






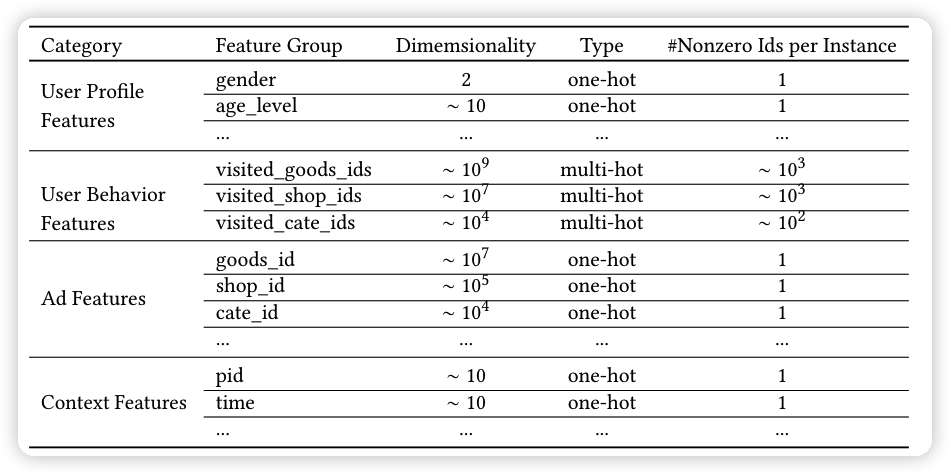
淘宝的【商品、店铺、商品类别】相当于是快手电商的【视频、主播、视频类型】。
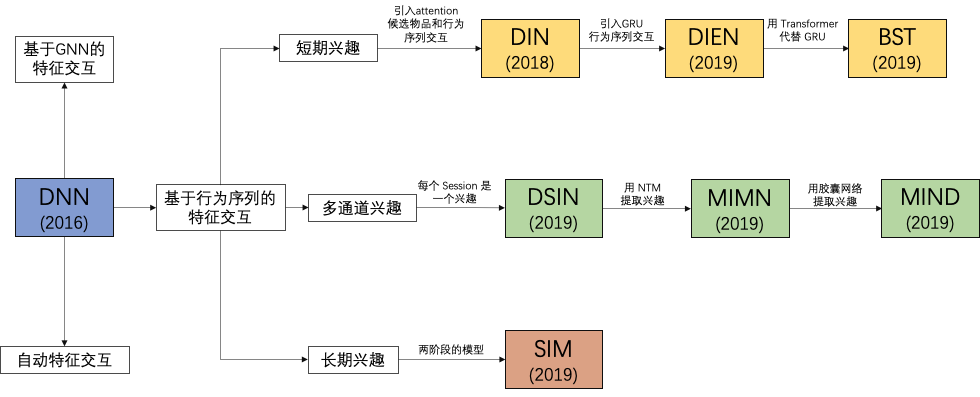
短期兴趣
DIN
Deep Interest Network for Click-Through Rate Prediction, SIGKDD 2018
DNN 有高阶特征交互的能力,但是没有考虑行为序列和候选物品之间的交互。
DIN 对短期行为序列进行建模,并从中提取出短期兴趣。
具体做法是引入了注意力机制,保留历史行为中和候选物品最相关的历史行为,再把这些历史行为相加。
缺点:
-
DIN 虽然考虑到行为序列和候选物品的交互,但是没有考虑到历史行为的相关性,忽略了兴趣随时间的演化。
-
候选物品需要和每个历史行为计算注意力分数,考虑到线上的实时性,DIN 只适用于短期序列,序列长度小于 100(曝光日志时长为 14 天)
-
由于序列较短,可能包含用户一些临时起意的行为,噪声相对较大。另外,在电商等环境下,用户的长期兴趣,无法在短期序列中体现出来。
model
在 DIN 之前的 model,DNN,没有对历史行为进行区分,都是直接使用 sum pooling 把历史行为信息聚合到一起,sum pooling 换成 concat 也可以。
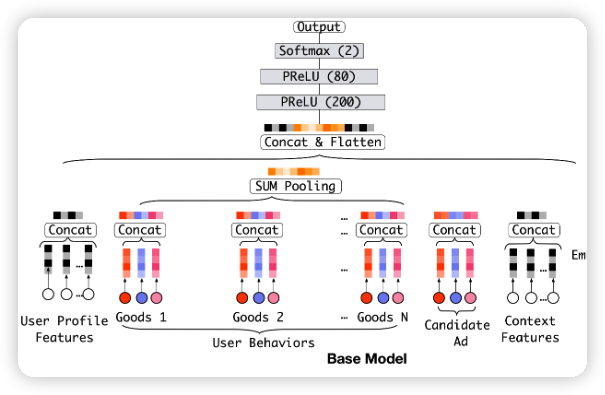
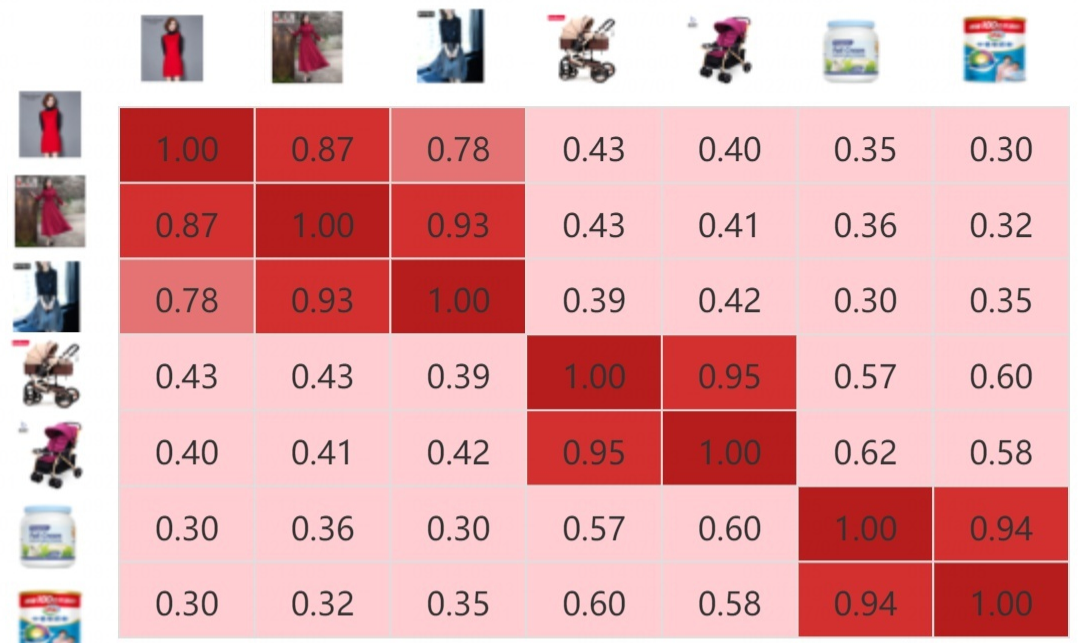
但这样并没有对历史行为进行区分,实际上,用户当前的兴趣应该只和一部分历史行为是相关的。下图所示是一个女生的历史行为,候选物品是上衣,现在要预估这件上衣的 CTR。那么,候选物品和历史行为中的上衣关联很大,而和鞋子、帽子、包包、杯子的关联不大。而 DNN 无法区分历史行为的差别。
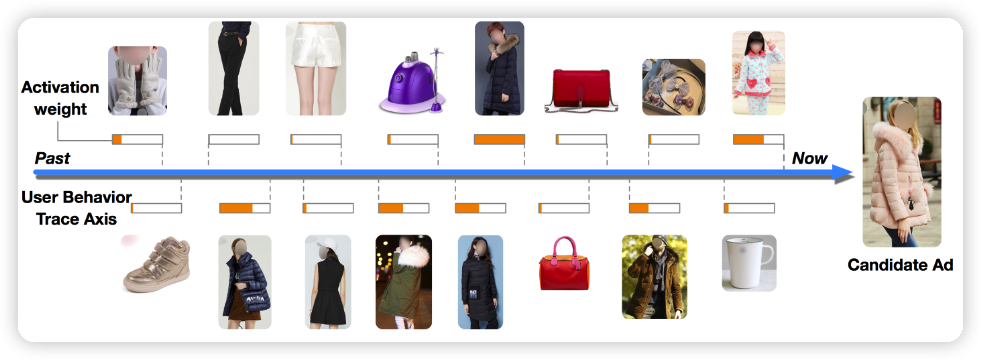
为了解决这个问题,DIN 引入了注意力机制,保留历史行为中和候选物品最相关的历史行为,再把这些历史行为相加。
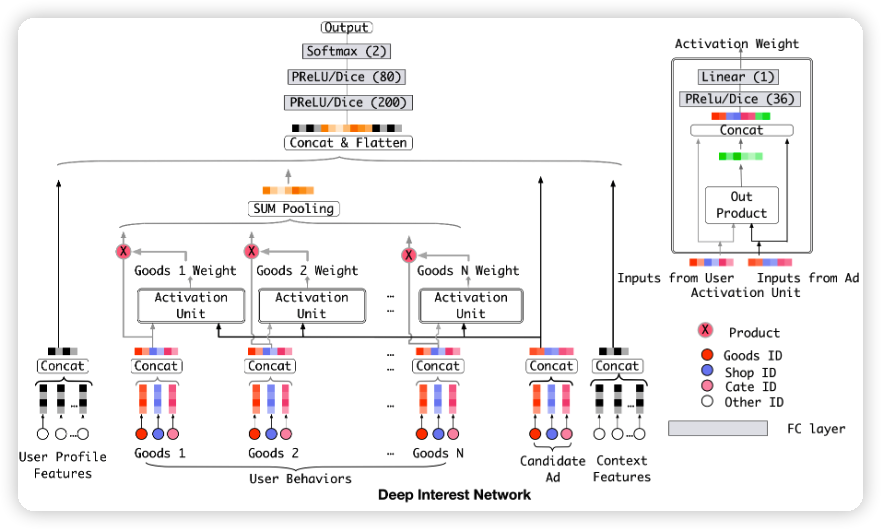
经过 sum pooling 之后的结果如下所示:
$$
V_u = f(V_a) = \sum_{i=1}^{N} w_i * V_i = \sum_{i=1}^{N} g(V_i, V_a) * V_i
$$
V_u 是 sum pooling 之后的结果,V_i 是用户历史行为的 embedding 特征,V_a 是候选物品,w_i 是历史行为 V_i 和 候选物品 V_a 的注意力分数。
注意力的结构如下图所示:
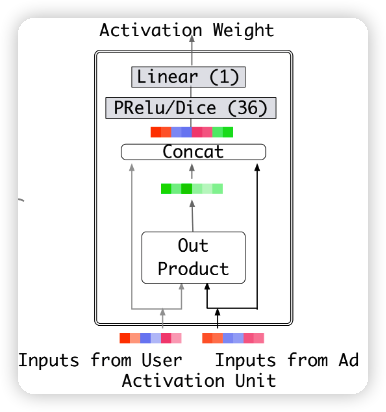
prelu 和 dice 是激活函数,可以加快模型收敛,out product (element-wise product) 也可以是相加、相减。
实验
DIN 比 DNN 的 AUC 高了 1.1%。DIN 在阿里巴巴电商广告推荐场景上线后,CTR 提升了10%,成为当时线上的主流模型。
物品相关性的可视化
阿里巴巴不同商品的维度。
DIEN
Deep Interest Evolution Network for Click-Through Rate Prediction, AAAI 2019
DIN 虽然考虑到行为序列和候选物品的交互,但是没有考虑到历史行为的相关性,忽略了兴趣随时间的演化。
DIEN 使用兴趣提取层(GRU),让行为序列交互,捕捉到历史行为的序列信息;再用兴趣进化层(带注意力的 GRU),让序列信息与候选物品之间进行信息交互,对用户的兴趣演化过程建模,当然本质上是想找出同一个主题的行为序列。
缺点:RNN 的计算速度过慢,导致线上服务延迟增加,为了降低延迟,就需要降低序列信息的长度,文中的序列长度小于100(曝光日志时长为 14 天)
model
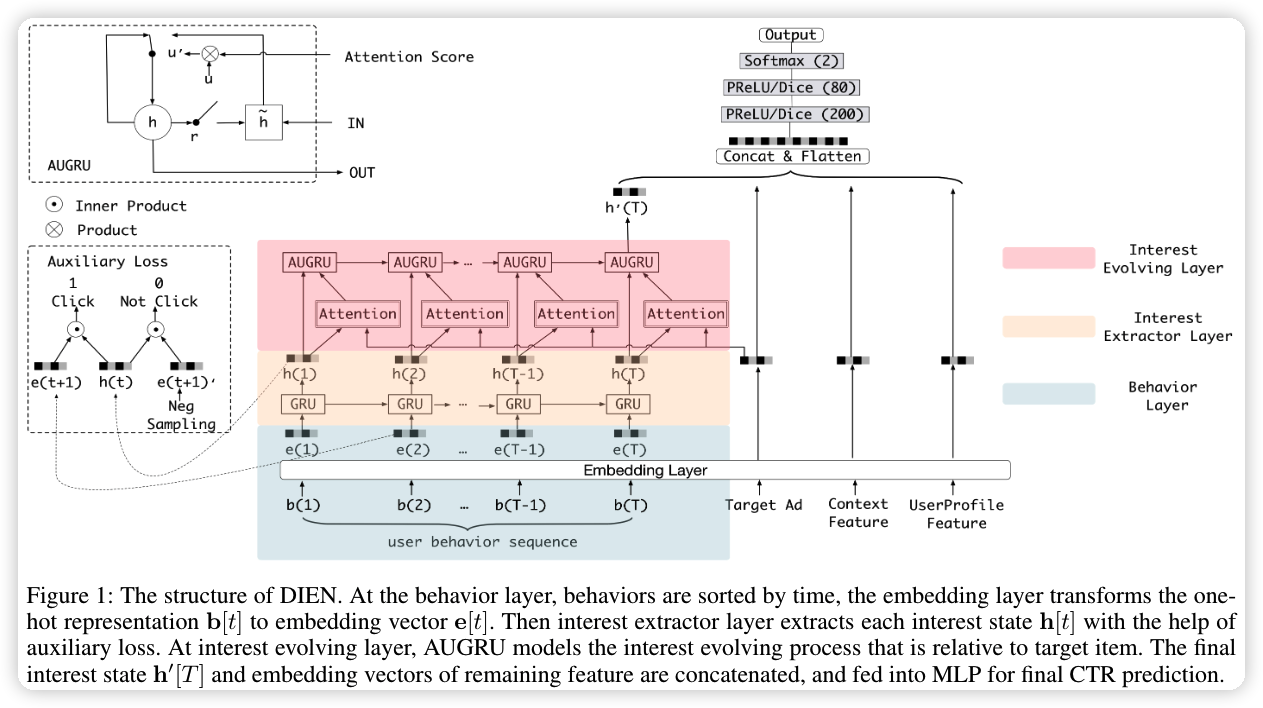
可以理解是打算做两次 GRU,在第二次 GRU 中加入注意力,注意力分数与输入相乘。
Interest Extractor Layer (GRU)
GRU 可以捕捉到用户历史行为的序列信息。并且 GRU 相比于 RNN 可以克服梯度消失的问题,还能提供更多的语义信息。
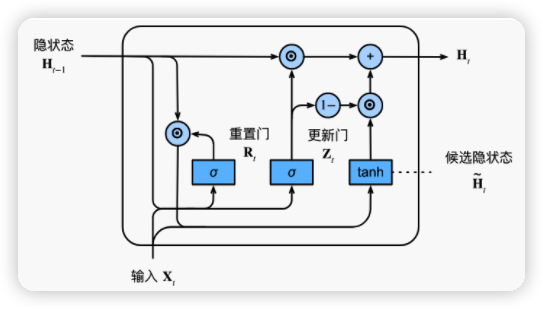
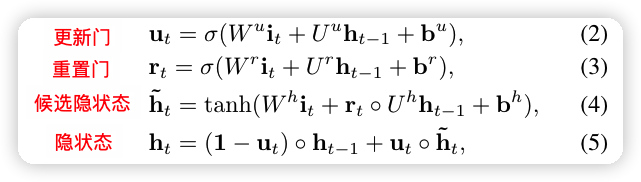
-
更新门:忽略输入的程度
-
重置门:保留上个时刻的隐状态的程度
辅助 loss
