






突然接到一个客户的需求,需要在Excel中批量提取图片中的文字,本文主要使用Tesseract OCR做识别,Tesseract OCR4.0以后提高了对中文的识别率,大家在别的编程语言中也可以试试,本文使用的5.5.0,今天把实现方式分享给大家。
1 安装Tesseract OCR
-
安装时勾选所需语言包(如
chi_sim中文、eng英文)。 -
网盘下载地址:Tesseract-OCR.rar
链接: https://pan.baidu.com/s/1P_ibRfWfMjLlLee5n2H3qw 提取码: scqf
--来自百度网盘超级会员v2的分享 - 添加Tesseract安装路径到系统环境变量(如D:\Tesseract-OCR)
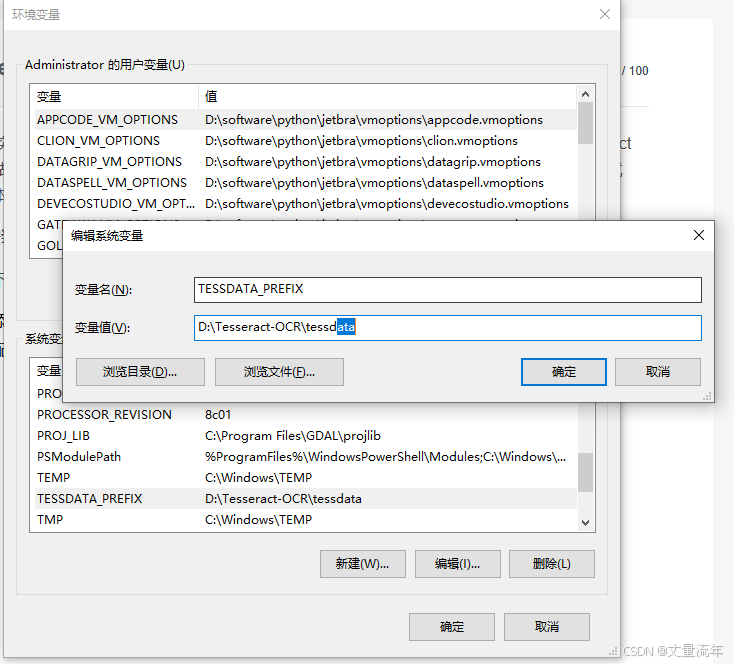
- 配置系统变量(变量名:TESSDATA_PREFIX,变量值:D:\Tesseract-OCR\tessdata)
2 Excel设置
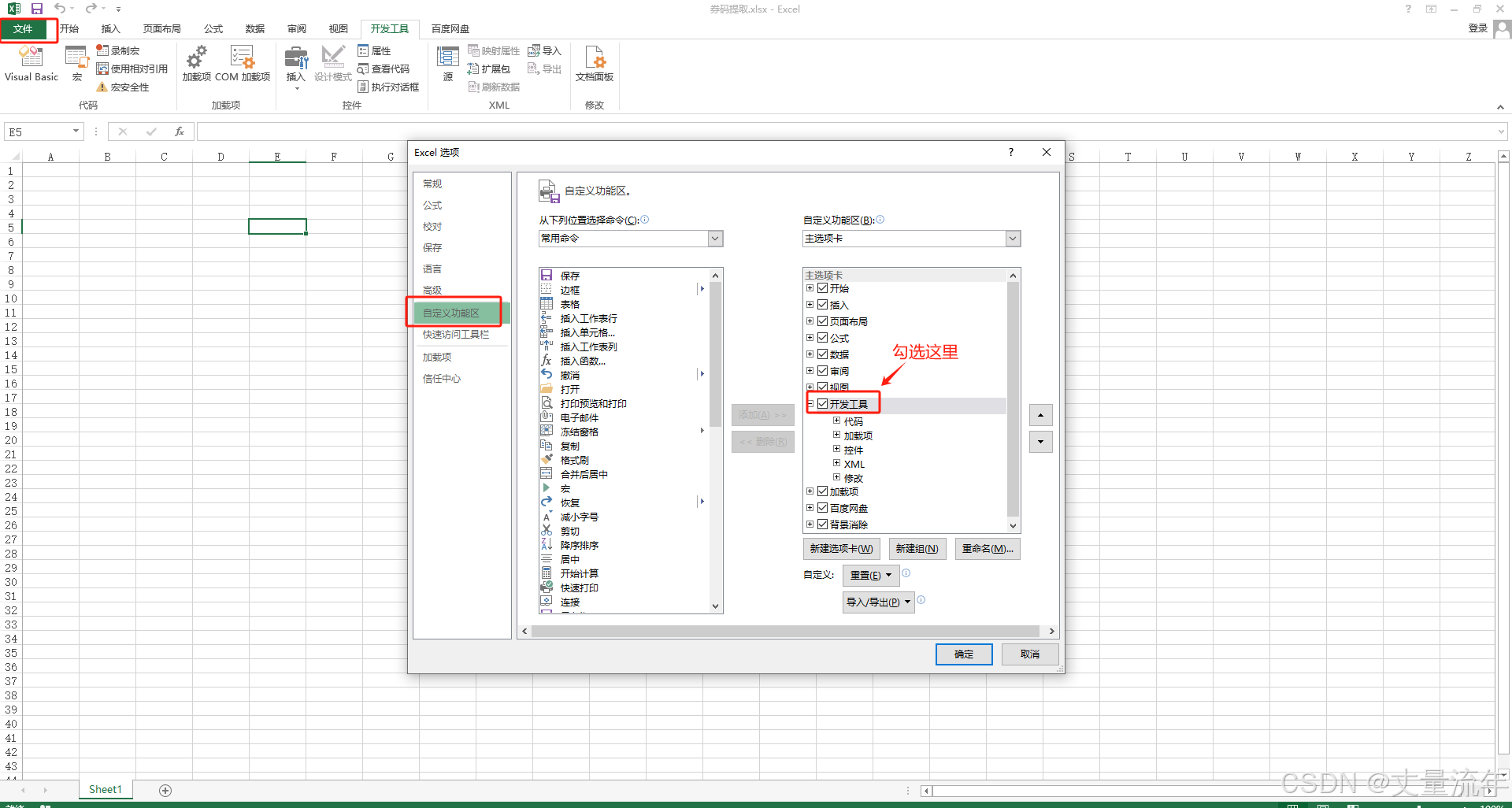
开启开发者工具:文件 → 选项 → 自定义功能区 → 勾选“开发工具”
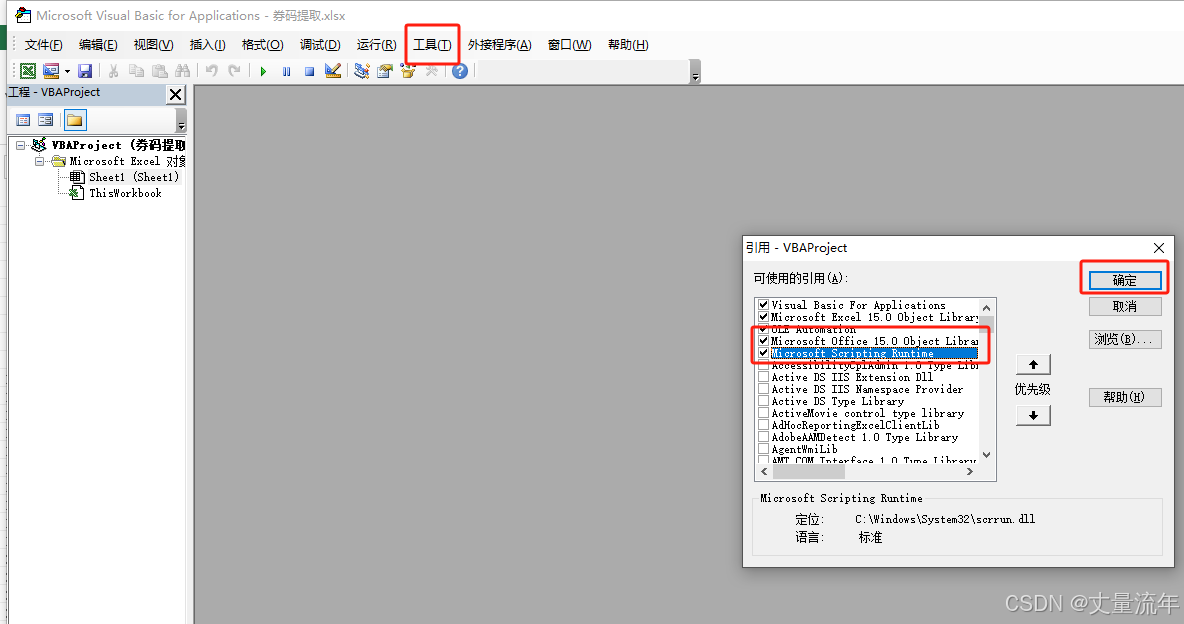
引用必要库:开发工具 → Visual Basic → 工具 → 引用 → 勾选:
-
Microsoft Scripting Runtime(文件操作) -
Microsoft Office XX.X Object Library(Office对象模型)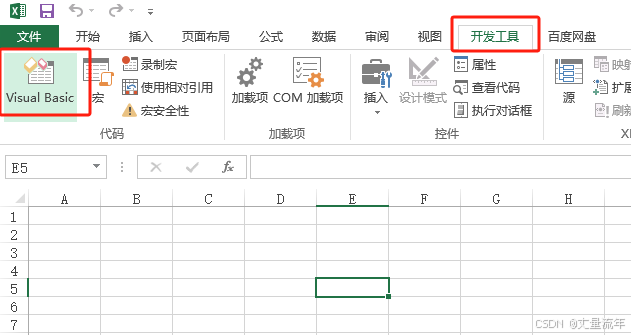
3 编写程序
step1:插入图片

step2:右键点击sheet1=>点击查看代码进入编码页面

step4:右键点击sheet1=>插入=>模块
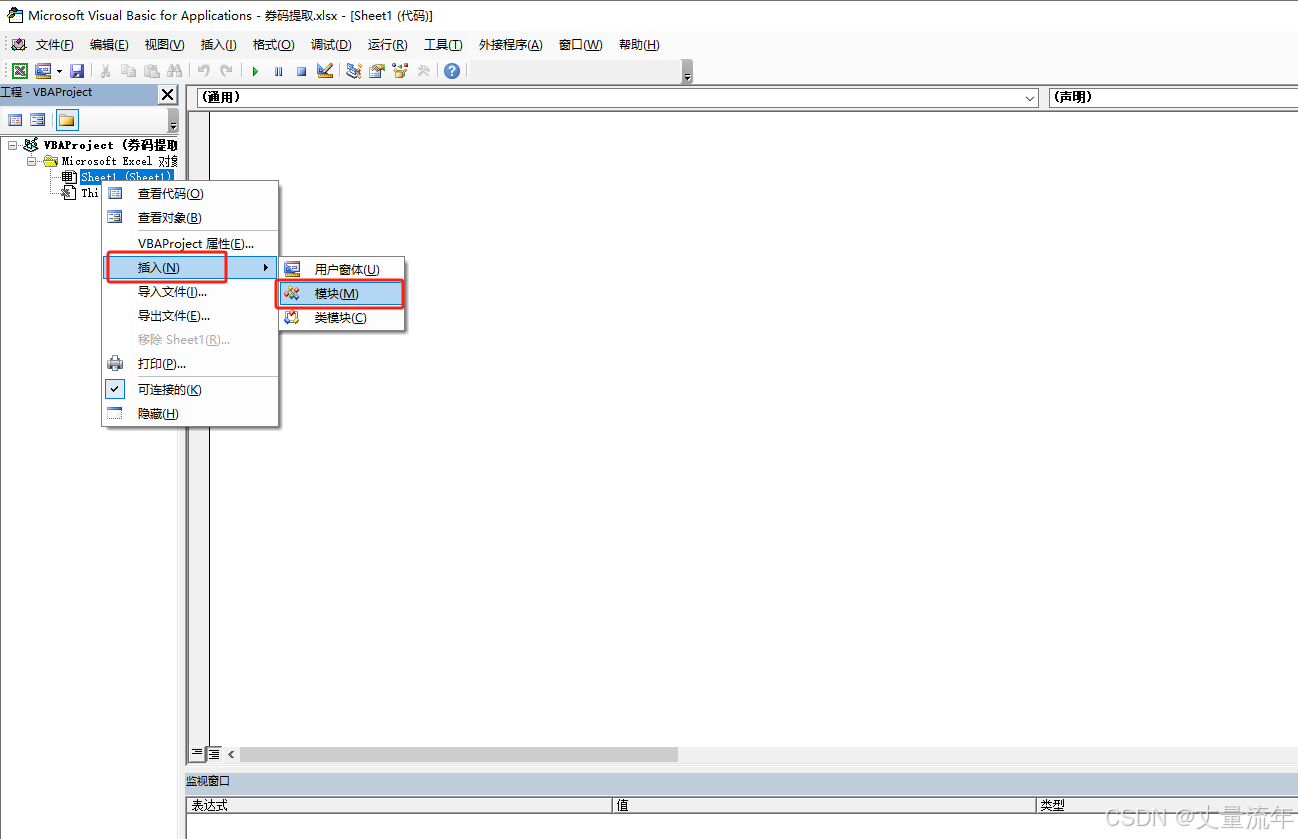
step3:在模块1写入图片识文字代码=>保存代码(我只提取部分带单元格内)
' 需要引用: Microsoft Scripting Runtime, Microsoft Office Object Library
Sub ExtractTextFromImagesToCells()
Dim shp As Shape
Dim tempFolder As String
