







一、基础命令
| passwd | 修改密码 | chmod | 用来修改权限 |
| switch user | 切换用户 | .tar | 打包 |
| useradd -m 用户名 |
| .tar.bz2 | 压缩文件 |
| passwd 密码 | 添加用户 | date | 查看系统时间命令 |
| su -用户名 | 切换用户名 | hwclock | 查看硬件时间命令 |
| userdel + 用户名 | 删除用户 | timedatectl set-time | 修改系统时间 |
| exit | 退出 | ls –l(ll) | 查看目录 |
| pwd | 打印当前所在的目录 | whereis + 要查看的命令 | 查看某个命令所在的目录 |
| groupadd | 添加组 | ps | 监控后台工作情况 |
| reboot | 重启 | logout | 退出登录 |
| Shutdown [选项]时间 | 关机、重启 | systemctl | 服务管理(常用) |
| free | 查看内存 | Df -h | 查看磁盘空间 |
打包——就是将多个文件合并为一个文件 不过合并后的文件大小与原来的文件大小和几乎不变;
压缩文件——合并后大小会发生变化 变小;
修改系统时间——如果出现Failed to set time: Automatic time synchronization is enabled的提示 那么需要先关闭ntp自动校时;使用命令 timedatectl set-ntp no
再进行修改 修改完成后开启ntp自动校时 timedatetectl set-up yes;
Shutdown——关机重启建议使用shutdown比较的安全;一般服务器上有很多用户在使用,不可以直接进行关闭电源等操作;因为同时可能有很多人的硬盘都在高速运转,就容易崩。
Shutdown中的选项 有 –c 取消前一个关机命令、-h 关机、-r 重启;一般服务器只进行重启。
二、yum源
在windows上我们可通过360等对软件进行安装、卸载,并解决软件之间的依赖相关问题。Yum就是这种软件,只是运行在CentOS系统中的,使用yum我们就可以做到一个命令安装软件。软件安装包的来源我们称之为源,所以yum源就是软件安装包来源,打开centOS的压缩文件可以看到其中有一个package文件,其实有很多很多的软件安装包,就是本地yum源。
配置yum源:https://blog.csdn.net/no_ob/article/details/78668255
三、文件处理命令
Linux比windows要灵活,比如可以同时对多个文件进行同时拷贝(可不同路径下的),也可以在复制、剪切的时候进行改名等。
| . (一个点) | 当前目录 | ..(两个点) | 代表上一层目录 |
| -rw-r—r-- | R读 w写 x执行 | mkdir -p | 创建目录,p递归创建 |
| cd | Change directory | rmdir | 删除空目录 |
| cp -rp | 复制目录 r复制目录p 保留文件属性 | rm -rf | 删除文件或目录 r删除目录 f强制执行 |
| mv | 剪切、改名 | touch | 创建空文件 |
| tail –n f | 显示文件后几行 n 指定行数 f动态显示 | less | 分页显示文件内容(可向上翻页) |
| cat -n | 显示文件内容 n行号 | ln -s | 创建链接文件 –s创建软链接 |
| chmod 数字(744) 文件 | 改变文件权限 | chown 用户名 文件名 | 将该文件所有者转到该用户名 |
其中写的命令后跟的每一个字符都是可分开使用的。
软链接可理解为windows的快捷方式,只是一个简单的链接指向;硬链接相当于cp –p,区别是硬链接可以动态更新。
权限管理中r代表4,w代表2,x代表1 ;u代表所有者,g代表所属组,o代表其他人;还有种修改权限方式:chmod u+x g+w o-r (不常用)。
四、查找相关命令
首先find查找命令所消耗的系统资源比较多,所以在使用率比较高的情况下避免使用,但是他的查找又是比较稳定的。
