






链接
解读:
https://cloud.tencent.com/developer/article/2057531?from=article.detail.1035412
引言
现有的one-shot人脸重现方法要么在大的位姿变换中出现明显的伪影,要么不能很好地保留源图像中的身份信息,要么由于计算量大而不能满足实时应用的要求。涉案。在本文中,我们介绍了 Face2Faceρ,第一个实时高分辨率和一次性(RHO,ρ)人脸重演框架。为了实现这一目标,我们设计了一种新的基于 3DMM 辅助变形的人脸重演架构,该架构由两个快速高效的子网络组成,即一个 u 形渲染网络,用于重演由头部姿势和面部运动场驱动的面部,以及一个分层的粗到细运动网络,用于预测由不同尺度的地标图像引导的面部运动场。与现有的最先进的作品相比,Face2Faceρ 可以产生相同或更好的视觉质量的结果,但时间和内存开销显着减少。我们还证明,Face2Faceρ 可以在桌面 GPU 上实现 1440 × 1440 分辨率的人脸图像和在移动 CPU 上实现 256 × 256 分辨率的人脸图像的实时性能
关键词:人脸再现,一次性,实时,高分辨率
介绍
面部重演是合成源演员的逼真图像的任务,头部姿势和面部表情与指定的驾驶演员同步。这种技术在媒体和娱乐应用方面具有巨大潜力。传统的重演解决方案 [1] 通常依靠昂贵的 CG 技术为源演员创建高保真数字化身,并通过动作捕捉系统将驾驶演员的面部动作转移到数字化化身上。为了绕过昂贵的图形管道,已经提出了基于图像的方法,该方法使用图像检索和混合算法 [8,35,38]、生成对抗网络 [16,17,19,46] 或神经纹理合成重新生成的人脸[36,37]。然而,所有这些方法都需要源演员的大量视频片段(即几分钟或几小时),这在实际应用场景中通常是不可行的。

图 1 Face2Faceρ 合成的 One-shot 人脸重现结果。左:在桌面 GPU(Nvidia GeForce RTX 2080Ti)上以 25 fps 生成的 1440×1440 分辨率图像;图片来源网络。右图:在移动 CPU (Qualcomm Kryo 680) 上以 25 fps 生成的 256 × 256 分辨率图像。请注意,每帧所需的所有计算(例如,面部标志检测、形状和表情回归等)的时间开销都计入了 fps 计算,而不仅仅是合成模块。
因此,已经开发了少镜头/单镜头解决方案,它可以仅使用少量示例面部图像来为看不见的演员制作动画。这些方法背后的关键思想是将演员的面部外观和运动信息与两个独立的编码解耦,从而允许网络以自我监督的方式从大量视频数据中学习面部外观和运动先验。根据运动信息在网络中的编码方式,经典算法可以分为两类[24,49],即基于翘曲和直接合成。基于扭曲的方法 [2,32,33,34,45] 学习基于明确估计的运动场扭曲源面部,而直接合成方法 [5,27,50,52] 将外观和运动信息编码为一些低维潜在表示,然后通过从相应的潜在代码中解码来合成重新生成的图像。尽管两者都能够产生照片般逼真的重演结果,但每种方法都有其优点和缺点。基于翘曲的技术非常适合小范围的运动,但当出现大的姿势变换时可能很容易中断。相反,直接合成解决方案对较大的姿势变化具有更好的鲁棒性,但合成人脸的整体保真度往往低于基于扭曲的方法产生的人脸,例如,即使源演员的身份也可能不是保存完好[7]。
在此背景下,后续在 one-shot 人脸重现方面的研究主要集中在实现各种姿势的高保真重现结果。例如,Meshry 等人。 [24] 通过额外采用与演员面部布局有关的编码来缓解直接合成方法中的身份保持问题,Wang 等人。 [43] 在基于翘曲的方法中加入 3D 运动场,以提高大姿势的性能,Doukas 等人。 [7] 提出了一种混合框架,通过将扭曲的外观特征注入典型的直接合成主干中,使两种类型的方法可以相互补充。尽管这些策略提高了生成图像的整体质量,它们还显着增加了网络的计算复杂性。据我们所知,目前最先进的一次性方法都不能成功地适应实时应用程序的要求,特别是在移动设备上。唯一报告几乎没有达到 25 fps 推理速度的算法是 [49],但考虑到面部标志检测、GPU-CPU 复制操作等的额外计算成本,它仍然无法支持实时面部重演系统。此外,[49] 为速度牺牲了太多质量,因为质量产生的结果明显低于最先进的水平。
在本文中,我们解决了一次性人脸重现中的一个新的具有挑战性的问题,即构建一个可以产生最先进质量结果的实时系统。为了实现这一目标,我们引入了 Face2Faceρ,第一个实时高分辨率和一次性人脸重现框架。具体来说,Face2Faceρ 可以以 25 fps 的速度重新生成桌面 GPU 上 1440 × 1440 分辨率和移动 CPU 上 256 × 256 分辨率的图像(见图 1)。该框架背后的关键思想是基于扭曲的主干在构建轻量级重演框架方面具有更好的潜力,因为扭曲的特征图已经描绘了目标人脸的大部分部分,从而使生成器的任务相对容易(即,精炼和绘画)来学习。本着这种精神,我们提出了一种结合基于翘曲和直接合成方法的新方法,即将 3D 头部姿势编码注入到轻量级的基于 u 形翘曲的主干中。此外,我们引入了一种新颖的分层运动预测网络,该网络根据地标图像的不同尺度从粗略到精细地估计所需的运动场。这样的设计在渲染和运动场预测方面都实现了 3 倍以上的加速,而不会损害视觉质量或预测精度。我们的实验还表明,Face2Faceρ 能够以比现有方法显着减少的时间和内存开销来执行最先进的人脸重演。
2. 相关工作
我们在本节中简要回顾了以前的几次/一次性方法。如前所述,现有方法可以从字面上分为基于翘曲的方法、直接合成方法和混合方法。
基于仿射的方法。这些方法使用显式运动场表示姿势和表情变换,然后根据估计的运动场学习扭曲和合成目标人脸。早期的方法 [45] 通常直接在源图像上进行变形,这通常会导致不自然的头部变形。 Siarohin 等人介绍了一个更新的基于翘曲的框架。 [32]对潜在特征图执行变形,并使用驾驶图像中的相对关键点位置来估计运动场。后续工作使用关键点 [33] 或关键区域 [34] 的一阶近似来提高运动场估计的准确性和鲁棒性,但仍遵循相对运动传递方案。但是,如果初始驱动人脸和源人脸的头部姿势或表情不同,则相对运动传递会导致明显的缺陷。因此,3D可变性人脸模型 [3] 可以显式估计 2D 人脸的姿势和表情信息,以允许绝对运动转移 [9,47,48]。尽管如此,以前基于翘曲的方法都有一个共同的局限性,即它们仅适用于有限范围的头部姿势。最新的工作 [43] 通过将 2D 运动场提升到 3D 空间,在一定程度上克服了这一限制。然而,像 3D 卷积这样昂贵的算子也使其不适合实时或移动应用程序。
