










前言
该项目主要实现了face-reenactment,人脸3D控制和语音驱动图像,不局限于特定人物,使用预训练模型可以针对任一人物完成。(项目源代码里没有写出,简单修改一下就可以)。
下面给出一点我个人实验过程中的截图(vox数据集实验截图可见项目地址或论文):


由于是自定义的源图,可能加载图像通道需要调整,所以会出现有点发白的情况。实验过程中发现针对自定义的图,wrap效果较好,editing后的图眼睛和牙齿很失真。(这个可能是由于驱动图像人物是欧美人的原因)
Abstract
Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream
通过控制人脸的运动来生成图像会对社交媒体行业产生重大的影响,为了便于使用和直观控制,应使用语义上有意义且完全分离的参数作为修改量。然而,现在大多数技术并没有提供这种精细的控制,也没有使用间接编辑方法,如模仿其他人的动作。在本文中,提出了一种人像神经渲染器(PIRender),利用三维可变形人脸模型(3DMM)来控制人脸运动。PIRender可以通过直接的修改生成具有准确运动的人脸图像视频,直接和间接编辑任务的实验证明了模型的优越性。同时,我们进一步扩展了该模型,通过从音频输入中提取顺序运动来解决音频驱动的面部重演任务。实验表明,我们的模型可以仅通过单张图像和驱动音频生成令人信服的连贯动作视频。
Introduction
人脸图像是日常生活中广泛使用的照片,能够通过直观地控制给定人脸的姿势和表情来编辑人脸图像(见图 1)是一项重要任务,在虚拟现实、电影制作和下一代领域具有广泛的应用。然而,使用此类编辑极具挑战性,因为它需要通过算法感知给定面部的3D模型。同时,肉眼对人脸图像的敏锐性也要求算法生成照片般逼真的人脸和背景,这使得任务变得更加困难。