命令:find 搜索范围 匹配条件
find /etc -name init 在目录etc中查找文件init
find /etc -iname init 不区分大小写搜索
find / -size 204800 在根目录中查找大于100MB文件 204800是数据块 1数据块=0.5kb
find /etc -cmin -5 在etc文件中查找5分钟内改动的文件
文件属性 cmin
文件内容 mmin
find /etc -size +163840 –a(-o) -size -204800 在/etc下查找大于80MB并且(或者)小于100MB的文件
locate -i 文件名 i代表不区分大小写 在文件资料库中查找文件(速度很快)(tmp临时文件中是查不到的)
updatedb 用来升级文件资料库 然后进行locate查找
grep 在文件内容中查找指定的字串,把他显示出来(很强大)
五、Vim常用操作
Vim有三种模式:命令模式,插入模式,编辑模式;
首先进入命令模式,输入a、A、i、I、o、O进入插入模式;esc从插入模式退出到命令模式;使用“:”从命令模式到编辑模式。
| vim 文件名 | 进入vi界面 | a | 在所在光标后输入 |
| A | 到所在行尾 | i | 在所在光标前输入 |
| I | 到所在行首 | o | 插入下一行 |
| O | 插入上一行 | gg | 到第一行 |
| G | 到最后一行 | :n | 到第n行 |
| x | 删除当前字符 | dd | 删除行(剪切行) |
| yy | 复制当前行 | p | 粘贴行 |
| u | 撤销上一个动作 | /字符串 | 搜索字符串所在位置 |
| :q! | 不保存退出 | :qw | 保存退出 |
| :q | 没操作,直接退出 |
|
|
Vim使用技巧:
定义快捷键:map 快捷键 触发命令
例如: : map ^p I#<etc> 在当前行首添加#注释(^p是由ctrl+v+p或者ctrl+v再ctrl+p所展示出来的)之后在该文件中输入ctrl+p就在行首打出注释;
:map ^B 0x<etc> 删除行首注释;
六、软件包管理
Windows中所有的包都不能在linux中进行安装;
软件包的分类:源码包和二进制包(就是rpm包,源代码包经过编译之后的包,不能再看到源码;系统默认包);
源码包:1、开源;
2、可以自由选择所需功能;
3、软件是编译安装,更适合自己的系统;
4、卸载方便;
5、安装步骤较多,容易出错;
6、编译时间较长;
7、安装过程报错,新手很难解决;
二进制包:1、包管理系统简单;
2、安装速度快;
3、看不到源码;
4、功能选择少;
5、依赖性强;
Rpm包是以.rpm结尾的,源码包是以tar.gz结尾的;
RPM包默认安装位置:
/etc/ 配置文件安装路径
/usr/bin/ 可执行的命令安装目录
/usr/lib/ 程序所使用的函数库保存位置
/usr/share/doc/ 基本的软件使用手册保存位置
/usr/share/man/ 帮助文件保存位置
源码包安装位置:
/usr/local/软件名/
安装位置的不同带来的影响
RPM包安装的服务可以使用系统服务管理命令(service)来管理;
service是不能管理源码包的,service只能去找到RPM包安装的路径;
所以源码包只能用绝对路径来进行管理,启动等;
源码包安装过程
1、安装准备 需要jcc的编译器(c语言的),下载相应的源码包(tar.gz);
2、源码包保存位置 /usr/local/src/ 软件安装位置 /usr/local/;
3、将软件包传到linux 并进行解压 (解压后的文件中的INSTALL和README两个文件很重要,对于陌生软件阅读他们进行安装及使用);
4、./configure 软件配置与检查
1)./configure --prefix=/usr/local/自己定义的文件 该命令表示安装在将源码包安装在该目录下;
5、make 进行编译;
6、make install 编译安装 (如果在前两部出错了,使用make clean进行清空即可);
7、使用绝对路径到安装位置 start 进行启动;
(在安装完成之后进行卸载,只要将安装的文件卸载就可以)
