






前言
图像生成和理解的技术都在快速发展,比如之前咱们介绍过的视频理解模型:
《能理解1万帧长视频的大模型!》https://zhuanlan.zhihu.com/p/1907375626903597639
但通常都是单独优化的,行业内一直有个技术主线就是将所有模态、各种任务进行大一统,训练一个巨无霸的模型,从理念上来讲这是有可能的,毕竟到时候就可以吃各种形式的数据,按照Scale Law,吃的多,那就有可能效果进一步提升。
今天要给大家介绍的是一篇字节刚放出的工作,其将图片、文本两个模态进行统一,同时将图像理解和生成进行统一(将来是不是可以将语音模态一块考虑进来,当然语音也有各种类型的任务,笔者也写过几篇语音的技术,感兴趣的可以翻阅历史)。同时还借鉴了deepseek的Thinking模型,给该模型加了可以思考推理的能力。
其不仅仅能生成一般的图片,还支持一些高级功能,下面是一些例子
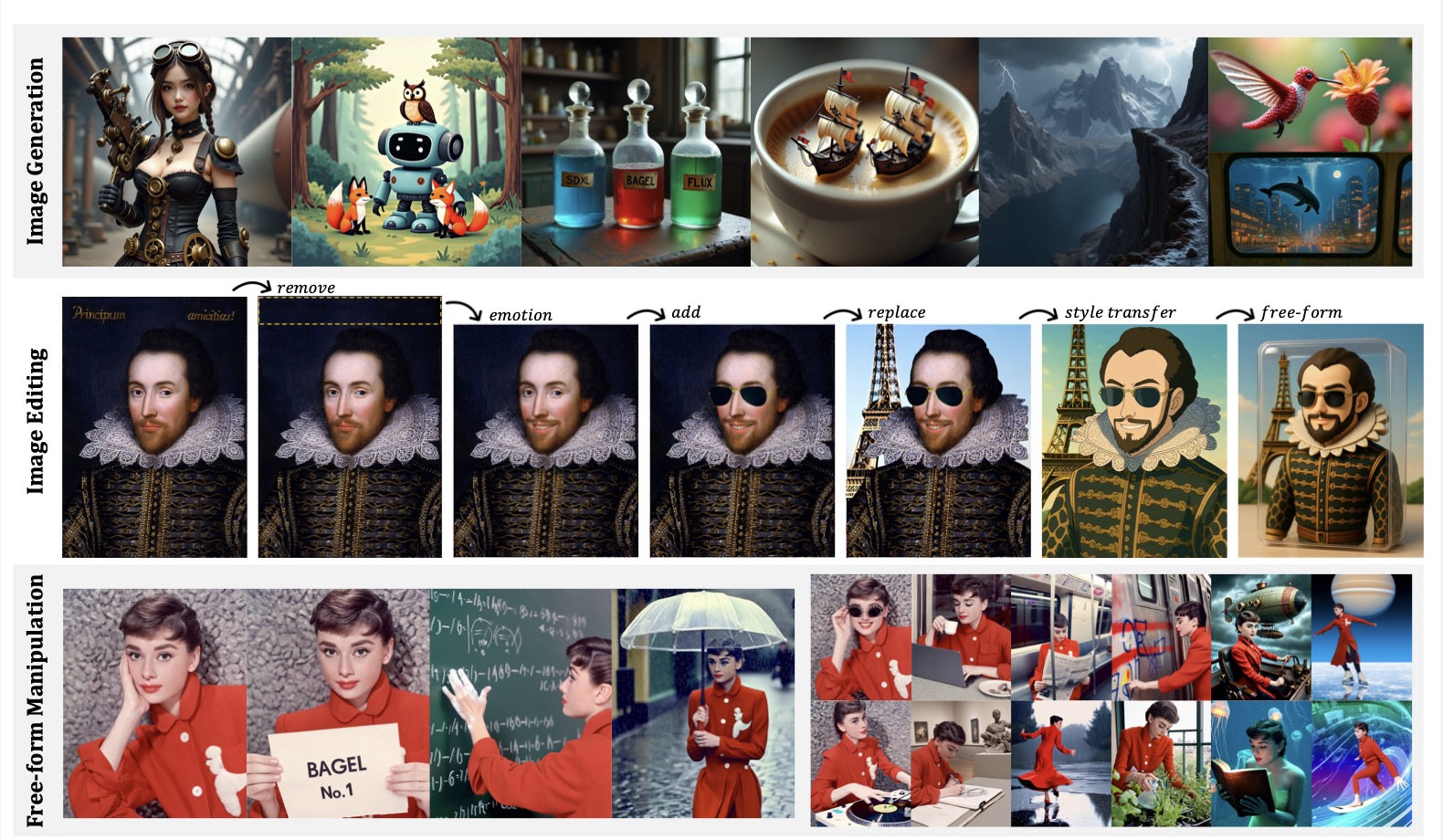
从这里可以看到模型的具体Thinking

和业界一些sota模型的对比

更多case大家可以看原文笔者就不一一列举了
论文链接:https://arxiv.org/pdf/2505.14683
github:https://github.com/ByteDance-Seed/Bagel
下面咱们还是重点看看其技术上是怎么实现的。具体来说我们先看理论方法,然后再深入看其代码实现。
方法
(1)模型框架
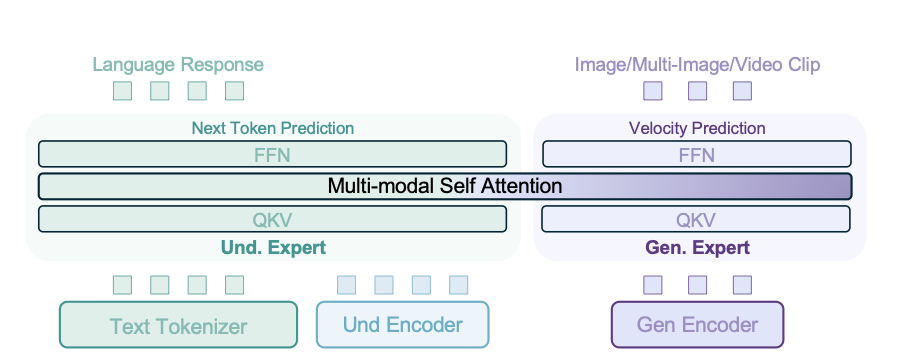
可以看到输入侧有三个编码器来分别处理不同模态和任务,输出侧有两个解码器。其中中间还是以大模型为主体的LLM框架。
具体来说主体LLM框架用的是Qwen2.5,输入侧的文本编码器都是对应的,图中的Und Encoder对应的是图像理解任务时对图像的编码也即ViT encoder,具体用的是SigLIP2-so400m。图中的Gen Encoder对应的是图像生成任务时对图像的编码也即VAE encoder,具体来说用的是FLUX的一个pretrain model。
输出侧对应文本就是用CE loss,对于图像就是MSE loss。