最近,生成对抗网络(GAN)的进步在合成真实面孔的大小方面取得了巨大进展。一些由 GAN 驱动的方法通过图像翻译来解决该问题,其目标是训练一个模型,给定输入指令,生成图像的分布类似于真实图像的条件分布。一些后续算法通过提出有效的变形模块或将源神经纹理注入到目标中来实现更好的泛化。然而,绝大多数现有方法使用间接和特定于主题的运动描述,例如边缘、语义分割或关键点来描述目标运动。虽然这些具有二维空间信息的描述可以使目标图像的生成,但它们阻碍了模型通过直接方式编辑肖像的能力。
为了实现直观控制,运动描述应该在语义上有意义,这需要将面部表情、头部旋转和平移转换为完全解耦的变量。参数化的人脸建模方法为使用语义参数描述 3D 人脸提供了强大的工具。这些方法允许通过诸如形状、表达式等参数来控制 3D 网格。结合这些技术的先验,人们可以控制照片般逼真的人脸图像的生成,类似于图形渲染的处理。
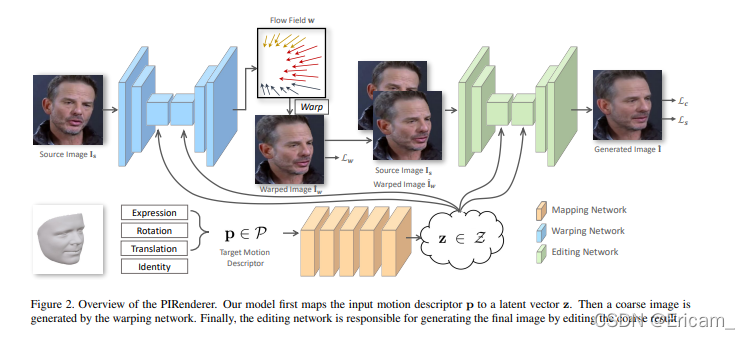
本文提出了一种神经渲染模型PIRenderer。给定源人脸图像和目标 3DMM 参数,我们的模型生成具有精确运动的照片般逼真的结果。如图 2 所示,所提出的模型分为三个部分:Mapping Network、Warping Network 和 Editing Network。映射网络从运动描述产生潜在向量。在向量的指导下,Warping Network估计源图和所需目标之间的变形,并通过使用估计的变形对源进行wrap来生成粗略的结果。Editing Network从粗糙图像生成最终图像。实验证明了我们模型的优越性和多功能性。我们表明,我们的模型不仅可以通过以下方式实现直观的图像控制,也可在间接肖像编辑任务中产生逼真的结果,如模仿另一个人的动作。此外,我们通过进一步扩展它来解决音频驱动的面部重演任务,展示了我们的模型作为高效神经渲染器的潜力。由于高级别的完全解耦参数化,我们可以从“弱”控制音频中提取令人信服的动作。实验表明,我们的模型从音频流中生成各种生动的动作,并将这些动作转换为任意目标人物的真实视频。主要贡献总结为:
- 提出了PIRender,可以对面部表情、头部旋转和平移进行直观的编辑
- 提出的模型可以实现face-reenactment(模仿目标人物的动作实现人脸编辑),也可以提取与主题无关的运动生成逼真的视频(3D控制)
- 音频驱动的面部重演的额外扩展展示了所提出模型的潜力,可以仅通过单张图片和驱动音频生成生动的视频
Related work
Portrait Editing via Semantic Parameterization (通过语义参数化完成人像编辑)
使用类似于语义控制的计算机动画控件可以为用户提供直观的控件,一些基于模型的方法可以渲染3DMM的图像并通过修改表情或姿势参数来编辑人像图片,这些方法取得了令人印象深刻的结果,但它们都是基于特定场景主题的方法,因此不用适用于任意人物。X2Face通过使用wrap操作对源图像纹理进行空间变换,取得了很好的成绩,但是只能编辑源肖像的姿势。诸如StyleGan之类的Gan网络被训练来合成真实的人脸图像,利用此种优势,StyleRig描述了一种通过3DMM控制生成人脸图像的方法,但是由于训练的StyleGan latent code,不支持对真实世界图像编辑。PIE通过一种优化方法来真实图像的嵌入,然而每次输入都需要迭代优化,降低了算法效率。
Portrait Editing via Motion Imitation(通过运动模仿进行人像编辑)
许多模型并不是通过语义参数来描述目标运动,而是被训练来模仿另一个人的运动(face-reenactment),一些从GAN派生的方法通过将其建模为图像到图像的转换来解决此任务,然而这需要对人物进行数时小时的训练来完成重演。一些后续的方法提出有效的空间变换或将源图神经纹理注入目标来实现更好的泛化,然而它们依赖于特定的场景主题(例如landmarks、edges、parsing maps)或运动纠缠(例如稀疏关键点),这使得它们缺乏直观的编辑人像的能力。
Portrait Editing via Audio(通过音频进行人像编辑)
使用音频编辑人脸肖像需要通过音频和源图生成令人信服的连贯动作视频。一些方法通过直接建模音频信号和图像之间的关系来完成任务,但是,由于音频输入不能完全确定目标的头部姿势,因此这些方法被训练以生成具有固定头部姿势(不支持完整的头部编辑)。为了避免来自真实图像中无关因素的干扰,一些模型首先将音频输入映射到中间结果,然后生成最终结果,但是这些方法需要视频输入,不适用单个图像,同时它们要么是特定于主题的模型,要么需要进一步微调才能应用于任意个体。我们的模型可以为音频流生成各种运动,并将这些运动转换为任意目标人物的真实视频。
Our Approach
Target Motion Descriptor (目标描述)
为了实现直观和精细的编辑,应该提供语义上有意义的控件。 在本文中,我们使用 3DMM 参数的子集作为运动描述。 通过 3DMM,人脸的 3D 形状 S 参数化为:
S
=
S
ˉ
+
α
B
i
d
+
β
B
e
x
p
S = \bar{S}+\alpha B_{id}+\beta B_{exp}
S=Sˉ+αBid+βBexp
S
ˉ
\bar{S}
Sˉ是平均人脸形状,
α
B
i
d
和
β
B
e
x
p
\alpha B_{id} 和 \beta B_{exp}
αBid和βBexp是基于200次人脸扫描PCA分析得到的身份和表情特征。现成的 3D 人脸重建模型是用于从真实世界的人像图像中提取相应的 3DMM 系数。 然而,系数提取会产生误差问题。 虽然 3D 人脸重建方法产生了相对准确的结果,但错误
和噪音是不可避免的。 提取之间的不匹配运动
p
p
p和目标的实际运动
I
t
I_{t}
It导致性能下降和不连贯的结果(见补充材料)。 为了缓解这个问题,具有连续帧的窗口系数a用作中心帧的运动描述。 因此,可以期望网络通过提取之间的关系来避免相邻帧错误。 因此,定义了运动描述符为:
p
=
p
i
−
k
:
i
+
k
=
{
β
i
,
R
i
,
t
i
.
.
.
β
i
±
k
,
R
i
±
k
,
t
i
±
k
}
p = p_{i-k:i+k} = \{\beta_{i},R_{i},t_{i}...\beta_{i\pm k},R_{i\pm k},t_{i\pm k}\}
