






前言
现在的大模型能够创作一些故事、小说等等,但是大多数时候创作出来的剧情都是泛泛而谈,并没人给读者很爽的感觉。近期已经有一些工作开始在该方面进行发力,即让大模型做内容消费,如果大模型能够源源不断的创作出好的剧情来供读者消费,那是非常不错的赛道。
本次笔者就介绍两篇最新的paper供大家参考,他们一个共同的思路都是去利用挖掘好已有的优秀作品,甚至请一些专业编剧合作完成。
论文链接:
《Ex3》:https://arxiv.org/pdf/2408.08506
《SKYSCRIPT-100M》:https://arxiv.org/pdf/2408.09333
其中第二篇其实更强调镜头、关键信息的创作(因为其聚焦的是短视频创作)
Ex3
该篇主要就是聚集如何创作一篇爽点密集、逻辑一致性长篇小说。看完整个paper后,笔者感觉其整个思路就是把map-reduce理念应用到极致即先分为处理然后聚合处理最终达到写长篇小说。
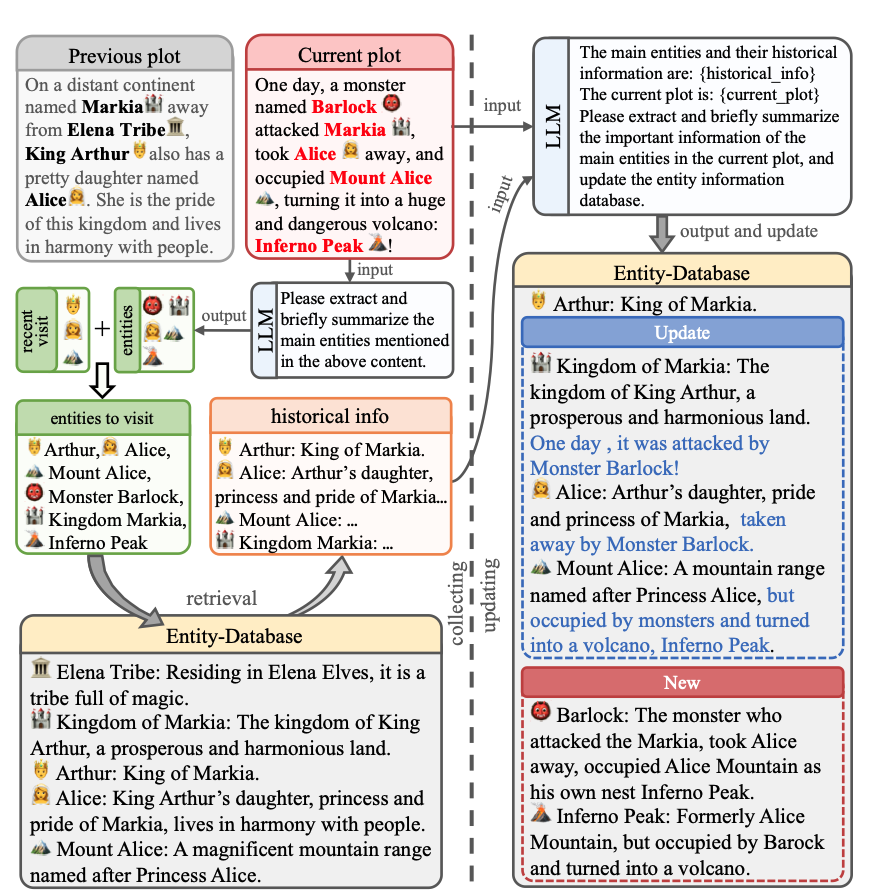
其整个框架一共分为三块如下,其中Extract、Excelsior是在制作训练样本进行训练;Expand是在inference推理阶段做了一些事情。下面我们来一个个模块看。
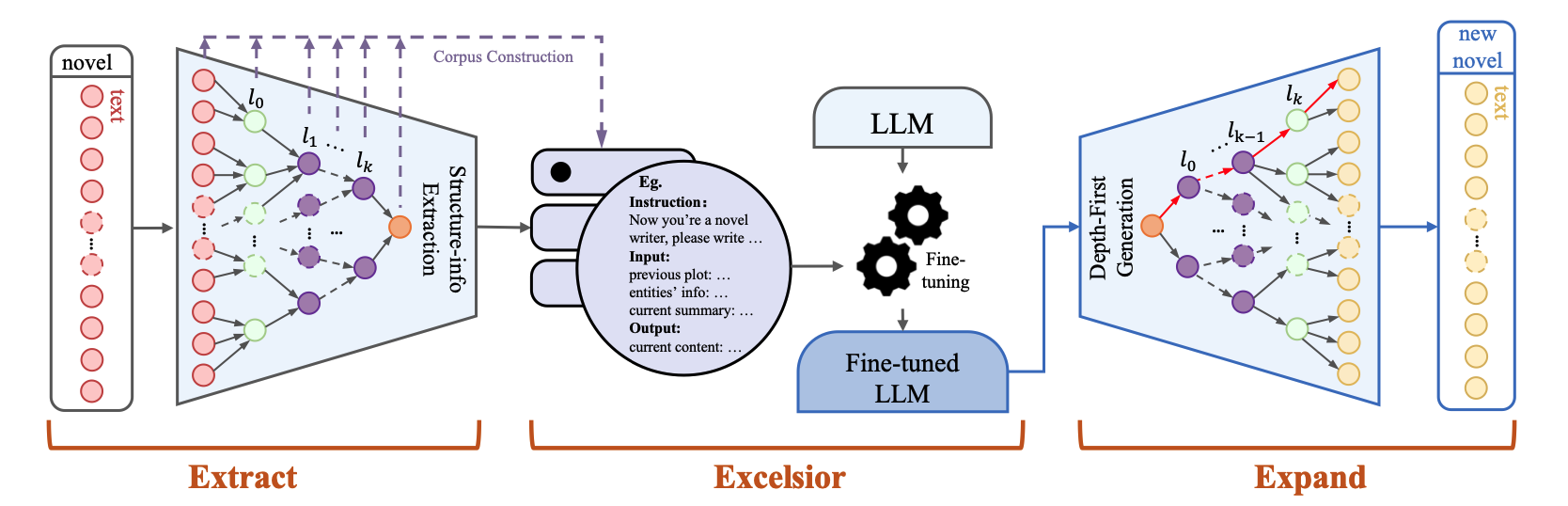
- Extract
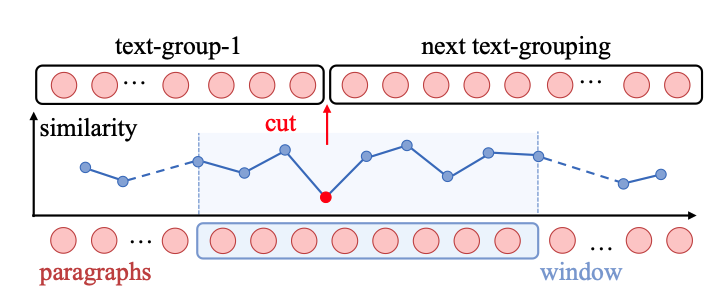
如上图所示,以小说每一段为一个最小单位然后进行分组,但是分组的逻辑是基于语义的,而不是按照字数。具体来说就是会计算所有相邻段落之间的语义相似度,当某两个段落之间突然出现较低相似度,那么就以此进行分割分组。
