







一、问题前提
熟悉flink过程中涉及到侧输出流应用方式,故在本地想运行一套测试逻辑将flink读取的流切分流两个,这里切分流的方式采用侧输出流实现。【侧输出流也大多可以用在窗口中或者join,当数据延迟或者connect或者join失败可以将该数据输入到侧输出流来进行下一步的逻辑处理。这里不进行展开描述】
【flink】1.13.2
【kafka】2.12-2.8.0
【gradle】7.1.1
【Idea】2021
二、代码
package org.apache.flink.training.exercises.ridecleansing;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Properties;
/**
* @ClassName SideOutPutTest
* @Description TODO 实现侧输出,选择一些指定数据到侧输出
* @Author yunqi
* @Date 2021/9/18 9:29 上午
* @Version 1.0
**/
public class SideOutPutTest {
static OutputTag<Obj_1> filterStream = new OutputTag<Obj_1>("filterStream");
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "group01");
DataStreamSource<String> kafkaStream = env.addSource(new FlinkKafkaConsumer<String>("sideout", new SimpleStringSchema(), properties));
SingleOutputStreamOperator<Obj_1> resStream = kafkaStream
.map(value->new Obj_1(value))
// .process(new SideOutProcess());//流会一分为二
.process(new ProcessFunction<Obj_1, Obj_1>() {
@Override
public void processElement(Obj_1 value, ProcessFunction<Obj_1, Obj_1>.Context ctx, Collector<Obj_1> out) throws Exception {
if(value.getValue().compareTo("9")<0){
ctx.output(filterStream,value);
}else{
out.collect(value);
}
}
});
kafkaStream.print("全部流数据");
resStream.print("high");//输出主流
resStream.getSideOutput(filterStream).print("low");//侧输出流需要获取输出
env.execute("sideoutTest");
}
public static class Obj_1{
private String value;
public Obj_1(String value) {
