








文章目录
What is Coreference Resolution
- 识别所有涉及到相同现实世界实体的 提及(指代)
例如




Applications
-
全文理解
- 信息抽取,问答,摘要,···
- “He was born in 1961” 如果没有共指消解,我们就不能知道 “He” 指的是谁
-
机器翻译
- 语言在性别、数字、零指代(dropped pronouns)等方面有不同的特点。
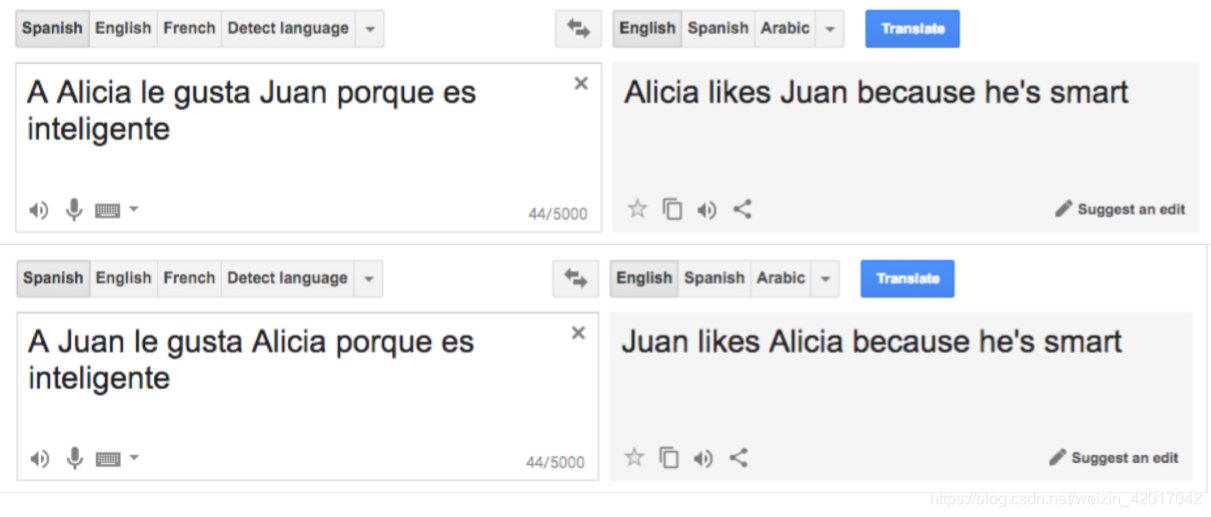
西班牙语在because句式中,可以省略主语,第二句话本应是 “Juan likes Alicia because she’s smart.”

土耳其语性别性比起英语少一些,在翻译成英语时对性别有些明显的偏差
- 语言在性别、数字、零指代(dropped pronouns)等方面有不同的特点。
-
对话系统

Coreference Resolution in Two Steps

Mention Detection
Mention:引用某个实体的文本范围(span)
有三种
- Pronouns: I, your, it, she, him, etc.
可使用词性标注 - Named entities:People, places, etc.
使用命名实体识别 - Noun phrases :“a dog,” “the big fluffy cat stuck in the tree”
Use a parser (especially a 依存解析器 constituency parser – next week!)
- 标记出所有的名词,命名实体和名词短语作为提及
- 这些都是提及吗?
- It is sunny 不是
- Every student 不是
- No student 不是
- The best donut in the world 存在争议
- 100 miles 不是
How to deal with these bad mentions?
- 可以训练一个分类器来过滤虚假的提及
- 更为常见的:保持所有 mentions 作为 “candidate mentions”
- 在你的共指系统运行完成后,丢弃所有的单个引用(即没有被标记为与其他任何东西共同引用的)
Can we avoid a pipelined system?
- 我们可以训练一个专门用于检测提及的分类器,而不是使用词性标注,命名实体识别和解析器
- 或者甚至联合提及检测和共指解析端到端完成,而不是分成两步
- 本节课接下来会覆盖到
some linguistics
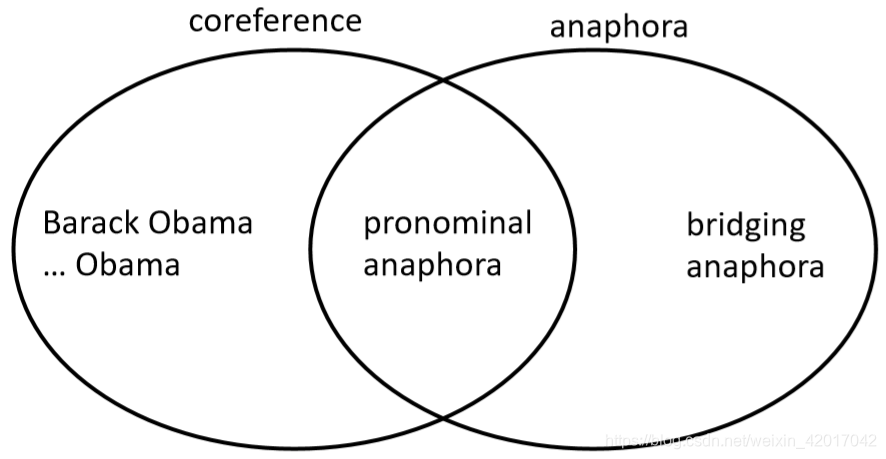
- Coreference 是两个 mention 指向现实世界中相同的实体
- 如:Barack Obama traveled to … Obama
- 一个相关的语言概念是回指(anaphora):当一个词(回指 anaphor )指另一个词(先行词 antecedent )时
- anaphor 的解释在某种程度上取决于 antecedent 先行词的解释