Dim tempImagePath As String
Dim ocrResult As String
Dim tesseractPath As String
Dim targetCell As Range
Dim fso As FileSystemObject
Dim ts As TextStream
Dim index As Integer
' 设置Tesseract路径(根据实际安装路径修改)
tesseractPath = "D:\Tesseract-OCR\tesseract.exe"
' 创建临时文件夹和文件系统对象
tempFolder = Environ("TEMP") & "\ExcelOCR\"
Set fso = New FileSystemObject
If Not fso.FolderExists(tempFolder) Then fso.CreateFolder tempFolder
' 遍历当前工作表所有图片
For Each shp In ActiveSheet.Shapes
If shp.Type = msoPicture Then
index = index + 1
' 导出图片到临时文件
Dim fileName As String
tempImagePath = tempFolder & "Image_" & index & ".jpg"
ExportShapeToImage shp, tempImagePath
' 调用Tesseract OCR识别
ocrResult = RunTesseractOCR(tesseractPath, tempImagePath, index, "chi_sim") ' 使用中文识别
' 将结果写入图片右侧单元格
Set targetCell = shp.TopLeftCell.Offset(0, 1)
targetCell.Value = ocrResult
' 清理临时文件
If fso.FileExists(tempImagePath) Then fso.DeleteFile tempImagePath
Dim tempTexPath As String
tempTexPath = Left(tempImagePath, InStrRev(tempImagePath, ".")) & "txt"