下面重点看下中间的LLM框架,作者这里考虑了三种常见的框架比如dense、moe和mot。其中moe经常就是把FFN层 多copy一份来路由。而这里的mot就是把所有的可被训练的参数进行copy(不仅仅是FFN)。需要注意的是对于moe类的框架(可以看到mot其实就是更特殊的mo e),虽然参数量看着多了,但是在实际推理时,每次激活的参数量和dense是一样的。
那究竟选哪个框架呢?作者选了一个相对来说小一点的模型(Qwen-2.5的1.5B)来做了个实验如下
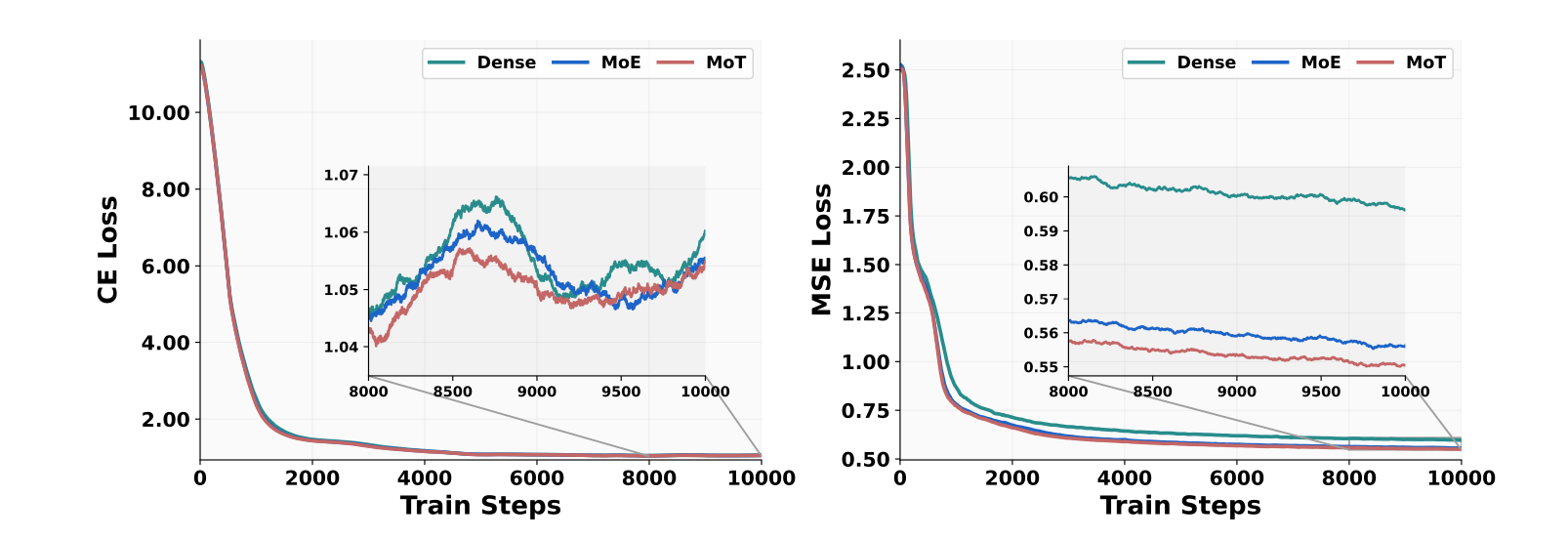
图中的CE和MSE loss可以分别理解成理解和生成任务,可以明显的看到在生成任务上MOT是稳定的好且收敛快。在理解任务上虽然有一些波动,但是综合来看的话MOT表现还是最好的。
从这里可以看到MOT这种将用于生成和理解的参数进行分离(所有的参数都copy了两份)有明显的好处,这可能表明理解和生成这两个不同的目标可能会将模型引向不同的参数空间。所以采用MOT这种为多模态理解和生成分配单独的容量的方法,可以缓解因特定模态学习目标相互竞争而产生的问题。
看到这里可能大家会有疑惑:都分别单独参数了,那大一统体现在哪里呢?其实是体现在统一算attention,虽然参数是分别的,但是到时候会merge成一个统一的sequence,一字排开,然后统一attention,后面我们具体看看代码会更清晰一点。
(2)数据
除了常见的纯文本和 文本-图片 pair外,作者还自行精心构建了Interleaved数据(灰色部分),旨在弥补支持涉及多幅图像和中间文本的复杂上下文推理方面的能力。
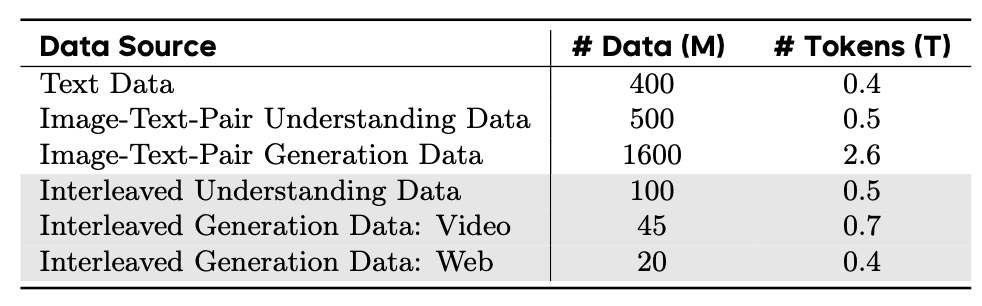
下面我们来重点看看Interleaved data这部分。
- 数据来源
一部分是收集了video数据,主要是一些在线的视频和一些开源的数据集比如Koala36M、MVImgNet2.0等等,这些视频数据天然包含大量的实现世界的信息。
还有一部分来源是Web,其主要有OmniCorpus等等。
- 数据过滤
