






一、背景与需求分析
随着数字化阅读的普及,用户对阅读数据的管理需求日益增长。微信读书作为主流阅读平台,积累了大量用户的阅读笔记、划线内容和书籍元数据。但这些数据的利用往往受限于平台封闭性,用户难以将数据与外部工具(如 AI 助手)结合,实现高效的知识整理与深度分析。
解决方案目标:
通过 Cursor与微信读书 MCP 服务器的结合,搭建一个轻量级桥梁,将微信读书的阅读数据无缝接入 ,实现以下目标:
- 数据互通:将微信读书的笔记、划线内容、书籍信息等实时同步至本地。
- 智能分析:利用 AI 对阅读数据进行分类、总结、主题提取等操作,辅助知识管理。
- 高效交互:通过自然语言交互快速检索阅读内容,生成摘要或关联知识图谱。
二、技术架构与核心组件
该解决方案的核心是 微信读书 MCP 服务器,其作用是作为中间层,将微信读书MCP服务端与MCP客户端连接起来。以下是技术架构的分层说明:
- 数据源层(微信读书)
- 微信读书的用户数据(笔记、划线、书架信息)通过 API 或 Cookie 模拟登录方式获取。
- 需要用户授权并提供 Cookie 值,确保数据访问的合法性与安全性。
- 中间层(MCP 服务器)
- 功能:
- 实现微信读书 API 与 MCP客户端的协议转换(如 MCP 协议)。
- 提供标准化接口(如
/books、/notes)供客户端调用。 - 支持数据缓存、格式转换(Markdown/PDF 导出)及权限控制。
- 技术实现:
- 通过
.env文件配置 Cookie 和服务器参数,支持灵活部署。
- 通过
- 功能:
- 客户端层(AI 工具Cursor)
- 功能:
- 调用 MCP 服务器接口,获取并处理阅读数据。
- 利用 AI 模型对数据进行分析(如主题分类、关键词提取)。
- 提供用户界面(CLI 或 GUI)实现交互式操作。
- 技术实现:
- 集成 MCP 协议支持,通过 API 请求获取数据。
- 功能:
三、部署与配置步骤
1. 环境准备
- 硬件要求:
- 一台可运行 Node.js 的笔记本。
- 操作系统:Windows。
- 软件依赖:
- Node.js (v16+)
- Git
- 微信读书网页版账号及 Cookie(需登录后获取)。
2. 获取微信读书 Cookie
- 打开微信读书网页版并登录。
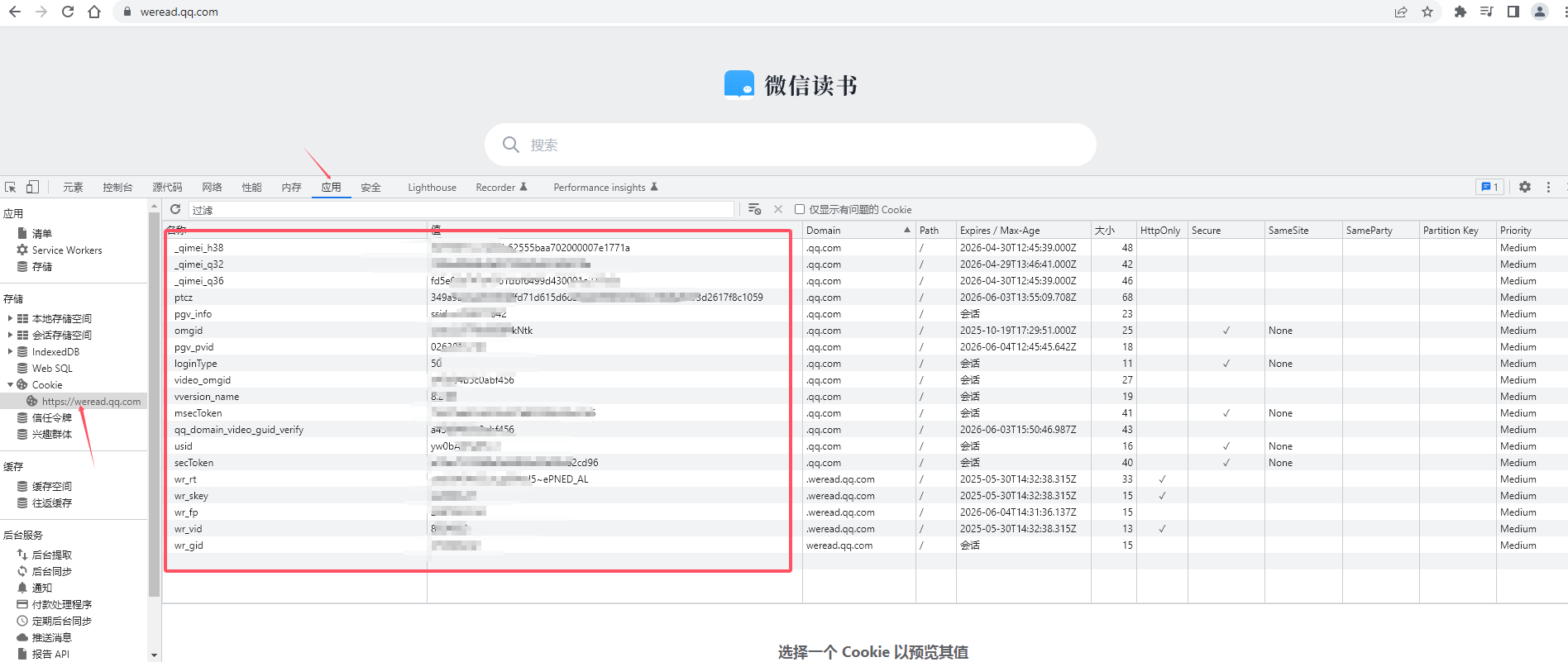
- 在浏览器中按