管理软件包的方式有两种:
1、rpm命令管理
rpm包管理方式最大的问题在于不断地有很多的依赖,安装会非常麻烦;
rpm安装命令:
rpm -ivh 包全名 -i(install) 安装;-v(verbose) 显示详细信息; -h(hash) 显示进度; --nodeps 不检测依赖性; 将i换成U update 就是升级;-e 卸载
2、yum在线管理
yum只要告诉他要装那个包,其他所有的依赖都会自动安装;使用光盘当成本地yum;缺点是部分产商对此会收取一定的费用;IP地址配置和网络yum源;
yum安装: yum -y install 包名
升级: yum -y update 包名 (如果不加包名,就是升级整个系统,慎用)
卸载: yum -y remove 包名 (导致所有依赖的包都卸载了,慎用)
光盘yum源搭建(常用的安装yum的方式)
其实就是使用光盘中所有已存在的包;
光盘yum源由于是光盘安装的,所以需要进行一些配置;
1、挂载镜像: mount /dev/cdrom /mnt/cdrom
2、让网络yum源文件失效: cd /etc/yum.repos.d/ 将该目录中的除了Medis的都进行后缀名改名,目的是让他们都失效;
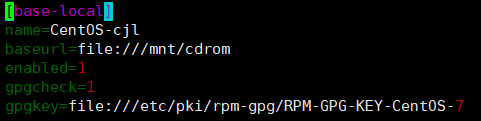
3、修改光盘yum源生效: vim CentOS-Media.repo 其中最重要的是enabled=1
七、分区和文件系统管理
分区与文件系统
主分区:总共最多只能有四个;(一个大柜子只能分为4个小柜子);
扩展分区:只能有一个;(只能其中一个柜子进行分隔;扩展分区中的是逻辑分区);
文件系统常用命令
| df -h | 文件系统查看命令 |
| du –sh [目录路径] | 统计目录或文件总大小 |
| fsck [选项] 分区设备文件名 | 文件系统修复命令(不建议使用) |
| dumpe2fs [分区设备文件名] | 显示磁盘状态命令 |
挂载——设备文件名与盘符(挂载点)进行联通;
| mount | 查询与自动挂载点 |
| mkdir /mnt/cdrom | 建立挂载点(盘符) |
| mount /dev/sr0 /mnt/cdrom/ | 挂载光盘 |
| umount /mnt/cdrom | 卸载命令 |
缓存(cache)—— 将数据保存在内存中,加速数据的读取过程;
缓冲(buffer)—— 在写入数据时,将分散的写入操作保存到内存中,达到一定程度再集中写入硬盘,加速数据写入过程;
八、Shell脚本
shell概述
shell是一个命令行解析器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序,用户可以用shell来启动、挂起、停止甚至是编写一些程序;
shell将我们的命令转换成机器可识别的二进制命令,又能将机器的命令转换成我们能认识的命令;
其实我们使用的交互命令就可以称为shell,其实window中我们使用的图形交互界面也是类似于shell,否则我们做的任何操作,机器都不能识别;
shell还是一个功能相当强大的编程语言,易编写,易调试,灵活性较强;Shell是解释执行(不需要先编译而是直接执行)的脚本语言,在Shell中可以直接调用Linux系统命令;
shell的分类:Bourne Shell ;在linux中识别为sh;
C Shell:主要用在BSD版中,其语法和C语言相似而得名;
这两种主要语法彼此不兼容;Bourne家族主要包括sh、ksh、bash、psh、zsh;C家族主要包括:csh、tcsh;我们使用的shell主要是bash的shell,比较主流;
sh命令 切换到bash下, exit 退出;
shell脚本的执行方式
echo [选项] [输出内容]
echo –e “ab\bc” 输出ab
| echo | 输出命令 | -e | 支持反斜杠控制字符转换 |
| \\ | 输出\本身 | \a | 输出警告音 |
| \b | 退格键 | \r | 换页符 |
| \n | 换行符 | \r | 回车键 |
Shell脚本编写:
#!/bin/Bash 这句话是所有bash脚本第一句必须写的(这句话是标识,不是注释);代表以下写的是shell脚本;
| 第一个shell脚本: |
| #!/bin/Bash #Author:chenjingling 注释 echo -e "hello world" |
使用两种方式运行脚本:1、先chmod 755 hello.sh 再使用相对或绝对路径运行 ./hello.sh; 2、使用bash hello.sh进行运行;
注:如果脚本是在windows中写好放到linux中执行是有问题的,因为windows中的回车符表示与linux回车符是不一样的;使用doc2unix 文件名来从windows格式转换为linux格式;不过需要先安装该工具,使用yum安装;
bash的基本功能
| history 可以查看敲过得历史命令 | history [选项] [历史命令保存文件] |
| -c 清空历史命令 | 上下箭头找到之前使用的命令; |
| -w 把缓存中的历史命令写入历史命令保存文件 ~/.bash_history | |
| !!重复执行上一条命令; | tab键进行自动补全; |
| alias 别名 = '原命令' 将原命令设置为简单方便的别名 | |
| vi /root/.bashrc 让别名永久生效 (在其中进行添加) | |
| alias 查询命令别名 | unalias 别名 删除别名 |
命令的执行顺序:
第一顺位使用绝对路径或者相对路径就执行原命令;
第二顺位其次就优先使用别名;
第三顺位执行bash的内部命令;
Bash常用快捷键
| ctrl + c 强制终止当前命令 | ctrl + l 清屏,相当于clear命令 |
| ctrl + u 删除或剪切光标之前的命令 | ctrl + k 删除或剪切光标之后的命令 |
| ctrl + y 粘贴u、k剪切的内容 | ctrl + r 搜索历史命令 |
| ctrl + d 退出当前终端 |
|
多命令顺序执行:
: 命令1 :命令2 代表多个命令顺序执行,命令之间没有任何逻辑联系
&& 命令1 && 命令2 逻辑与 只有前一个命令正确后一个命令才能执行
|| 命令1 || 命令2 逻辑或 只要前一个命令执行错误,后一个命令才能执行
管道符:
| 命令1|命令2 命令1的正确输出作为命令2的操作对象
bash的变量
变量分类:
- 用户自定义变量;
- 环境变量:这种变量中主要保存的是和系统操作环境相关的数据;
3、 位置参数变量:这种变量主要是用来向脚本当中传递参数或数据的,变量名不能自定义,变量作用是固定的;
4、 预定义变量:是bash中已经定义好的变量,变量名不能自定义,变量作用也是固定的;
用户自定义变量(本地变量):
在bash中,变量的默认类型都是字符串型,如果要进行数值运算,则必须指定变量类型为数值型;
对变量进行赋值,等号两边不能有空格;
变量的值要是有空格,需要使用引号;
如果需要增加变量的值,可以进行值的叠加;不过要用"$变量名"或者用${变量名}进行包含;
如果把命令的结果作为变量值赋予变量,则需要使用反引号或者$()包含命令;
echo $变量名 调用该变量;
set 查看系统当中所有的变量;
unset name 变量删除;
环境变量:
部分环境变量是系统固定的变量;作用域为当前shell和所有子shell中都有作用;如果写入配置文件,会对所有的shell中生效;
export 变量名=变量值 申明变量;
env 查询变量;
unset 变量名 删除变量;
位置参数变量:
| $n n为数字,$0代表命令本身,$1-$9代表第一到第九个数;10以上的用${n}; | |
| $* 把命令行中所有参数看成一个整体 | |
| $@ 把每个参数区分对待 | $# 命令行中所有参数的个数 |
预定义变量:
位置参数变量其实就是预定义变量中的一种;
| $? 判断上一次执行命令的返回结果;如果是0代表执行正确,如果是1代表执行错误; | |
| $$ 当前进程的进程号(PID); | $! 后台运行的最后一个进程的进程号(PID); |
| read [选项] [变量名] 接受键盘输入 |
|
| -p “提示信息” :在等待read输入时,输出提示信息; | |