If fso.FileExists(tempTexPath) Then fso.DeleteFile tempTexPath
End If
Next shp
End Sub
' 导出Shape为图片文件
Private Sub ExportShapeToImage(shp As Shape, savePath As String)
Dim chartObj As ChartObject
shp.Copy
Set chartObj = ActiveSheet.ChartObjects.Add(0, 0, shp.Width, shp.Height)
chartObj.Chart.Paste
chartObj.Chart.Export savePath
chartObj.Delete
End Sub
' 调用Tesseract执行OCR
Private Function RunTesseractOCR(tesseractPath As String, imagePath As String, index As Integer, Optional lang As String = "eng") As String
Dim shellCommand As String
Dim outputPath As String
Dim found As Boolean
Dim fileNum As Integer
Set fso = New FileSystemObject
outputPath = Left(imagePath, InStrRev(imagePath, ".")) & "txt"
' 构建命令行指令
shellCommand = tesseractPath & " " & imagePath & " " & Left(outputPath, Len(outputPath) - 4) & " -l " & lang & " --oem 3 --psm 6"
Shell "cmd.exe /c " & shellCommand, vbHide
' 等待命令执行完成(可选)
Do While Len(Dir(outputPath)) = 0
DoEvents
Application.Wait Now + TimeValue("0:00:01")
Loop
' 读取输出文件内容
Dim fileContent As String
Dim lines() As String
' 读取OCR结果