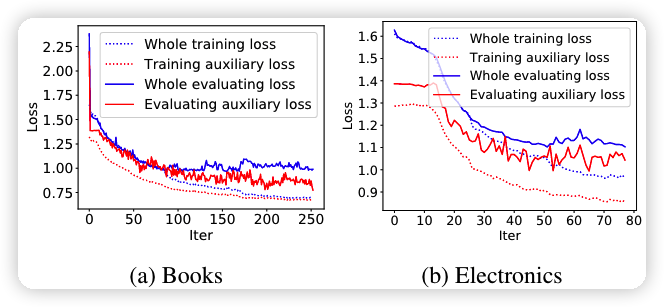
用户的每一步兴趣都会影响用户的连续行为,现在的隐状态 h_t 只能捕捉到历史行为的序列关系,为了让 GRU 更好地从历史行为中捕捉到兴趣,也就是让隐状态 h_t 更有效地表达用户的兴趣。为了有监督的学习到兴趣隐状态 h_t,从下一时刻 采样得到点击样本 ,负采样得到未点击样本 ,辅助loss 表示为下面的形式:
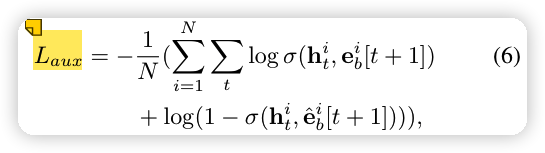
其中,\sigma 是 sigmoid 函数,h_t^i 是第 i 位用户的第 t 个隐状态。这一个辅助 loss 蛮有道理的,因为两层 GRU 确实不太好 train,第一层是重点。
总 loss
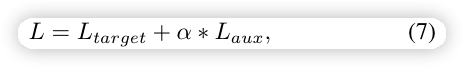
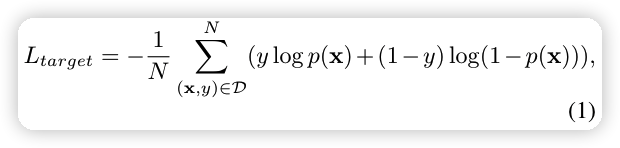
\alpha 是超参数,L_{target} 是模型的损失。
Interest Evolution Layer (基于注意力的 GRU)
基于注意力的 GRU 为了克服兴趣漂移(interest drifting),克服兴趣漂移也就是对用户的兴趣演变过程建模。兴趣漂移:比如用户在一段时间对各种书籍感兴趣,而在另一段时间对各种衣服感兴趣。
虽然兴趣可能相互影响,但是每种兴趣都有自己不断演变的过程,比如书籍和衣服的演变路径几乎是独立的,而我们主要关注和目标广告相关的演化路径。例如目标广告是计算机相关书籍,那么书籍相关的演变路径显然比购买衣服相关的演变路径更重要。既然要考虑和目标广告相关的演变路径,那么自然想到利用注意力机制。
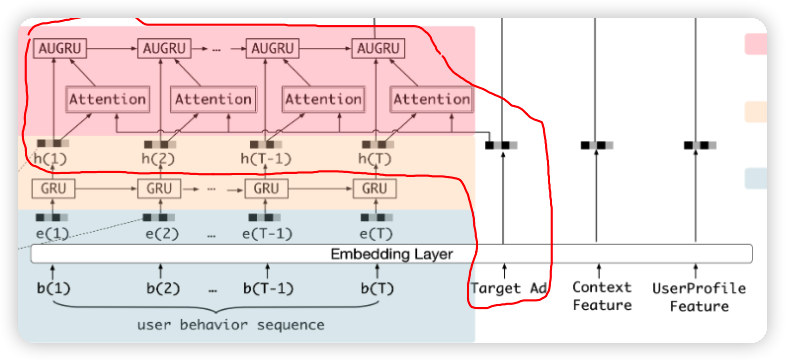
AUGRU
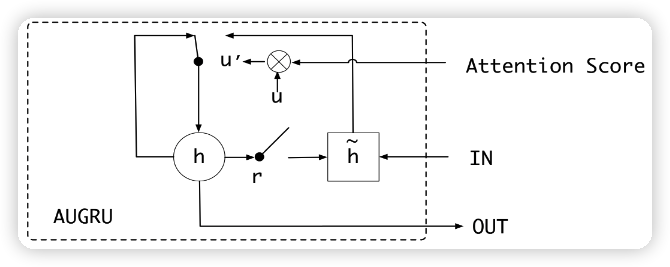
更新门的结果✖️注意力分数 代替 更新门的结果,如下所示
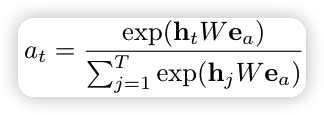
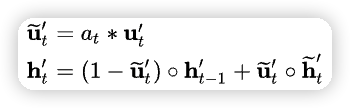
注意力的计算只到当前序列长度 T,We_a 是待学习的注意力权重。
实验
用户49天内购买的物品是候选物品,用户14天内的浏览记录是历史行为。
离线结果:
| 模型 | AUC | AUC提升百分比 |
|---|---|---|
| Base模型(图2) | 0.6350 | 0.00% |
| WDL | 0.6362 | +0.19% |
| PNN | 0.6353 | +0.05% |
| DIN | 0.6428 | +1.23% |
| 两层GRU+Attention | 0.6457 | +1.68% |
| DIEN | 0.6541 | +3.01% |
线上AB结果:
| 模型 | CTR提升 |
|---|---|
| Base模型 | 0% |
| DIN | +8.9% |
| DIEN | 20.7% |
DIEN 上线后,相比于 base 模型,CTR 提升了 20.7%,相比 DIN,CTR 提升了10%以上。
消融实验
消融实验证明辅助 loss 的有效性
不同物品的注意力分数的可视化
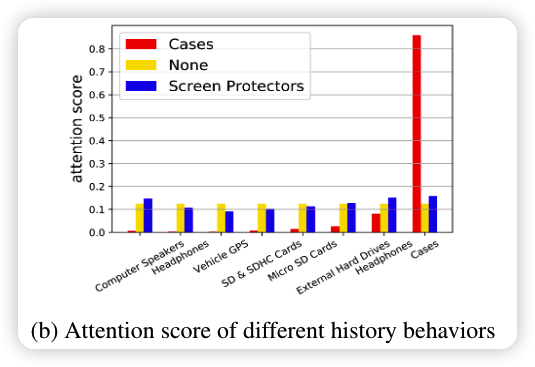
BST
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba, KDD 2019
DIEN 虽然捕捉到了用户历史行为的序列信息,对用户的兴趣演化过程建模。但是 GRU 的计算速度过慢,为了提升速度,序列的长度就很短,和 DIN 差不多长。
为了加快运算速度,BST 用 Transformer 代替 GRU,速度和 DIN 差不多。BST 还在行为序列中加入类别特征和商店 ID 特征,解决冷启动。
model
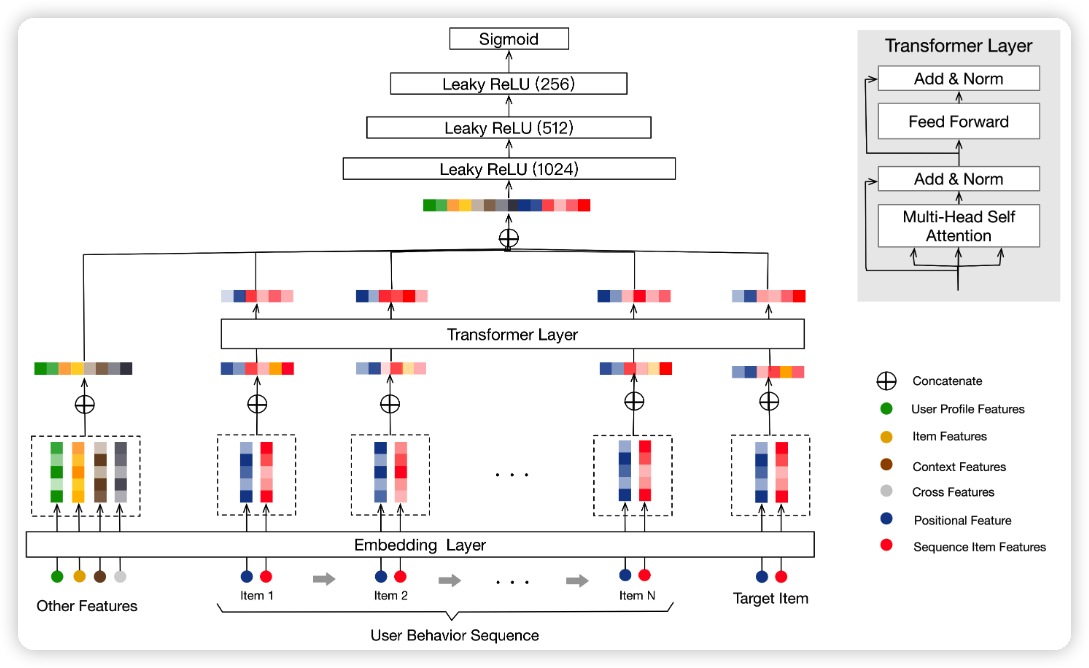
BST 主要为了捕捉历史行为的序列信息,所以特征最后简化为 3 类:用户历史行为,候选物品,其余特征
Position Embedding
为了捕捉历史行为的序列信息,BST 使用了位置特征。position feature 和 item feature 是 concat 的。
postion 表示如下:
$$
pos(v_i) = t(v_t) - t(v_i)
$$
t(v_i) 表示第 i 次行为的时间,t(v_t) 是点击候选物品的时间。
然后 postion 经过 embedding 的到 position feature,postion feature 的大小为 \mathbb{R}^{k \times d},某一次行为的 item feature 大小为 \mathbb{R}^{n \times d} 。