F12打开开发者工具或者检查,切换到 应用 标签。 - 刷新页面,任意点击一个请求(如书籍列表),在 Cookies 部分复制所有 Cookie 值。
3. 部署 MCP 服务器
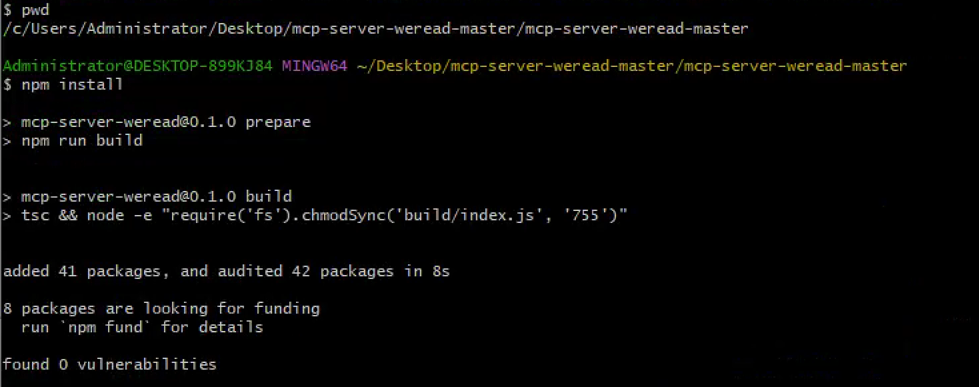
1、 克隆项目仓库
2、安装依赖
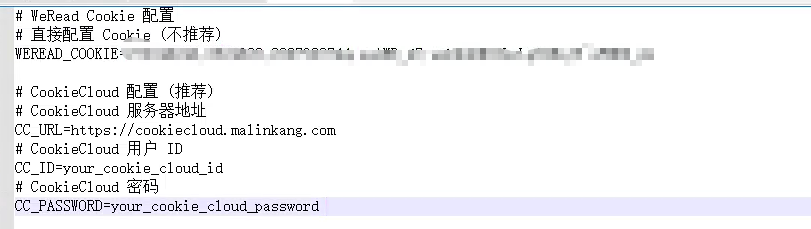
3、 配置环境变量
在项目根目录创建 .env 文件,填写以下内容:
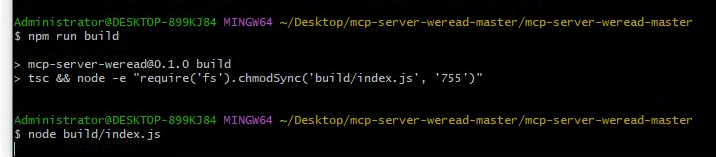
4、 启动服务器
4. 集成 MCP客户端
1、 配置 MCP 服务器地址
在 Trae 的配置文件中添加以下内容:
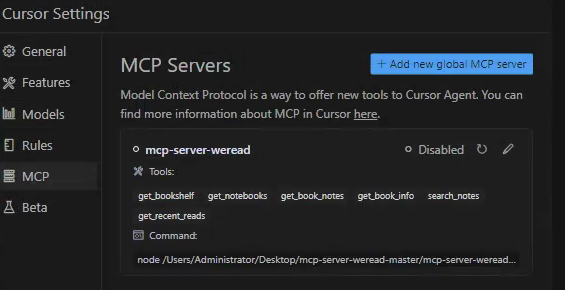
2、. 验证连接
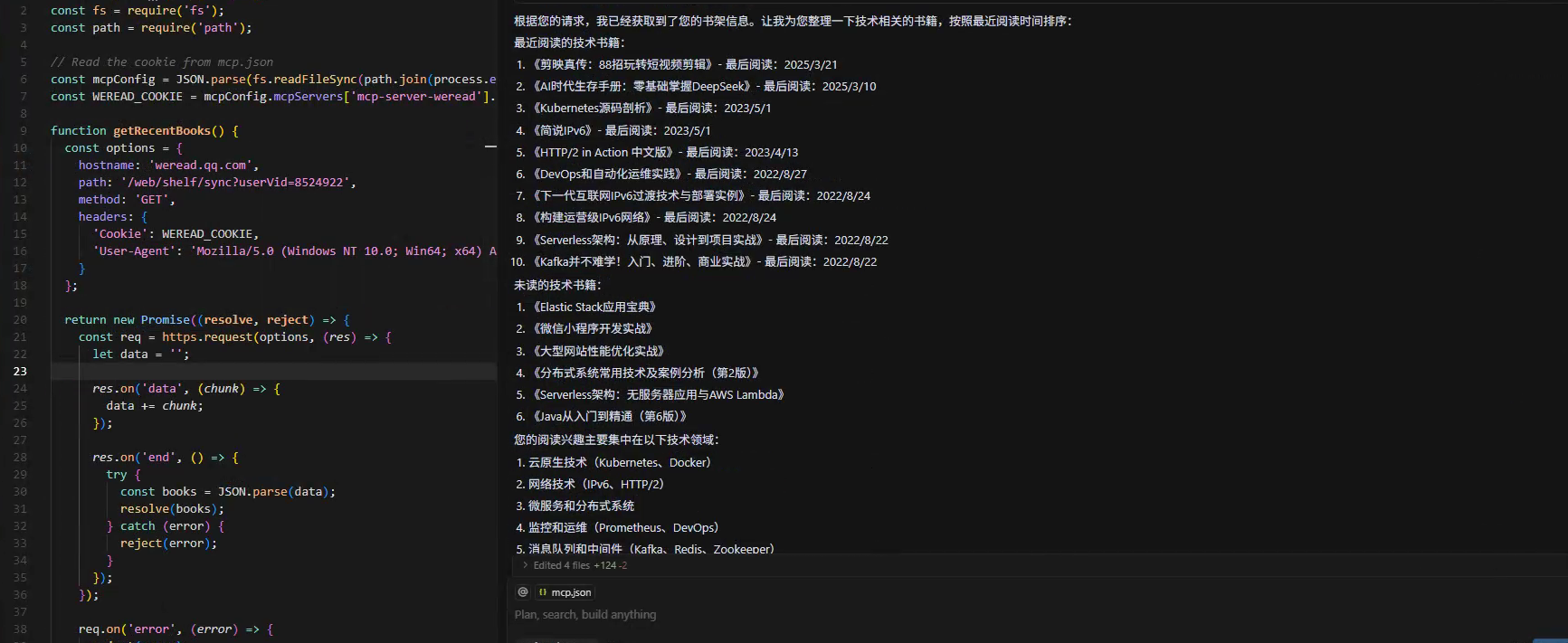