直接合成方法。扎哈罗夫等人。 [50]介绍了第一种直接合成方法,它将外观和运动都投影到潜在特征空间中,并通过从相应的潜在代码中解码来合成目标人脸。该框架还表明,无需显式扭曲场即可直接合成合理的重演结果。然而,[50] 使用驾驶人脸的地标来计算运动编码。由于面部标志是特定于人的,因此从驾驶面部标志中提取的运动编码也将包含一些与身份相关的信息,从而在合成的面部中造成明显的身份差距。后来的作品试图通过从动作代码中消除驾驶者的身份信息来解决这个问题。已经提出了各种策略,例如,FReeNet [52] 训练一个界标转换器以使任意人的运动适应潜在空间中的目标人,LPD [5] 应用姿势增强来提高跨人重演性能,DAE- GAN [51] 利用变形自动编码器 [31] 来学习姿势不变的嵌入式面部等。最新的方法 [24] 还涉及对演员面部布局的编码,这在某种意义上可以进一步缓解身份保存问题。总体而言,直接合成方法可以处理更广泛的头部姿势变化,但是,在相同条件下,生成图像的保真度通常低于基于翘曲的对应物,因为高频细节很容易丢失将源面投影到低维外观嵌入空间时。此外,直接合成主干也往往比基于翘曲的主干慢,因为运动场提供了关于运动信息的强先验,而直接合成方法从头开始学习一切。
混合方法。受 FS-VID2VID [41] 的启发,结合变形和合成的混合方法被提出[7,49]。双层[49]以并行方式组合它们,即直接合成分支生成面部图像的低频分量,以及基于翘曲的分支添加高频细节。这种组合使得有史以来最快的一次性重演网络(即移动 GPU 上 256 × 256 分辨率图像的 25 fps 推理速度),但是其结果质量明显低于最先进的水平。此外,它仍然不足以支持实时面部重演应用程序,因为其他必需的操作,如面部标志检测和 GPU-CPU 复制操作也需要不可忽略的计算时间。 HeadGAN [7] 以另一种方式组合它们,将扭曲的外观特征注入到直接合成主干中。这种设计在所有现有算法中实现了最佳的视觉性能,但也使 HeadGAN [7] 成为最复杂的框架之一,无法用于时间关键的应用程序。face2facep使用的也是混合方法,但是我们以一种新的方式结合了变形和合成。具体来说,我们将通常用于直接合成方法的姿势编码注入到基于扭曲的生成器主干中。我们证明了这种架构使我们能够构建更好的一次性人脸重现框架,从而产生最先进的结果,显着减少时间和内存开销。
3. 方法
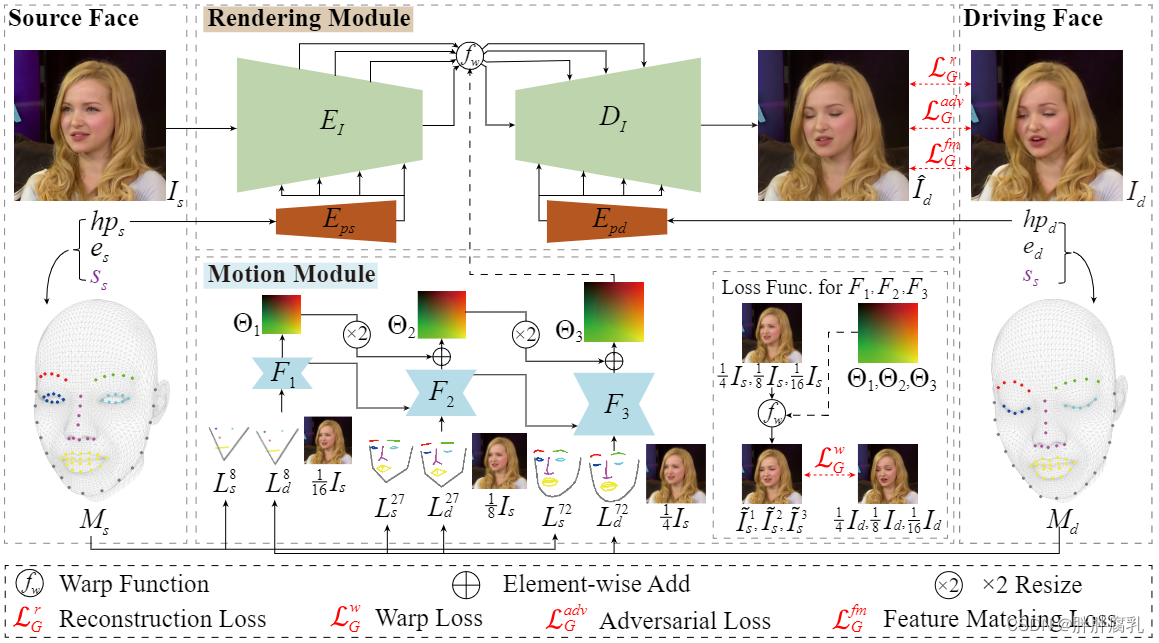
图2。Face2Faceρ 的训练管道。我们首先从源图像 I s I_s Is 和驱动图像 I d I_d Id 中回归 3DMM 系数,并重建三个不同尺度的地标图像(即 L s n L_s^n Lsn 和 L d n L_d^n Ldn )。地标图像和调整大小的源图像被馈送到运动模块以从粗略到精细地预测面部运动场,即 Θ 1 , Θ 2 \Theta_1, \Theta_2 Θ1,Θ2 和 Θ 3 \Theta_3 Θ3 。 Θ 3 \Theta_3 Θ3 和 I s I_s Is 被发送到渲染模块以生成重新生成的图像 I ^ d \hat{I}_d I^d。头部姿势信息也被注入到编码器 E I E_I EI 和解码器 D I D_I DI 中,以提高大姿势的性能。调整图像尺寸以获得更好的说明。
Face2Faceρ 的训练流程如图 2 所示。对于每对源和驱动人脸图像,我们在 3DMM(第 3.1 节)的帮助下计算它们的形状系数、表情系数、头部姿势和地标图像,然后,渲染模块学习基于源图像、估计的运动场和源/驱动头部姿势对(第 3.2 节)合成重新生成的人脸图像,而运动模块学习从粗略到精细地恢复运动来自三个不同尺度的地标图像的场(第 3.3 节)。训练和推理细节在第3.4节。
3.1 3DMM 拟合
与之前的方法 [7,48] 类似,我们的方法也依赖 3DMM [3] 来解析面部形状 s ∈ R 50 s \in \mathbb{R}^{50} s∈R50、表情 e ∈ R 51 e \in \mathbb{R}^{51} e∈R51 和头部姿势 h p ∈ R 6 h p \in \mathbb{R}^6 hp∈R6。
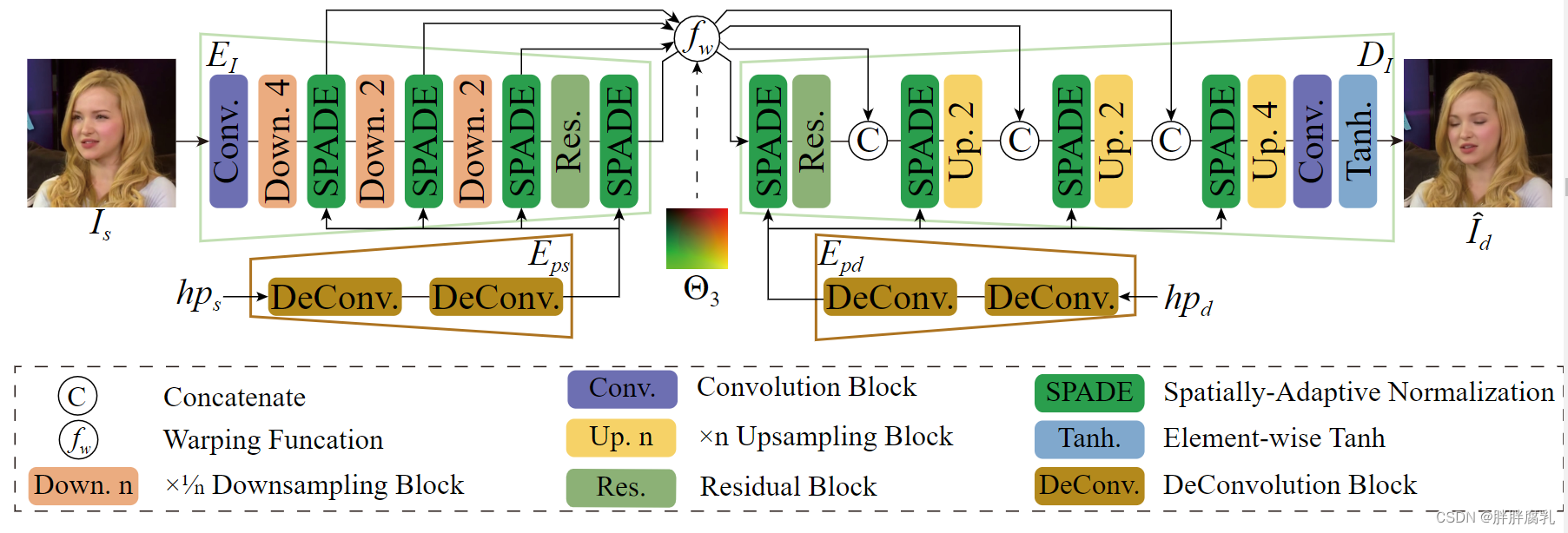
图3 渲染模块架构。
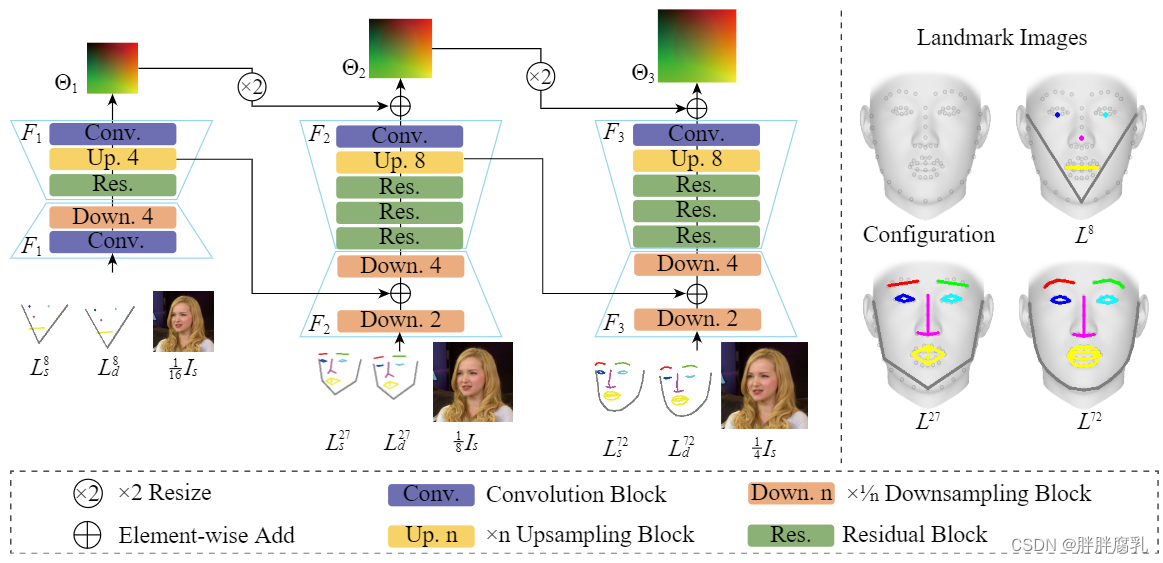
图 4. 左:运动模块的架构,三个运动场尺度(即输入图像的大小 1/16 、1/8 和 1/4 )从粗到细估计。右:不同尺度的地标图像,左上为网格模板上预先配置的72个关键点,粗尺度地标图像的关键点是这些点的子集。
我们根据 [44] 将 3DMM 拟合到源图像和驱动图像,产生两个向量 [ h p s , e s , s s ] \left[h p_s, e_s, s_s\right] [hps,es,ss] 和 [ h p d , e d , s d ] \left[h p_d, e_d, s_d\right] [hpd,ed,sd],其中下标 s s s 和 d d d 分别表示源和驱动。每个向量对应于 3DMM 空间中的一个 3D 面网格。然而,与以前的方法不同,我们的框架不需要构建整个面部网格,因此,我们只使用拟合 3DMM 信息来计算一组预先指定的 3D 关键点(即 M s M_s Ms 和 M d M_d Md)的位置在 3DMM 人脸模板上。在我们的实现中,选择了 72 个关键点(如图 4 所示),它们是 106 点面部标志规范 [20] 的子集。使用标准的 68 点规范 [4](即在每只眼睛的边界处少两个点)也是可以的。另外值得注意的是, M d M_d Md 是使用 [ h p d , e d , s s ] \left[h p_d, e_d, s_s\right] [hpd,ed,ss] 而不是 [ h p d , e d , s d ] \left[h p_d, e_d, s_d\right] [hpd,ed,sd] 计算的,以消除对驱动者身份的干扰。
3.2 渲染模块
