










一、Spark SQL的基本概念
1,Spark SQL的组成
Spark SQL是Spark的一个结构化数据处理模块,提供一个DataFrame编程抽象,可以看做是一个分布式SQL查询引擎。
Spark SQL主要由Catalyst优化、Spark SQL内核、Hive支持三部分组成。
(1)Catalyst优化
处理查询语句的整个过程,包括解析、绑定、优化、物理计划等,主要由关系代数(relation algebra)、表达式(expression)以及查询优化(query optimization)组成。
(2)Spark SQL内核
处理数据的输入输出,从不同的数据源(结构化数据Parquet文件和JSON文件、Hive表、外部数据库、现有的RDD)获取数据,执行查询(execution of queries),并将查询结果输出成DataFrame。
(3)Hive支持
是指对Hive数据的处理,主要包括HiveQL、MetaStore、SerDes、UDFS等。
2,Spark SQL
Spark SQL的发展,和大数据的发展一样,经历了离线计算、准实时计算、实时计算三个阶段。
(1)离线计算阶段,在大数据发展初期,通过MapReduce模型编写程序直接进行数据查询,解决了海量数据处理问题,编程模型比较简单,可以和Java无缝对接,同时通过Streaming支持C++等多语言编程,产生了划时代的影响;随着数据量的增加和对实时性的要求,基于离线数据计算的输入输出受到磁盘I/O和网络速度的限制,效率成为离散计算的瓶颈。
(2)准实时计算阶段,为了提升编程和查询效率,发展了Hive数据仓库。Hive数据仓库基于HDFS存储构建,并允许使用类似于SQL的语法HiveQL进行数据查询,简化了MapReduce编程,在一定程度上提升了效率,但是并没有彻底解决效率问题。Hive的局限性,促进了Shark的产生。为了进一步提升效率,伯克利实验室使用Shark对Hive进行了改造,替换了Hive的物理引擎,速度得到提升。Shark是Spark生态环境的组件之一,它修改了内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,使SQL查询的速度得到10~100倍的提升。然而不容忽视的是,Shark集成了大量的Hive代码,给优化和维护带来了很多麻烦。Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等)制约了Spark各个组件的相互集成。随着性能优化和分析整合的进一步加深,基于MapReduce设计的部分无疑成为实时计算的瓶颈。
(3)实时计算阶段,为了更好地发展,给用户提供更好的体验,Spark SQL抛弃原有Shark的代码,汲取了Shark的优点,重新进行了开发;Spark SQL直接基于Spark架构进行实现,效率比Shark有所提升。Spark SQL作为新的SQL引擎,基于Catalyst的优化引擎可以直接对Spark内核进行优化处理。Spark SQL整合各种数据源,包括Parquet、JSON、NoSQL数据库和传统关系型数据库,程序在内存中的运行速度是Hadoop MapReduce程序在磁盘上运行速度的100倍。
3,Spark SQL架构
Spark SQL对SQL语句的处理和关系型数据库SQL处理类似,将SQL语句解析成一棵树(tree),然后通过规则(rule)的模式匹配,对树进行绑定、优化等,得到查询结果。
Tree的具体操作是通过TreeNode实现的;Rule是一个抽象类,是通过RuleExecutor完成的,应用于Spark SQL的Analyzer、Optimizer、Spark Planner等组件中,可以简便、模块化地对Tree进行Transform操作。
在整个SQL语句处理过程中,Spark SQL主要依赖了Catalyst这个新的查询优化框架,把SQL解析成逻辑计划之后,Tree和Rule相互配合,利用Catalyst包里的一些类和接口,完成了解析(Analysis)、绑定、优化等过程,最终生成可以执行的物理计划,最后变成DataFrame的计算。
