






前言
在推荐系统中冷启动一直是一个研究热点,所幸的是同一个用户在其他场景上可能有对应的交互行为,于是我们就可以利用这些其他场景交互行为数据来挖掘当前场景的可能行为,进而来解决冷启动问题。
该研究其实是一个很大的方向叫做Cross-domain Recommendation (CDR) ,其他场景的数据通常叫做源域(source domain),而真真要做的场景叫做目标域(target domain),该方向已经有很多代表性的工作,感兴趣的同学可以搜索相应的关键词去检索相关的工作。
今天要介绍的一篇就是其中之一,还开源了代码,一起来看下吧~,其中的meta network设计有点难理解,这里也贴一些代码实际看下到底是怎么实现的。
后面还会陆陆续续的介绍一些相关工作~
论文链接:https://arxiv.org/pdf/2110.11154.pdf
代码链接:https://github.com/easezyc/WSDM2022-PTUPCDR
问题定义
在开始介绍之前,这里先规范定义一下各个参数的含义:
每一个domain都有一个用户集合 和item集合 以及一个交互矩阵 ,其中 代表用户 和 的交互行为。
其中 代表源域, 代表目标域。在源域和目标域同时有行为的用户为 。
当然了不同域之间的item是没有交集的即 和 没有交集。
其中 分别代表用户 和item 在 这个domain的向量,向量的维度是k。
对于某一个用户 其在源域的行为序列为 ,其中 代表用户在源域的时间 交互的item。
好了,明确了这些参数的具体含义,我们来看本篇paper具体的做法。
方法
-
总体框架
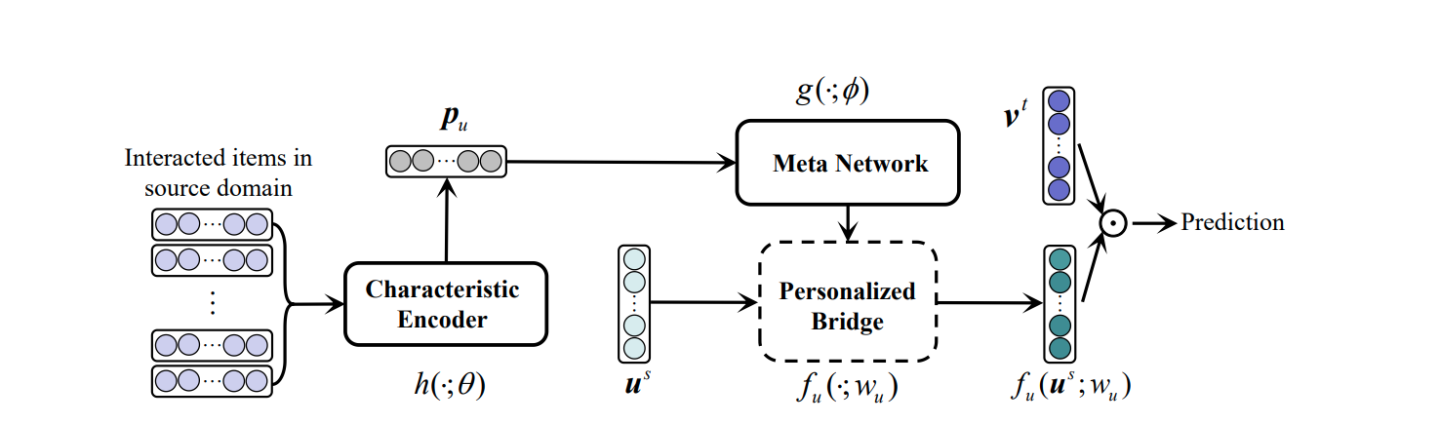
从上面的框架看,大的方面这里主要有三个模块:characteristic encoder、meta network、personalized bridge。
主要流程是先把用户源域的行为编码(characteristic encoder),然后经过一个meta network网络,进而将其和用户在源域的用户embedding进行融合(personalized bridge)得到目标域的用户embedding,然后和目标域的用户行为进行loss计算,进而更新整个网络。 下面我们详细看下各个模块的细节~
-
characteristic encoder
这里实际实现用到的就是attention机制,更具体的说就是将用户在源域的行为item通过attention来聚合得到一个用户在源域的兴趣表征,也就是论文中说的用户的transferable characteristic embedding。 具体的公式如下所示:

可以看到公式里的 就是attention中的score,其具体实现就很简单了,相信大家都知道:
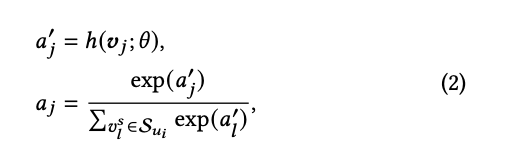
具体的 这里是一个两层前馈网络。最终得到的 就是框图中用户的characteristic encoder结果。
-
meta network和personalized bridge