如前所述,我们的渲染模块的网络结构源自基于扭曲的主干。以前基于翘曲的方法 [32,33,34,43] 最多支持 4 次下采样。进一步的下采样层会迅速降低网络的性能,从而在处理高分辨率图像时导致大量的时间和内存消耗。为了解决这个问题,我们提出了一种更有效的渲染网络架构,它支持 16 倍的下采样而不损害结果的质量。渲染模块的详细结构如图 3 所示,它是一个 u 形编码器-解码器架构,在图像编码器 EI 和解码器 DI 之间的每个连接的特征图上都应用了一个扭曲场。由于每个下采样操作都会丢弃一些细节,因此我们添加了跳过连接以补偿信息丢失,正如其他高速渲染网络中所建议的那样 [23,54]。这种设计允许编码器使用两个额外的下采样块,使网络比以前基于扭曲的主干网络快 3 倍。
标准基于扭曲的方法的主要缺点是它们只能处理有限范围的姿势变化。由于使用姿势信息来监督合成过程被证明是提高,在最近的直接合成方法 [5,50] 中对大姿态的鲁棒性,我们将姿态编码注入到图像编码器 EI 和解码器 DI 中。用于解释头部姿势的常用输入是 2D 面部标志 [41,49,50]、3D 面部标志 [43] 和光栅化 3DMM 面部网格 [7]。然而,产生或处理这样的输入信息将花费不可忽略的计算时间。或者,我们直接将在 3DMM 拟合过程中估计的头部旋转和平移作为姿势编码提供给渲染网络。 6维头部姿势向量通过反卷积(即Eps和Epd)重新塑造成方形矩阵,并通过SPADE [28]注入渲染主干。实际上,AdaIn [11] 也可以用于相同目的,但其中的 MLP 层往往更耗时。由于在我们的实验中这两种策略之间没有明显的差异,我们在实现中采用 SPADE [2]。
3.3 运动模块
估计运动场的精度对于基于翘曲的管道至关重要。由于拟合 3DMM 网格已被证明是用于此目的的最佳指导信息 [7,48],我们的运动模块也遵循 3DMM 辅助方式。然而,与之前需要构建和/或渲染整个面部网格的 3DMM 辅助方法不同,我们的方法只需要跟踪 3DMM 模板网格上的一小组预配置 3D 关键点的 3D 位置,因为合理数量的稀疏关键点已经足以揭示全局运动场 [32,33,43]。然后将跟踪的稀疏 3D 关键点投影到图像空间并转换为面部草图,我们将其称为地标图像。
这样设计的主要优点是它成功地避免了对整个网格进行软光栅化(即非常昂贵的操作),确保即使在移动 CPU 上也能快速生成运动模块的所有输入。
预测运动场的经典主干是单尺度沙漏网络[32,33,34],有效但效率低。受最近的光流估计算法(例如,[12])的启发,这些算法逐渐产生基于较低光流图的高分辨率光流图,我们将类似的从粗到细的策略应用于运动场估计,并成功地增加了推理在不牺牲精度的情况下,运动分支的速度提高了 3.5 倍。如图 4 所示,运动模块预测运动场的三个尺度 Θ 1 , Θ 2 \Theta_1, \Theta_2 Θ1,Θ2 和 Θ 3 \Theta_3 Θ3,分别具有三个子网络 F 1 F_1 F1、 F 2 F_2 F2 和 F 3 F_3 F3。每个子网络采用不同比例的源图像和地标图像,每个子网络中上采样块后的特征图被累积到后续子网络以帮助收敛,如 [42] 中所建议的。请注意,在生成不同尺度的地标图像(即 L s n L_s^n Lsn 和 L d n L_d^n Ldn )时使用的关键点数量 n 也遵循从粗到细的方案,其中 n = 8、27、72(见图 4 右侧)。
3.4 训练以及推理
我们在 VoxCeleb 数据集 [26] 上训练 Face2Faceρ,该数据集包含超过 20k 个不同演员的视频序列。对于每个视频帧,我们预先计算其 3DMM 系数,如第 2 节所述。 3.1。请注意,相同视频的形状系数在 3DMM 拟合过程中被迫相同。源图像 Is 和驱动图像 Id 的训练对是从同一视频中采样的。渲染和运动模块以对抗方式联合训练 380k 次迭代,批大小为 6。我们使用 Adam [18] 优化器,分别具有 β1 = 0.9 和 β2 = 0.999。前 330k 次迭代的学习率为 0.0002,然后线性衰减到 0。我们采用人脸重演中常用的训练损失配置 [5,7,9,33,41,43],生成器 G (即渲染和运动模块)计算为:
L
G
=
λ
G
r
L
G
r
+
λ
G
w
L
G
w
+
λ
G
a
d
v
L
G
a
d
v
+
λ
G
f
m
L
G
f
m
,
\mathcal{L}_G=\lambda_G^r \mathcal{L}_G^r+\lambda_G^w \mathcal{L}_G^w+\lambda_G^{a d v} \mathcal{L}_G^{a d v}+\lambda_G^{f m} \mathcal{L}_G^{f m},
LG=λGrLGr+λGwLGw+λGadvLGadv+λGfmLGfm,
这里 L G r , L G w , L G a d v \mathcal{L}_G^r, \mathcal{L}_G^w, \mathcal{L}_G^{a d v} LGr,LGw,LGadv 以及 L G f m \mathcal{L}_G^{f m} LGfm 分别表示重建损失,扭曲损失, 对抗性损失和特征匹配损失。对应的平衡权重 λ \lambda λ 分别设置为 15, 500,1 和1 ,由网格搜索确定。
重建损失
L
G
r
\mathcal{L}_G^r
LGr 确保输出图像看起来与地面实况相似。具体来说,我们采用 Wang 等人的感知损失 [43]测量驾驶图像
I
d
I_d
Id 和合成图像之间的距离
I
^
d
\hat{I}_d
I^d :
L
G
r
(
I
d
,
I
^
d
)
=
∑
i
=
1
N
∥
V
G
G
i
(
I
d
)
−
V
G
G
i
(
I
^
d
)
∥
1
,
\mathcal{L}_G^r\left(I_d, \hat{I}_d\right)=\sum_{i=1}^N\left\|V G G_i\left(I_d\right)-V G G_i\left(\hat{I}_d\right)\right\|_1,
LGr(Id,I^d)=i=1∑N
VGGi(Id)−VGGi(I^d)
1,
其中 V G G i ( ⋅ ) V G G_i(\cdot) VGGi(⋅) 是从预训练的 VGG-19 网络 [15] 和 N = 5 N=5 N=5 中提取的第 i th i^{\text {th }} ith 个特征层。我们尝试使用预训练的 VGGFace 网络 [29] 添加额外的损失,但是身份保存方面没有观测到明显改善。原因是 3DMM 已经解开了身份(形状)、表情和头部姿势。