Spark SQL的执行过程:
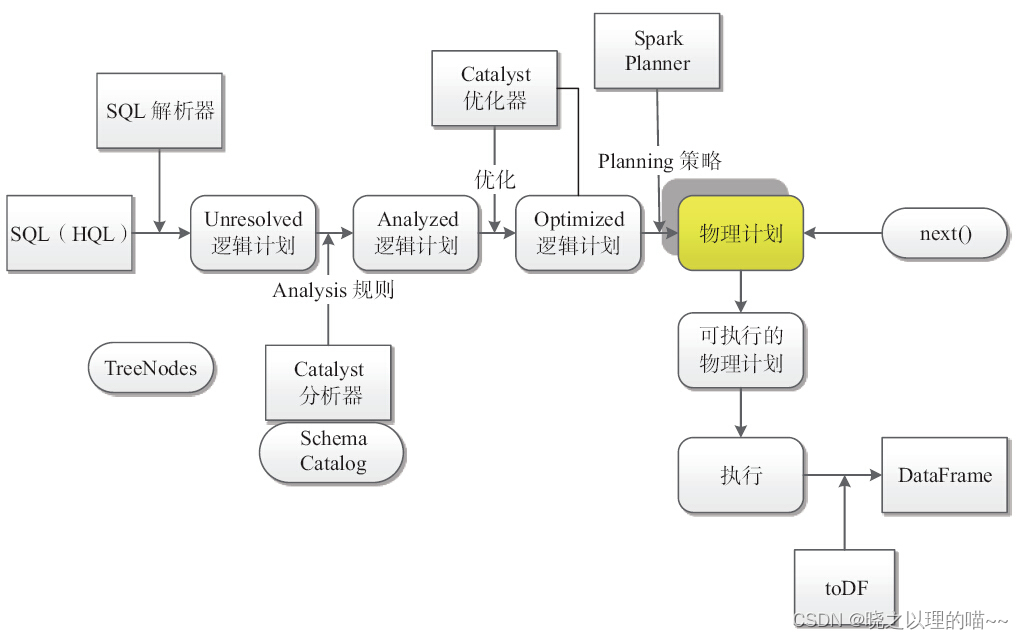
其中树节点(TreeNodes)是指Scala Case类的变换树(transforming trees);SQL解析器(SQL parser)完成SQL语句的语法解析功能,将SQL语句解析成一棵Unresolved逻辑计划树;规则(rules)针对树进行分析、优化。
在Spark SQL的运行架构中,逻辑计划(logical plan)贯穿了大部分过程,其中,Catalyst的SqlParser、Analyzer、Optimizer都要对逻辑计划进行操作;最终形成可执行的物理计划(physical plan)。
sqlContext是使用sqlContext.sql(sqlText)提交用户的查询语句,调用DataFrame(this,parseSql(sqlText))对SQL语句进行处理,执行流程如下:
(1)使用SqlParser对SQL语句进行解析,生成Unresolved逻辑计划(没有提取Schema信息);
(2)使用Catalyst分析器,结合数据字典(catalog)进行绑定,生成Analyzed逻辑计划,在此过程中,Schema Catalog则要提取Schema信息;
(3)使用Catalyst优化器对Analyzed逻辑计划进行优化,按照优化规则得到Optimized逻辑计划。
(4)接下来需要和Spark Planner进行交互,使用策略(strategy)到plan,使用Spark Planner将逻辑计划转换成物理计划,然后调取next函数,生成可执行物理计划。
(5)调用toDF,最后生成DataFrame。
4,Spark SQL特点
(1)数据兼容方面:不但兼容Hive,还可以从RDD、Parquet文件、JSON文件中获取数据。可以在Scala代码里访问Hive元数据,执行Hive语句,并且把结果取回作为RDD使用。支持Parquet文件的读写,且保留Schema。
(2)组件扩展方面:无论是SQL的语法解析器、分析器,还是优化器都可以重新定义,进行扩展。
(3)性能优化方面:除了采取内存列存储、动态字节码生成等优化技术,还采取了内存缓存数据。
(4)支持多种语言:包括Scala、Java、Python、R等,可以在Scala代码里写SQL,支持简单的SQL语法检查,能把RDD转化为DataFrame存储起来。
5,Spark SQL性能
Spark SQL兼容了Hive的大部分语法和UDF,在处理查询计划时,使用了Catalyst框架进行优化,优化成适合Spark编程模型的执行计划,其效率比Hive高出很多。
(1)内存列式存储。
Spark SQL使用内存列式模式(in-memory columnar format)缓存表,仅扫描需要的列,并且自动调整压缩比使内存使用率和GC压力最小化,如果缓存了数据,则再次执行时不需要重复读取数据。
(2)动态代码生成和字节码生成技术,提升了复杂表达式求值查询的速率。
如下查询:
SELECT a + b FROM table
在这个查询语句中,传统的处理方式,会生成一个表达式树,需要调用虚函数确认Add两边的数据类型,然后分别调用虚函数确认a和b的数据类型,并装箱,最后调用指定数据类型的Add,返回装箱后的计算结果。计算时多次涉及虚函数的调用,虚函数的调用会打断CPU的正常流水线处理,减缓执行速度。
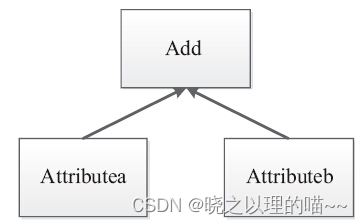
作为Spark SQL优化的一部分,已经实现了新的表达式计算,增加了codegen模块,Spark SQL在执行物理计划时,会对匹配的表达式采用特定的代码动态编译,能够为每个查询动态生成自定义字节码,然后运行。
内存列式存储和动态代码生成仅仅是冰山一角,存储方面还有很多需要提升,包括:改进的Parquet集成,自动查询半结构化数据(如JSON),通过JDBC访问Spark SQL等。针对Scala代码优化,当Java虚拟机(VM)发现内存资源紧张时,就会自动地清理无用对象(没有被引用到的对象)所占用的内存空间。在执行过程中,支持多种数据源,统一转化为DataFrames进行操作等。