在Cursor AI中中发送测试请求
返回如下结果。
四、功能与应用场景
1. 无缝访问阅读数据
- 阅读知识管理:比如可以根据书架上已读书籍,总结下分析我的阅读数据。

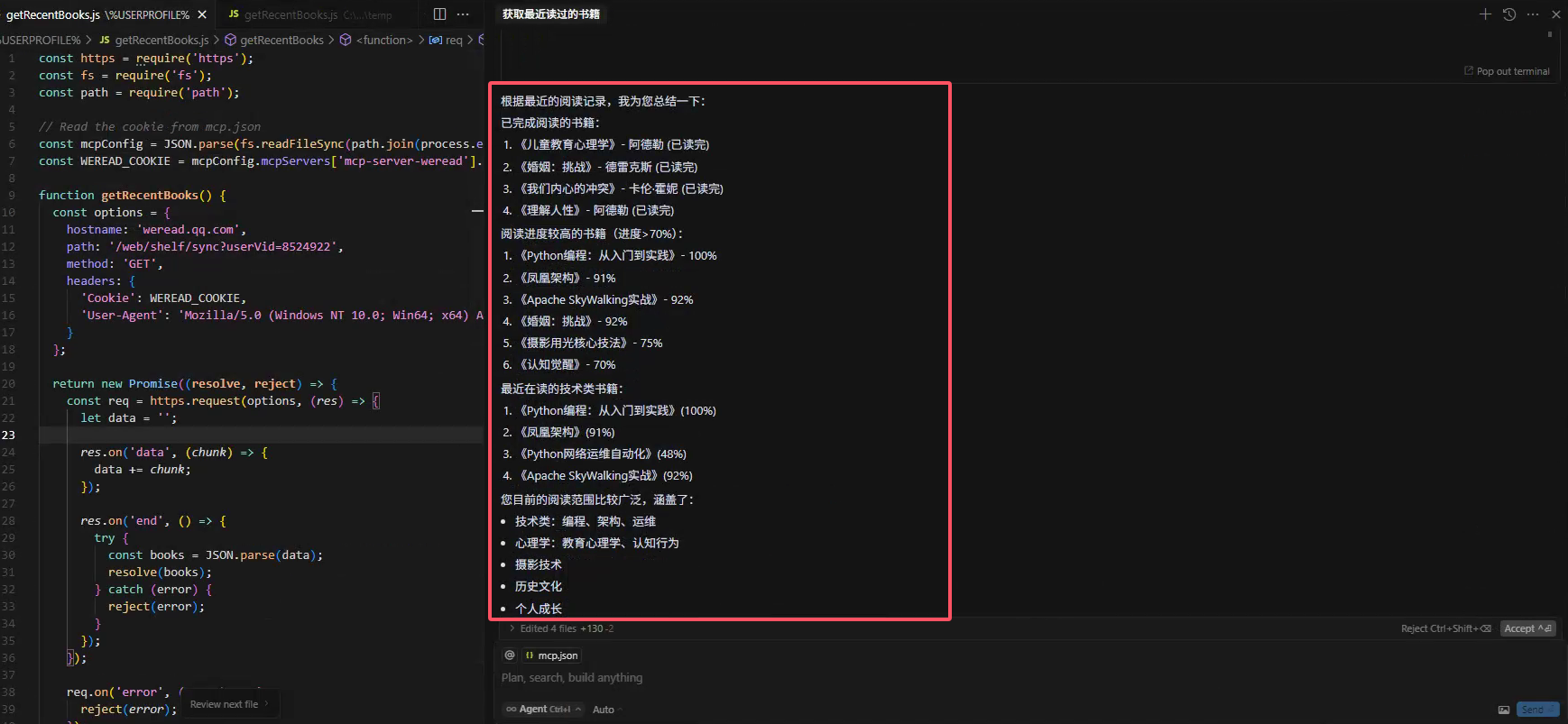
- 书架信息同步: 用户可在 AI 客户端中实时查看微信读书的书架,比如列出我最近阅读书籍的进度。
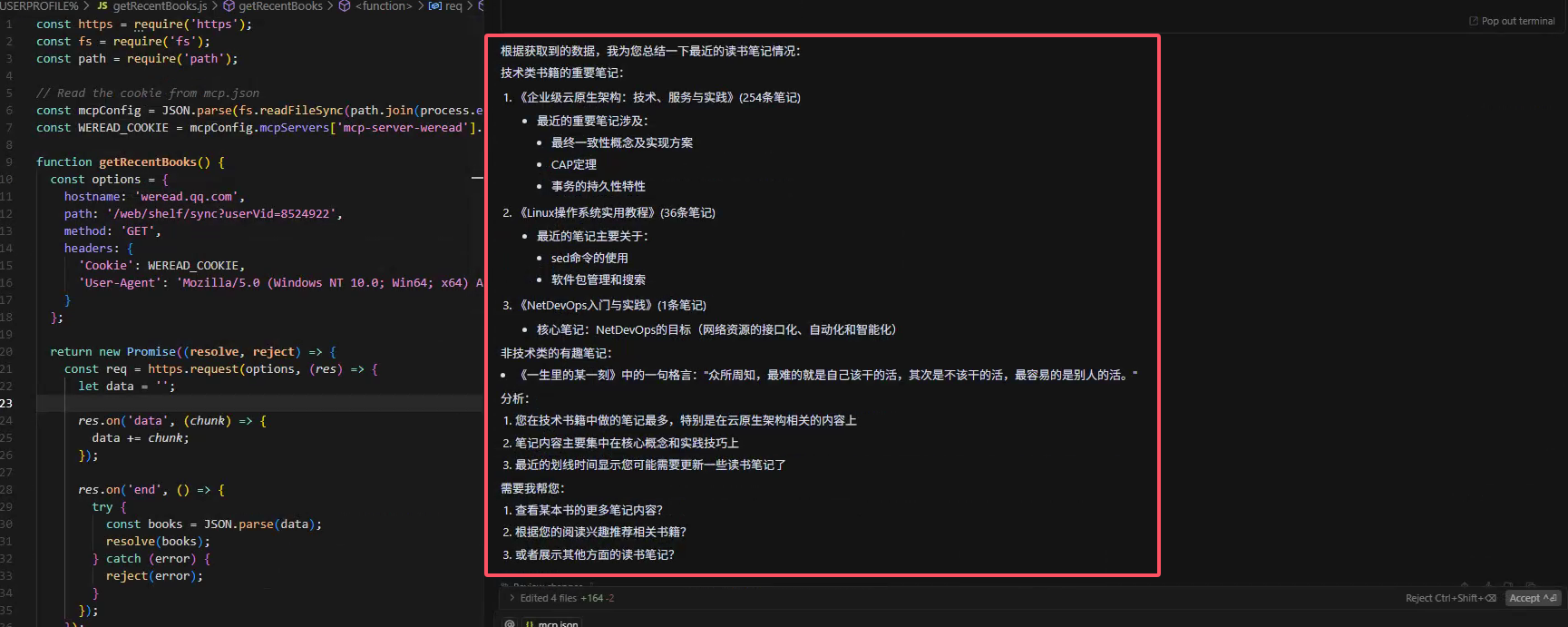
- 笔记与划线管理: 通过命令或自然语言查询书籍的笔记内容,例如: "显示最近所读书籍的划线内容"
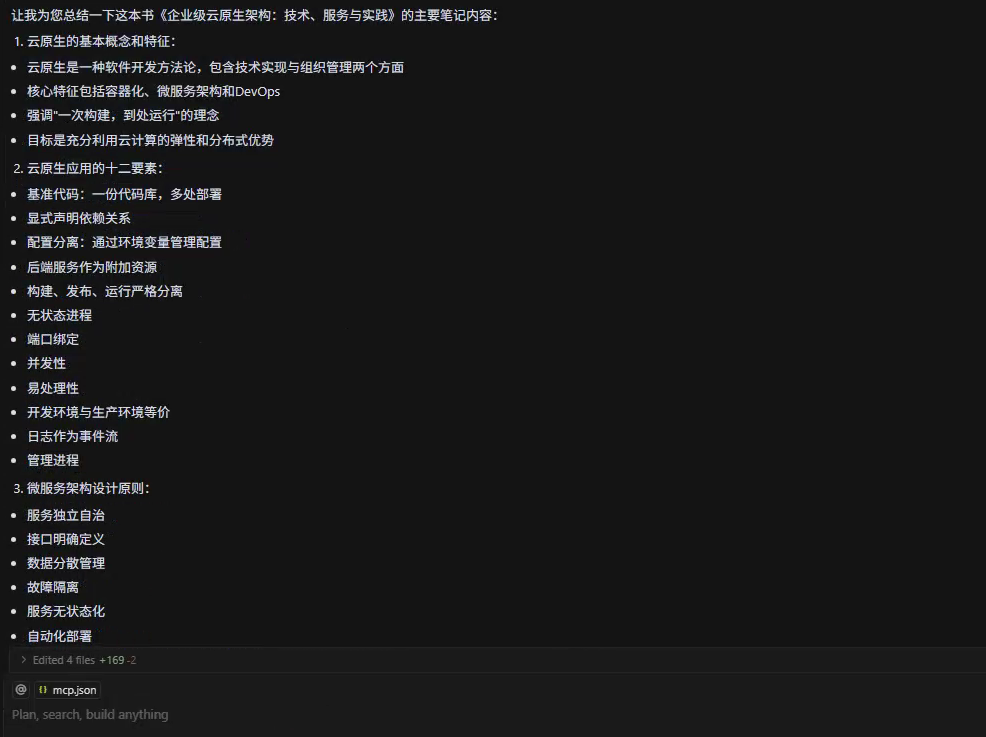
2. 智能分析与知识管理
- 主题分类与标签生成: AI 自动对笔记内容进行主题聚类,生成标签,便于后续检索。