- anaphor 的解释在某种程度上取决于 antecedent 先行词的解释
Anaphora vs Coreference

- anaphora是一种 textural dependence.
Not all anaphoric relations are coreferential - 不是所有的名词短语都有指代 reference

- 这些句子每个有三个名词短语;因为第一个是非指称的,另外两个也不是。

- 如果将指代的格式放松一些,则这也是 anaphora,这称为 bridging anaphora
Anaphora vs. Cataphora
- 通常先行词在回指之前(例如代词),但并不总是

但在现代语法规则中,这种现象没有了
Four Kinds of Coreference Models
- Rule-based (pronominal anaphora resolution)
- Mention Pair
- Mention Ranking
- Clustering
Four Kinds of Coreference Models
- Rule-based (pronominal anaphora resolution)
- Mention Pair
- Mention Ranking
- Clustering
Traditional pronominal anaphora resolution:Hobbs’ naive algorithm
传统代词回指消解
- Begin at the NP immediately dominating the pronoun
- Go up tree to first NP or S. Call this X, and the path p.
- Traverse all branches below X to the left of p, left-to-right, breadth-first. Propose as antecedent any NP that has a NP or S between it and X
- If X is the highest S in the sentence, traverse the parse trees of the previous sentences in the order of recency. Traverse each tree left-to-right, breadth first. When an NP is encountered, propose as antecedent. If X not the highest node, go to step 5.
- From node X, go up the tree to the first NP or S. Call it X, and the path p.
- If X is an NP and the path p to X came from a non-head phrase of X (a specifieror adjunct, such as a possessive, PP, apposition, or relative clause), propose X as antecedent (The original said “did not pass through the N’ that X immediately dominates”, but the Penn Treebank grammar lacks N’ nodes….)
- Traverse all branches below X to the left of the path, in a leftto-right, breadth first manner. Propose any NP encountered as the antecedent
- If X is an S node, traverse all branches of X to the right of the path but do not go below any NP or S encountered. Propose any NP as the antecedent.
- Go to step 4
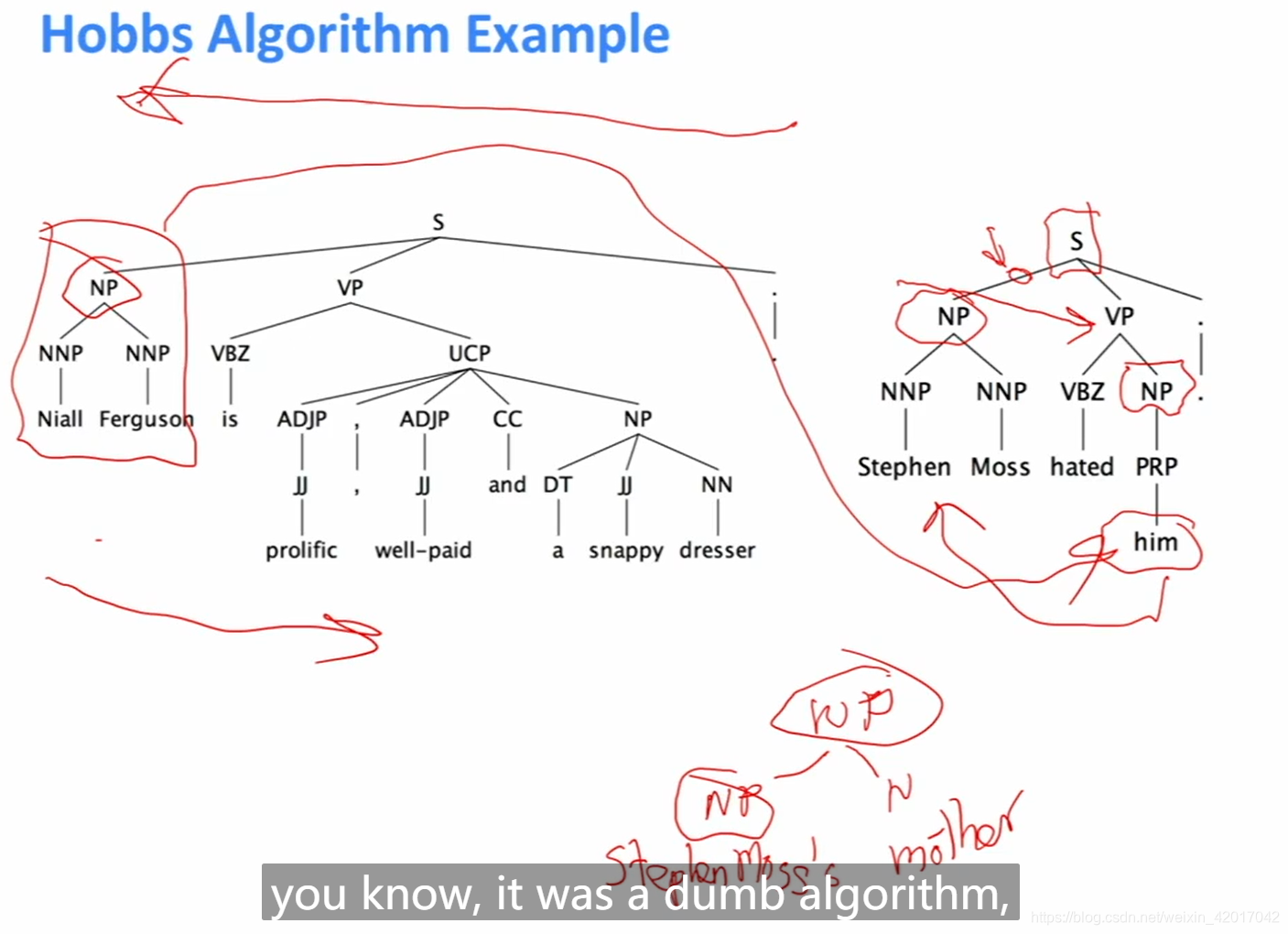
- 首先找回指所属的NP或S,若没有时,从右向左找前一个S,然后从找到的S或NP下,从左向右找NP,找到的第一个NP就是先行词。在上面例子中,得到了正确的结果,而在下面例子中Stephen Moss’s mother hated him. 这个就会出错。
- 这个方法被作者命名为 naive 算法,但是直到深度学习出现之前一直在ML系统中作为一个特征
- 这是一个很简单、但效果很好的共指消解的 baseline
Knowledge-based Pronominal Coreference