这里比较有意思,也是论文的看点之一,为了讲解这里,我们先来看一下这里设计的背景:

我们在做跨领域个性化迁移这件事的时候本质上其实是在做用户在源域行为和目标域行为之间的关系映射,而这个映射函数其实对于不同的用户是不一样的,但是之前所有用户都是学同一个映射函数,而实际上这个关系映射应该是被个性化的,于是乎本篇paper使用了meta network。如上图所示,图(a) 是之前一些CDR模型的方法,而图(b)是本文提出的方法。
那什么是meta network网络呢?如下:
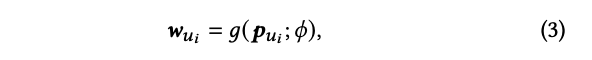
这里的 就是所谓的meta network,可以看到它的网络参数是 ,输入是上述产出的 ,最后得到的 其实就是一个向量。
重点来了!!! 所谓meta network最大的不同之处在于,在用 的时候我们不是把它作为下一个网络的输入,而是作为网络参数,如果作为网络的输入其实就是common bridge。更泛化一点来说就是:

说到这里 也仅仅是一个网络并且有参数 那它的输入是什么呢?从上面可以看到就是 即用户在源域的embedding。
这里我们再捋捋哈,首先说在源域这一端来看的话,会给每一个用户和item默认申请一个look up 的embedding,然后通过用户交互的各个item的look up 的embedding来attention encoder得到 其经过一个meta network得到个性化的网络参数,其实就是个向量,然后 把它当作自己的网络参数(而不是输入),用户的look up 的embedding当作输入最终得到用户在源域的兴趣embedding即 。
到目前为止我们得到了用户在源域的兴趣embedding,而且是有个性化的映射在里面,那最后我们总是要训练模型更新网络的对吧,那必然就涉及到loss是什么?下面我们看下loss是什么?或者说网络学习的目标到底是什么?
这里作者首先提到了mapping-oriented optimization,它的目标是:
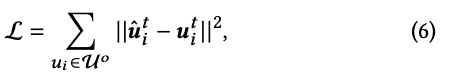
其中的 是用户在目标域的用户兴趣embedding,通过不断优化减少用户在源域得到的embedding和在目标域的用户兴趣embedding来优化,但是用户在目标域的行为往往是稀疏的,所以我们往往拿不到真真意义的 ,所以这样学的话往往导致网络是一个有偏向性甚至是负向的。
为此作者提出了task-oriented optimization,其直接预测用户在目标域的行为 即
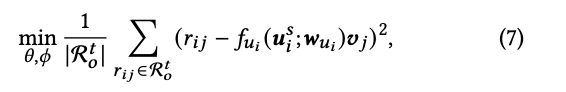
这样做就避免了上述的问题,同时还有一个好处就是增加了训练样本,假设源域和目标域有交互的用户数是N,每一个用户在目标域的交互数量是M,那么mapping-oriented optimization的训练样本数量就是N,而task-oriented optimization就是M*N
总体算法流程

PTUPCDR(本文提出的框架)的整体训练流程如上,一共可以看成是四个大的stage阶段。
-