Item feature 包含 item 的 id 特征、类别特征、商店id特征。引入类别特征和商店id特征能够很好的解决 item 冷启动问题。
实验
实验细节

速度对比,没有和 DIEN 对比,但是考虑 DIEN 比 DIN 慢很多,那么相比而言,BST 就比 DIEN 快很多了。
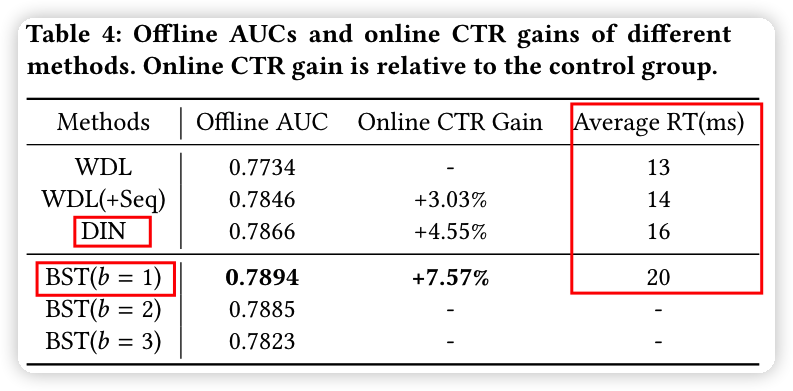
其中,RT 是 response time,b 是 transformer block 的数量
实验结果:
| 模型 | AUC | CTR提升 |
|---|---|---|
| WDL | 0.7734 | 0.00% |
| WDL+seq | 0.7846 | +3.03% |
| DIN | 0.7866 | +4.55% |
| BST | 0.7894 | +7.57% |
离线 AUC 相比 DIN 提升 0.35%,CTR 相比 DIN 提升 3%,取得了不错的效果。
从离线实验结果来看,BST使用Transformer建模用户序列,取得了不错的效果,但是更像是堆积木的结果,没有像DIEN那样结合具体业务进行优化,没有太多亮点。
多通道兴趣
DSIN
Deep Session Interest Network for Click-Through Rate Prediction, IJCAI 2019
DIEN 考虑先捕捉到历史行为的序列信息,再对用户的兴趣演变过程建模。
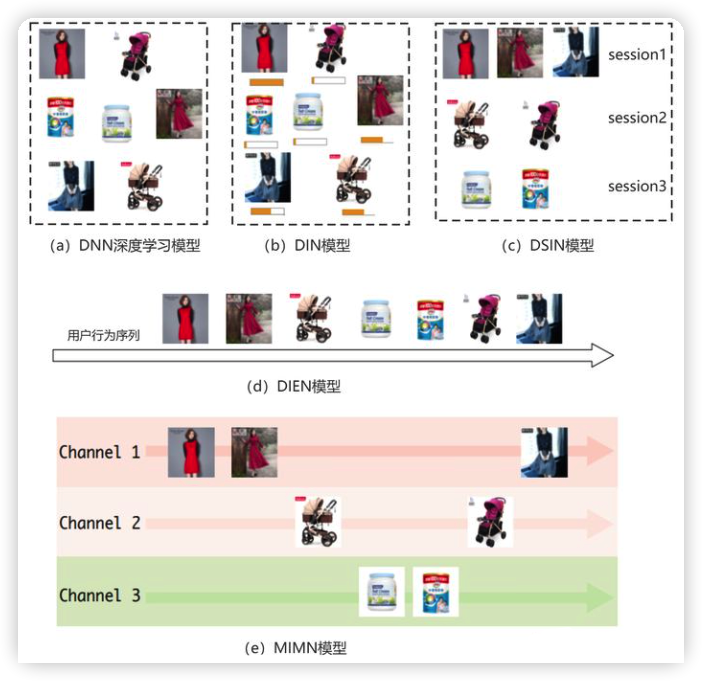
但经过阿里技术人员的观察发现,用户每一次打开淘宝购物,在这一段时间内的兴趣都差不多;而下一次打开淘宝之后兴趣大概率不同,但是有关联。所以,将用户的行为序列划分为不同的 Session,如果用户半小时内没有点击行为,Session 断开。用户在相同 Session 内的行为是接近的,不同 Session 的行为差异较大。在 Session1 内,用户点击的都是裤子相关的商品,在 Session2 内点击都是首饰相关的商品,在 Session3 内点击的都是衣服相关的商品。

于是,DSIN 不是像 DIEN 把所有历史行为都往里怼,而是考虑通过 session 的方式对历史行为建模。
具体做法是,先将历史行为按时间排序,再以 30 min 为间隔进行切分。然后用 self- attention 提取每个 session 中的用户兴趣,再用 Bi-LSTM 对用户的兴趣演变过程建模,让不同的 session 进行信息交互,提取 session 的序列信息。最后,用注意力的方式进行 session 和候选物品之间的信息交互。
当然,DSIN 的漏洞太多了,比如 session 这种方式可能只适合于手淘,在直播推荐不太管用。其次,针对不同的场景,session 的长度不同,session 如何选择又是个问题。最后,DSIN 不太适合对较长的序列建模,因为 session 的长度固定为 30 min(浏览器的默认长度),但是用户购物可能连续购物几个小时,强行对用户行为进行切分会减弱行为的序列特征。一种解决方式是根据不同的场景设置不同的 session。另一种是训练一个网络去动态的选择 session 的切割长度,当然我想它们肯定已经做过了,只是发现网络不太好 train,所以采用固定的 session,然后用 self- attention 尽可能的保留 session 之间的相关性。
model

Session Division Layer
这一层是将用户的历史行为进行切分,首先将历史行为按时间排序,判断两个行为之间的时间间隔,如果前后间隔大于 30min,就进行切分(划一刀)。当然 30 从离线实验结果来看,BST使用Transformer建模用户序列,取得了不错的效果,但是更像是堆积木的结果,没有像DIEN那样结合具体业务进行优化,没有太多亮点。min 不是定死的,具体跟着自己的业务场景来。

划分完成之后,我们把长度为 N 的用户历史行为是 S = [b_1,...,b_N] \in \mathbb{R}^{N \times d} ,转为了 session 特征 Q \in \mathbb{R} ^ {K \times T \times d},这里的 K 是 session 的数量。
比如上面这个历史行为会被划分为 4 个会话,分别用 Q_1, Q_2, Q_3,Q_4 表示。第 k 个 session 就是 Q_k = [b_1,...,b_T] \in \mathbb{R}^{T \times d},其中 T 是这个 session 内用户行为的长度。