- 这两对例子是 Winograd 提出的。它们具有相同的结构,使用上面提到的算法,总是一个正确一个错误。

- 这个人提出,可以将共指问题作为图灵测试的一个选择,若完全解决了共指问题,可以说解决了 AI
Hobbs’ algorithm: commentary

Coreference Models: Mention Pair

- 训练一个二进制分类器,该分类器为每一对提及指定一个相互关联的概率:
p
(
m
i
,
m
j
)
p(m_i,m_j)
p(mi,mj)
- 例如,对于“she”,查看所有候选先行词(之前发生的提及),并决定哪些与之相关
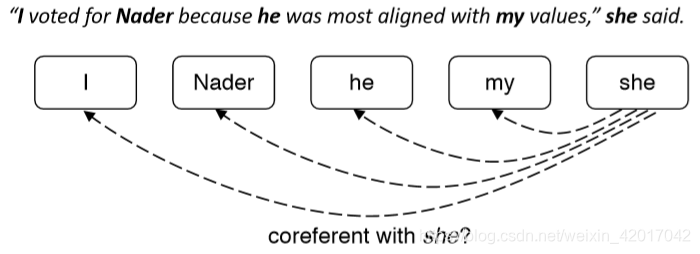
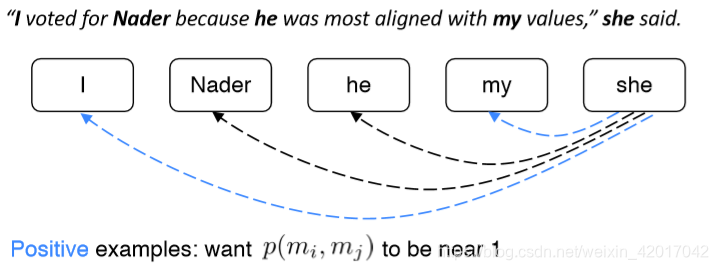
- 例如,对于“she”,查看所有候选先行词(之前发生的提及),并决定哪些与之相关
Mention Pair Training
- 文章有 N 个 mention
- 如果 m i m_i mi 和 m j m_j mj是共指的,则 y i j = 1 y_{ij} = 1 yij=1 ,否则 y i j = − 1 y_{ij} = -1 yij=−1
- 只是训练正常的交叉熵损失(看起来有点不同,因为它是二元分类)

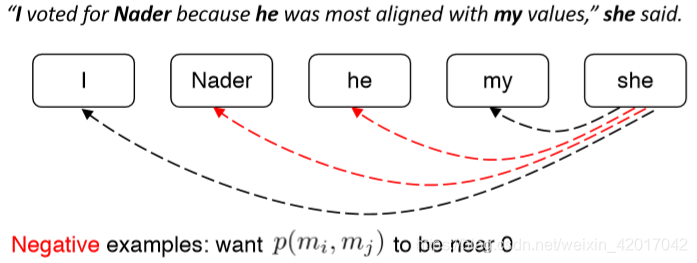
Mention Pair Test Time
- 共指消解是一项聚类任务,但是我们只是对 mentions 对进行了评分……该怎么办?
- 选择一些阈值(例如0.5),并将 p ( m i , m j ) p(m_i,m_j) p(mi,mj) 在阈值以上的 mentions 对之间添加共指链接
- 利用传递闭包得到聚类
- 可能会出现严重的错误
- 如果有一个共指 link 判断错误,就会导致两个 cluster 被错误地合并了
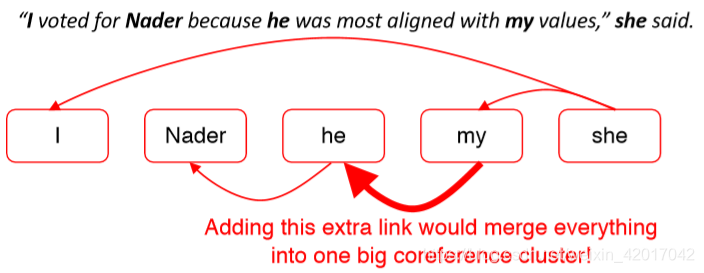
Mention Pair Models: Disadvantage
- 假设我们的长文档里有如下的 mentions