同时小说基本天然都会有目录结构,这些信息也是一个粗粒度的分割,于是我们就可以在每一章节下先进行分组,然后各个组进行聚合就可以得到当前这一章节的摘要
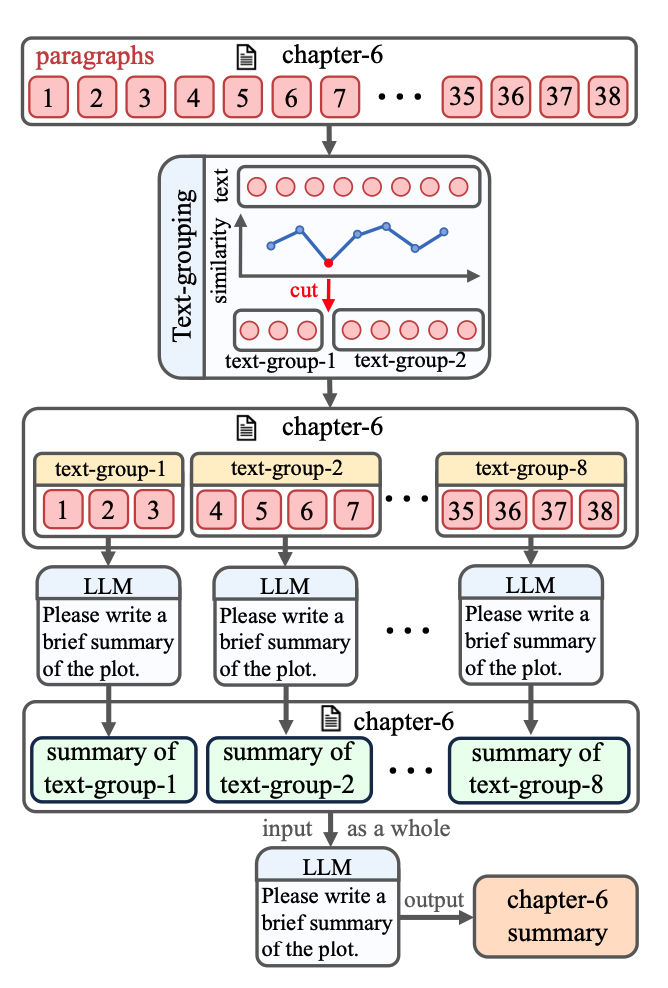
可以看到上图展示了一个章节6的摘要聚合过程。
同理有了各个章节的摘要,那么我们就可以再向上聚合出更高层次的大纲直到得到整个小说的一个摘要。
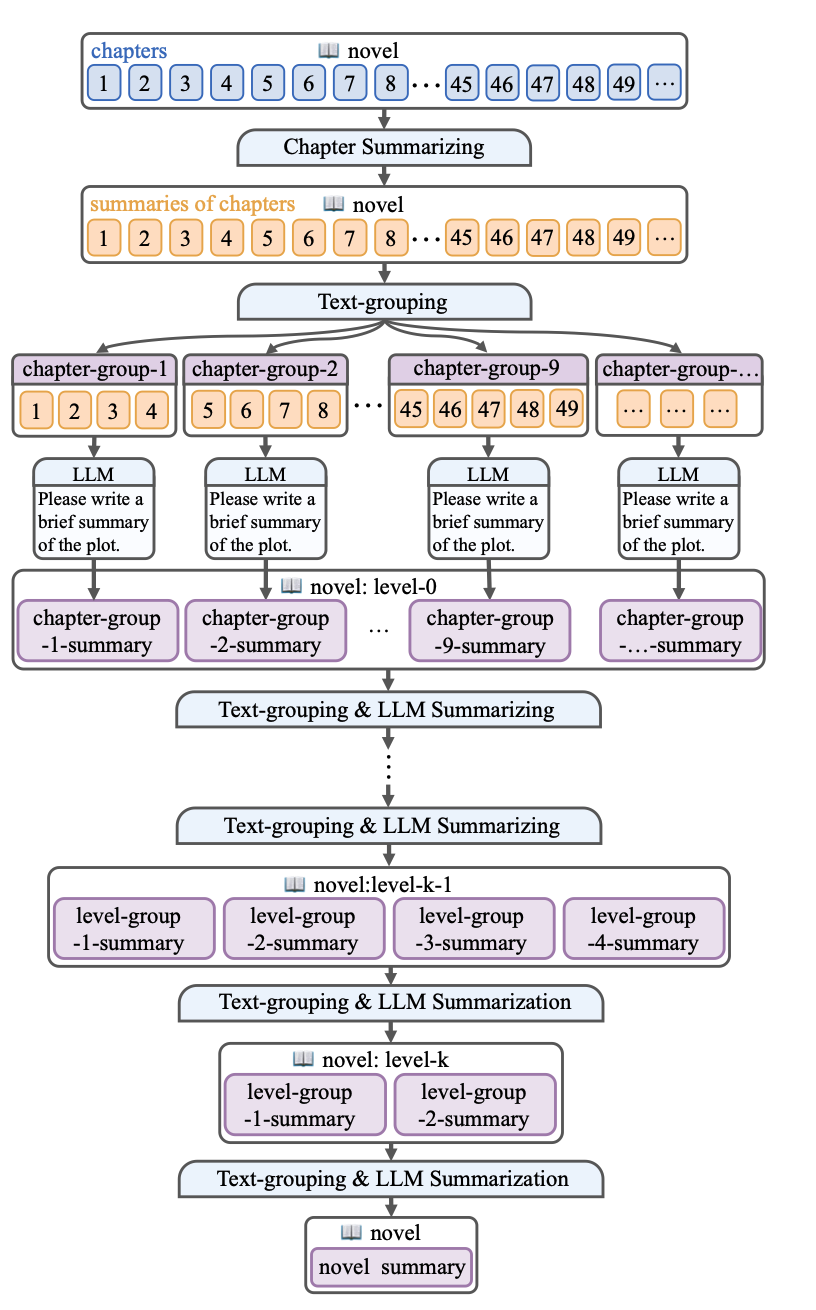
可以看到作者整个过程是从低到高、从下到上不断分块总结处理,然后向上聚合。
插曲:总结摘要的时候为了保证关键信息的存在以及整个故事的完整,作者特意还做了一个实体抽取,保住关键人物等等。具体可以看Entity Extraction一节。
- Excelsior