对于视频数据,首先使用镜头检测将视频分割成简短、连贯的片段(根据视觉相似性选择性地合并相关片段)。然后使用裁剪检测和帧级边界框聚合技术去除黑色边框和叠加层。为了确保质量,同时根据长度、分辨率、清晰度和运动稳定性对片段进行筛选,并使用基于 CLIP 的相似性进行重复数据删除。
对于web数据首先用fastText分类器进行主题分类,然后选定的数据再次通过 LLM 分类器进行细粒度过滤,同时为了进一步提高数据质量,还应用了一组基于规则的过滤器,分别针对图像清晰度、相关性和文档结构等进行过滤

- 数据构建
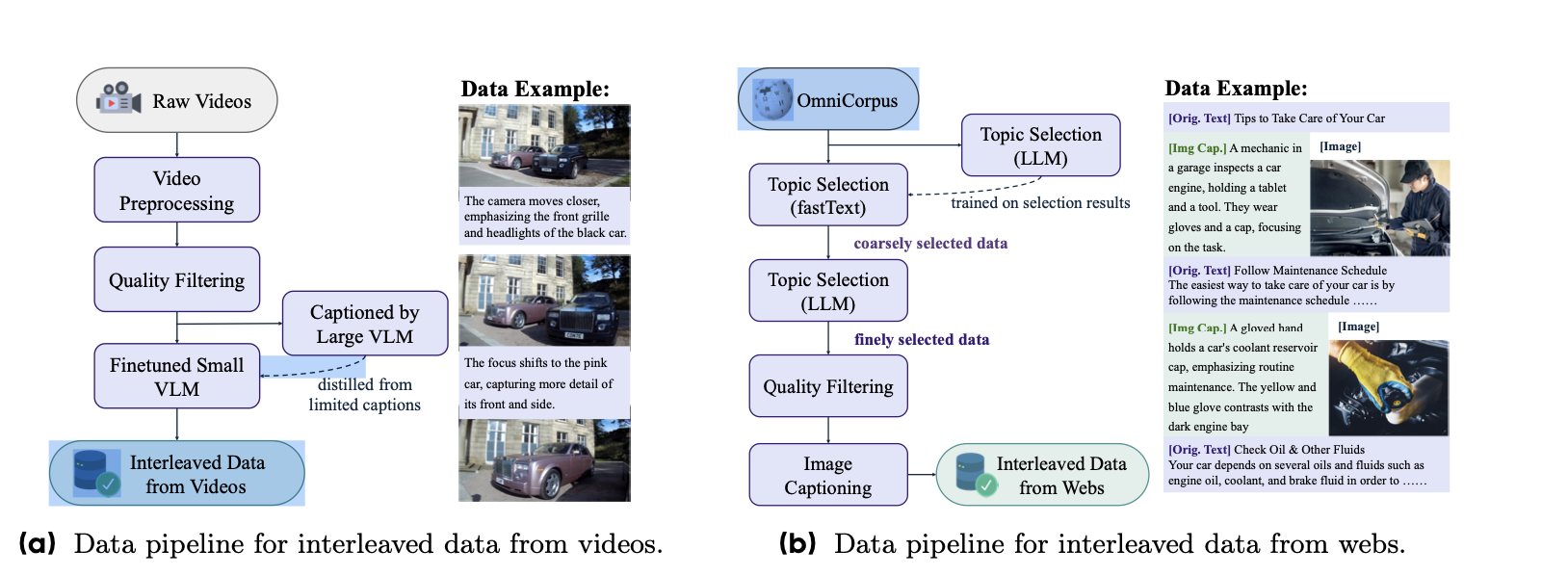
其从video里面构建Interleaved数据的主要思路是生成连续帧之间变化的文本描述比如捕捉物体运动、动作转换和场景转换。具体来说是用VLM类的模型,但是由于成本太高,所以作者用了一个高质量的数据蒸馏训练了一个小的VLM模型即Qwen2.5-VL-7B,然后用其去标注。同时为了减少幻觉,每个图片的描述caption限制在30 token(生成的多了就容易幻觉),整个流程如上图(a)。
其从web里面构建Interleaved数据的主要思路是先用Qwen2.5-VL-7B来给图片生成一个简洁的描述,并将其直接插入到图像之前。这样模型在生成图片的时候会同时基于先前的上下文和插入的描述,这样的好处是可以缓解由松散相关或模糊的输入引起的不对齐问题。
- 推理数据
作者参考现在语音模型大火的推理范式即在完成任务之前,模型自己先think一下,为此作者将其也搬到了多模态。具体来说如下:
(a)Text-to-Image generation
在普通文生图领域,先写一些文本query,然后让Qwen2.5-72B去根据这query生成对应的更详细的相关prompt,然后根据query和相关prompt去调用 FLUX.1-dev生成图片。其中prompt就是think的部分。
(b) Free-form image manipulation
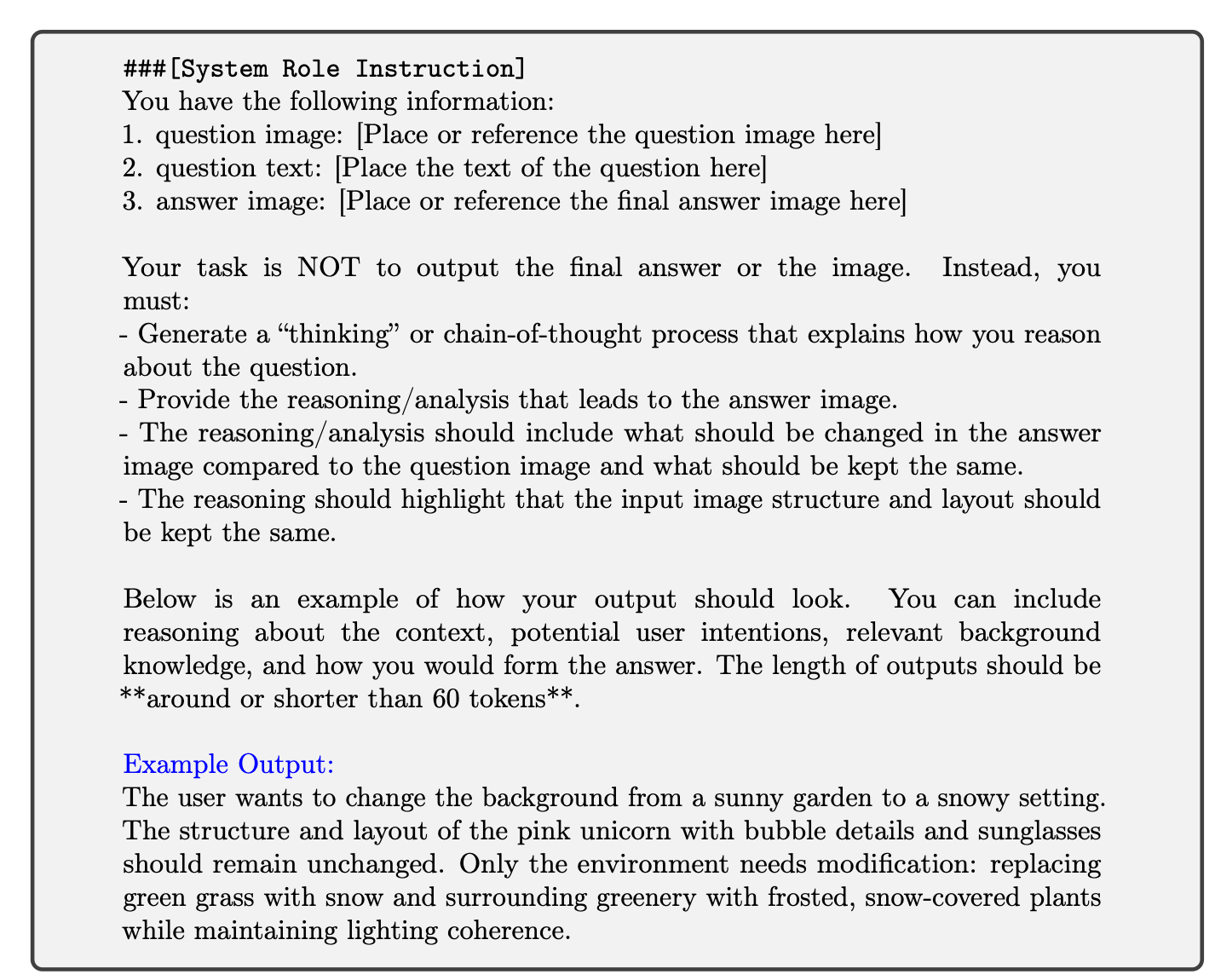
这部分的任务对应的是图像自由编辑,其核心思路也很简单,就是把原始图像、query和目标图像给到VLM 模型,让其给出中间的推理过程(注意不是给结果,而是只给中间的推理过程),具体送给VLM 的prompt如下

© Conceptual Edits.