- 许多 mentions 只有一个清晰的先行词
- 但我们要求模型来预测所有先行词
- 解决方案:相反,训练模型为每个 mention 只预测一个先行词
- 在语言上更合理
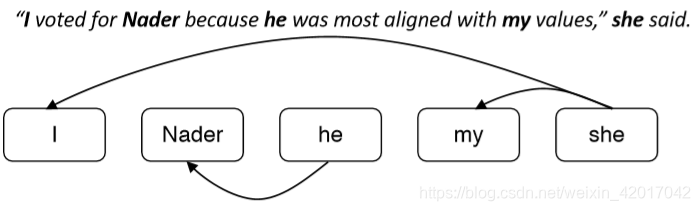
Coreference Models: Mention Ranking
- 根据模型把其得分最高的先行词分配给每个 mention
- 虚拟的 NA mention 允许模型拒绝将当前 mention 与任何内容联系起来(“singleton” or “first” mention)
- first mention: I 只能选择 NA 作为自己的先行词
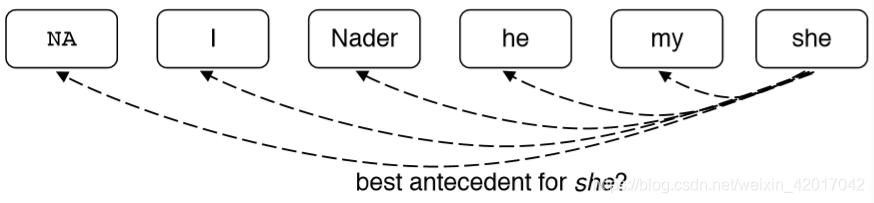
- first mention: I 只能选择 NA 作为自己的先行词
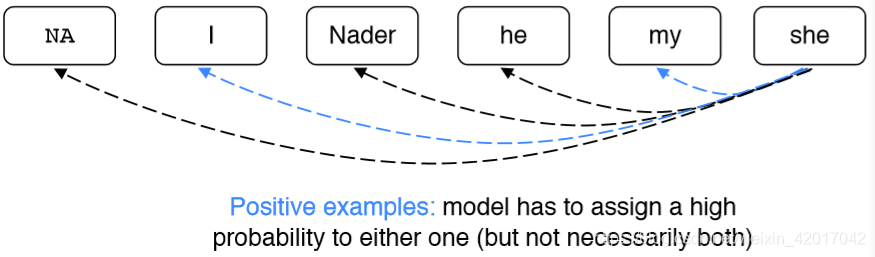
Coreference Models: Training
- 我们希望将当前 mention m j m_j mj 与它指代的先行词任意之一相关联
- 数学上,我们想要最大化下面的概率
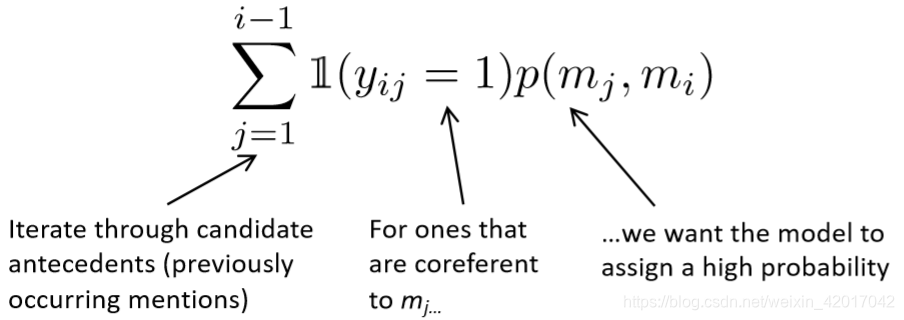
- 这个模型能够为正确的先行词之一产生0.9的概率,而对其他产生较小的概率,加和依旧很大
- 使用负对数似然,然后对所有 mention 迭代,将其转化为损失函数,如下
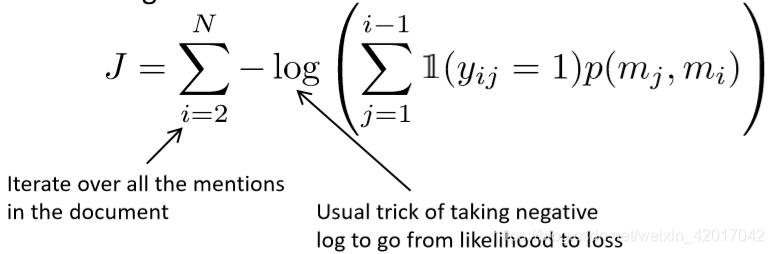
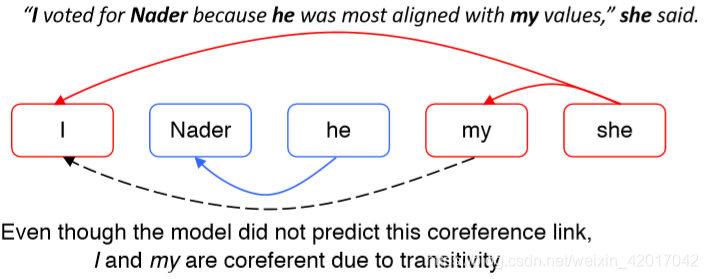
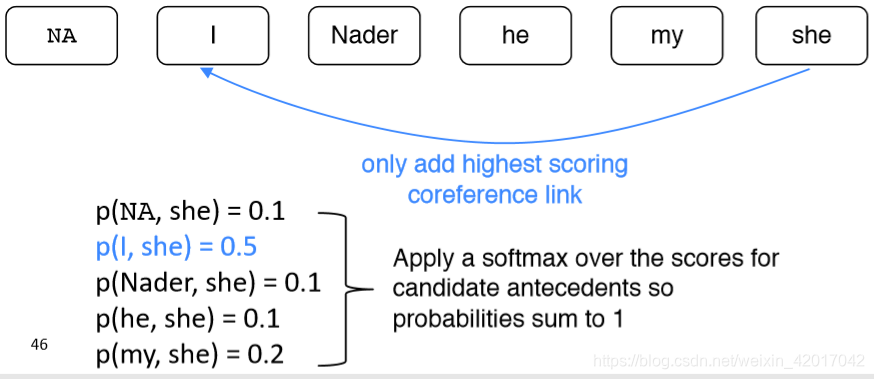
Mention Ranking Models: Test Time
和 mention-pair 模型很类似,只是每个 mention 只分配一个先行词
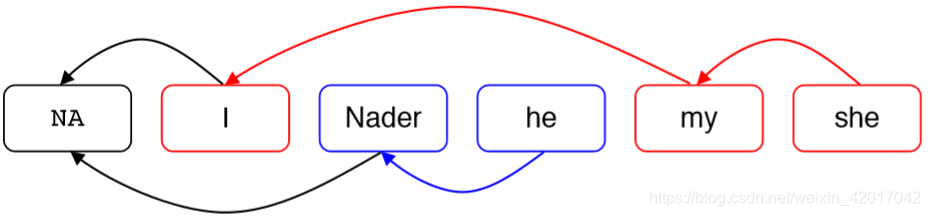
- NA相当于阻断,所有与NA相连的 mention 不需要 cluster 到一个组
How do we compute the probabilities?
有三种方法
A. Non-neural statistical classifier
B. Simple neural network
C. More advanced model using LSTMs, attention
A. Non-neural statistical classifier