Session Interest Extractor Layer
这一步用 self- attention 提取每个 session 中的用户兴趣。
进行 self- attention 之前要做 postion embedding。
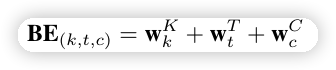
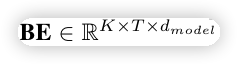
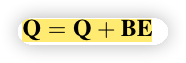
针对每个行为,position embedding 由三项组成,session 的位置,session 中的时间位置,行为编码。
在做 self- attention 的时候,为了减少 self-attention 的计算量,又不降低效果,DSIN 沿着最后一个维度拆分 session 特征 Q \in \mathbb{R} ^ {K \times T \times d},假设 head 数量为 H , 那么第 k 个 session 送入的特征大小为 Q_k = [Q_{k1},...,Q_{kH}] \in \mathbb{R} ^{H \times T \times \frac{d}{H}} 。这个操作好 sao,我在 cv 没见人用过。
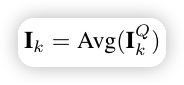
在做完 self-attention 之后,再接一个 avgpooling,压缩特征 token 数量,最后输出 I_k \in \mathbb{R} ^ {1 \times d} ,这是第 k 个 session 抽取特征的结果。
Session Interest Interacting Layer
用双向的 LSTM 提取 session 的序列信息,前向和后向的隐状态 concat 得到输出的隐状态。
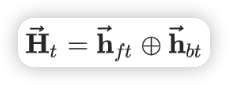
Session Interest Activating Layer
这种局部 Attention 机制,DIN 和 DIEN 里都见识过了,这里就不详细解释了。
-
会话兴趣提取层
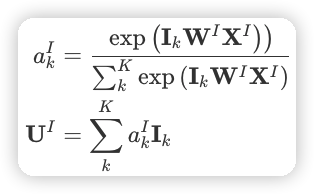
这里 I_k \in \mathbb{R} ^ {1 \times d} ,W^I \in \mathbb{R} ^{d \times d} 是参数矩阵,X^I \in \mathbb{R} ^ {d \times 1} 是候选商品的 embedding 向量,
-
会话兴趣交互层
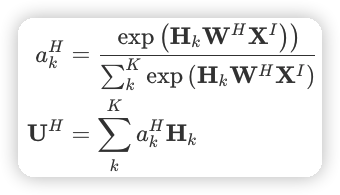
会话兴趣交互层的做法也一样,只是用双向的 LSTM 提取到了 session 的序列信息。
实验
DSIN 离线 AUC 结果:
实验结果来看,DSIN 相比 DIEN 离线 AUC 提升了 0.5% 以上。需要再次强调的是,DSIN 基于 Session 的假设并不适合所有场景,对于不满足 Session 内在结构的场景,使用 DSIN 不一定有效果,这也强调了模型和业务相结合的重要性。
| 模型 | 广告数据集 | 电商推荐数据集 |
|---|---|---|
| WDL | 0.6326 | 0.6432 |
| DIN | 0.6330 | 0.6459 |
| DIEN | 0.6364 | 0.6473 |
| DSIN | 0.6375 | 0.6515 |
self-attention 和 Session Interest Activating Layer 的可视化,一个在下面,另一个在上面,颜色越深,权重越大。

MIMN
Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction, KDD 2019
DIN 是为了从短期序列中提取出短期兴趣。DIEN 是为了对用户的短期兴趣演化过程建模。而 DSIN 通过 session 的方式对短期兴趣建模。但是 DIN 和 DEIN 只能处理长度为 50 的行为序列,DSIN假设行为序列存在 Session 结构,因此都有各自的不足。
MIMN 将兴趣细分为不同的兴趣通道,在不同的兴趣通道上对兴趣的演化过程建模,生成不同的兴趣向量,避免不同兴趣之间相互干扰。并且 MIMN 可以支持的行为序列长度为 1000。
缺点:在处理大数据量的时候,容易被噪声干扰,导致效果下降。
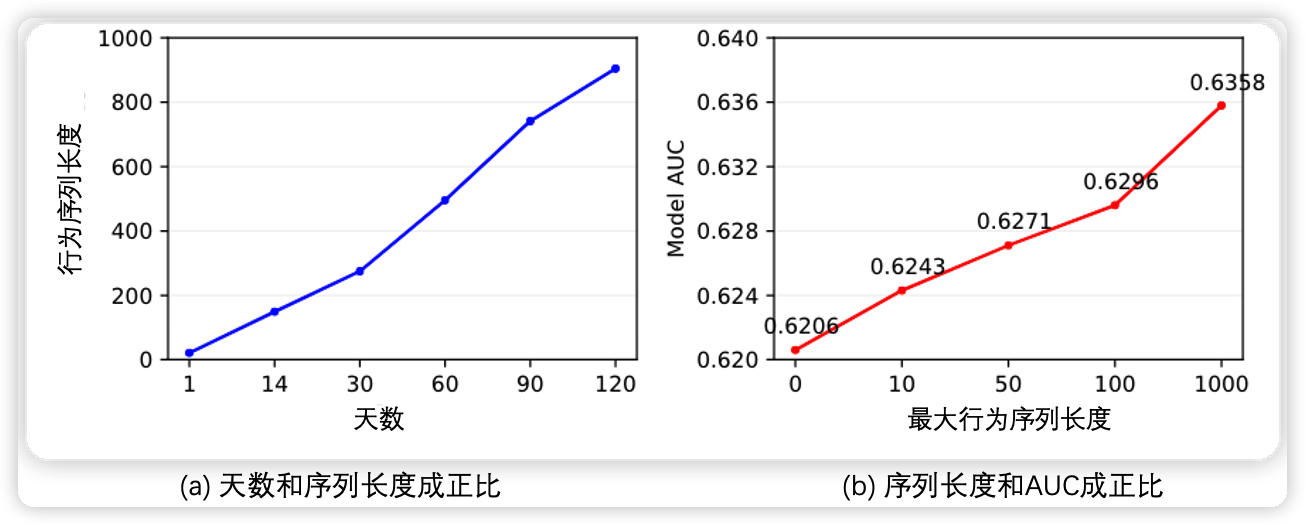
为什么需要对用户的长期行为建模?