经过上一步我们已经抽取得到了各个结构化的数据,这一步就是要组合成真真的训练样本来训练模型
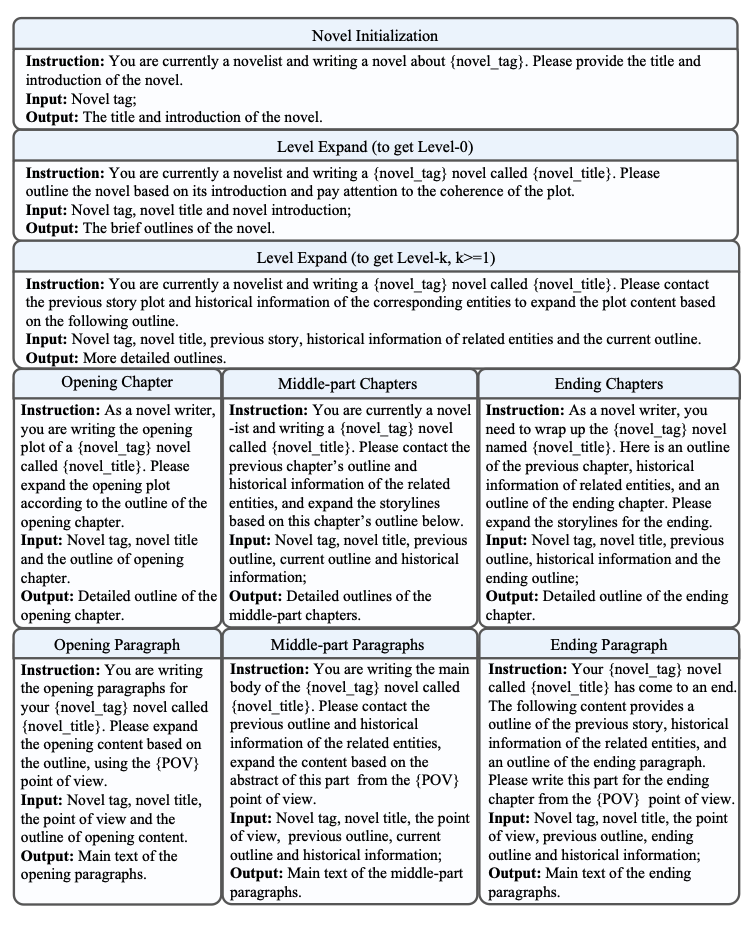
可以看到其实就是把上述各个聚合过程都进行了prompt反向化组成训练样本,进行训练,确保了模型能够在各个粒度(章节等等)进行创作。
- Expanding
用上面数据训练后的模型具备各种粒度的创作能力,那么最后该如何创作一部完整的长篇小说呢?小说再次按照从高到低的思路进行创作,比如先创作章节,再创作细节,且会利用前面的剧情作为铺垫。
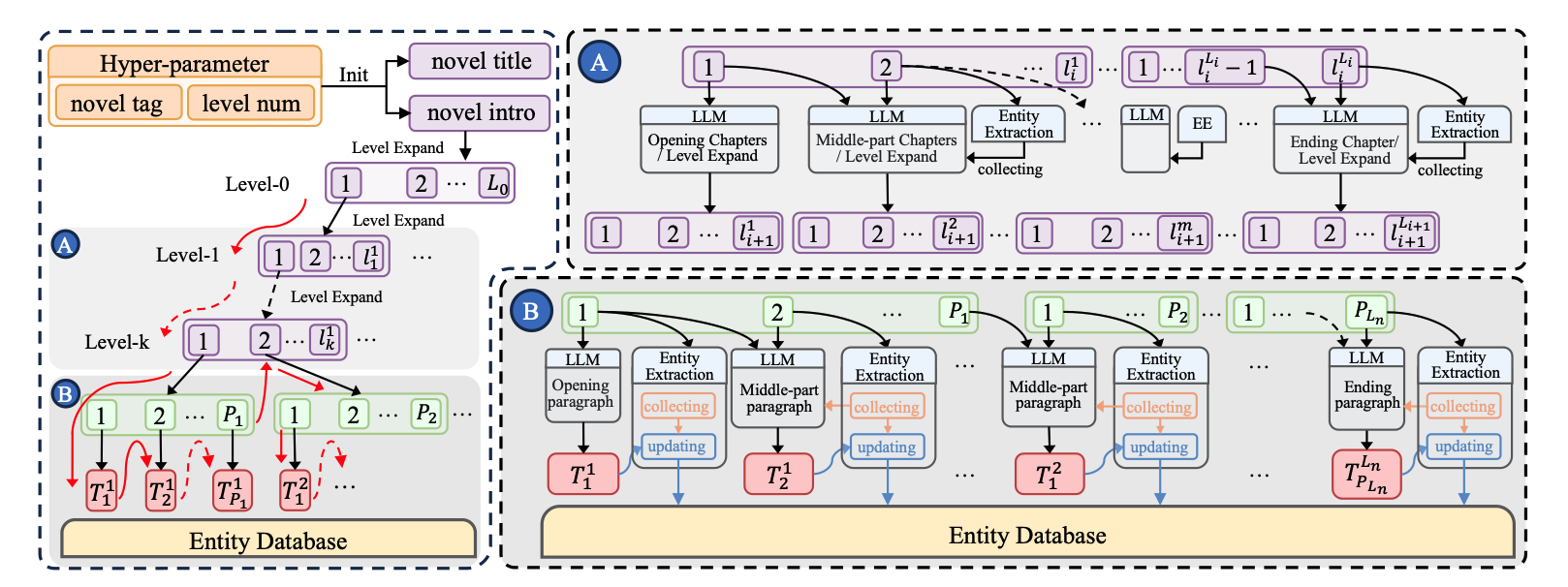
关于更多的一些细节和case,大家感兴趣可以去看附录。
- 总结
可以看到作者在训练和推理阶段都是用map-reduce的思想,通过对小说进行解刨然后进行训练,再反向创作。