- 人物/数字/性别 要一致:如上面例子中使用了性别就判断出来了正确的先行词
- 语义相容性:两个名词短语指的同一个东西,可以使用 word2vec 词向量的距离等
- 某些句法约束:比如上面例子举得就是使用我们之前提到的算法(Hobbs’ naive algorithm),这个算法在很多机器学习分类器中作为一个重要的特征来使用,经常会赋予其很大的权重。
- 最近提到的实体优先供参考
- 语法角色
- 排比
B. Neural CorefModel
- 标准的前馈神经网络
- 输入层:词向量和一些类别特征
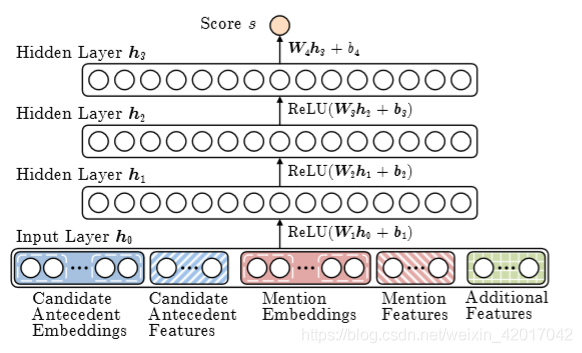
- 输入层:词向量和一些类别特征
- 嵌入:每个 mention 的前两个词,第一个词,最后一个词, head word
- head word 是 mention 最重要的词,可以使用 parser来找到它
- 例如:The fluffy cat stuck in the tree
- 仍然需要一些其他特征
- 距离、文档类型、说话人信息
C. End-to-end Model
- 当前最优的共指消解模型(Kenton Lee et al. from UW, EMNLP 2017)
- mention 排名模型
- 在简单前馈网络上提升
- 使用LSTM
- 使用attention
- 将 mention 检测和消解端到端
- 没有 mention 检测步骤
- 取而代之的是,把每一段(span)文字(达到一定长度)都看作是候选 mention
- 一个 span 只是一个连续的词序列
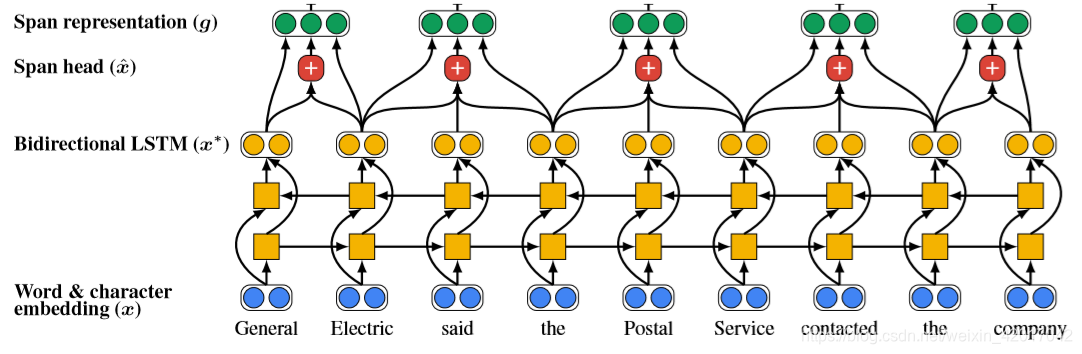
- 首先将文章中的单词使用词嵌入和字符级别获得的CNN嵌入拼接在一起
- 然后通过一个双向LSTM
- 最后将文章 i 的每个 span,从
S
T
A
R
T
(
i
)
START(i)
START(i) 到
E
N
D
(
i
)
END(i)
END(i),表示成一个向量
- 例如,上图中 G e n e r a l , G e n e r a l E l e c t r i c , G e n e r a l E l e c t r i c s a i d , … E l e c t r i c , E l e c t r i c s a i d , … General, General Electric, General Electric said, …Electric, Electric said, … General,GeneralElectric,GeneralElectricsaid,…Electric,Electricsaid,…都会获得其表示
- span表示主要由三部分组成 ,如 “the postal service”
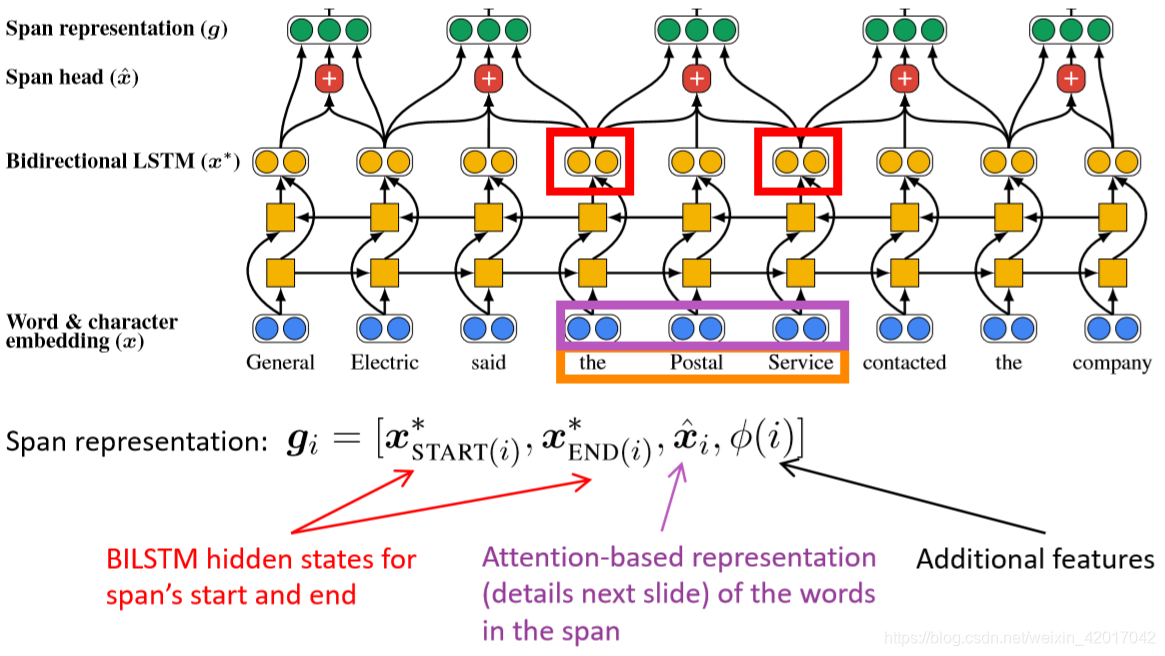
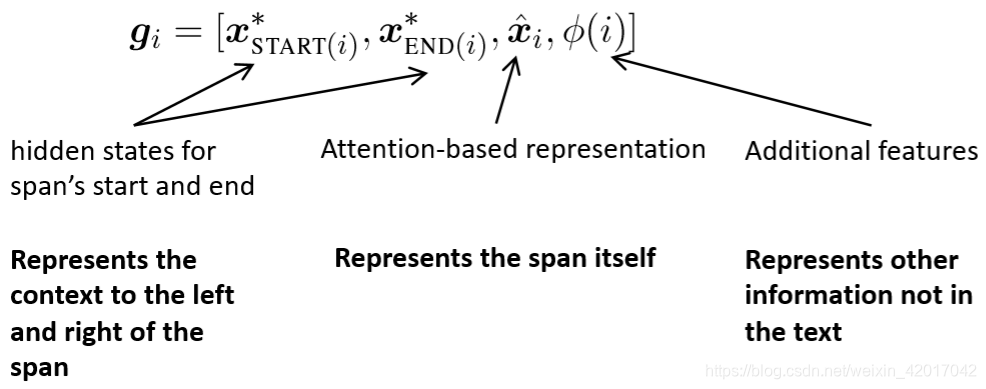
- 其中
x
^
i
\hat x_i
x^i是span范围内使用注意力权值对词向量的一个加和。