这个任务就是一些更高级一些的概念层面的编辑比如把一个物体转换成另外一种风格(而不是之前的简单的pixel的编辑)。具体来说分三步,从一个图像序列中,让VLM识别一个合理的输入输出图像对。然后让模型根据选定的对生成相应的文本问题query。最后使用 VLM 评估问题的质量及其与输入和输出图像的对齐情况,过滤掉质量低下的示例。这样就有了基本的训练数据。然后让VLM生成中间的合理解释(用DeepSeek-R1的一个例子来做few-shot)。具体的prompt如下:

(3)训练
(a) 训练阶段.
框架和训练数据介绍完了,接下来咱们就看看具体的训练流程,下面这种表基本非常清晰的列出了所有。
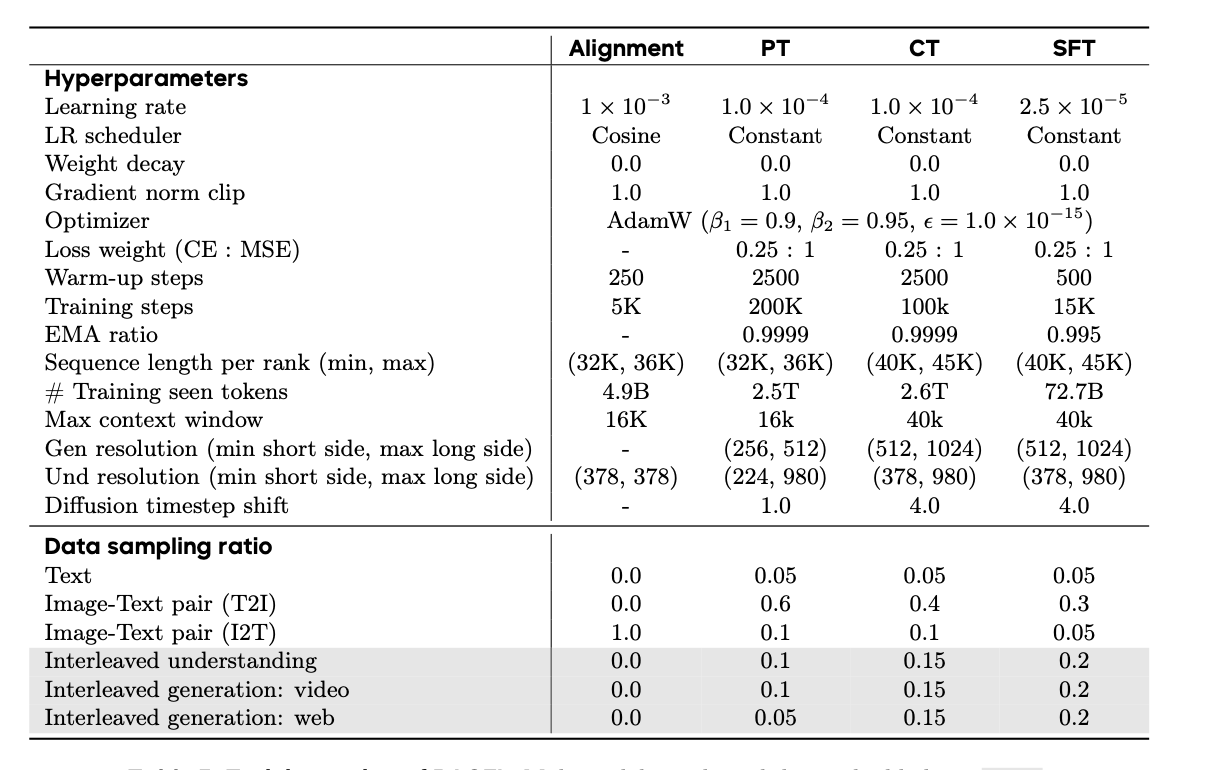
具体来说分四个阶段,第一个阶段是Alignment,主要是对齐SigLIP2 ViT encoder和Qwen2.5 LLM,具体来说就是训练一个MLP connector。
第二个阶段是Pre-training (PT),除了不训练VAE,其他都开始训练,基本上所有准备的语料全部上,一共训练2.5T tokens。
第三阶段是Continued Training (CT)这个阶段主要是进一步增加视觉的语料比重,因为这对多模态的生成和理解都很有帮助,而且是增强上述的interleaved数据。
第四阶段是Supervised Fine-tuning (SFT),这就是sft阶段,生成的数据是从image–text-pair和interleaved-generation里面构建的一个高质量数据子集。对于生成的理解用的数据是 LLaVA-OV和Mammoth-VL。