如 [7,17,47] 中所述。与[7,31,45]类似,我们也采用了一个扭曲损失
L
G
w
\mathcal{L}_G^w
LGw 来强制运动模块学习正确的运动场,定义为:
L
G
w
=
∑
i
=
1
3
∥
I
d
−
I
~
s
i
∥
1
\mathcal{L}_G^w=\sum_{i=1}^3\left\|I_d-\widetilde{I}_s^i\right\|_1
LGw=i=1∑3
Id−I
si
1
这里
I
~
s
i
=
f
w
(
I
s
,
Θ
i
)
\widetilde{I}_s^i=f_w\left(I_s, \Theta_{\mathrm{i}}\right)
I
si=fw(Is,Θi) 表示根据第
i
t
h
i^{t h}
ith 个运动场
Θ
i
\Theta_{\mathrm{i}}
Θi 的扭曲源图像。
f
w
(
⋅
,
⋅
)
f_w(\cdot, \cdot)
fw(⋅,⋅) 是使用双线性采样器实现的变形函数。我们对
I
d
I_d
Id 进行下采样以匹配每个扭曲图像的大小
生成器也通过最小化对抗性损失
L
G
a
d
v
\mathcal{L}_G^{a d v}
LGadv 进行训练,该对抗性损失是通过使用 PatchGAN 鉴别器
D
D
D [13] 和最小二乘 GAN 目标 [21] 计算的。根据[21],
L
G
a
d
v
\mathcal{L}_G^{a d v}
LGadv 定义为:
L
G
a
d
v
=
(
D
(
I
^
d
,
L
d
72
)
−
1
)
2
\mathcal{L}_G^{a d v}=\left(D\left(\hat{I}_d, L_d^{72}\right)-1\right)^2
LGadv=(D(I^d,Ld72)−1)2
其中
L
d
72
L_d^{72}
Ld72 是驱动图像的顶级关键点图像。我们还添加了一个特征匹配损失
L
G
f
m
\mathcal{L}_G^{f m}
LGfm 来帮助稳定训练过程 [42]。判别器 D 通过最小化来优化:
L
a
d
v
D
=
(
D
(
I
d
,
L
d
72
)
−
1
)
2
+
D
(
I
^
d
,
L
d
72
)
2
\mathcal{L}_{a d v}^D=\left(D\left(I_d, L_d^{72}\right)-1\right)^2+D\left(\hat{I}_d, L_d^{72}\right)^2
LadvD=(D(Id,Ld72)−1)2+D(I^d,Ld72)2
在推理过程中,源演员的3DMM系数 [ h p s , e s , s s ] \left[h p_s, e_s, s_s\right] [hps,es,ss] 、关键点图像 L s n L_s^n Lsn 以及渲染模块中 E I E_I EI 和 E p s E_{p s} Eps 的编码都可以在离线阶段预先计算和记录,而其他的都是在线计算(例如,驾驶演员的 3DMM 系数 [ h p d , e d , s d ] \left[h p_d, e_d, s_d\right] [hpd,ed,sd],运动场 Θ 1 − 3 \Theta_{1-3} Θ1−3 等)。推理速度足够快,足以支持 PC 和移动设备上的实时应用程序。补充视频中提供了演示。
4. 评估
在本节中,我们将 Face2Faceρ 与最先进的作品进行比较,并进行消融研究以评估我们的一些关键设计选择。
4.1 比较
我们选择作为基线的最先进的 one-shot 方法是 FS-VID2VID [41]、Bi-layer [49]、LPD [5]、FOMM [33]、MRAA [34] 和 HeadGAN [ 7]。为了公平比较,所有方法均使用 PyTorch [30] 实现,并在 VoxCeleb 数据集上进行训练(即随机抽样 3M 对用于训练,3k 对用于测试)。作者的官方实现用于 Bi-layer、LPD、FOMM、MRAA 和 FS-VID2VID,而 HeadGAN 是我们自己实现的,因为它的源代码不公开。所有模型使用论文中推荐的训练配置进行训练。请注意,我们省略了与一些早期作品的并排比较,例如 X2Face [45] 和 FSTH [50],因为它们的性能已被广泛比较并证明低于我们的基线 [5,7,33 ,49]。此外,补充文件中提供了与其他最先进方法的小规模定性比较以及多镜头方法[36]。
计算复杂度。我们首先在推理阶段评估每个重演主干的时间和空间复杂性。时间复杂度由推理时间和乘加运算 (MAC) 的数量来衡量,而空间复杂度由运行时 GPU 内存开销来衡量。表中显示的结果。图 1 表明 Face2Faceρ 在计算复杂性方面具有压倒性优势。将实时应用的速度要求设置为 25 fps,并考虑到一些必要的辅助模块所需的额外时间(即大约 3-6 ms),只有 Bi-layer 和 LPD 可以处理 512 × 512 分辨率的图像,并且只有 Bi当分辨率增加到 1024 × 1024 时,-layer 仍然存在。相比之下,Face2Faceρ 的分辨率限制为 1440 × 1440。我们在补充文档中提供了由 Face2Faceρ 合成的更高分辨率(即 1440 × 1440)的结果。
请注意,目前没有适用于面部重演任务的可用高分辨率数据集。因此,高分辨率版本的 Face2Faceρ 是使用来自 VoxCeleb 的放大图像(即 512 × 512)进行训练的,这不可避免地限制了 Face2Faceρ 在一些真正的高清图像上的性能。然而,与简单地放大 512×512 模型的输出所产生的伪造 1440 × 1440 结果相比,通过 1440×1440 模型生成的结果显然具有更好的视觉质量(见补充文件)。因此,尽管缺乏高分辨率数据集,支持高分辨率图像仍然是有益的。

图 5. 与基线的定性比较,关于重演的任务。