- 为什么要包含所有这些不同的项?
最后,对每对 span 打分,来决定它们是否是coreferent mentions

- 打分函数将 span 表示作为输入

- 很难给每一对 span 打分
- 一共有 O ( T 2 ) O(T^2) O(T2)个 span 在一片文章中(T是单词的个数)
- 运行时复杂度为 O ( T 4 ) O(T^4) O(T4)
- 所以必须做大量的剪枝工作(只考虑一些可能是 mention 的 span)
- attention学习了在一个 mention 中,哪些词可能是重要的(有点像 head words)
Clustering-Based
-
共指是个聚类任务,我们可以使用聚类算法解决
- 尤其应该使用 合并聚类 (agglomerative clustering )
-
开始时,每个 mention 在自己单独的集群中
-
在每一步融合一对集群
- 使用一个模型来评分哪些集群合并是好的
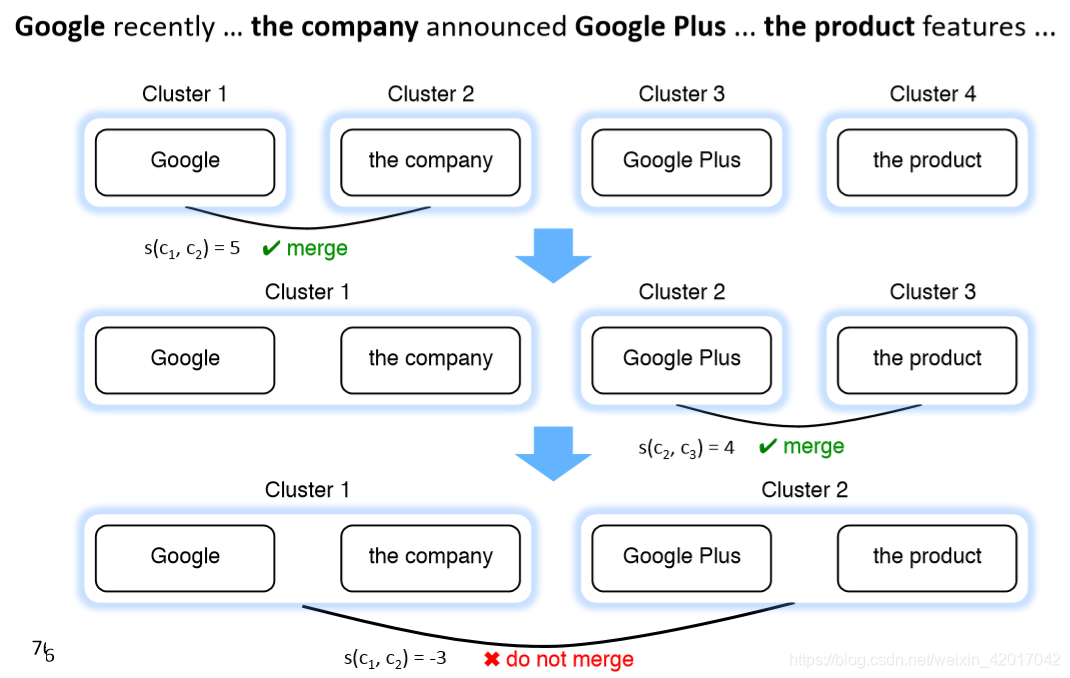