SKYSCRIPT-100M
该工作其实是聚焦做短视频,而做短视频底层需要的也是一个好的剧本甚至要细到镜头描写。所以一个好的剧本是一个短视频能否火的关键,为此作者挖掘生成了一个SKYSCRIPT-100M数据集,专门聚焦剧本创作。不过目前数据集还没开源,可以期待一波。
github: https://github.com/vaew/SkyScript-100M
- 关键信息预提取
由于其是想从视频这个源提取脚本,那第一步肯定是要想办法将视频转化为文本,为了减少人力,作者这里使用多模态大模型先做了一个预提取。这里对比很多多模态大模型,最终选择了InternVL2-Llama3-76B。作者也给出了提取prompt,输出的格式是json。
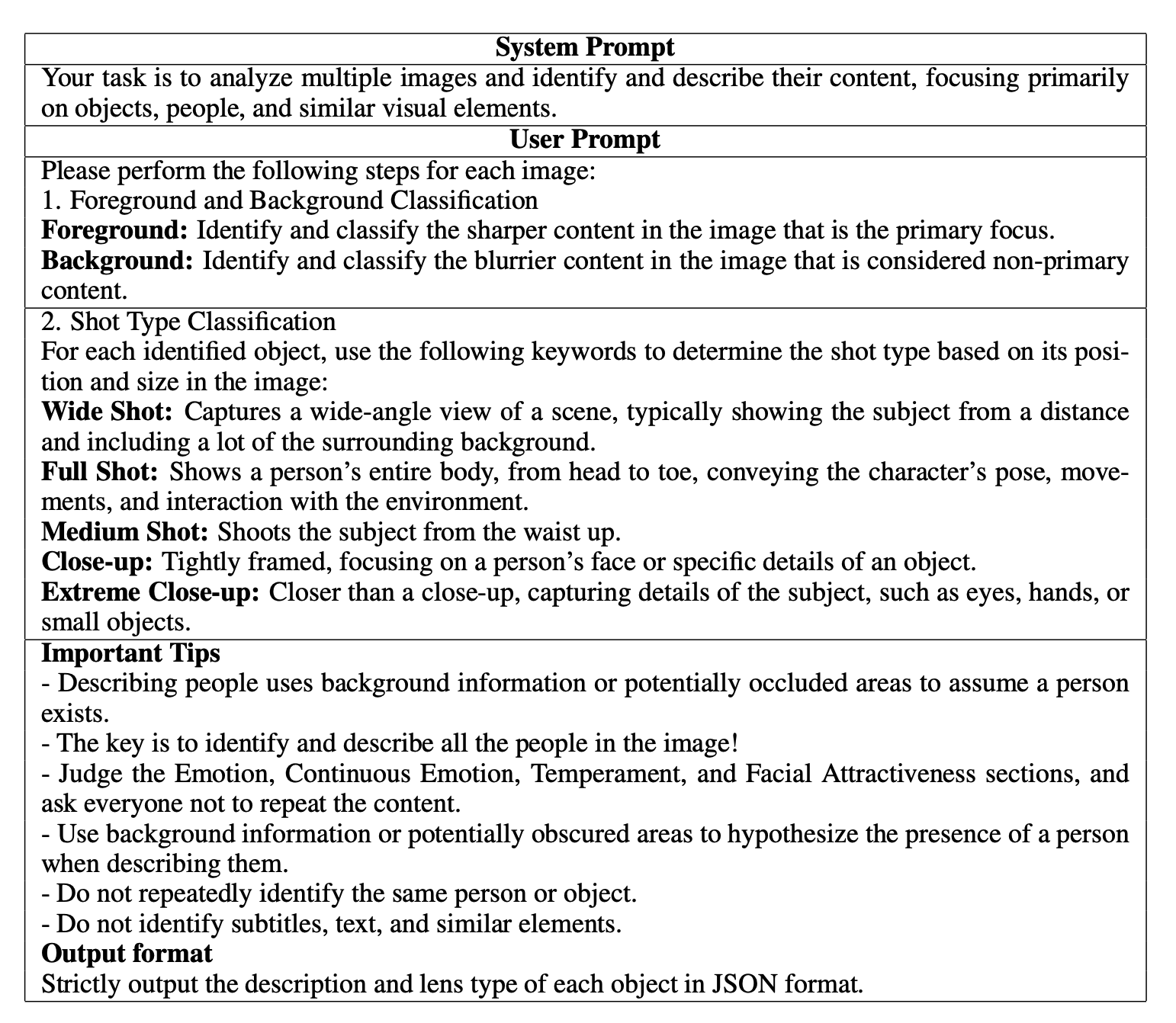