二、DataFrame概述
1,DataFrame的概念
Spark SQL所使用的数据抽象并非RDD,而是DataFrame。DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,它不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。RDD是分布式的Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的。
DataFrame是一种以RDD为基础的分布式数据集,提供了详细的结构信息,就相当于关系数据库的一张表。DataFrame是以指定列(named columns)组织的分布式数据集合,在Spark SQL中,相当于关系数据库的一个表,或R/Python的一个data frame。DataFrame支持多种数据源构建,包括:结构化数据文件(Parquet、JSON)加载、Hive表读取、外部数据库读取、现有RDDs转化,以及通过SQLContext运行SQL查询结果。
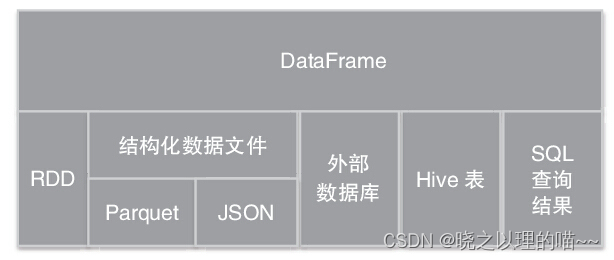
2,DataFrame和RDD的区别
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
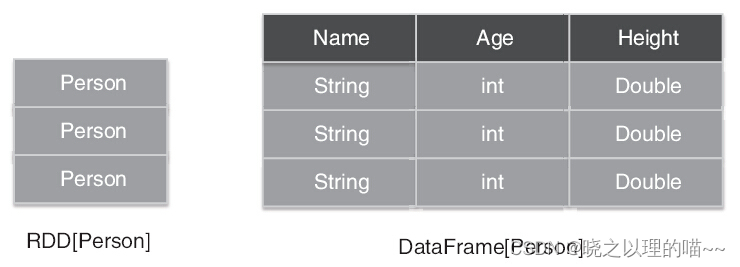
DataFrame使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅度提升运行时效率的目标。而RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在Stage层面进行简单、通用的流水线优化。
正如RDD的各种变换实际上只是在构造RDD DAG,DataFrame的各种变换同样也是惰性的。它们并不直接求出计算结果,而是将各种变换组装成与RDD DAG类似的逻辑查询计划,经过优化的逻辑执行计划被翻译为物理执行计划,并最终落实为RDD DAG。
3,创建DataFrame
(1)示例数据
people.txt,每行数据的组成方式是字符串、逗号、整数。
Michael, 29
Andy, 30
Justin, 19
people.json文件可以发现,里面放置的是一个有键值对(key:value)组成的JSON字符串,字符串和字符串之间被逗号隔开。
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
(2)创建DataFrame
使用sqlContext.read函数从JSON文件中创建一个DataFrame,并通过Show(DataFrame的Action操作)显示数据。
val sc: SparkContext // spark-shell默认SparkContext
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 创建DataFrame,变量$SparkHome指Spark的安装目录
scala> val df = sqlContext.read.json("file:// $SparkHome/examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
4,DataFrame操作
DataFrame操作分为Action、基础DataFrame函数(basic DataFrame functions)、集成语言查询(language lntegrated queries)、Output操作、RDD操作和Ungrouped等几类,具体可参考org.apache.spark.sql.DataFrame的API。
(1)DataFrameAction
常用的DataFrame的Action操作包括collect、count、first、head、show、take等.