| -t 秒数: read命令会一直等待用户输入,使用此项可以指定等待时间; | |
| -n 字符串: read命令只接受指定的字符串,就会执行; | |
| -s : 隐藏输入的数据,适用于机密信息的输入; | |
bash的运算符
数值运算与运算符
| declare [+/-][选项] 变量名 声明变量类型; | |
| - :给变量设定类型属性; | + :取消变量的类型属性; |
| -i :将变量声明为整数型; | -x :将变量申明为环境变量; |
| -p :显示指定变量的被申明的类型; |
|
| 还可以使用 $((运算式)) 或者 $[运算式] 其中的运算式与数学一样,比较方便; | |
变量测试与内容替换
作用:在写脚本的时候可以用来判断某个值是否存在等操作;
例如: x=${y-新值} x=新值 表示变量y没有设置; x为空 表示变量y值为空值; x=$y 表示变量y设置了值;
九、Shell编程基础
基础正则表达式
正则表达式用来在文件中匹配符合条件的字符串,正则是包含匹配;grep、awk、sed等都支持正则表达式;
通配符用来匹配符合条件的文件名,通配符是完全匹配;ls、find、cp这些不支持正则表达式,只用来支持通配符;
基础正则表达式
| * 前一个字符匹配0次或任意多次 | . 匹配除了换行符外任意一个字符 |
| ^ 匹配行首 | $ 匹配行尾 |
| [ ] 匹配中括号中指定的任意一个字符,只匹配一个字符 | |
| [^] 匹配除中括号中的字符以外的任意一个字符 | |
| \ 转义附 | \{n\} 表示其前面的字符恰好出现n次 |
| \{n,m\} 表示其前面的字符至少出现n次,最多出现m次 | |
要使用支持正则表达式的方式:grep、awk、sed;
字符截取命令
cut字段提取命令、awk命令、sed命令;
cut字段提取命令:
cut [选项] 文件名
-f 列号: 提取第几列
-d 分隔符: 按照指定分隔符分割列
cut命令只能针对制表符进行提取,不能对空格符进行提取;
awk命令:
printf '输出类型输出格式' 输出内容
输出类型:
%ns: 输出字符串;n是数字指代输出几个字符;
%ni: 输出整数;n是数字指代输出几个数字;
%m. nf: 输出浮点数;m和n是数字;指代输出的总位数,与小数所占位数;
输出格式:
\n : 换行;
\r : 回车,也就是enter键;
\t : 水平输出退格键,也就是tab键;
这是awk中的基本命令;
awk命令功能强大,只是书写比较复杂
awk ‘条件1{动作1} 条件2{动作2}...’ 文件名
例如: df -h | awk '{print $2 "\t" $5 }'
sed命令:
sed是一种几乎包括在所有UNIX平台(包括Linux)的轻量级流编辑器。sed主要是用来将数据进行选取,替换,删除,新增的命令;
sed [选项] '[动作]' 文件名
-n 一般sed命令会把所有数据输出到屏幕,如果加入此选择,则只会把经过sed命令处理的行输出到屏幕
-e 允许对输入数据应用多条sed命令编辑
-i 用sed修改结果直接修改读取数据的文件,而不是由屏幕输出
动作:
a \ :追加,在当前行后添加一行或多行。添加多行时,除最后一行外,每行末尾需要用“\”代表数据未完结;
c \ :行替换,用c后面的字符串替换原数据行,替换多行时,除最后一行外,每行末尾需用“\”代表数据未完结;
i \ :插入,在当期行前插入一行或多行;插入多行时,除最后一行外,每行末尾需用“\”代表数据未完结;
d :删除,删除指定的行;
p :打印,输出指定的行;
s :字串替换,用一个字符串替换另一个字符串。格式为: 行范围s/旧字串/新字串/g;
主要作用还是用来命令输出;
字符处理命令
sort [选项] 文件名
| -f 忽略大小写 | -r 反向排序 |
| -n 以数值型进行排序,默认使用字符串型排序 | |
| -t 指定分隔符,默认是分隔符的制表符 | |
| -k n[,m] 按照指定的字段范围排序;从第n字段开始,m字段结束(默认到行尾) | |
wc [选项] 文件名
| -l 只统计行数 | -w 只统计单词数 |
| -m 只统计字符数 |
|
条件判断
1、按照文件类型进行判断