序列越长,准确率越高。
model
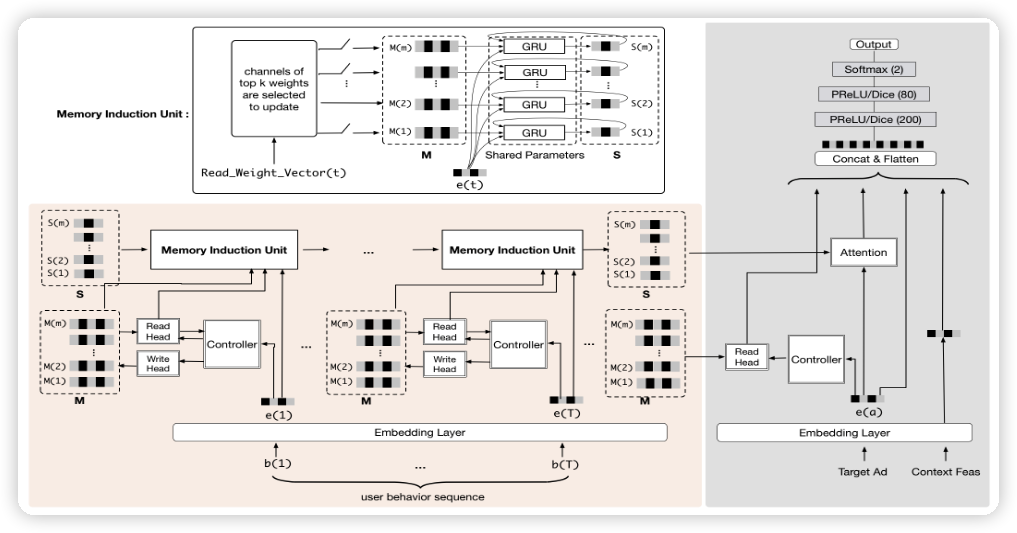
MIMN 引入了 2014 年 deepmind 的 NTM (Neural Turing Machines) ,模型看上去好复杂,但本质上 NTM 是带 Memory 的 RNN。NTM 的结构如下所示:
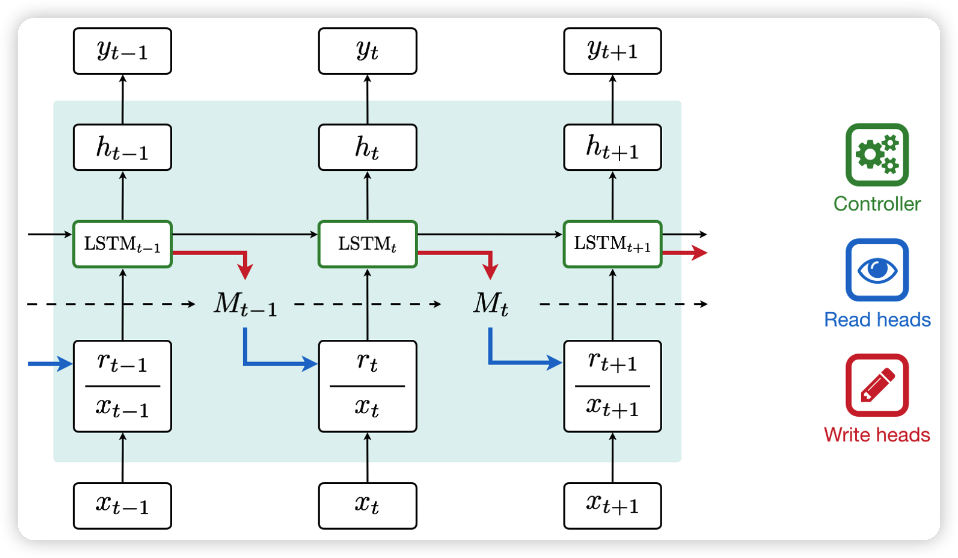
NTM 由 controller、read/write head、memory 组成,memory 保存一组记忆向量 M \in \mathbb{R}^{m \times d}。记忆向量 M 最开始是随机初始化的。t 时刻的行为 x_t \in \mathbb{R}^{1 \times d} 到来的时候,controller 会产生一个 key vector k_t,它与记忆向量 M 交互得到读向量 r_t \in \mathbb{R}^{1 \times d},交互的方式和注意力机制类似,但是注意力机制使用的是点积操作,这里是计算余弦相似度,为了避免记忆向量的之间尺度不一致,产生马太效应。读向量的计算方式:
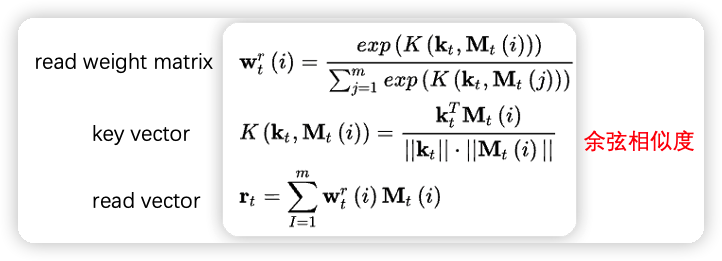
然后把从 memory 中得到的读向量 r_t 和 t 时刻的行为 x_t concat 起来,送给 LSTM,它会输出隐状态 h_t 。最后,controller 会产生一个 erase vector e_t 和 add vector a_t,这两个向量会和写权重矩阵 w_t^w 相乘,得到 erase 矩阵 E_t 和 add 矩阵 A_t,然后通过两个矩阵去更新记忆向量 M 。写权重矩阵 w_t^w 的和读权重矩阵 w_t^r 的计算方式一样。记忆向量更新如下:
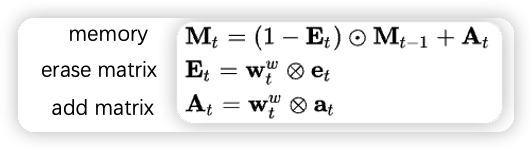
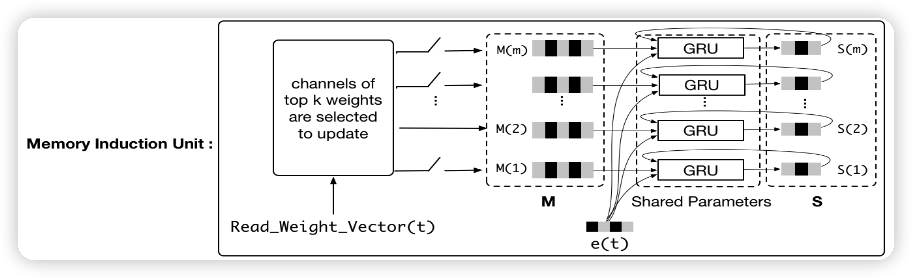
于是,基于 NTM,我们便能从行为序列中得到 m 个不同的有关兴趣的记忆向量。
但是,记忆向量之间并没有交互,这怎么完成呢?MIMN 引入 GRU,进行记忆向量之间的交互,从中捕捉到用户的兴趣 S \in \mathbb{R}^{m \times d}。方式如下:
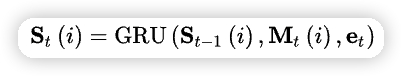
有了每个通道的兴趣表达,就可以和候选商品做 cross attention 了。
如何做到实时?
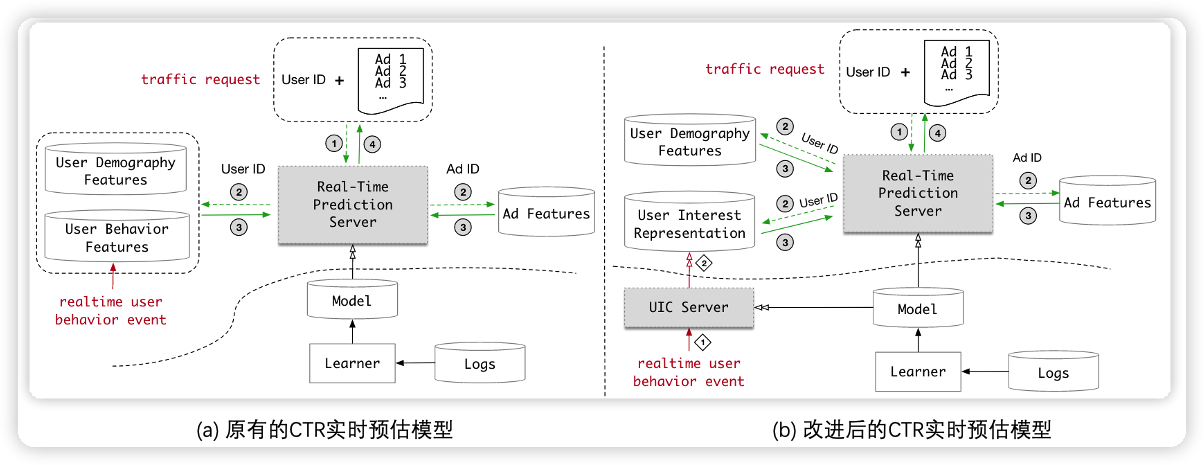
原有的 ctr 实时预估模型如上图 (a) 所示,来一个请求,就根据候选商品去提取用户的行为序列特征,然后再送入模型进行 ctr 预估,排序后将商品返回给用户。为了实时性,对于 DIEN 这样的结构而言,序列长度就不能太长。MIMN 为了提升序列长度,引入了 UIC 模块,保存用户的兴趣向量。具体做法是把用户的兴趣向量离线保存起来,模型可以直接获得用户兴趣向量,省去了计算兴趣向量的计算量。以 MIMN 为例,如下图所示,将兴趣向量 S(1),...,S(m) 和记忆向量 M(1),...,M(n) 存储在数据库中,用的时候直接读取。更新这些向量的话,就离线更新就行。
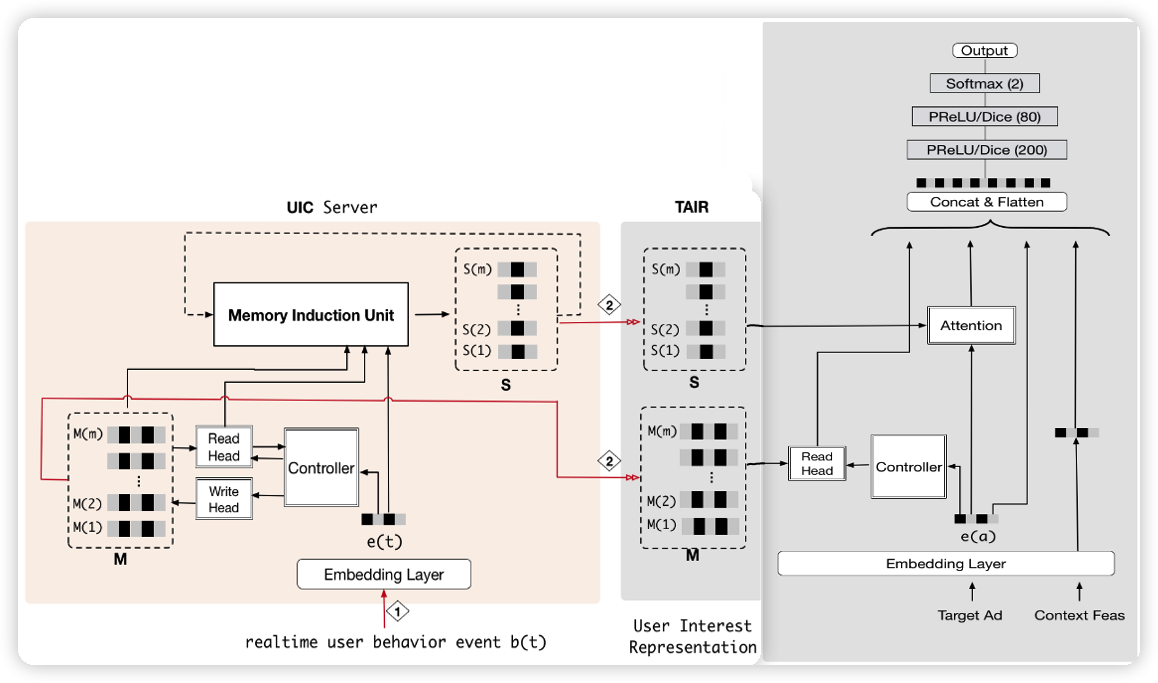
最后,MIMN 的行为序列长度可以做到 1000。阿里在改进后的实时预估系统上线后,DIEN 的模型预估时间从 200ms 降低至 19ms,性能大大提升。
实验
相较于 DIEN,MIMN 在线上的 AUC 提升了 1%。最后一行说明了 MIMN 在处理大数据量的时候,容易被噪声干扰,导致效果下降。这里的大数据量是指加入了双 11 当天的数据。

MIND
Multi-Interest Network with Dynamic Routing for Recommendation at Tmall, CIKM 2019
优点:用胶囊网络对用户兴趣建模。
缺点:水论文的吧?