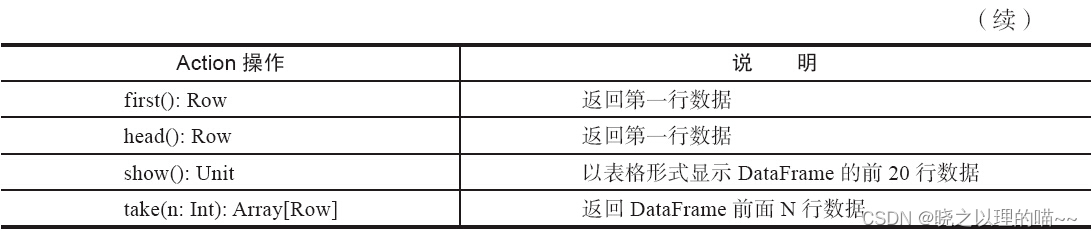
(2)基础DataFrame函数
基础DataFrame函数包括cache、columns、dtypes、explain、persist等.
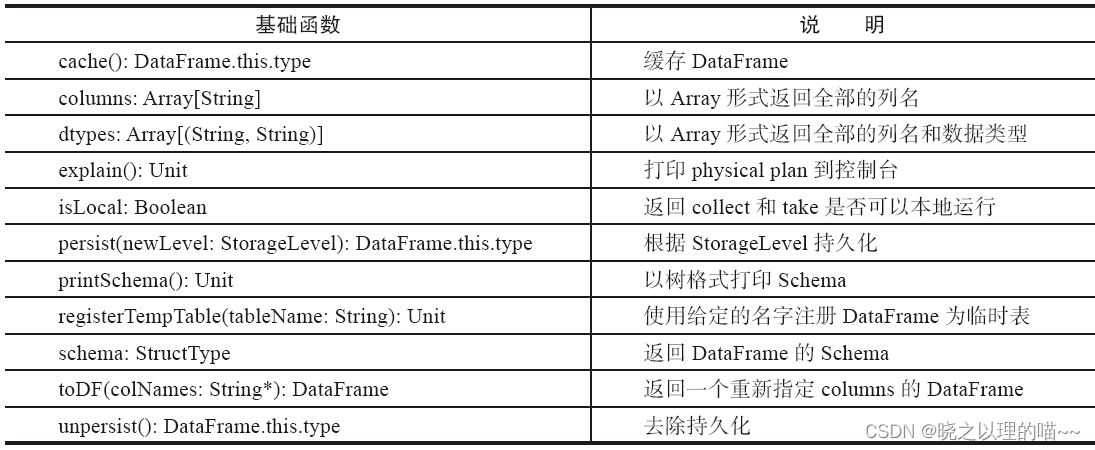
(3)集成语言查询
集成语言查询,参考SQL语句,如distinct、filter、groupBy、select、sort、where等.
