






前言
当下大模型的能力已经很强了,但是将来我们想要的是能力更强的大模型,其最好能够处理各种复杂问题也即强对齐模型。
之前大模型训练的监督信号主要来源于人类反馈,但是如果想要训练一个强对齐模型必然就需要一个对应的强监督信号,这对于人类来说本身就很难,比如之前openai 的RLHF主要聚焦对齐的是某一方面能力(安全方面),这个时候人类还比较好判断case(是否安全)进而反馈,但是当面对各种复杂问题的时候,人类也很难反馈,可能需要各个领域的专家去反馈,但是这显然是不现实的。
前段时间openai也意识到这个问题了,其还专门成立了一个超级对齐团队来攻克这个方向,并发表了他们第一阶段的工作,其主要通过模拟一个弱监督强的实践来探索实现强对齐模型在理论上是否可行?以及初步提出了一些可能实现的方向,笔者也对其进行了解读,感兴趣的小伙伴可以穿梭:
穿梭门:《openai最新探索:超级对齐是否可行?》:https://zhuanlan.zhihu.com/p/673806165
今天要给大家带来的是一篇meta最新的paper,其也是尝试解决这个难题,具体的是让模型通过自监督的方式完成自我更新。一起来学习下吧~
论文:《Self-Rewarding Language Models》
论文链接: https://arxiv.org/pdf/2401.10020.pdf
背景
正如前言所说,之前的训练方法主要是RLHF,其利用人类标注的偏好数据训练一个reward打分model,然后使用这个reward model通过强化学习PPO来更新LLM,其中在PPO训练阶段,reward model是不更新的。
最近有一些工作则是绕过了训练一个reward model,而是直接用标注好的偏好数据去训练LLM即DPO方法。
可以看到上述两种方法都严重依赖标注好的偏好数据,倘若面对复杂问题,人类不能很高效的标注偏好数据的时候,那么就相当于没有数据了,那不论是PPO也好DPO也罢也就不能训练了。同时RLHF在PPO阶段reward model是不参与更新的,被冻结住了。