(b) 数据混合比例
可以看到整个数据集既有理解的又有生成的,那到底该以什么比例混合呢?为此作者在1.5B上面先做了个小实验如下
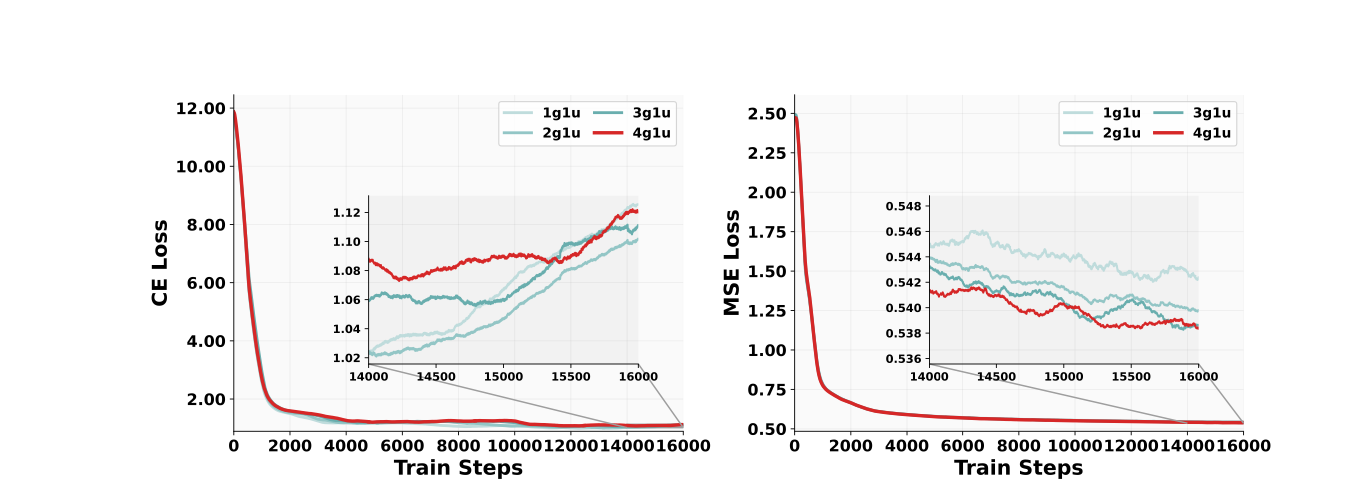
图中1g1u代表生成和理解的比例是1:1。可以看到在生成任务MSE loss上当生成:理解增加到4:1时,其带来了0.4%的收益(这在生成领域是个显著的收益)。而在理解任务CE loss上不同混合比例没有表现出统一一致的规律,其中最大差距是“4g1u”和“2g1u”之间在第 14,000 步的 0.07,但是这个量级对下游benchmark的影响可以忽略不计。
所以得出的一个结论是生成数据采样频率应该远高于理解数据。这里一个直观感觉其实也可以知道,那就是生成任务比理解任务通常来说更难一些,所以需要更多一点数据来学。
© 学习率
关于如何配置学习率,作者也是先在小模型1.5B上做了个实验如下:
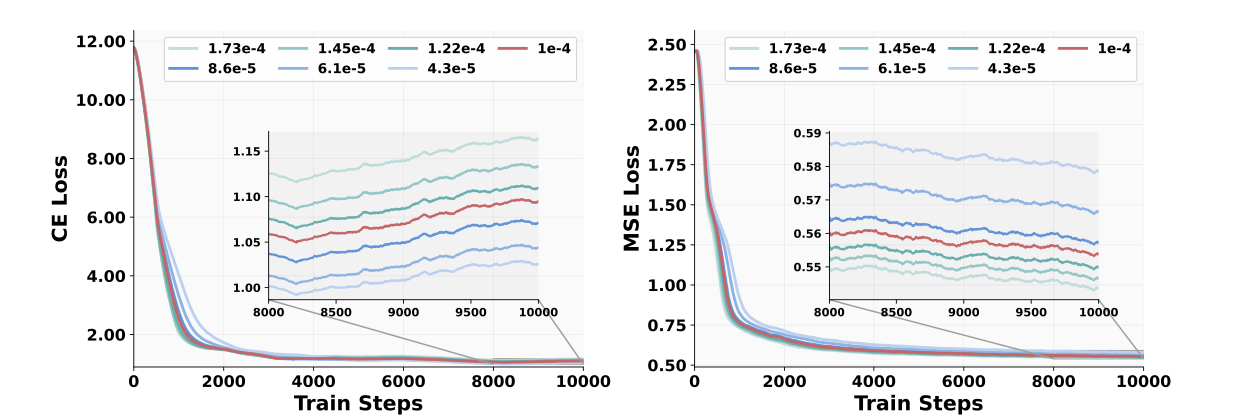
可以看到更大的学习率有助于生成任务MSE loss快速收敛,而更小一点的学习率对理解任务更好一些,也就是说呈现了相反的趋势,为了平衡好两个任务,作者用了给了不同的权重。
效果评估
文章一开始已经放了很多case了,这里就再放几个随着数据训练越来越多,效果越来越好的的变化case吧,也算是进一步验证了Scale Law的铁律吧
。


代码实现
再看了论文了解了基本做法后,我们再来看下代码是具体怎么实现的。
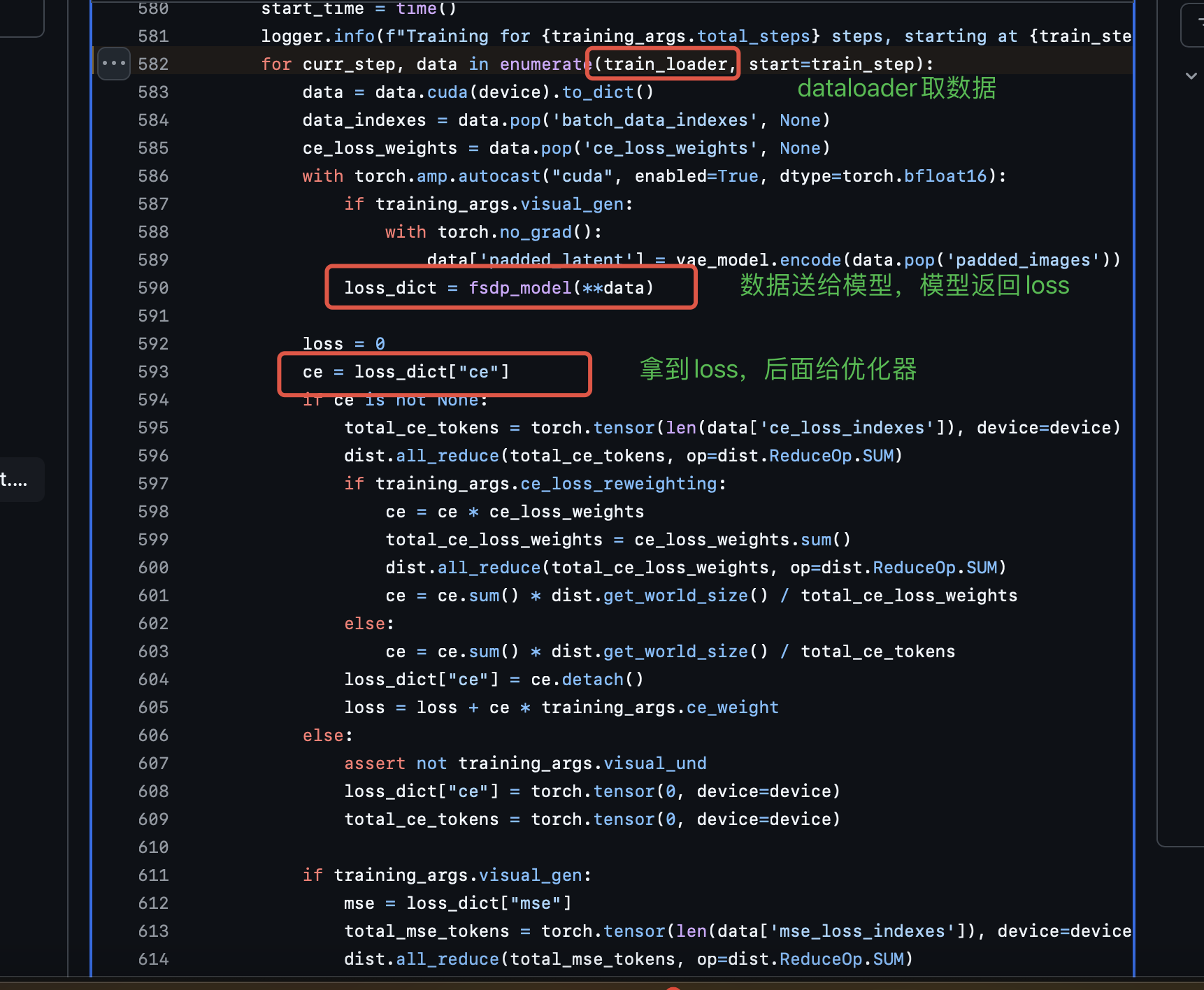
