







数据库瓶颈
不管是IO瓶颈还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载的活跃连接数的阈值。在业务service来看,就是可用数据库连接少甚至无连接可用,接下来就可以想象了(并发量、吞吐量、崩溃)。
IO瓶颈
-
第一种:磁盘读IO瓶颈,热点数据太多,数据库缓存放不下,每次查询会产生大量的IO,降低查询速度->分库和垂直分表
-
第二种:网络IO瓶颈,请求的数据太多,网络带宽不够 ->分库
CPU瓶颈
-
第一种:SQl问题:如SQL中包含join,group by, order by,非索引字段条件查询等,增加CPU运算的操作->SQL优化,建立合适的索引,在业务Service层进行业务计算。
-
第二种:单表数据量太大,查询时扫描的行太多,SQl效率低,增加CPU运算的操作。->水平分表。
水平分库
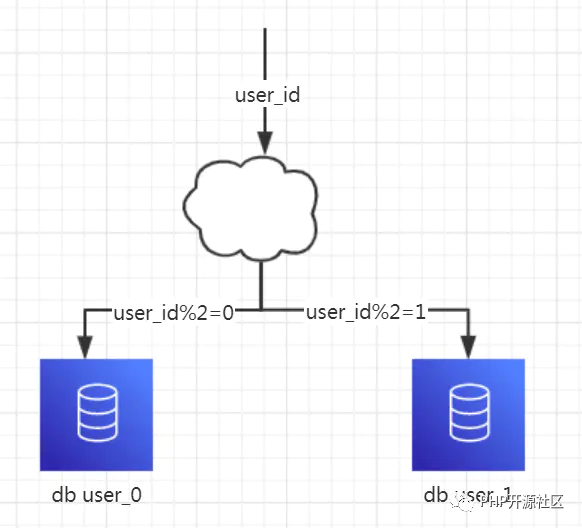
1、概念:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2、结果:
-
每个库的结构都一样
-
每个库中的数据不一样,没有交集
-
所有库的数据并集是全量数据
3、场景:系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库的情况下。
4、分析:库多了,io和cpu的压力自然可以成倍缓解
水平分表

1、概念:以字段为依据,按照一定策略(hash、range等),讲一个表中的数据拆分到多个表中。
2、结果:
-
每个表的结构都一样
-
每个表的数据不一样,没有交集,所有表的并集是全量数据。
3、场景:系统绝对并发量没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU负担,以至于成为瓶颈,可以考虑水平分表。
4、分析:单表的数据量少了,单次执行SQL执行效率高了,自然减轻了CPU的负担。
垂直分库
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