Pre-training stage
在各种domain端预训练, loss就是
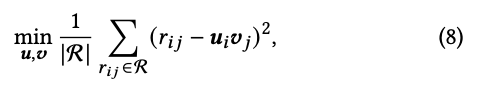
训练完后就可以得到一个预训练好的
-
Meta stage
就是整个上面介绍的框架,利用meta network和公式(7)的loss来进行Cross-domain学习
-
Initialization stage
当来了一个新的用户的时候(这里所说的新用户是说在目标域是新用户,但是在源域得先有一些交互行为,毕竟这样我们才可以映射嘛),我们通过上述公式(5)来映射得到其在目标域的embedding。
-
Test stage
所以对于冷启动用户我们就直接用Initialization stage映射得到的embedding,对于一些热用户,就可以再在新的交互行为上fine-tune一把。
代码解析
相信看到这里大家对整个设计框架比较了解了,但是是不是对meta network网络那里还是有点疑惑呢?不满大家说笔者当时看了后,也感觉好像还是没有完全理解透,好在作者开源了代码,下面我们一起来看下其具体是怎么实现的,说白了就是去看看model的部分。
大家通过看run.py后就会发现model部分就是看models.py下的DNNBasedModel即可,该网络下对应多个stage,对应meta network这里的就是train_meta
首先我们再明确下论文里面说的流程:
首先是Characteristic Encoder:也就是得到 ,然后进入meta network 网路得到 ,以它为网络参数, 为网络输入,产生得到 也就是Personalized Bridge,最后拿它去做task-oriented optimization,更新整个网络。
好了大家看代码,其实核心代码就是179、180行代码,其中179行得到的mapping就是 ,180行得到的uid_emb就是 至于182行的output就是论文公式(7)中的: 换句话说就是模型预测
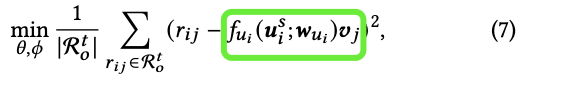
好了我们重新回到179和180行,首先看179行的MetaNet
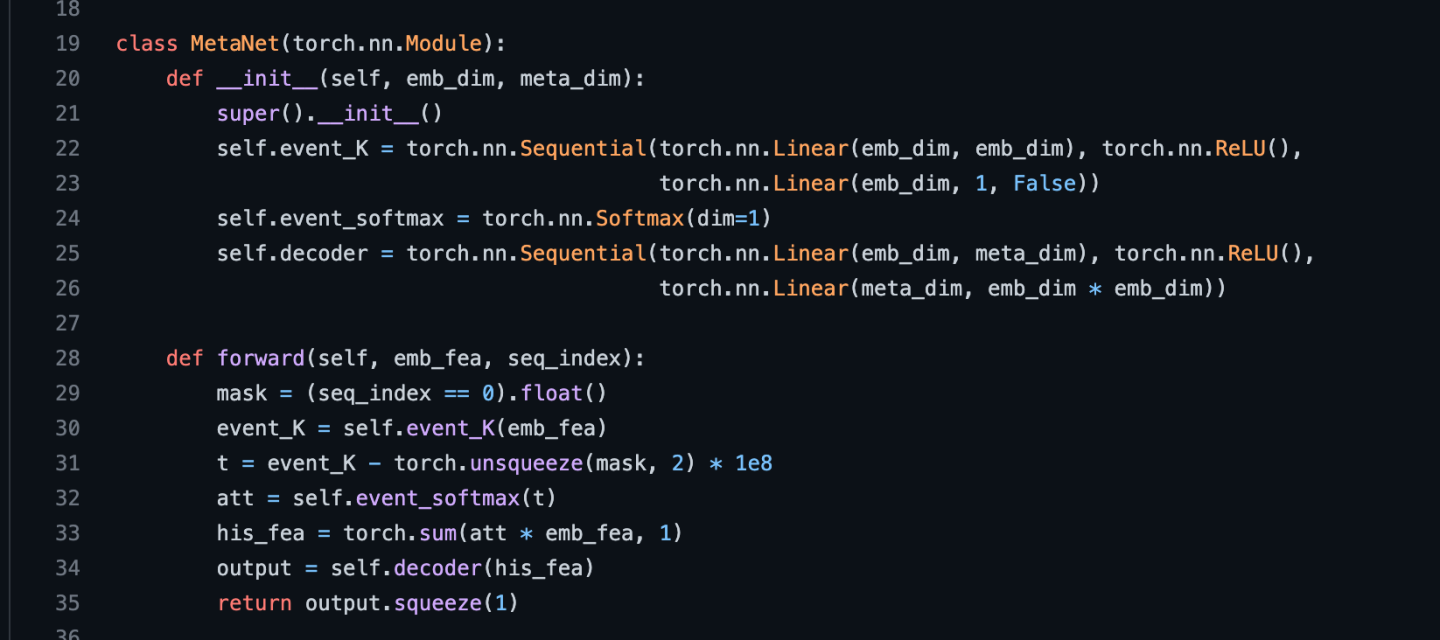
其中的29-30行就是Characteristic Encoder也就是论文中的公式(1),从这里也可以看到就是个attention,具体的就是论文中公式的(2),没什么好说的;34行就是一个两层的前馈网络也就是论文中的公式(3)。
好了到目前为止我们拿到了179行的mapping也就是 ,但是这里还是没有体现出怎么把它当做参数而不是输入去用,其实体系这一步的是180行,它是一个矩阵相乘,从这里可以看到一个输入是 另外一个是uid_emb_src也就是 ,这就是论文中公司(5),现在我们来理解下:一个线性网络层其实就是y=wx,其实就是个矩阵相乘,w就是 ,x就是 ;所以180行的矩阵相乘就是论文中说的公式(4)即a linear layer,它这里直接把mapping当作了linear layer的网络权重!!!