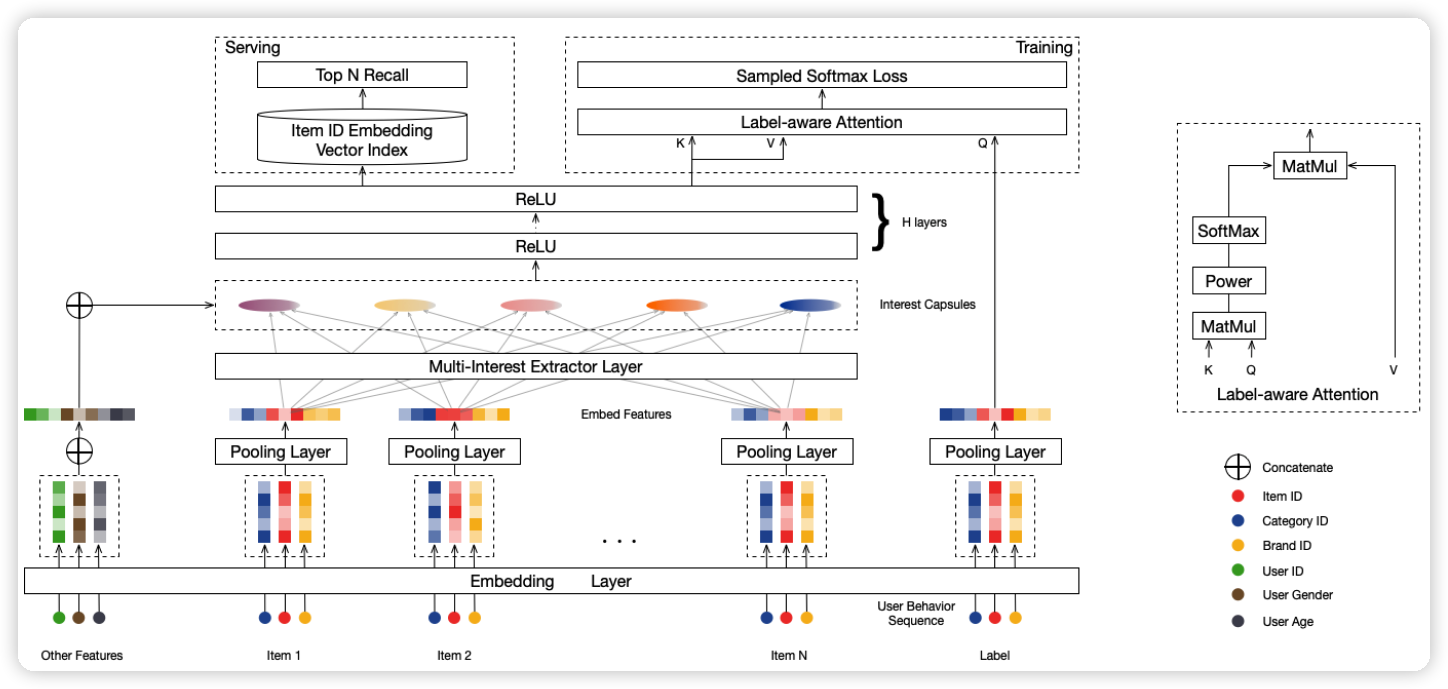
multi-interest extractor layer 是两层的胶囊网络,胶囊网络可以看作是另类的注意力机制。如何得到动态的通道呢?为了每一个通道都代表一种兴趣,文中采用了 k-means 聚类的方式,得到通道的数量,聚类的数量是通过公式算出来的。得到多通道兴趣之后,再和候选物品做 cross attention。
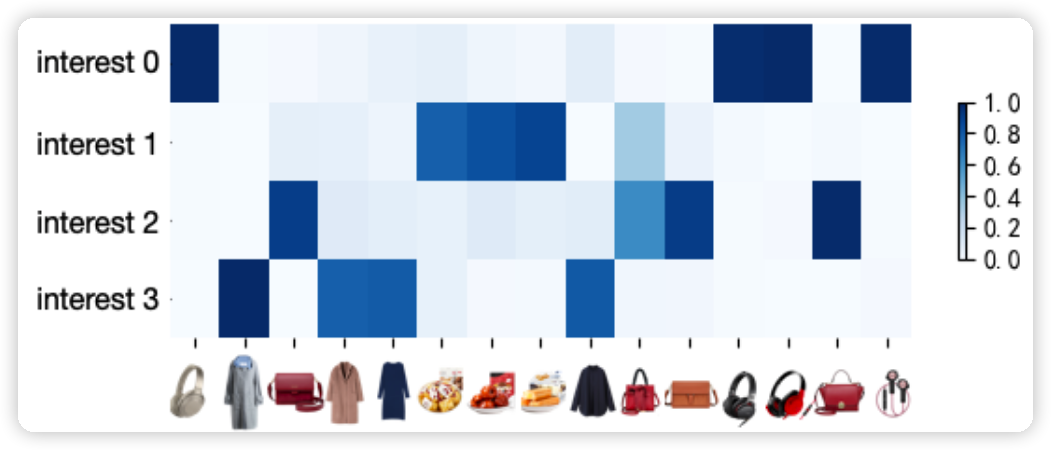
不同兴趣通道的物品的相关系数。兴趣 0 是耳机,兴趣 1 是食物,兴趣 2 是包包,兴趣 3 是衣服。
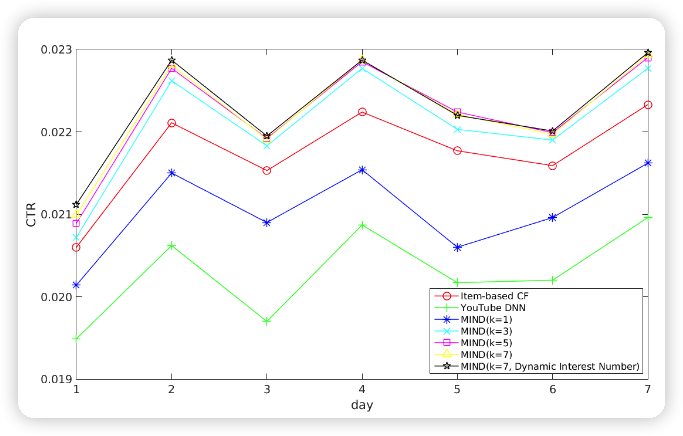
线上效果,CTR 相比于 DNN 提高了 0.3% 左右。
长期兴趣
SIM
DIN, DIEN, MIMN 虽然取得了不错的效果,但是它们支持最长的用户行为长度为 35, 50, 1000。 如果再增加长度,效果会下降,速度也会下降。
SIM 将序列长度提升为 54000,相比 MIMN 提升了 54 倍,但是耗时只增加了 5 ms。
具体的做法是把这个任务拆分为两步,第一步可以看作是召回,从长度 10000+ 的用户行为序列(长期行为)中筛选出:100+ 个与候选物品最相关的行为;第二步看作是排序,输入经过筛选的长期行为、短期行为、候选物品、其他特征(用户画像、商家信息等),然后用 DIEN 或 Transformer 建模。
不足:用空间换时间,需要离线构建索引,存储开销增加了。6 亿用户需要 22 TB 的空间。
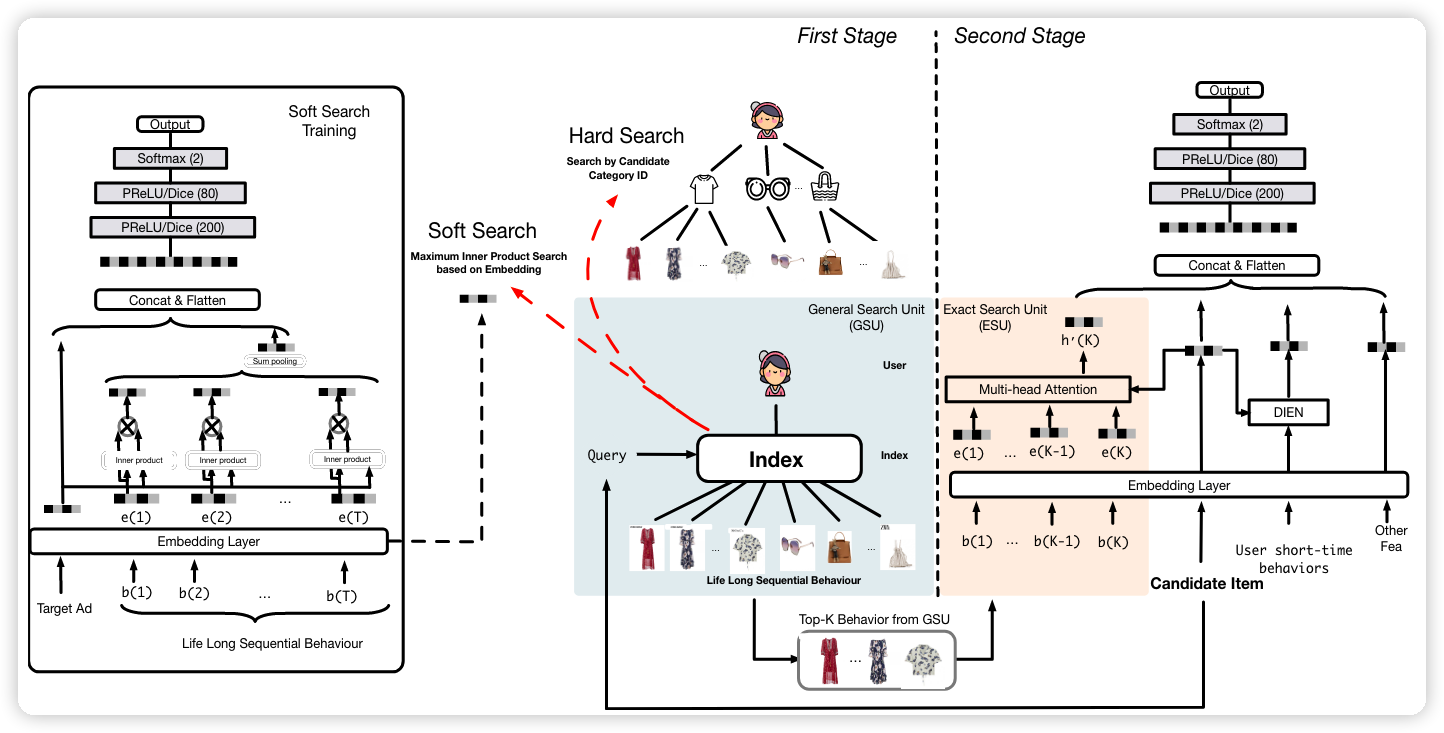
First Stage: GSU
General Search Unit
在第一个阶段,如果使用大模型的话,10000+ 的行为序列,模型速度会很慢;但如果使用小模型的话,效果又不好。于是,作者取了 trade-off,线下用 hard search,线下用 soft search。但在实际业务中,作者发现两种搜索模式的效果并没有太大差异,而性能上,明显 Hard Search 更有优势,因此线上采用 Hard Search(单个用户平均存储消耗 22TB。。。)。
Hard Search 从历史行为中,检索出和候选物品类别相同的行为。Soft Search 根据候选物品 Embedding 和历史行为 Embedding 的内积大小来进行检索。