重演。接下来,我们比较重演结果的质量。由于此任务没有可用的基本事实,我们使用 FID [10] 来测量图像真实性并使用 CSIM [6] 来测量身份差距。我们还采用[7]中使用的平均旋转距离(ARD)和动作单位汉明距离(AU-H)来分别评估姿势和表情转移的准确性。表中显示的统计数据。图 2 表明 Face2Faceρ 在每次测量中都达到了最先进的质量。图 5 突出显示了一些结果,其中源图像和驱动图像具有相对较大的头部姿势差异,即头部姿势在滚动、俯仰或偏航中的变化范围为 30°–45°。请注意,最近专注于姿势编辑的作品 [7,43] 通常只允许姿势变化高达 30° 左右,因此在一次性面部重演中,这种姿势变化范围已经可以被认为是很大的。从结果中,我们可以看到 HeadGAN 和 Face2Faceρ 方法明显优于它们的对应方法。 CSIM 分数低的方法(即 FS-VID2VID 和 Bi-layer)无法正确保留源参与者的身份,而 FID 分数高的方法(即 Bi-layer 和 LPD)往往会产生模糊的结果。此外,当头部姿势变形很大时(例如,图 5 的最后两行),在两种基于翘曲的方法(即 MRAA 和 FOMM)的结果中可以观察到不自然的变形。此外,由于它们都遵循相对运动转移方案,当初始驱动面和源面之间存在较大的姿态间隙时(例如,图 5 的前两行),该方案无法正确转移头部姿态。最重要的是,结果表明双层为快速推理速度牺牲了太多质量,而 Face2Faceρ 在不影响质量的情况下实现了更快的推理速度。注意选项卡中 FOMM 和 MRAA 的 CSIM/FID (表2)与图5中的视觉质量不一致,因为图 5 只突出了大型头部姿势转换的情况,而这些分数是所有 3k 测试对的平均值。补充视频中显示的动态结果更符合这些统计数据。此外,该视频还展示了我们的方法呈现出良好的时间一致性,尽管我们没有在训练过程中明确强制执行它(即,如 [41] 中所做的那样)。这是通过一种简单但有效的策略来实现的,即对拟合的 3DMM 系数应用双边滤波。

图 6. 与基线的定性比较,重建任务。
重建(自我重演)。最后,我们比较了自我重演任务中的结果(见图 6),其中源图像和驱动图像属于同一演员。由于在这种情况下,驾驶图像也可以被视为ground truth,因此可以通过比较驾驶图像和合成图像之间的相似度来直接衡量重建质量。在我们的实验中,为此目的采用了基于 AlexNet 的 LPIPS 度量 [53] 和平均关键点距离 (AKD) [33]。统计数据也显示在表2中,这表明 Face2Faceρ 在这项任务中取得了最好的成绩。
4.2 消融研究
在本节中,我们将评估一些关键选择将如何影响 Face2Faceρ 的性能。为清楚起见,我们表示建议的渲染模块,3DMM 头部姿势编码网络和运动模块分别为 r 0 r_0 r0、 p 0 p_0 p0 和 m 0 m_0 m0。然后,要研究的替代方案可以定义如下。 1) r 1 r_1 r1: r 0 r_0 r0 没有跳过连接, 2) r 2 r_2 r2: r 0 r_0 r0 没有头部姿势注入, 3) p 1 p_1 p1: 用于姿势编码的 2D 地标, 4) p 2 p_2 p2: 用于姿势编码的 3D 地标, 5) p 3 p_3 p3 : 用于姿势编码的深度图, 6) m 1 m_1 m1: [32,33] 中使用的单尺度运动估计网络,减少通道数以匹配 m 0 m_0 m0 的复杂度。
不同组合的结果如表3、图7和补充视频所示。我们可以看到 r 1 r_1 r1 和 r 2 r_2 r2 在头部姿势变化较大时往往会出现问题, m 1 m_1 m1 生成的表情经常与驾驶演员不一致(参见图 7 第 2 和第 3 行的眼睛和嘴巴),以及头部姿势编码 p 0 p_0 p0 几乎等于 p 2 p_2 p2 和 p 3 p_3 p3 ,尽管 p 2 p_2 p2 和 p 3 p_3 p3 消耗更多的计算时间(即 2-5 ms)。请注意,使用 2D 地标对 p 1 p_1 p1 进行姿势编码实际上无助于处理大姿势。此外,我们还进行了另一项消融研究,以评估补充文档中每个损失项的重要性。

图 7. 与消融研究案例的定性比较。
4.3 局限性
虽然我们的框架通常是健壮的,但它与其他最先进的一次性方法有一些共同的限制。如图 8 所示,当头部变换较大时,背景区域可能会出现一些可见的伪影,而前景中的异常物体(例如手或麦克风)可能会导致结果模糊。

图8, 示例限制。左:大的姿势修改有时会导致背景中出现可见的伪影。右:前景中的异常物体(例如手或麦克风)可能导致结果模糊。
5. 移动设备部署
我们使用 MNN [14] 在移动设备上部署 Face2Faceρ(请参阅移动演示的补充视频)。 3DMM 拟合和关键点图像生成在 CPU 上运行,而所有其他步骤在 CPU 或 GPU 上运行。每个步骤的运行时间列在表4中。可以看出,Face2Faceρ只需要一个Mobile CPU就可以实现256×256分辨率图像的实时性能。理论上,Face2Faceρ 在 GPU 上运行时支持更高分辨率的图像,但昂贵的 GPU-CPU 通信操作限制了它的能力。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kamXpVV5-1678083568524)(:/0ea98578b75a4e20868fe00fb7ccfeed)]
表 4. 不同分辨率图像在 Mobile CPU(Kryo 680,4 线程)和 GPU(Adreno 660,FP16)上的运行时间
6 结论
在本文中,我们提出了 Face2Faceρ,这是第一个实时高分辨率一次性人脸再现框架,由两个快速高效的网络组成:一个 u 形渲染网络和一个分层粗到细运动网络。实验结果表明,Face2Faceρ 实现了最先进的质量,同时显着降低了计算复杂度。具体来说,它可以实时运行,使用台式机 GPU 生成分辨率为 1440 × 1440 的人脸图像,使用移动 CPU 生成分辨率为 256 × 256 的人脸图像。
此外,我们的方法支持使用单张照片生成不真实的视频,因此它有可能被用于非法活动。一个典型的例子是对 DeepFakes [25,39] 的日益滥用。然而,随着越来越多的人可以使用此类技术,威胁也变得更加清晰。因此,已经提出了图像取证技术[22,40]。由于无法保证通过这些方法检测到所有虚假图像,因此严禁使用我们的方法生成和发布未经授权的视频。
7. 参考
- Alexander, O., Rogers, M., Lambeth, W., Chiang, J.Y., Ma, W.C., Wang, C.C.,Debevec, P.: The digital emily project: Achieving a photorealistic digital actor.IEEE Computer Graphics and Applications 30(4), 20–31 (2010)