并给出了一些抽取的case
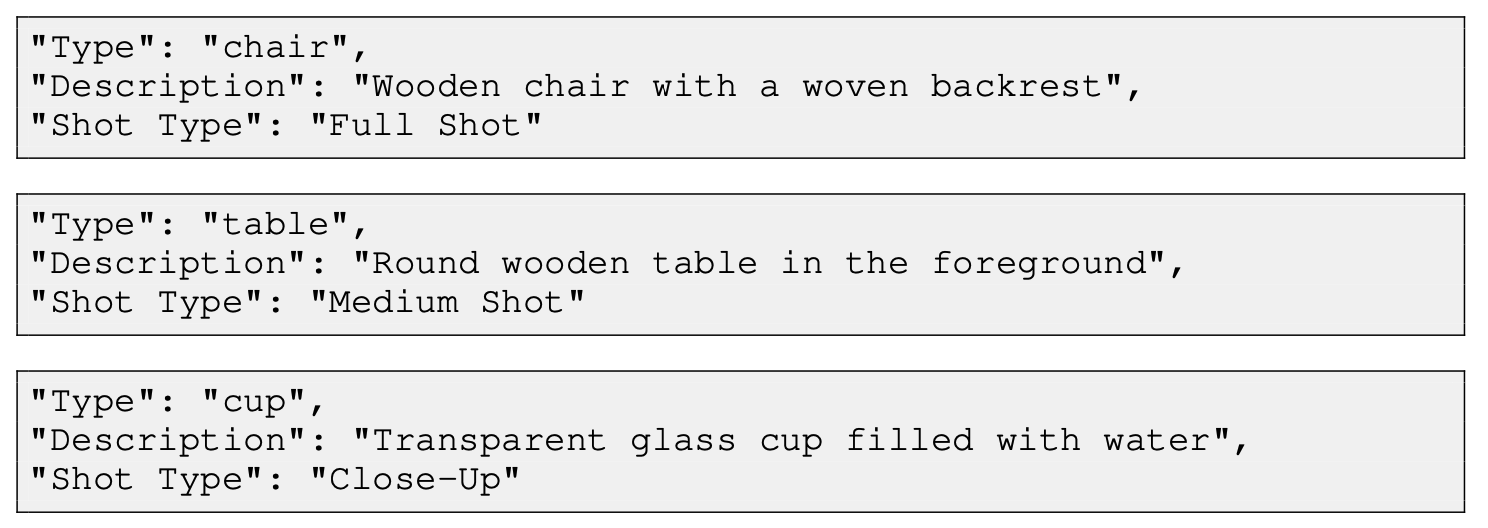

需要注意的是作者专门做了“Continuous Emotion”的抽取即对于关键人物的情绪等变化。
- 关键信息清理和像素化
经过上面抽取的信息可能还是存在格式等方面的错误,于是需要再清洗一遍具体来说就是用gpt4再来润色一遍,作者也给出了相应的prompt

同时为了安全等,作者对图像进行了模糊处理
- 关键物体检测

基于前面识别出的物体名称和关键词组成一个开放词汇列表,连同像素化图片一起输入到开放词汇检测模型中,以便进一步标定物体位置。
- 主角信息的后期处理
为了进一步细化和校准人物信息,作者进一步使用了Deepface对人脸进行检测并标注其在整帧中的位置,用于后续模型对人物二维位置的理解。而且还对主角的年龄、性别、情感和民族进行预测,以使人物的信息更加完整。总的来说就是更加细化补充各种关键信息。
- 数据校准
让12名专业短剧编剧对数据进行最后的校准。
- 创作视频

有了上面的数据,就可以直接输入给视频模型进行创作了,不同于传统的拍摄(需要完整剧情等等),这里更需要关键信息的描述即上面的所做的抽取。
总结
(1)对于短视频的创作,镜头等描写很关键,而且只写了一些关键人物等等,脚本剧情本身的冲击感不强,而对于创作小说来说文字本身的刺激感更关键,所以根据最终产品形态的不同侧重点不同,那么可以利用挖掘的数据源也不一样。
(2)AIGC本身还是做内容消费,如果模型能够持续不断的创作好内容(不论是搞笑、段子等等),那都可以有一席之地!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