笔者看代码的习惯是先找到训练的主流程,注意是要找到真真的主流程,因为有的代码会在外面包很多层,真真的主流程有一个不变的逻辑:那就是从dataloader里面取数据,然后送给模型,模型返回loss,优化器优化该loss。
找到主流程后那接下来其实就是去看dataloader和model。分别对应着数据怎么处理和模型结构是什么(模型的输入和输出具体是什么),其两则往往是对应的即数据处理的最终输出样式就是模型的输入样式。
- 主逻辑
按照上面思路我们就先来找一下主逻辑
https://github.com/ByteDance-Seed/Bagel/blob/main/train/pretrain_unified_navit.py#L582
- 模型
既然找到了主逻辑,那我们就顺藤摸瓜去看看模型长啥样即找fsdp_model,其实主要就是看其forward,具体来说在:
https://github.com/ByteDance-Seed/Bagel/blob/main/modeling/bagel/bagel.py#L98
先宏观来看,其实很清晰如下:
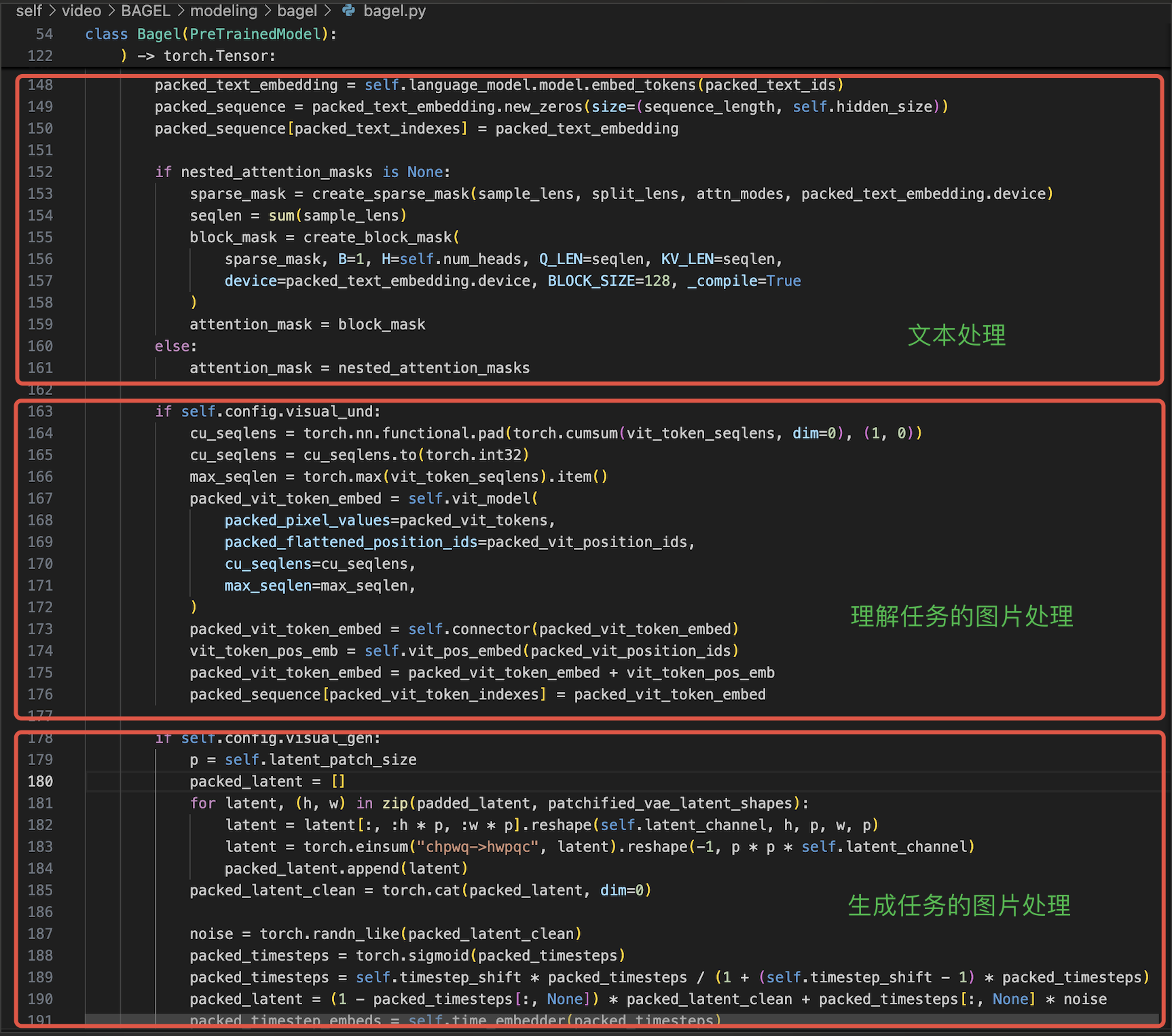
具体来说其有一个全局的packed_sequence序列,文本、图像理解以及生成的模态在各自encode化后都merge到该序列然后统一送到LLM中,比如150、176行就分别通过packed_text_indexes、packed_vit_token_indexes索引将文本和图像理解的输入放到了对应的位置,而packed_text_indexes和packed_vit_token_indexes都是dataloader处理好传进来的,其实就是一字排开,到时候看loader就清楚了。