- Averbuch-Elor, H., Cohen-Or, D., Kopf, J., Cohen, M.F.: Bringing portraits to life.ACM TOG 36(6), 1–13 (2017)
- Blanz, V., Vetter, T.: A morphable model for the synthesis of 3D faces. In: SIGGRAPH. pp. 187–194 (1999)
- Bulat, A., Tzimiropoulos, G.: How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In: ICCV. pp. 1021–1030 (2017)
- Burkov, E., Pasechnik, I., Grigorev, A., Lempitsky, V.: Neural head reenactment with latent pose descriptors. In: CVPR. pp. 13786–13795 (2020)
- Deng, J., Guo, J., Xue, N., Zafeiriou, S.: ArcFace: Additive angular margin loss for deep face recognition. In: CVPR. pp. 4690–4699 (2019)
- Doukas, M.C., Zafeiriou, S., Sharmanska, V.: HeadGAN: One-shot neural head synthesis and editing. In: ICCV. pp. 14398–14407 (2021)
- Garrido, P., Valgaerts, L., Sarmadi, H., Steiner, I., Varanasi, K., P´erez, P.,Theobalt, C.: VDub: Modifying face video of actors for plausible visual alignment to a dubbed audio track. Comput. Graph. Forum 34(2), 193–204 (May 2015)
- Ha, S., Kersner, M., Kim, B., Seo, S., Kim, D.: MarioNETte: Few-shot face reenactment preserving identity of unseen targets. In: AAAI. pp. 10893–10900 (2020)
- Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: GANs trained by a two time-scale update rule converge to a local nash equilibrium. In: NIPS. pp. 6626–6637 (2017)
- Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: ICCV. pp. 1501–1510 (2017)
- Huang, Z., Zhang, T., Heng, W., Shi, B., Zhou, S.: RIFE: Real-time intermediate flow estimation for video frame interpolation. arXiv preprint arXiv:2011.06294 (2020)
- Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-Image translation with conditional adversarial networks. In: CVPR. pp. 1125–1134 (2017)
- Jiang, X., Wang, H., Chen, Y., Wu, Z., Wang, L., Zou, B., Yang, Y., Cui, Z., Cai, Y., Yu, T., Lv, C., Wu, Z.: MNN: A universal and efficient inference engine. In:MLSys (2020)
- Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: ECCV. pp. 694–711 (2016)
- Kim, H., Elgharib, M., Zollh¨ofer, M., Seidel, H.P., Beeler, T., Richardt, C.,
Theobalt, C.: Neural style-preserving visual dubbing. ACM TOG 38(6), 1–13(2019) - Kim, H., Garrido, P., Tewari, A., Xu, W., Thies, J., Niessner, M., P´erez, P., Richardt, C., Zollh¨ofer, M., Theobalt, C.: Deep video portraits. ACM TOG 37(4), 1–14 (2018)
- Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2015)
- Koujan, M.R., Doukas, M.C., Roussos, A., Zafeiriou, S.: Head2Head: Video-based neural head synthesis. In: FG. pp. 16–23 (2020)
- Liu, Y., Shen, H., Si, Y., Wang, X., Zhu, X., Shi, H., Hong, Z., Guo, H., Guo,
