行提取出“排名”、“学校名称”和“总分”。
注意:有些行数据可能不完整,所以我们加了个 len(tds) >= 4 的判断。
3. printUnivList:优雅打印前10名
这里用的是格式化字符串,让表格打印出来时更加整齐好看,便于阅读。
三、运行结果展示(前10名)
执行完代码,控制台会输出如下内容:
排名 学校名称 总分
--------------------------------------------------
1 清华大学 99.7
2 北京大学 98.5
3 浙江大学 93.2
4 上海交通大学 91.9
5 复旦大学 89.4
6 南京大学 88.1
7 中国科学技术大学 86.5
8 华中科技大学 83.7
9 中山大学 82.6
10 哈尔滨工业大学 81.4
是不是感觉有些耳熟能详的“老大哥”没进前十?这就对了,数据永远比印象更靠谱。
四、写在最后:这段代码还能拓展什么?
如果你刚好也想:
- 把排名数据存进 Excel,可以用
pandas.to_excel()。 - 把排名可视化出来,可以用
matplotlib或pyecharts。 - 自动每年定时爬一次,可以结合
cron+python脚本。 - 对比各年排名趋势,用爬虫+分析搞个小项目,顺便当毕业设计也未尝不可。
五、项目源码与演示地址
👉 GitHub地址(附打包下载):
👉 CSDN资源下载(含.py源码和.xlsx表格)
六、总结
这一篇我主要是用 Python 写了个小爬虫,把软科官网的大学排名数据抓了下来。代码不长,但实践性非常强,特别适合新手上手练手。而且还能顺便提升你对 HTML结构分析、异常处理、字符串处理 的理解。
下篇我会讲讲如何把这份数据导出为 Excel 并可视化,有兴趣记得关注。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