假设用户行为长序列为 B = [b_1,b_2,...,b_T] ,其中 b_i 代表用户的第 i 个行为,T 代表了序列长度。GSU 每一个行为计算一个相关性分数 r_i,然后根据从长序列中选出 Top-K 个相关的行为,构成新的子序列 B^{*} 。r_i 的计算方式如下所示:
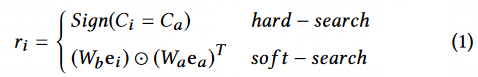
Hard Search
Hard Search 是无参数的,直接从历史行为中,检索出和候选物品类别相同的行为。其中 C_a 是候选物品的种类,C_i 是第 i 个用户的行为种类。
Soft Search
在 Soft Search中,将用户行为序列 B 映射成 Embedding 表达 , 和 都是待学习的参数。其中 代表了候选物品的 Embedding, 代表了第 个用户行为的 Embedding。
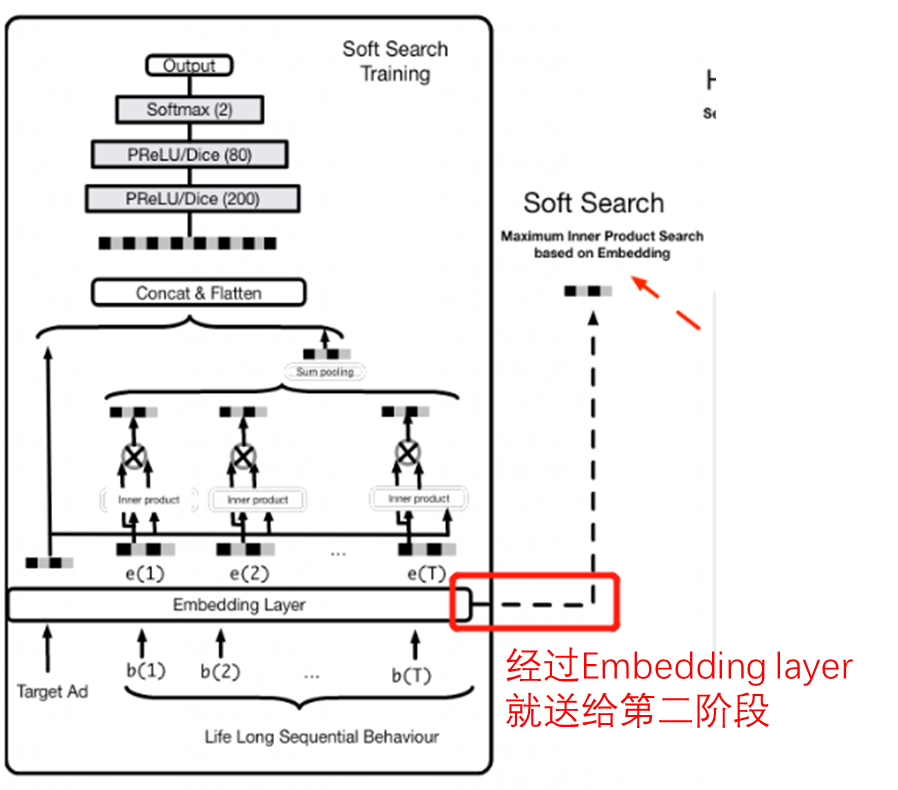
请注意,特征从 embedding layer 就送往 ESU。上面和 DIEN 类似的网络会有输出,也会有辅助的 loss 去约束 soft search training,这是为了得到经过 soft search 之后的长期行为。
Second Stage: ESU
Exact Search Unit
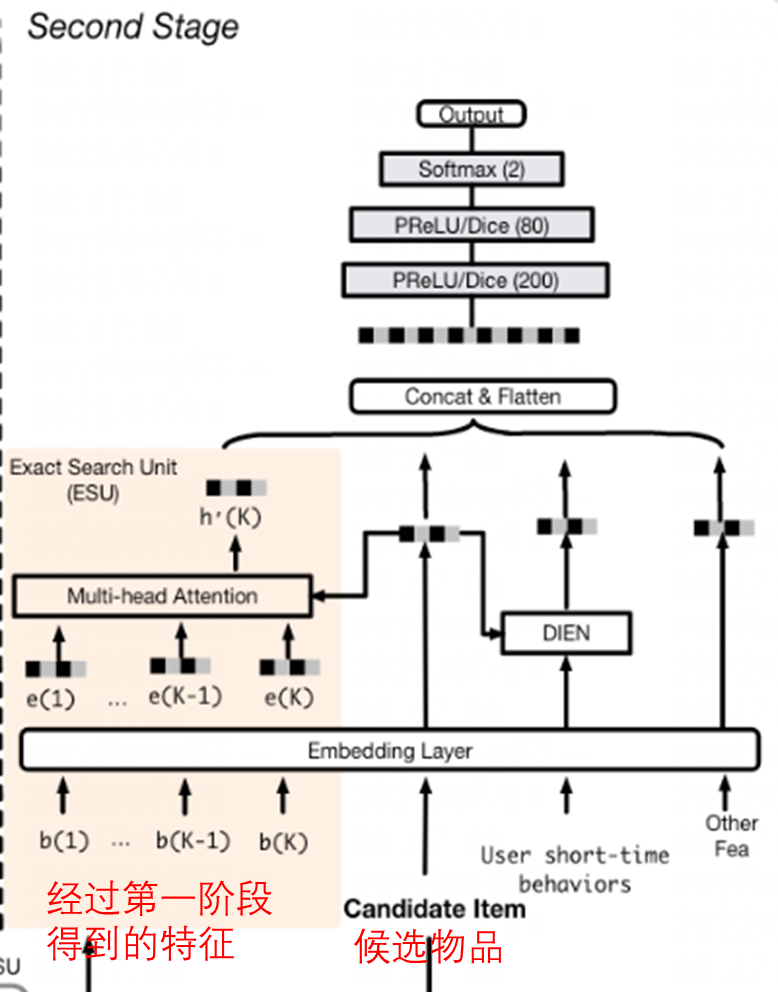
ESU 的 position embedding 是行为发生时间和候选物品之间的时间差 D = [∆1; ∆2; ...; ∆K ],再编码为 embedding E_t = [e_{1}^T; e_{2}^t; ...; e_{K}^t ]。经过第一阶段得到的特征 B^{*} 被编码为 E^∗ = [e^∗_1; e^∗ _2; ...; e^∗_ K ]。然后二者 concat 起来,送往 Transformer 做 cross attention。
整体的 Loss 为两阶段 loss 的加权和(第一阶段采用 hard search 时,\alpha = 0, \beta = 1;第一阶段采用 soft search 时,\alpha = 1, \beta = 1 )
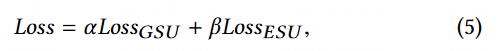
部署
考虑到离线效果提升和在线资源开销的性价比,阿里巴巴最终把 hard search 方式的 SIM 部署到在线广告系统,soft search 用于离线。咱们是两种方式并行的。