-d 文件 判断该文件是否存在,并且是否为目录文件(是目录为真);
-e 文件 判断该文件是否存在(存在为真);
-f 文件 判断该文件是否存在,并且是否为普通文件(是普通文件为真);
两种方式:1、 test -e 文件 2、 [-e 文件] (这种在脚本文件中常用);
再去使用echo $? 获取上一条命令的结果;
2、按照文件权限进行判断
-r 文件 判断该文件是否存在,并且是否该文件拥有读权限(有读权限为真);
-w 文件 判断该文件是否存在,并且是否该文件拥有写权限(有写权限为真);
-x 文件 判断该文件是否存在,并且是否该文件拥有执行权限(有执行权限为真);
例如: [ -w /sh/student.txt ] && echo yes || echo no
3、两个文件之间进行比较
文件1 -nt 文件2 判断文件1的修改时间是否比文件2的新(如果新则为真);
文件1 -ot 文件2 判断文件1的修改时间是否比文件2的旧(如果旧则为真);
文件1 -ef 文件2 判断文件1是否和文件2的Inode号一致,可以理解为两个文件是否是同一个文件;一般用于判断硬链接;
4、两个整数之间的比较
| 整数1 -eq 整数2 相等为真 |
| 整数1 -ne 整数2 不相等为真 |
| 整数1 -gt 整数2 1大为真 |
| 整数1 -lt 整数2 1小为真 |
| 整数1 -ge 整数2 1大于等于为真 |
| 整数1 -le 整数2 1小于等于为真 |
5、字符串之间的比较
-z 字符串 判断字符串是否为空(空位真);
-n 字符串 判断字符串是否为非空(非空为真);
字符1==字符2 相等为真;
字符1 != 字符2 不等为真;
6、多重条件判断
判断1 -a 判断2 逻辑与,判断1和判断2都成立,最终的结果才是真;
判断1 -o 判断2 逻辑或,判断1和判断2有一个成立,最终的结果为真;
! 判断 逻辑非,使原始的判断式取反;
流程控制
1、if语句
单分支if条件语句
if [ 条件判断式 ];then
程序
fi
或者使用
if [ 条件判断式 ]
then
程序
fi
双分支if条件语句
if [ 条件判断式 ]
then
条件成立时,执行的程序
else
条件不成立时,执行的另一个程序
fi
多分支if条件语句
if [ 条件判断式1 ]
then
当条件判断式1成立时,执行程序1
elif [ 条件判断式2 ]
then
当条件判断式2成立时,执行程序2
else
条件不成立时,执行的另一个程序
Fi
2、case语句
case $变量名 in
"值1“)
如果变量的值等于值1,则执行程序1
;;
“值2”)
如果变量的值等于值2,则执行程序2
;;
......
*)
如果不是以上所有的值,执行此程序
;;
Esac
3、for循环
语法1:
for 变量 in 值1 值2 值3...
do
程序
done
语法2:
for((初始值;循环控制条件;变量变化))
do
程序
Done
4、while循环与until循环
while [ 条件判断式 ]
do
程序
done
until循环与while循环相反,不成立一直循环,直到循环成立,终止循环;
until [ 条件判断式 ]
do
程序
Done
十、备份与恢复
dump [选项] 备份之后的文件名 原文件或目录
| -level 就是我们说的0-9十个备份级别; |
| -f 文件名 指定备份之后的文件名; |
| -u 备份成功之后,把备份时间记录在/etc/dumpdates文件 |
| -v 显示备份过程中更多的输出信息 |
| -j 调用bzlib库压缩备份文件,其实就是把备份文件压缩为.bz2格式 |
| -W 显示允许被dump的分区的备份等级及备份时间 |
restore [模式选项] [选项]
模式选项:(只能选一个)
-C 比较备份数据和实际数据的变化
-i 进入交互模式,手工选择需要恢复的文件
-t 查看模式,用于查看备份文件中拥有哪些数据
-r 还原模式,用于数据还原
选项:
-f 指定备份文件的文件名















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