所以谜底解开了,困惑我们的其实就是一行代码即180行的torch.bmm。
更多代码细节如果大家想了解,可以去看源代码。
试验结果
这里我们重点看下这个meta network的消融试验:
本文应用了meta network网络的框架作者其名为PTUPCDR,而去掉meta network网络的设计(其他的一样)命名为EMCDR,作者首先在目标域训练用户的embedding,依次作为ground truths,然后将源域转化来的embeddings作为预测迁移的embedding,使用t-SNE降维可视化如下:
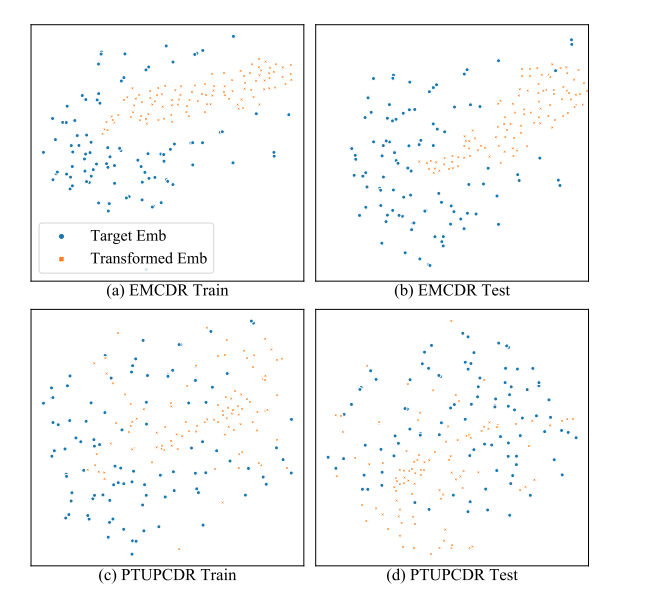
从图(a)(b)可以看到不论是在train还是在test数据集上不加meta network网络的时候,Transformed Emb的embedding就是很集中,而ground truths其实是很分散的,这可能就是因为没有使用meta network网络做到个性化,所有用户的Transformed都是共用一个映射函数。
而图(c)(d)是本文提出的方法,明显分散了很多,也就是更个性化啦,不想EMCDR那么集中在一起,而且更加拟合ground truths。
同时作者这里还给了一些case来分析attention的设计重要性。
更多试验结果大家感兴趣可以去看原论文
总结
(1) 本文的一个大的inference逻辑就是所有用户都会有一个从源域迁移的用户embedding,然后如果用户还在目标域有丰富的行为就可以进一步以迁移的用户embedding为热启fine-tune一把,如果在目标域没有丰富的行为也就是冷启动用户,就直接用从源域迁移的用户embedding作为使用就可以啦~
(2) 值得借鉴学习的就是meta network的设计以及task-oriented optimization loss的设计出发点。
(3) Pre-training stage的重要性!!!
这里大家可以看到没有使用用户和item的side information(比如用户的性别、年龄;item的标题,种类等等信息),只是把他们当作一个id通过look up 来优化得到embedding,这些不仅在训练的时候丢失了这些重要的side information,而且还存在一个问题就是当一个新的item来的时候怎么办?如果我们加了side information,就可以一定程度上以side information来initialize。 同时这里就涉及到另外一个从源头设计的问题,我们到底要不要把user和item本身当作一个id,进而优化一个id embedding,这样的弊端就是当来了新的user和item的时候,就没法拿到完整的id embedding,就比如paper的Initialization stage部分,大家可以想象一下,那里的 输入是怎么得到的?其既然在目标域没有交互,就自然拿不到id embedding,其实它是通过Pre-training stage过程中在源域预训练得到的id embedding来作为这里的热启动的 如果我们去掉id embedding,比如item就用side information来表征聚合出一个embeding,然后用户也是同样的道理,更甚至说通过构graph,用户的embedding是可以通过聚合旁边的item embedding来表征自己的,那么这样的话,即使是新来的,side information肯定是能拿到的,那么就自然可以拿到embedding,对齐训练的时候的embedding。
关注
欢迎关注,下期再见啦~
本文由 mdnice 多平台发布


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