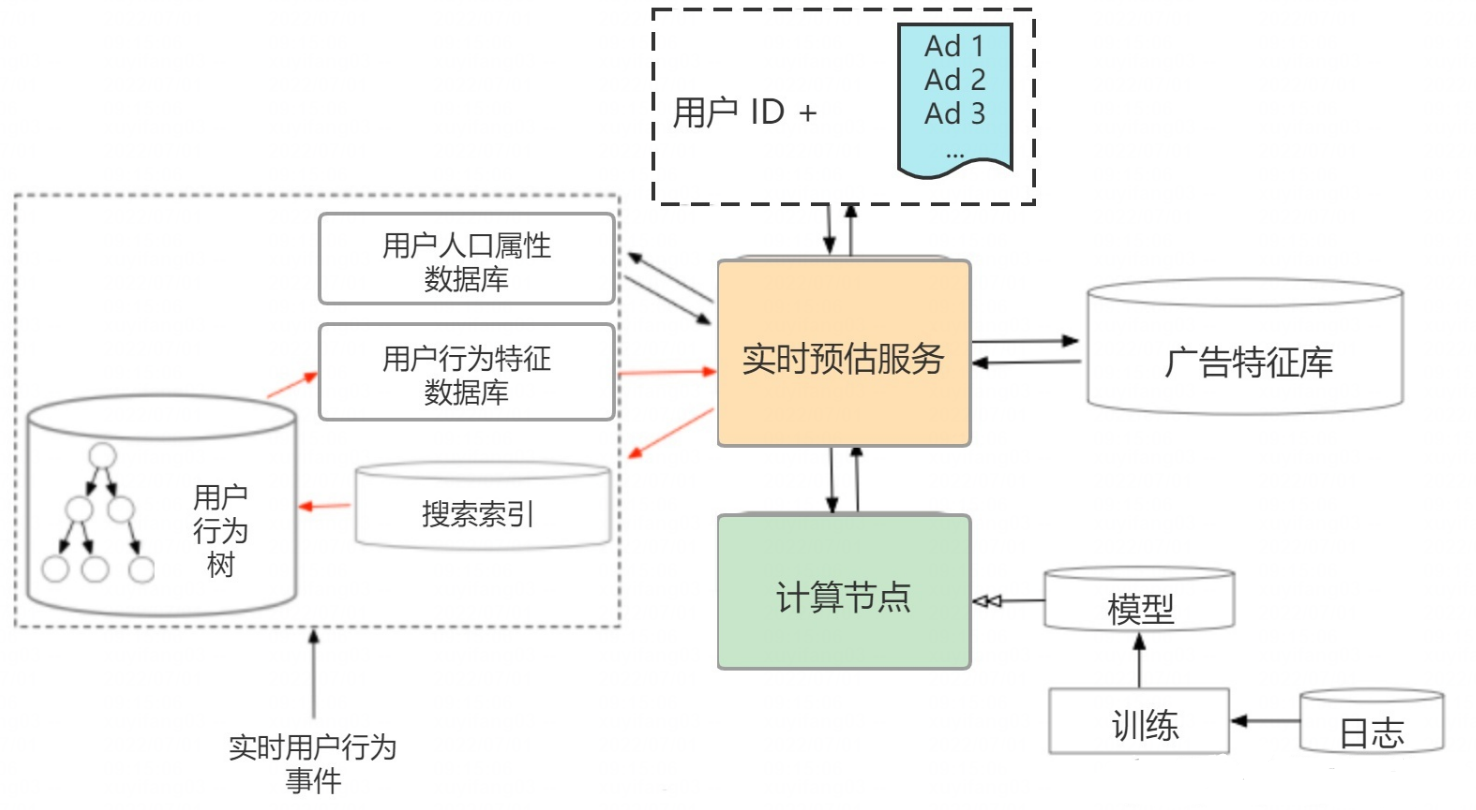
Hard Search 适用于线上服务,为了加快查找速度,SIM 构建了一个两级的索引来检索用户行为,取名为用户行为树 (UBT, User Behavior Tree) 。UBT 采用Key-Key-Value 数据结构来进行存储,第一级 key 是用户 ID,第二级 key 是物品 ID,value 为行为 ID。当 query (候选物品) 到来时,直接检索对应物品 ID 的行为序列即可。
实验
在工业数据中,将用户180天行为数据作为长期用户行为,14天作为短期用户行为。其中超过30%样本的序列长度超过10,000,最长用户行为长度为54,000,相比MIMN提升了54倍,对于阿里广告业务而言,相当于 180 天的广告行为。SIM离线实验使用的数据集统计:
| 数据集 | 用户规模 | Item数量 | 样本数 |
|---|---|---|---|
| 工业数据 | 2.9亿 | 6亿 | 122亿 |
SIM在工业数据集上的结果:
| 模型 | AUC | AUC提升 |
|---|---|---|
| DIEN | 0.6452 | 0.00% |
| MIMN | 0.6541 | +1.38% |
| SIM(hard) | 0.6604 | +2.36% |
| SIM(soft) | 0.6625 | +2.68% |
| SIM(hard,引入时间间隔(position embedding)) | 0.6624 | +2.67% |
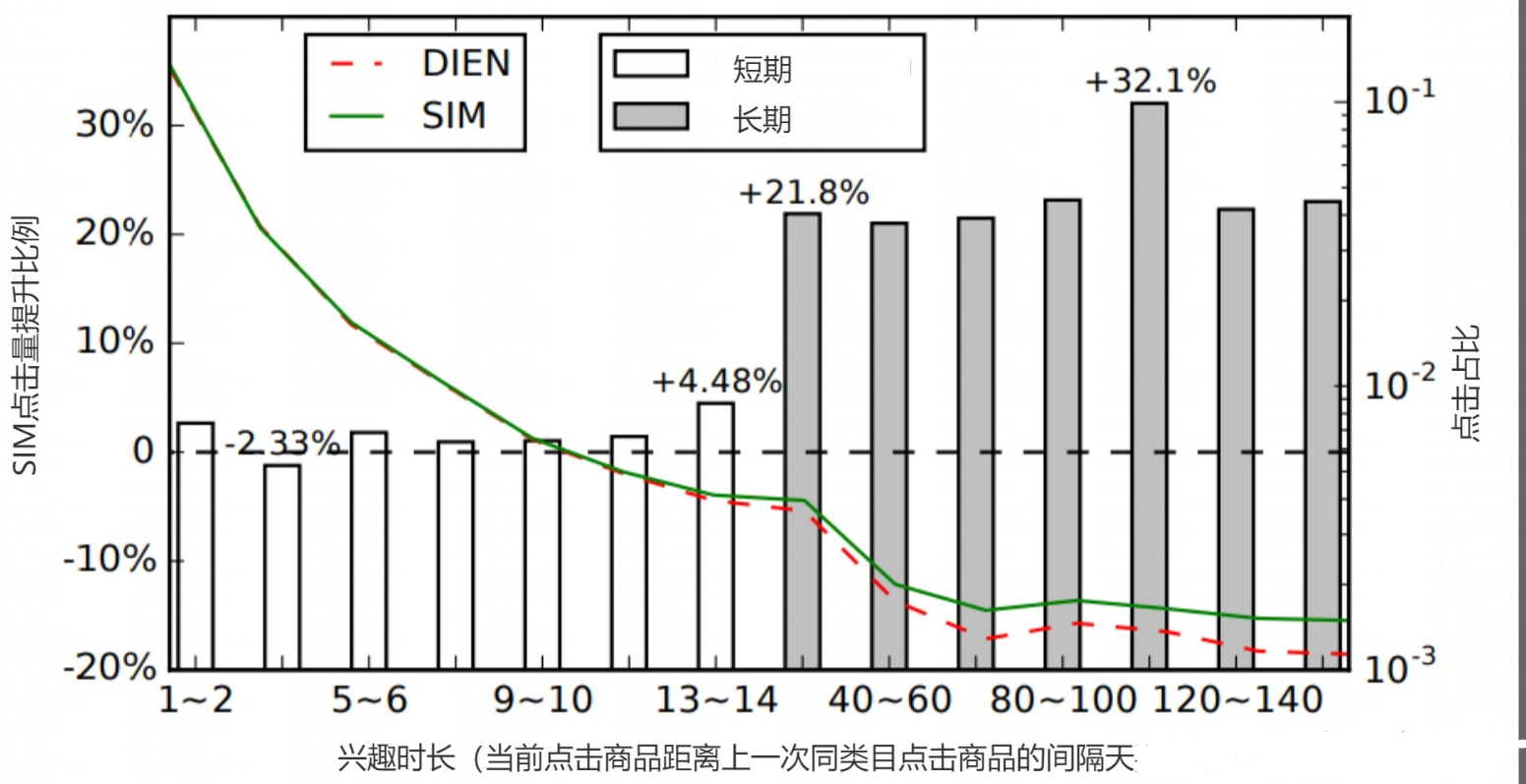
SIM 相比于 DIEN,在较长的兴趣时长点击数量有明显的提升(其中DIEN和SIM流量大小一样)。这说明SIM推荐系统的视野变得“开阔”起来,能够给用户推荐更长期的商品。同时在推荐长期兴趣相关的商品时,能够准确的对用户兴趣偏好进行精准的刻画,使得用户点击兴趣时长变长。
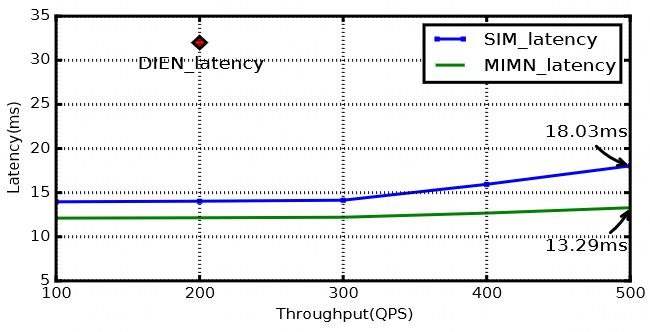
时延方面,SIM 因为要处理 1w+ 的序列信息,性能比 MIMN 要弱一些,但18ms的时延也基本满足实时性的要求。
可视化
Soft Search下不同 item 的相似度,可以看出同类别下的 item 更加相似。















 971
971











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