Z., Chen, Y., et al.: Grand challenge of 106-point facial landmark localization. In: ICMEW. pp. 613–616. IEEE (2019) 16 K. Yang et al. - Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z., Paul Smolley, S.: Least squares generative adversarial networks. In: ICCV. pp. 2794–2802 (2017)
- Marra, F., Gragnaniello, D., Cozzolino, D., Verdoliva, L.: Detection of gangenerated fake images over social networks. In: MIPR. pp. 384–389. IEEE (2018)
- Martin-Brualla, R., Pandey, R., Yang, S., Pidlypenskyi, P., Taylor, J., Valentin, J.P.C., Khamis, S., Davidson, P.L., Tkach, A., Lincoln, P., Kowdle, A., Rhemann, C., Goldman, D.B., Keskin, C., Seitz, S.M., Izadi, S., Fanello, S.R.: LookinGood: Enhancing performance capture with real-time neural re-rendering. ACM TOG 37(6), 255:1–255:14 (2018)
- Meshry, M., Suri, S., Davis, L.S., Shrivastava, A.: Learned spatial representations for few-shot talking-head synthesis. In: ICCV. pp. 13829–13838 (2021)
- Mirsky, Y., Lee, W.: The creation and detection of deepfakes: A survey. ACM Computing Surveys 54(1), 1–41 (2021)
- Nagrani, A., Chung, J.S., Zisserman, A.: VoxCeleb: A large-scale speaker identification dataset. In: INTERSPEECH. pp. 2616–2620 (2017)
- Nirkin, Y., Keller, Y., Hassner, T.: FSGAN: Subject agnostic face swapping and reenactment. In: ICCV. pp. 7184–7193 (2019)
- Park, T., Liu, M.Y., Wang, T.C., Zhu, J.Y.: Semantic image synthesis with
spatially-adaptive normalization. In: CVPR. pp. 2337–2346 (2019) - Parkhi, O.M., Vedaldi, A., Zisserman, A.: Deep face recognition. In: BMVC (2015)
- Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., K¨opf, A., Yang, E.Z., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: PyTorch: An imperative style, high-performance deep learning library. In: NIPS. pp. 8024–8035 (2019)
- Shu, Z., Sahasrabudhe, M., Guler, R.A., Samaras, D., Paragios, N., Kokkinos, I.: Deforming Autoencoders: Unsupervised disentangling of shape and appearance. In: ECCV. pp. 650–665 (2018)
- Siarohin, A., Lathuiliere, S., Tulyakov, S., Ricci, E., Sebe, N.: Animating arbitrary
objects via deep motion transfer. In: CVPR. pp. 2377–2386 (2019) - Siarohin, A., Lathuiliere, S., Tulyakov, S., Ricci, E., Sebe, N.: First order motionmodel for image animation. In: Adv. Neural Inform. Process. Syst. pp. 7135–7145(2019)
- Siarohin, A., Woodford, O.J., Ren, J., Chai, M., Tulyakov, S.: Motion representations for articulated animation. In: CVPR. pp. 13653–13662(2021)
- Suwajanakorn, S., Seitz, S.M., Kemelmacher-Shlizerman, I.: Synthesizing Obama: Learning lip sync from audio. ACM TOG 36(4), 1–13 (2017)
- Thies, J., Elgharib, M., Tewari, A., Theobalt, C., Nießner, M.: Neural Voice Puppetry: Audio-driven facial reenactment. In: ECCV. pp. 716–731 (2020)