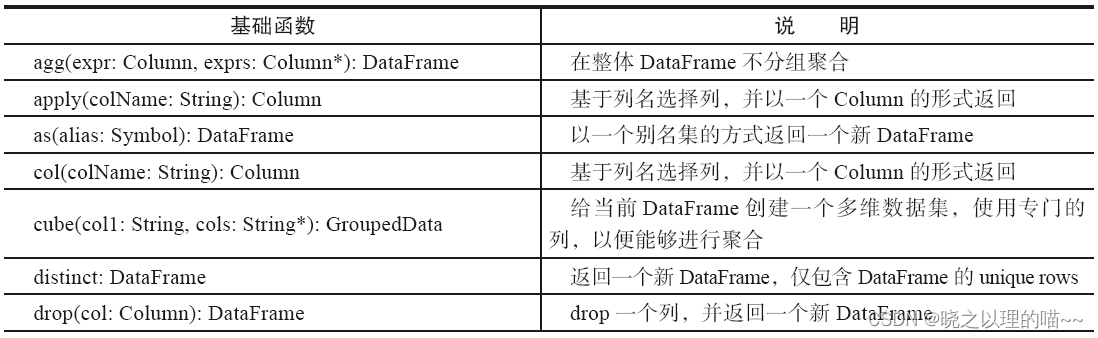
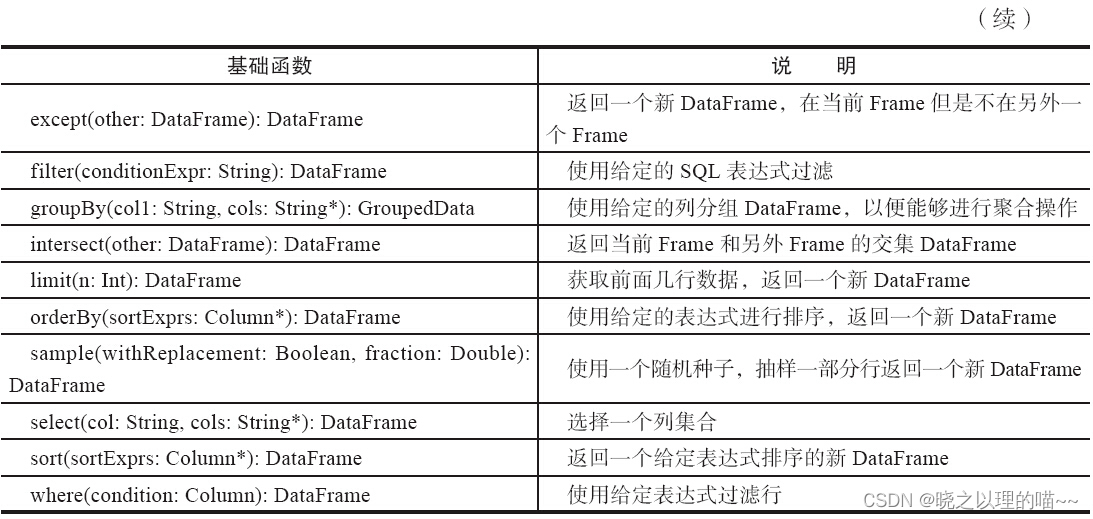
(4)输出操作和RDD操作
DataFrame采用write保存DataFrame内容到外部存储。
DataFrame本质上是一个拥有多个分区的RDD,支持一些RDD操作,包括:coalesce、flatMap、foreach、foreachPartition、javaRDD、map、mapPartitions、repartition、toJSON、toJavaRDD等。
(5)DataFrame执行后端优化
DataFrame可以说是整个Spark项目最核心的部分,在1.5版本这个开发周期内最大的变化就是Tungsten项目的第一阶段已经完成。主要的变化是由Spark自己来管理内存而不是使用JVM,这样可以避免JVM GC带来的性能损失。内存中的Java对象被存储成Spark自己的二进制格式,计算直接发生在二进制格式上,省去了序列化和反序列化时间。同时这种格式也更加紧凑,节省内存空间,而且能更好地估计数据量大小和内存使用情况。
如果想自己测试Tungsten第一阶段的性能,在1.5版本中spark.sql.tungsten.enabled默认为true,只需要修改这一个参数就可以配置是否开启Tungsten优化(默认是开启的)。
5,RDD转化为DataFrame
Spark SQL支持两种不同的方法将现有的RDD转化为DataFrame。
第一种方法使用反射机制来推断一个包含特定类型对象的RDD模式(schema),如果提前知道Spark应用程序的Schema,基于这种反射方式让代码变得更简洁。Spark SQL反射机制的核心思想是通过支持特定的RDD自动转换为DataFrame。
第二种方法是通过一个编程接口,允许构建一个Schema,然后应用到现有的RDD,这种基于编程接口的方法,允许在运行之前,列名及列类型未知时构建DataFrame。
(1)以反射机制推断RDD模式
Spark SQL的Scala接口支持自动转换一个包含case类的RDD为一个DataFrame。case类定义了表的Schema,使用反射读取case类的参数名为列名,case类也可以是嵌套的或包含复杂类型,如序列或数组。RDD可以隐式转换成一个DataFrame,并注册成一个表,表可以用于后续的SQL查询语句。
SQLContext的sql函数使应用程序运行SQL查询并返回结果DataFrame,只有存在case类时,会自动发生隐式转换,map操作的结果才能变成一个DataFrame。
转换过程有三个重点:
1)必须创建case类,只有case类才能隐式转换为DataFrame。
2)必须生成DataFrame,进行注册临时表操作。
3)必须在内存中register成临时表,才能供查询使用。
// 通过SparkContext创建SqlContext,并进行实例化
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 将一个RDD隐式转换为一个
DataFrameimport sqlContext.implicits._
// 使用case定义Schema(不能超过22个属性),实现Person接口
case class Person(name: String, age: Int)
// 读取文件创建一个MappedRDD,并将数据写入Person模式类,隐式转换为DataFrame, 注册作为
// 临时表,供查询使用。$SPARK_HOME指Spark文件目录,使用“file:// ...”标识的本地文件,
// 使用“hdfs:// ...”标识的HDFS存储系统的文件。