If fso.FileExists(outputPath) Then
fileContent = ReadUTF8File(outputPath)
' MsgBox fileContent
If fileContent <> "" Then
' 按行分割
Dim num1 As String
Dim num2 As String
Dim num3 As String
lines = Split(fileContent, "使用须知")
num1 = Mid(lines(0), Len(lines(0)) - 38, 12)
num2 = Mid(lines(0), Len(lines(0)) - 25, 12)
num3 = Mid(lines(0), Len(lines(0)) - 12, 12)
Range("G" & index).Value = num1
Range("H" & index).Value = num2
Range("I" & index).Value = num3
End If
Else
RunTesseractOCR = "识别失败"
End If
End Function
' 函数:读取UTF-8编码的文本文件
Function ReadUTF8File(filePath As String) As String
On Error GoTo ErrorHandler
Dim stream As Object
Set stream = CreateObject("ADODB.Stream")
With stream
.Type = 2 ' 文本模式
.Charset = "utf-8" ' 指定编码为UTF-8
.Open
.LoadFromFile filePath ' 加载文件
ReadUTF8File = .ReadText ' 读取内容
.Close
End With
Exit Function
ErrorHandler:
MsgBox "读取文件失败!" & Err.Description
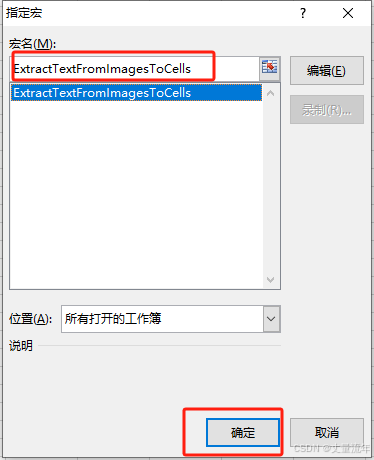
End Functionstep4:添加提取文字按钮,并绑定事件




















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