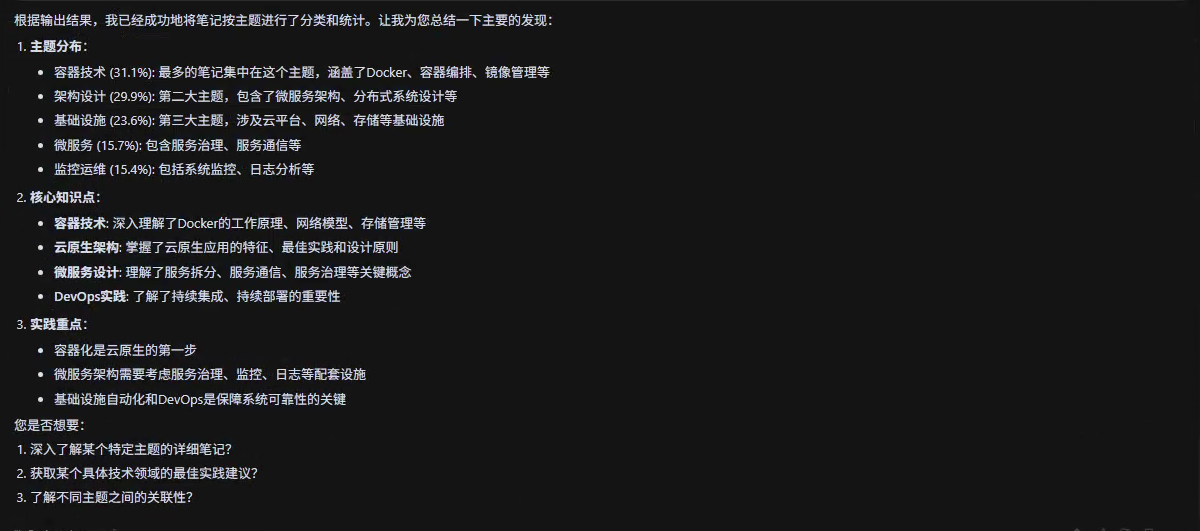
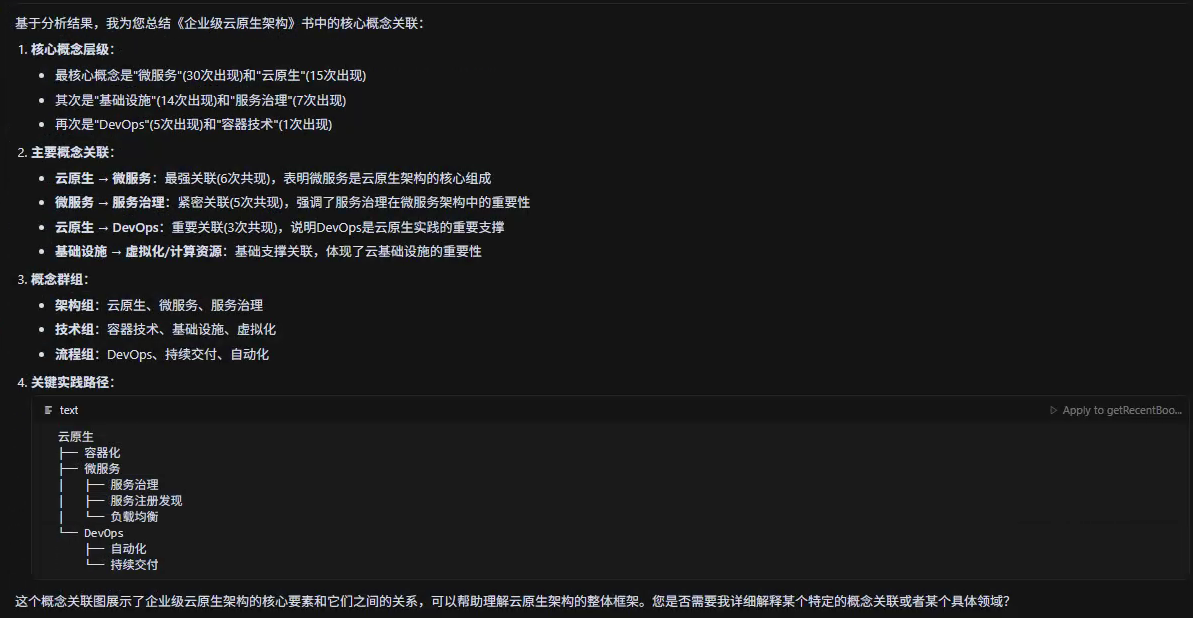
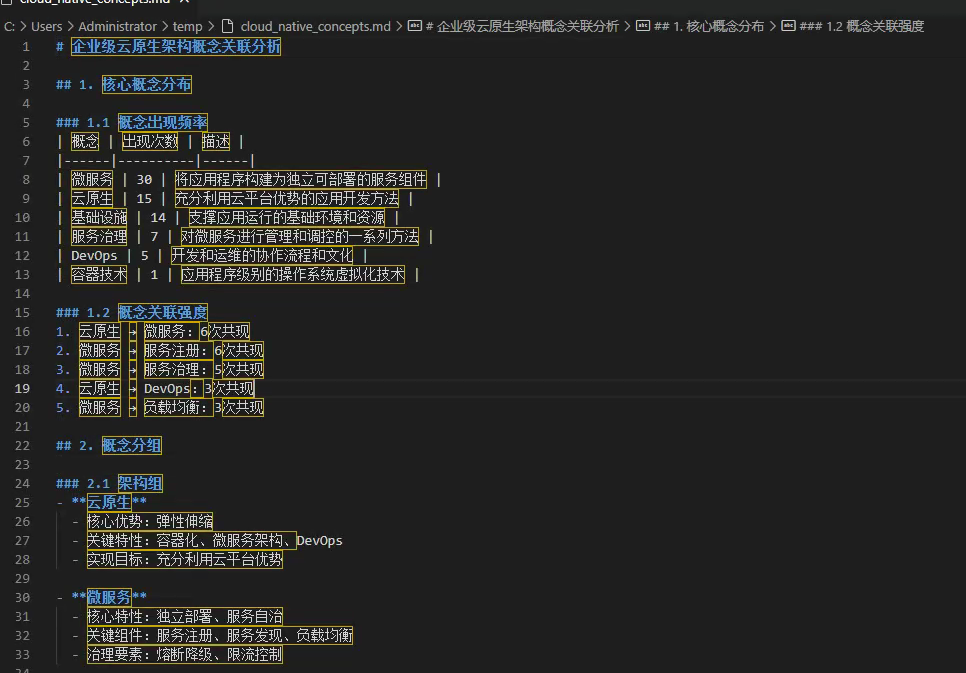
- 知识图谱构建: 将多本书籍的关联内容可视化,例如:生成《企业级云原生架构》这本书中的概念关联图。
- 摘要与导出: 用户可一键导出书籍笔记为 Markdown 或 PDF,用于知识总结或分享。
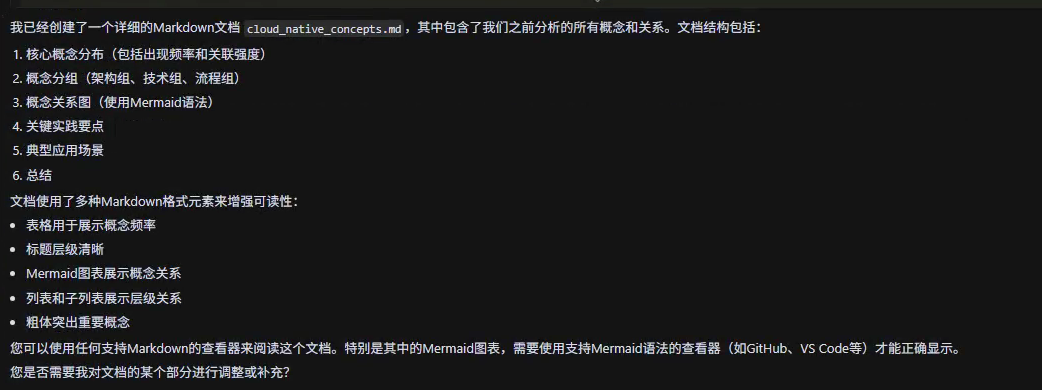
打开这个MD文档。
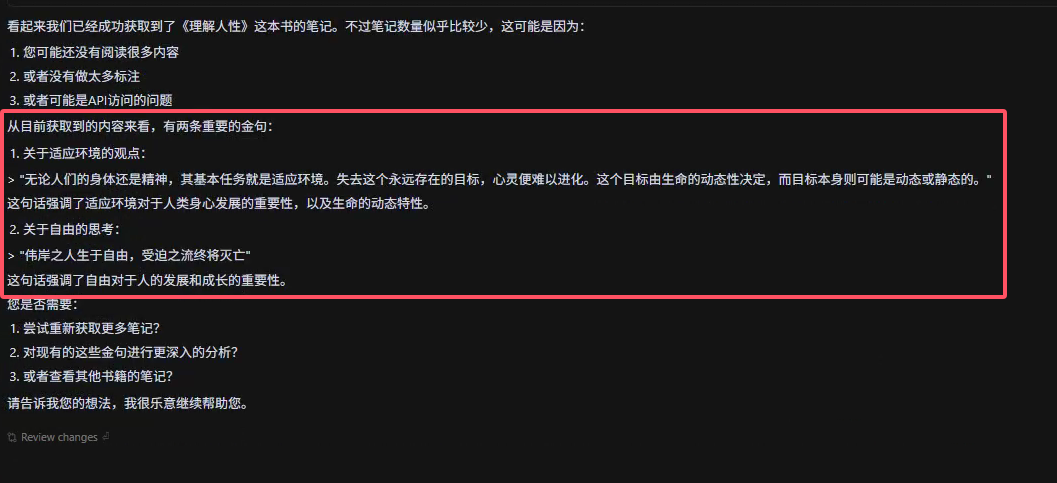
3. 交互式学习与创作