同时可以看到对于文本,就用language_model取元素LLM的文本编码即可。而对于理解的图像是先过167行的vit_model,然后过173行的connector,最后175行叠加位置编码作为最终的编码表征。对于生成的图像则同样通过193行vae2llm、timestep_embeds以及位置编码三部分叠加得到最终的编码。
再得到最终拼接好的packed_sequence就可以送到LLM拿到最终的last_hidden_state计算loss(非常标准的做法),如下
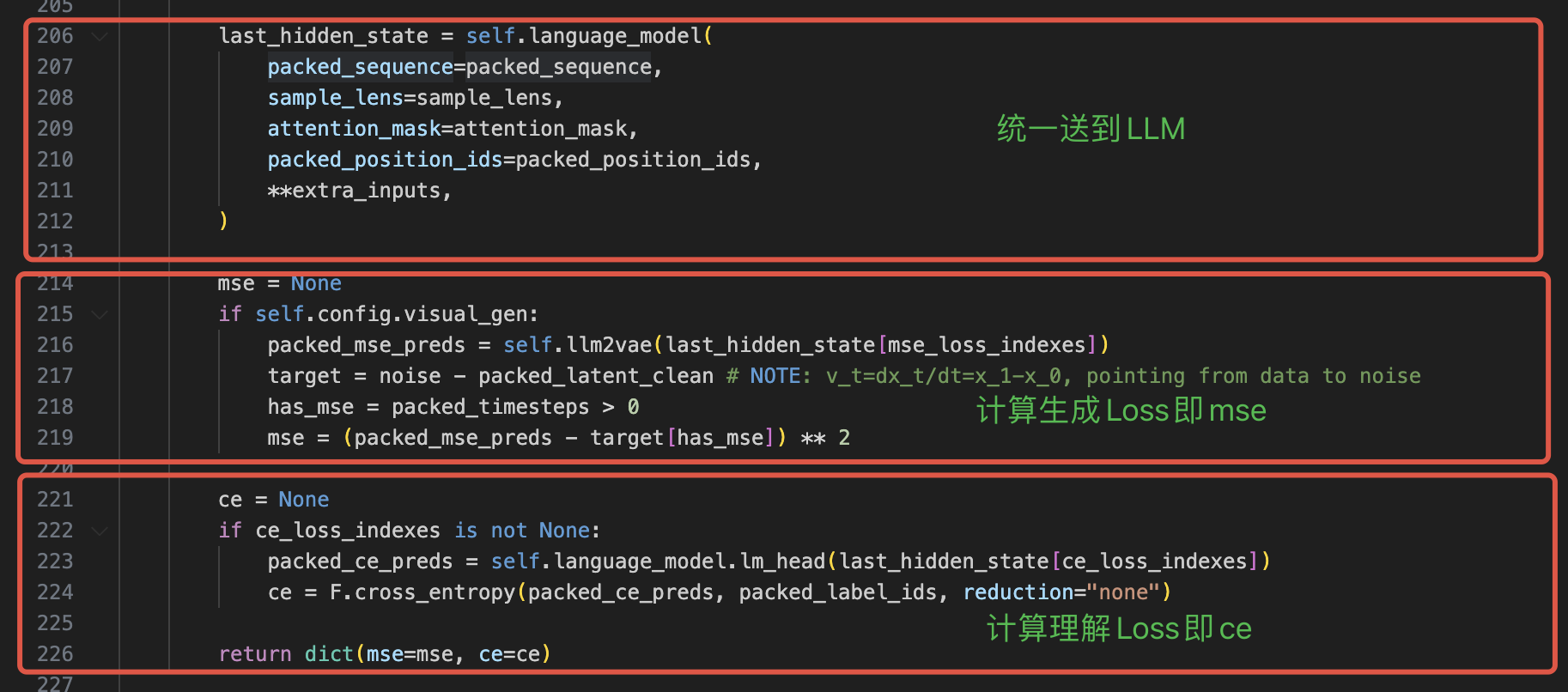
看到这里大家可能会有疑问?MOT即给理解和生成单独copy参数在哪里体现的呢?其实是在这里
https://github.com/ByteDance-Seed/Bagel/blob/main/modeling/bagel/qwen2_navit.py#L403
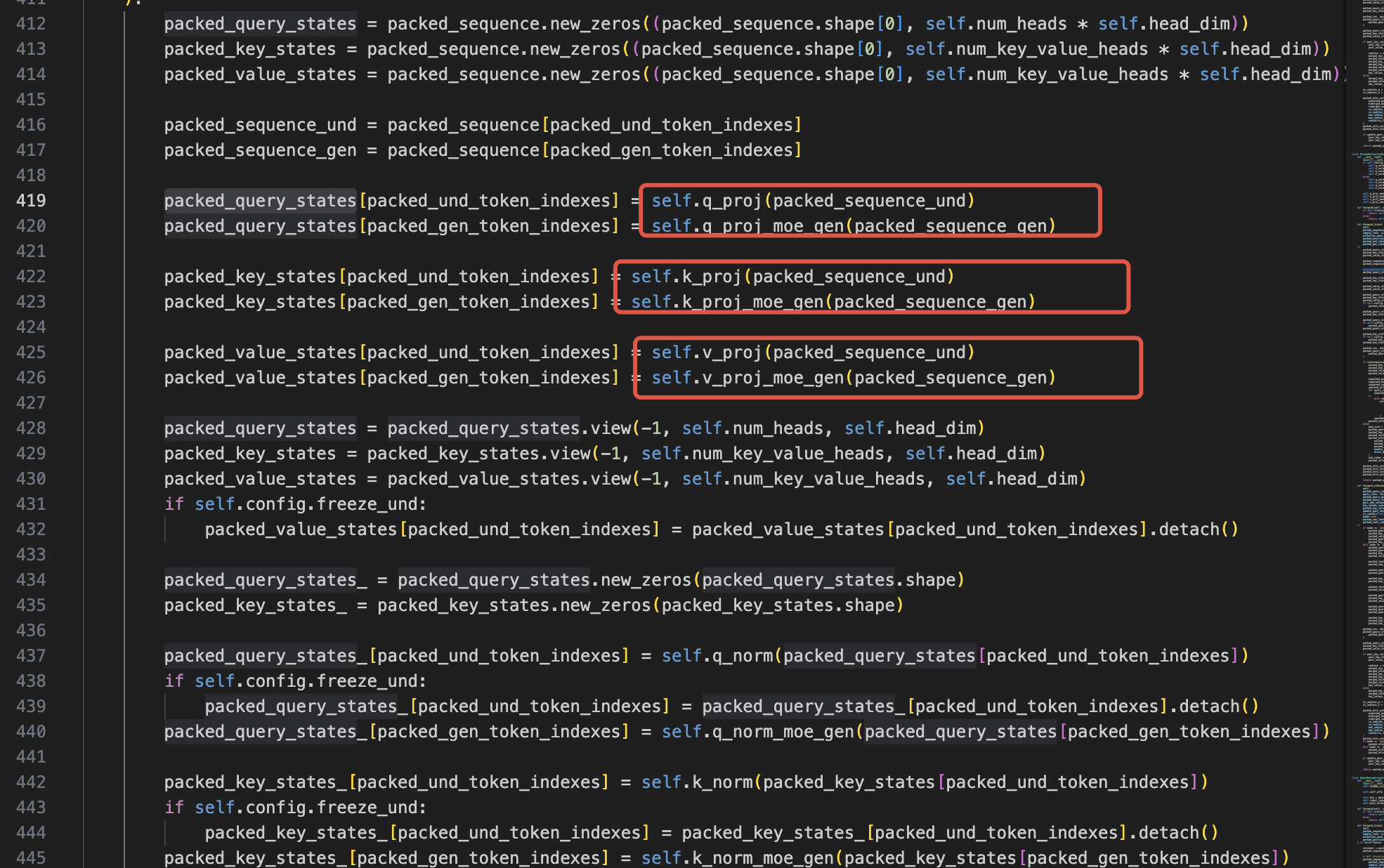
比如上面的红色框其为理解和生成都单独生成了kqv,但是最后用了同样的手段即拼接好统一放到了packed_query_states_。然后497行进行统一的attention。
- dataloader
看dataloder核心一般其实就是看dataset,loader其实包了一次取数据的逻辑,于是我们找到了PackedDataset。具体来说最主要的拼接逻辑在
https://github.com/ByteDance-Seed/Bagel/blob/main/data/dataset_base.py#L316