基于此,作者提出了训练一个自我更新的reward model(而不是冻结的模型),即reward model在训练LLM对齐过程中也会同步持续更新,具体的做法是不再将reward model和LLM分离成不同的模型,而是看成一个整体,作者将这一方法命名为Self-Rewarding Language Models。
方法
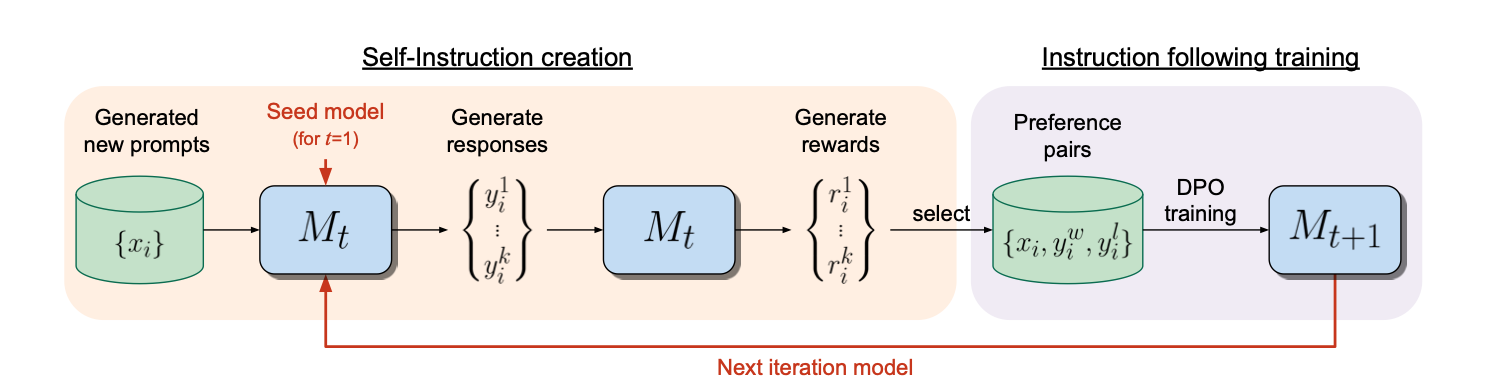
- Initialization
首先是需要初始化,即使用指令微调数据训练一个简单的sft模型,作者将这里的指令微调数据命名为IFT (Instruction Fine-Tuning),同时作者的idea是让LLM自己可以对response打分(即作为Reward model),具体是5分值;具体能打分的这个能力如果有专门的数据能先训练一下子最好,没有的话也无所谓,因为经过用IFT数据微调后,模型已经初步具备了打分能力,后续自我更新的时候,这个能力会自我提高;当然如果有对应的数据更好啦,作者将这个数据命名为EFT。
经过IFT和EFT数据微调也即SFT后,我们后续就会基于这个初版模型进行自我更新啦~
- Self-Instruction Creation
这个模块具体包含三个步骤,首先是Generate a new prompt即产生新的prompt,具体的是通过few-shot去生成新的prompt;然后每个prompt通过LLM模型的拒绝采样得到N个候选resposne;最后使用同一个LLM对这些response进行打分(reward model的功能),其中打分这一步具体的实施是通过prompt engernering实现的,作者也给出了模版(LLM-as-a-Judge prompt):

- Instruction Following Training
经过上面的步骤后,我们就相当于有了偏好数据,然后就可以更新模型了,具体更新的机制也有两种,一直是基于偏好数据进行DPO,另一种只使用偏好得分高的数据直接进行SFT,作者发现前者效果更好。