this.value = value;
}
public Obj_1() {
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "Obj_1{" +
"value='" + value + '\'' +
'}';
}
}
}
三、报错信息
Caused by: org.apache.flink.api.common.functions.InvalidTypesException: Could not determine TypeInformation for the OutputTag type. The most common reason is forgetting to make the OutputTag an anonymous inner class. It is also not possible to use generic type variables with OutputTags, such as ‘Tuple2<A, B>’.
四、解决方案
报错信息中其实已经指明了解决办法:The most common reason is forgetting to make the OutputTag an anonymous inner class。所以我们只要new OutputTag的时候采取下面这种方式即可解决。
static OutputTag<Obj_1> filterStream = new OutputTag<Obj_1>("filterStream"){};
仔细看哈:是生成对象的时候加了大括号,加括号后flink就会认为这个是匿名内部类。就满足了make the OutputTag an anonymous inner class。
再次运行,问题解决。
五、深入
5.1 思考
报错原因是在于flink无法识别当前OutputTag的类型,即使我们在泛型中指定了该对象的类型,但是flink还是无法识别?
5.2 探索报错信息
报错信息中说必须要给一个匿名内部类,也就是使用匿名内部类传入就可以识别到该对象类型了。
5.3 Debug
使用泛型传入参数后方法参数:
注意:clazz参数还是原类型
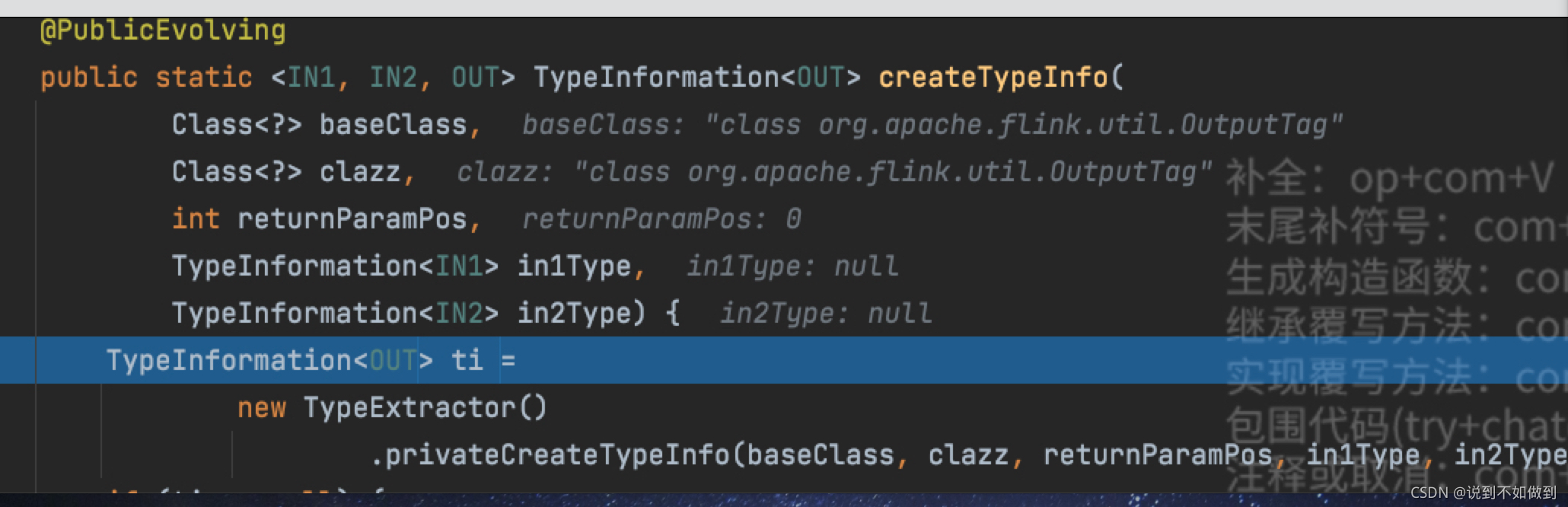
使用匿名内部类传入后方法参数:
注意:clazz参数是我们的匿名内部类。$代表是内部(嵌入)类
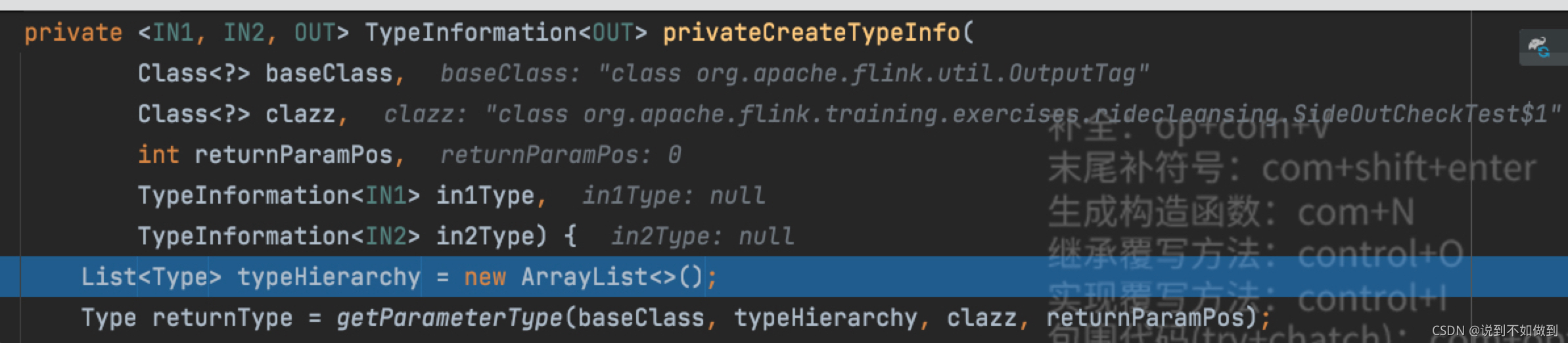
所以继续往下debug会发现,匿名内部类的类型最后会被返回,作为OutputTag的类型。
5.4 大胆假设
flink无法对指定泛型的OutputTag实例化,因为这里指定泛型,但是内部执行的时候会丢失这个泛型。丢失后类型就无法推测出来进而报错。
但是通过匿名内部类来实例化,参数类型不会丢失,可以成功返回该类型生成OutputTag对象。
5.5 小心论证
很惭愧,目前还没有这么精通flink,等慢慢熟悉flink运行机制后,再来论证~~
当然如果有大神可以解释下的话,不胜感激!!!














 5411
5411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