- 问答与归纳: 用户可通过自然语言提问,例如: 提取下《理解人性》这本书的金句,AI 将结合笔记内容生成答案。
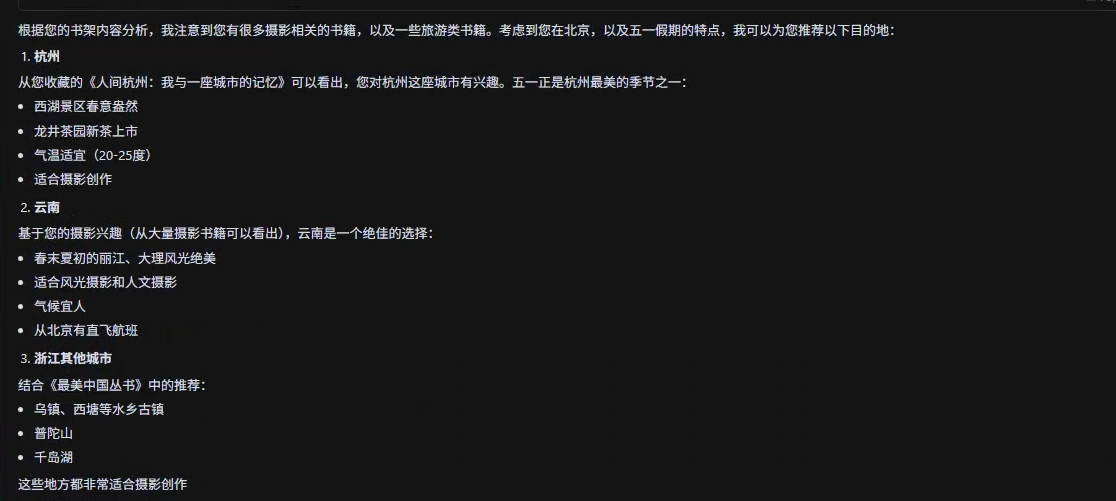
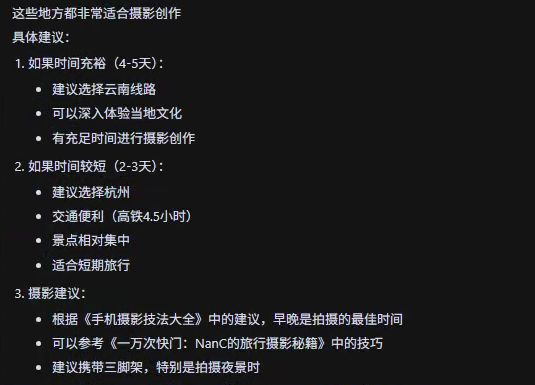
- 内容创作辅助: 利用阅读数据生成推荐内容。比如:我在北京,根据书架上的旅游书籍,帮我推荐一个五一的目的地。
4. 知识共享
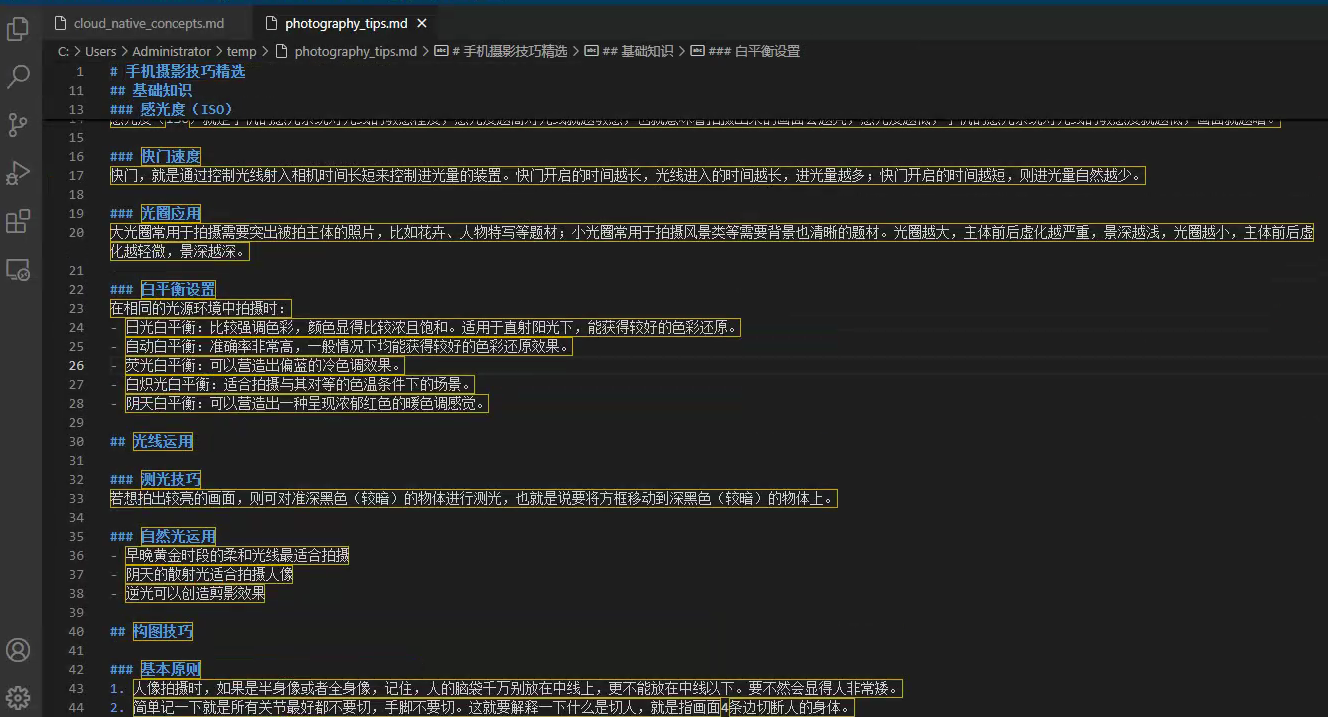
- 知识共享: 比如:根据《手机摄影技法大全》来提取摄影知识,并生成分享文档。
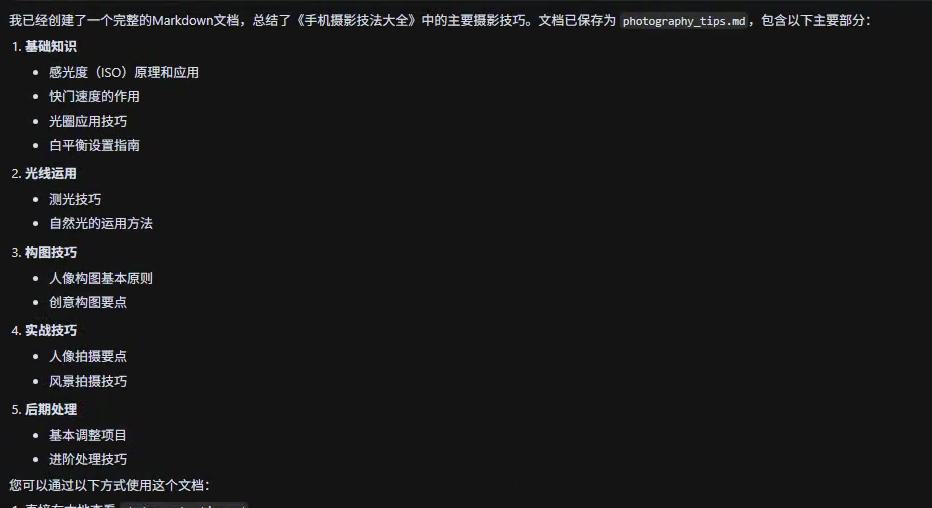
生成的分享文档。
五、优势与创新点
- 隐私与安全
- 数据存储在本地服务器,避免敏感信息泄露。
- 支持多平台
- 跨平台兼容:支持 Windows/macOS/Linux 系统。
- 低成本与易用性
- 开源项目免费使用,部署简单且成本低。
- AI 赋能的深度体验
- 通过 AI 分析挖掘阅读数据价值,提升学习效率。
- 自然语言交互简化操作流程,无需手动整理内容。
六、总结
通过 Cursor AI与微信读书 MCP 服务器的结合,用户能够突破平台限制,将阅读数据转化为可操作的知识资产。该方案不仅提升了阅读效率,还为 AI 辅助学习、创作和协作提供了全新可能性。
未来,随着 MCP 协议的完善和 AI 模型的升级,此类工具将进一步推动个性化知识管理的发展,成为数字阅读生态的重要组成部分。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