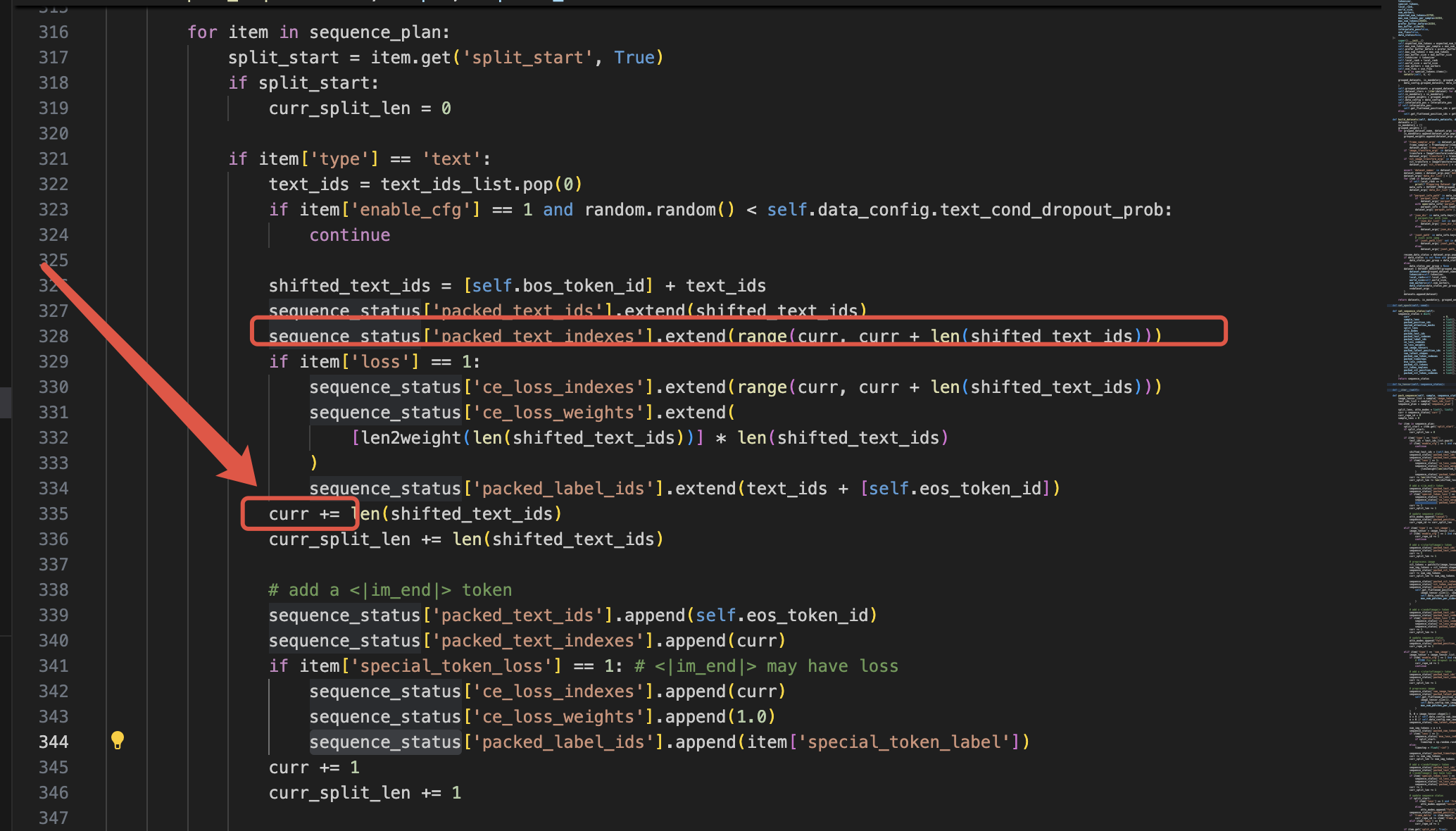
比如最前面我们说的packed_text_indexes和packed_vit_token_indexes其实都是这里来的。具体来说是通过curr这个全局变量来一字的,curr记录的是当前最右面拼接到哪里了,然后把当前的模态的token继续按照这个往后排,比如328这里就是继续按照curr排文本token。排完了文本接着就排图像理解的token,具体来说先加一个隔离符<|startofimage|>,然后再排。
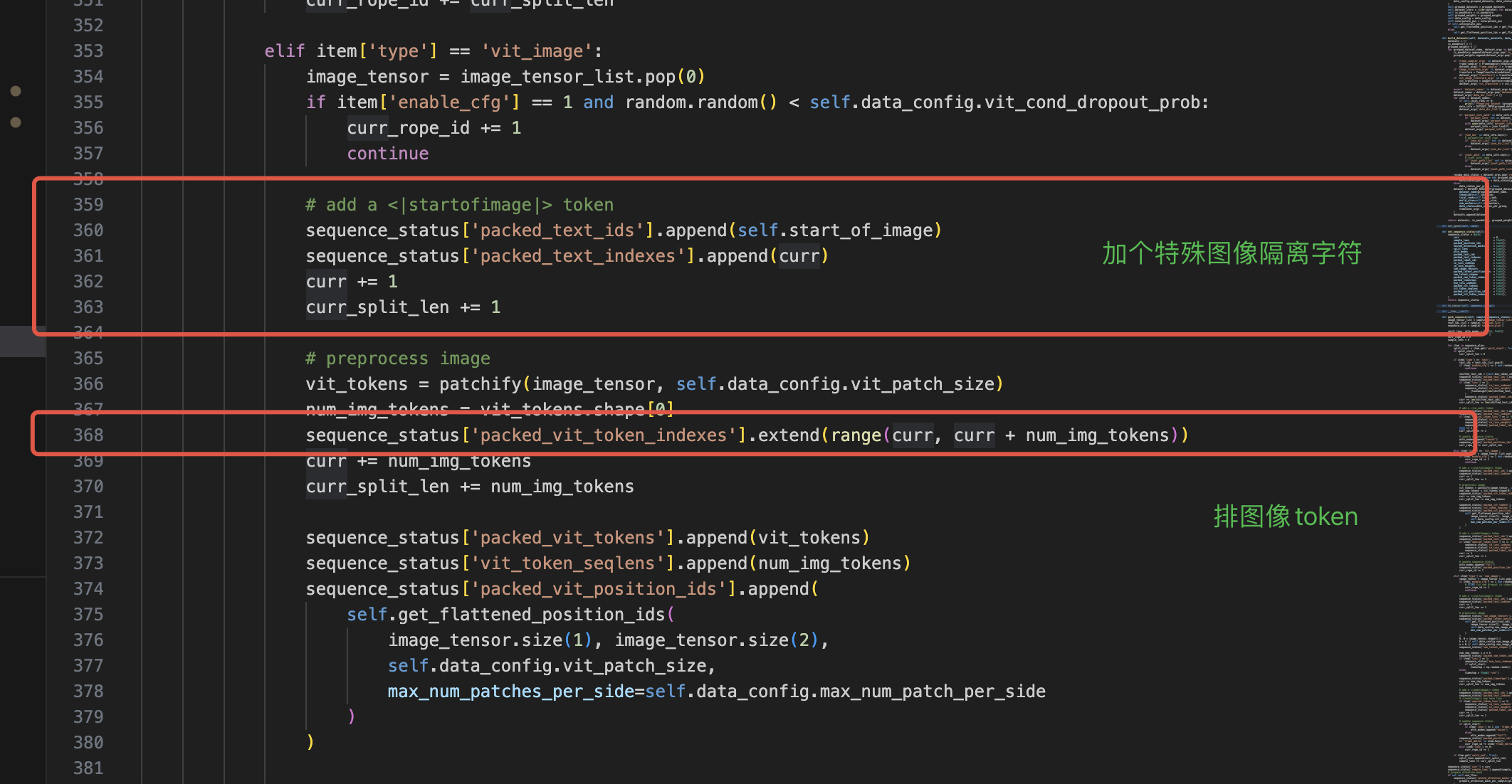
当然后面紧接着就是排图像生成的token了,笔者就不一一列举了。
总结
(1)模态、任务的大统一是趋势,这个方向段时间内应该还会继续有很多工作,甚至把语音一款融合进来。但是大的框架应该是相同的即【输入】每个模态(任务)可能有自己对应的encoder进行分别编码【主框架】主框架应该都还是用LLM,毕竟他的推理能力强,当然这里可以有各种花样比如dense、moe等等。但大概率都是复用目前一些训练好的强大推理能力的参数【输出】每个模态(任务)可能有自己对应的encoder进行分别解码。
(2)数据层面也是非常非常重要,尤其是各种多摸交叉数据的获取。这里可以有很多工作,必须数据的清洗和重建生成,其中后者一直是AI领域尤其是大模型出现后的一个重要研究领域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