- 使用一个模型来评分哪些集群合并是好的
-
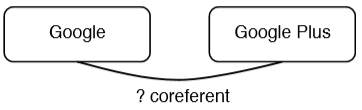
Mention-pair 决定是困难的
-
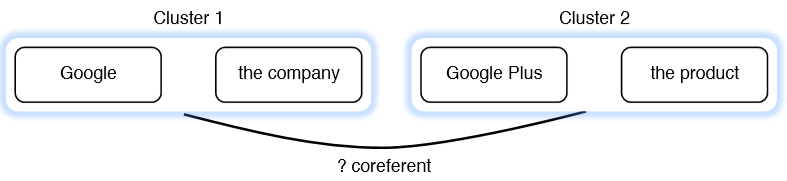
Cluster-pair 决定是容易的
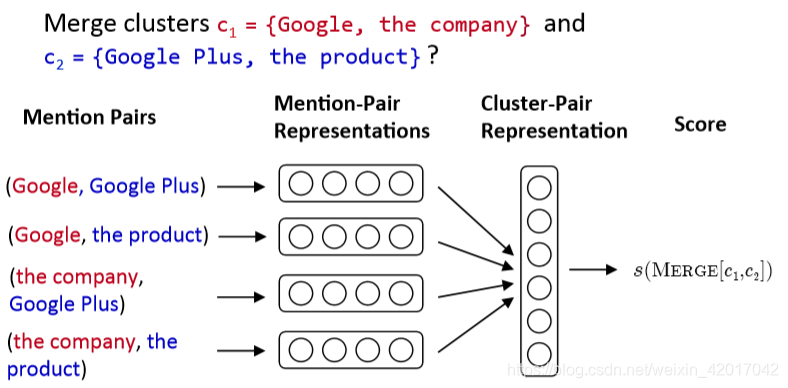
Clustering Model Architecture
From Clark & Manning, 2016
-
首先为每一对 mention 产生一个向量
- 例如,使用前馈神经网络模型隐藏层的输出
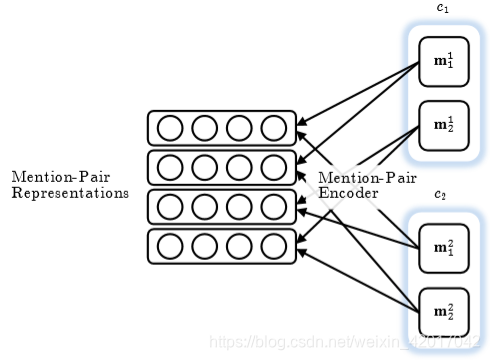
- 例如,使用前馈神经网络模型隐藏层的输出
-
接着将池化操作应用于 mentino-pair 表示的矩阵上,得到一个 cluster-pair 聚类对的表示
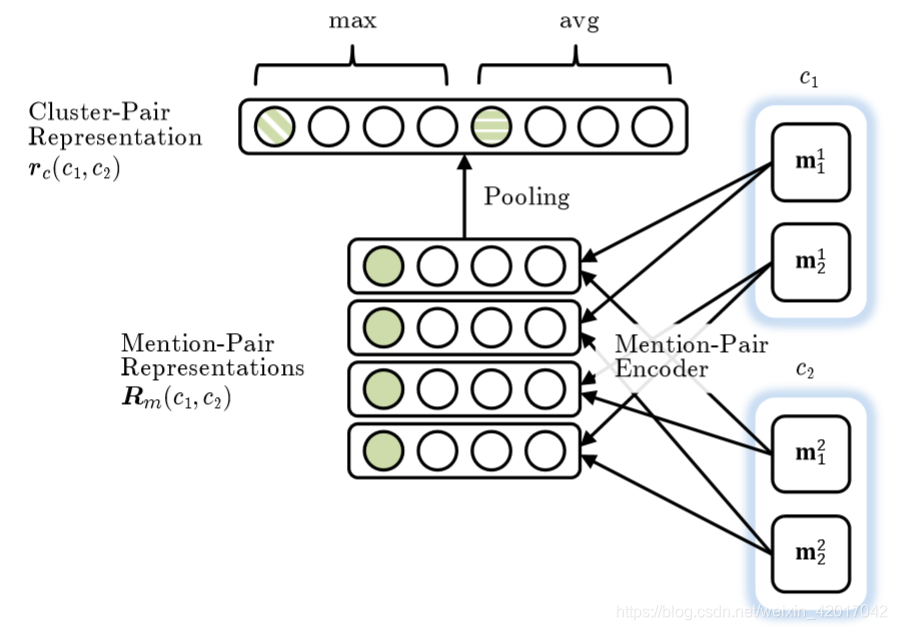
-
用加权向量表示的点积对候选聚类合并进行评分