- Thies, J., Zollh¨ofer, M., Nießner, M.: Deferred neural rendering: Image synthesis using neural textures. ACM TOG 38(4), 1–12 (2019)
- Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C., Nießner, M.: Face2Face: Real-time face capture and reenactment of rgb videos. In: CVPR. pp. 2387–2395 (2016)
- Tolosana, R., Vera-Rodriguez, R., Fierrez, J., Morales, A., Ortega-Garcia, J.: Deepfakes and beyond: A survey of face manipulation and fake detection. Information Fusion 64, 131–148 (2020)
- Wang, S.Y., Wang, O., Zhang, R., Owens, A., Efros, A.A.: CNN-generated images are surprisingly easy to spot… for now. In: CVPR. pp. 8695–8704 (2020)
- Wang, T., Liu, M., Tao, A., Liu, G., Catanzaro, B., Kautz, J.: Few-shot video-to-video synthesis. In: NIPS. pp. 5014–5025 (2019) Face2Faceρ 17
- Wang, T.C., Liu, M.Y., Zhu, J.Y., Tao, A., Kautz, J., Catanzaro, B.: High-resolution image synthesis and semantic manipulation with conditional GANs. In: CVPR. pp. 8798–8807 (2018)
- Wang, T.C., Mallya, A., Liu, M.Y.: One-shot free-view neural talking-head synthesis for video conferencing. In: CVPR. pp. 10039–10049 (2021)
- Weng, Y., Cao, C., Hou, Q., Zhou, K.: Real-time facial animation on mobile devices.Graphical Models 76(3), 172–179 (2014)
- Wiles, O., Koepke, A., Zisserman, A.: X2Face: A network for controlling face generation using images, audio, and pose codes. In: ECCV. pp. 670–686 (2018)
- Wu, W., Zhang, Y., Li, C., Qian, C., Loy, C.C.: ReenactGAN: Learning to reenact faces via boundary transfer. In: ECCV. pp. 603–619 (2018)
- Yao, G., Yuan, Y., Shao, T., Li, S., Liu, S., Liu, Y., Wang, M., Zhou, K.: One-shot face reenactment using appearance adaptive normalization. In: AAAI. pp.
3172–3180 (2021) - Yao, G., Yuan, Y., Shao, T., Zhou, K.: Mesh guided one-shot face reenactment using graph convolutional networks. In: ACM MM. pp. 1773–1781 (2020)
- Zakharov, E., Ivakhnenko, A., Shysheya, A., Lempitsky, V.: Fast bi-layer neural synthesis of one-shot realistic head avatars. In: ECCV. pp. 524–540 (2020)
- Zakharov, E., Shysheya, A., Burkov, E., Lempitsky, V.: Few-shot adversarial learning of realistic neural talking head models. In: ICCV. pp. 9459–9468 (2019)
- Zeng, X., Pan, Y., Wang, M., Zhang, J., Liu, Y.: Realistic face reenactment via self-supervised disentangling of identity and pose. In: AAAI. pp. 12757–12764 (2020)
- Zhang, J., Zeng, X., Wang, M., Pan, Y., Liu, L., Liu, Y., Ding, Y., Fan, C.:
FReeNet: Multi-identity face reenactment. In: CVPR. pp. 5326–5335 (2020) - Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
- Zhang, R., Zhu, J., Isola, P., Geng, X., Lin, A.S., Yu, T., Efros, A.A.: Real-time user-guided image colorization with learned deep priors. ACM TOG 36(4), 119:1–119:11 (2017)















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