p=pi−k:i+k={βi,Ri,ti...βi±k,Ri±k,ti±k}
PIRenderer for Semantic Control
给定一个源肖像图像 I s I_{s} Is和目标运动描述 p p p,PIRenderer 生成准确的运动的肖像图像 I ^ \hat{I} I^,同时保持另一个源身份、照明和背景等信息。该网络结合了几个完成特定任务的组件:
The Mapping Network
定义一个mapping network,将运动描述p转换成latent vectors z。
z
=
f
m
(
p
)
z = f_{m}(p)
z=fm(p)
可学习的latent vector z进一步通过仿射变换生成
y
=
(
y
s
,
y
b
)
y=(y_{s},y_{b})
y=(ys,yb),然后经过控制自适应归一化AdaIN,使其从z能够进入到wraping和editing network。
A
d
a
I
N
(
x
i
,
y
)
=
y
s
,
i
x
i
−
μ
(
x
i
)
σ
(
x
i
)
+
y
b
,
i
{AdaIN}(x_{i},y) = y_{s,i}\frac{x_{i}-\mu (x_{i})}{\sigma (x_{i})}+y_{b,i}
AdaIN(xi,y)=ys,iσ(xi)xi−μ(xi)+yb,i
The Warping Network
卷积神经网络缺乏以有效方式对输入进行空间转换,为了更好的保留生动的纹理、实现泛化,我们使用一个warping network对源图像的重要信息进行空间转换。warping network有望感知源图像准确的3D几何形状并估计输入源和目标之间的变换路线。
w
=
g
w
(
I
s
,
z
)
w = g_{w}(I_{s},z)
w=gw(Is,z)
该网络使用auto-encoder结构设计,在每个卷积层后使用AdaIN操作来注入z描述运动。我们不估计全分辨率流场,输出流为输入图像的1/4分辨率。在训练和评估期间,我们对预测流进行上采样以匹配分辨率。
我们通过warping loss
L
w
L_{w}
Lw约束wraping network以生成准确的流场。但事实证明,流场在此任务中不可用,因此我们计算目标图像和warped图像之间的重建损失。(通过预训练VGG19计算L1距离)
L
w
=
∑
i
∥
ϕ
(
I
t
)
−
ϕ
(
I
w
^
)
∥
L_{w} = \sum_{i}^{}\left \| \phi (I_{t})-\phi (\hat{I_{w}}) \right \|
Lw=i∑∥∥∥ϕ(It)−ϕ(Iw^)∥∥∥
The Editing NetWork
虽然wraping network可以有效地对源图像进行空间变换,但它却无法生成源图像中不存在的内容,同时由于wrap操作会导致性能下降,因此,设计了Editing Network来修改wraped network产生的粗略的结果。
I
^
=
g
e
(
I
^
w
,
I
s
,
z
)
\hat{I}=g_e(\hat{I}_{w},I_{s},z)
I^=ge(I^w,Is,z)
Editing network的网络结构和wraping network类似,同样加入了AdaIN操作去注入z。Editing Network在训练中使用重建损失
L
c
L_{c}
Lc和风格损失
L
s
L_{s}
Ls。
L
c
=
∑
i
∣
∣
ϕ
(
I
t
)
−
ϕ
(
I
^
)
∣
∣
L
s
=
∑
j
∣
∣
G
j
ϕ
(
I
t
)
−
G
j
ϕ
(
I
^
)
∣
∣
L_c = \sum_{i}||\phi(I_{t})-\phi(\hat{I})|| \\ L_{s}=\sum_{j}||G_{j}^\phi(I_{t})-G_{j}^\phi(\hat{I})||
Lc=i∑∣∣ϕ(It)−ϕ(I^)∣∣Ls=j∑∣∣Gjϕ(It)−Gjϕ(I^)∣∣
最终的Loss为:
L
=
λ
w
L
w
+
λ
c
L
c
λ
s
L
s
L = \lambda_{w}L_{w}+\lambda_{c}L_{c}\lambda_{s}L_{s}
L=λwLw+λcLcλsLs。
在实验中,我们设置如下: λ w = 2.5 , λ c = 4 , λ s = 1000 \lambda_{w}=2.5,\lambda_{c}=4,\lambda_{s}=1000 λw=2.5,λc=4,λs=1000
Extension on Audio-driven Reenactment
在本节中,我们将 PIRenderer 进一步扩展到解决音频驱动的面部重演任务,该任务生成具有令人信服的表情和姿势的视频驱动音频和源图像。这项任务需要一个模拟音频和面部动作之间的关系。但是,直接将音频信号映射到照片般逼真的图像或其他低级运动描述符(例如边缘,
地标)具有挑战性。因此,使用语义上有意义的参数化(如 3DMM)作为中间结果可以显着简化任务。因此,我们进一步改进了我们的通过包含一个额外的映射函数 fθ 到从音频中产生连续的 3DMM 系数。设计 fθ 的一个基本挑战是处理多种可能的输出。训练它生成确定性运动将限制网络产生伪影,因为它受限于预测所有物体的平均运动可能的结果。出于这个原因,将 fθ 概述为一个随机模型,可以从单个音频流有助于减少此问题。规范化flow [13, 29, 24] 被用来设计这个模型。这规范化流的核心思想是训练一个可逆和可微分非线性映射函数,将样本从简单分布映射到更复杂的分布。
具体来说,我们以循环方式生成顺序运动。 先前生成的 k 个动作以及音频 被用作条件信息
。同时,为了提取时间相关性,我们将归一化流层中的神经网络设计为 LSTM模块。 隐藏状态在每次迭代时更新以生成当前运动。 我们使用单个负对数似然损失。 在推理阶段,可以使用 p = fθ(n, c) 生成各种顺序运动。然后这些动作可以转换成逼真的视频。
Experiment
这部分属于作者的实验细节,感兴趣的盆友可以自行详细阅读论文。
下面简单给出作者的实验结果:



其他
我是在3090的环境下测试的该项目,大家如果复现过程中有问题可以留言咨询。


















 4826
4826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