val people = sc.textFile("file:///$SPARK_HOME/examples/src/main/resources/people. txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
// DataFrame注册临时表
people.registerTempTable("peopletable")
// 使用sql运行SQL表达式val
result = sqlContext.sql("SELECT name, age FROM peopletable WHERE age >= 13 AND age <= 19")
// SQL 查询结果是DataFrames,通过索引和字段名访问,并进行RDD操作
result.map(t=>"Name:"+t(0)).collect().foreach(println)
result.map(t=>"Name:"+t.getAs[String]("name")).collect().foreach(println)
(2)以编程方式定义RDD模式
当匹配模式(Java的JavaBean类,Python的kwargs字典)不能被提前定义时(例如,记录结构被编码成一个字符串,或将要被解析的文本数据集,将为不同用户分别设计的属性).
一个DataFrame可以编程方式创建,主要有三个步骤:
1)从原始RDD中创建一个RowS的RDD。
2)创建一个表示为StructType类型的Schema,匹配在第1步创建的RDD的RowS的结构。
3)通过SQLContext提供的createDataFrame方法,应用Schema到RowS的RDD。
// 通过SparkContext创建了SqlContext,并进行实例化
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create an RDD
val people = sc.textFile("file:///$SPARK_HOME/examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// 导入Spark SQL 的Row 和data types
import org.apache.spark.sql.Row;
import org.apache.spark.sql.types.{StructType,StructField,StringType};
// 生成基于schemaString结构的schema
val schema =StructType(
schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
// Convert records of the RDD (people) to Rows.
val rowRDD = people.map(_.split(",")).map(p => Row(p(0), p(1).trim))
// 将自定义schema应用于RDD
val peopleDF = sqlContext.createDataFrame(rowRDD, schema)
// 注册为临时表people
peopleDF.registerTempTable("peopletable")
// 使用sql运行SQL表达式
val result = sqlContext.sql("SELECT name FROM peopletable")
result.map(t => "Name: " +t(0)).collect().foreach(println)
文章来源:《Spark核心技术与高级应用》 作者:于俊;向海;代其锋;马海平
文章内容仅供学习交流,如有侵犯,联系删除哦!
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