为什么前者更好呢?其实也好理解,说的简单点就是前者不仅仅利用了正反馈信号,而且利用负监督信号,这对于LLM-as-a-Judge自身的更新是有帮助的,而整个算法过程又是严重依赖LLM-as-a-Judge的,所以前者理论上就是会更好一些。
在进行完一轮的更新后,就可以进行第二轮的更新了,整个过程完全自动化。
- Overall Self-Alignment Algorithm
总结一下整个过程就是,相信大家一目了然,不用笔者再累述啦。

效果怎么样呢?

这里的SFT Baseline是只使用IFT进行微调的模型,可以看到随着迭代的轮数提高,效果在不断变好。
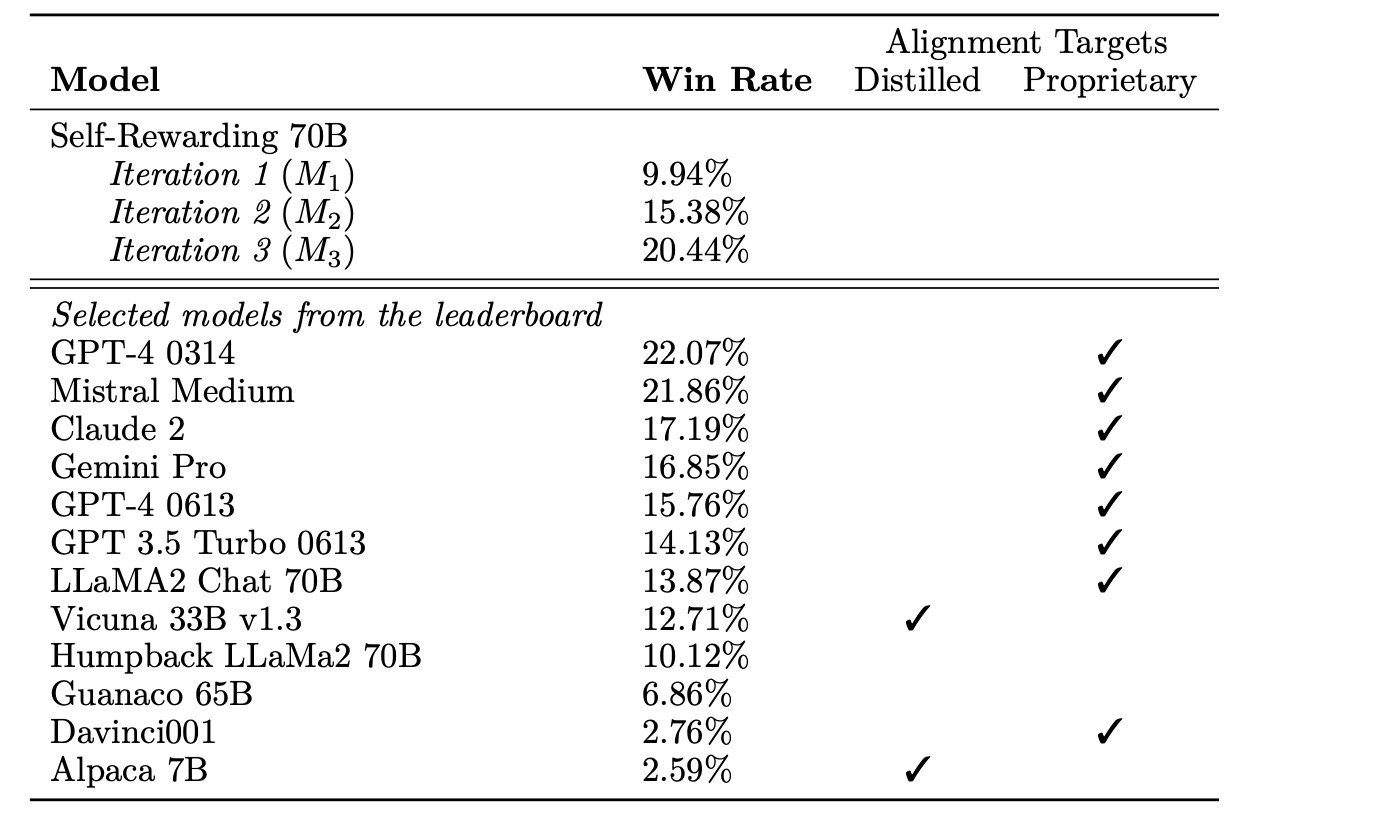
同时作者也和业界的模型做了一个整体的对比:
同时作者也观察了LLM-as-a-Judge的能力在随着轮数增加而提高
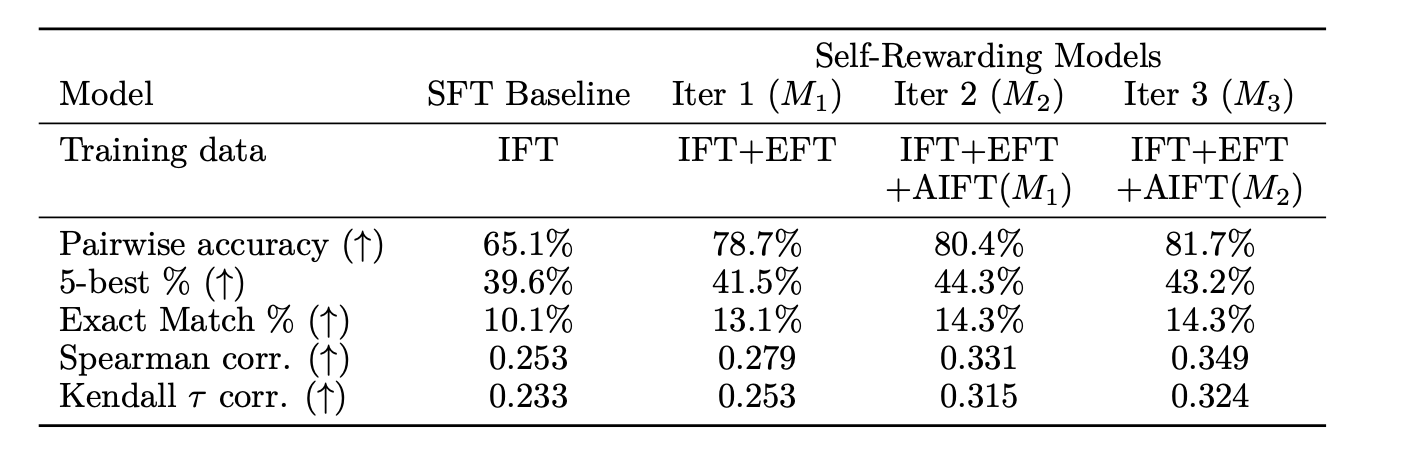
不过实验这里是不是应该再加一个对比实验:和传统的RLHF以及DPO方法相比,带来的提升有多少?这样就更好啦。
总结
作者提出了一个自我更新的流程,大的方向选择还是不错的即自监督,其实其中每个子流程我们都可以进一步优化或者探索,比如
(1)Generate a new prompt部分我们可以做的更精细化一点比如使用进化学习进行生成更有难度的prompt。
(2)在LLM-as-a-Judge prompt部分可以针对
不同query进行不同维度的打分设计。
(3)我们可以看到整个过程其实就是依靠自己判断数据质量,然后自己又完全信赖这个结果去更新自己,相当于自己给自己打分,好处就是自动化更新,但是总感觉不踏实,如果能结合一些第三方以合作的方式进行评估更新或许也是一个不错的选择。
(4)是不是可以先进行传统的RLHF或者DPO,再进行自我迭代,换句话说我们可以先尽力使用各种办法达到目前最好的模型性能状态,然后自己实在没招了且还想进一步提高模型性能,这个时候就可以试试本篇的自我更新
(5)等等…
感兴趣的小伙伴可以follow一下这个方向
关注
欢迎关注,下期再见啦~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