Clustering Model: Training
- 当前候选群集合并依赖于它以前进行的合并
- 所以不能使用常规的监督学习
- 而是应该使用像强化学习之类的方法去训练模型
- 每次合并的奖励:共指评价指标的变化
Coreference Evaluation
- 有很多评测指标:MUC, CEAF, LEA, B-CUBED, BLANC
- 经常报告几个不同指标的平均值
- 这里介绍下B-cubed
- 对于每个 mention,计算一个精确率和一个召回率
- 然后平均每个Ps和Rs
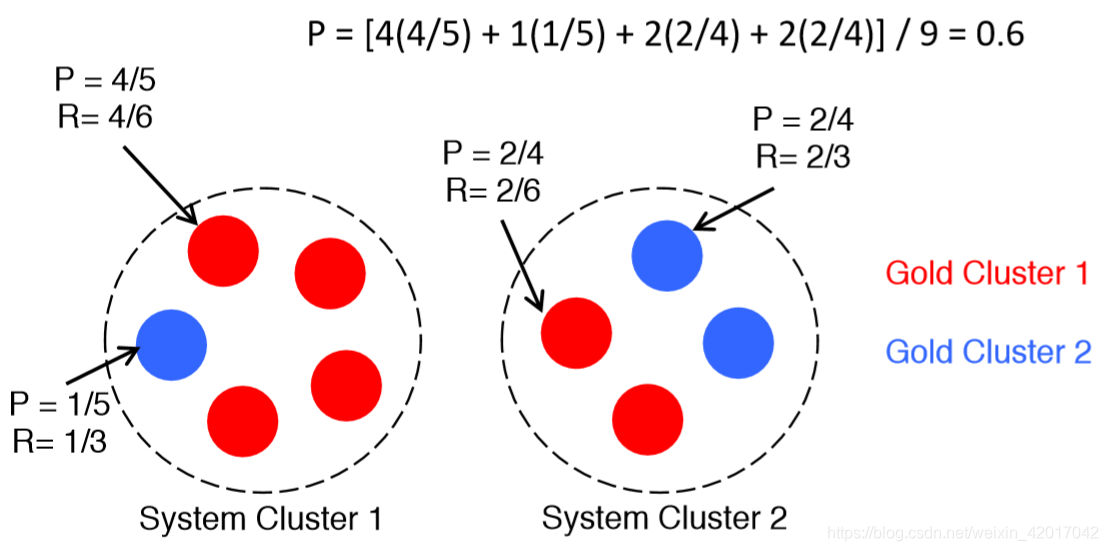
- 两种极端
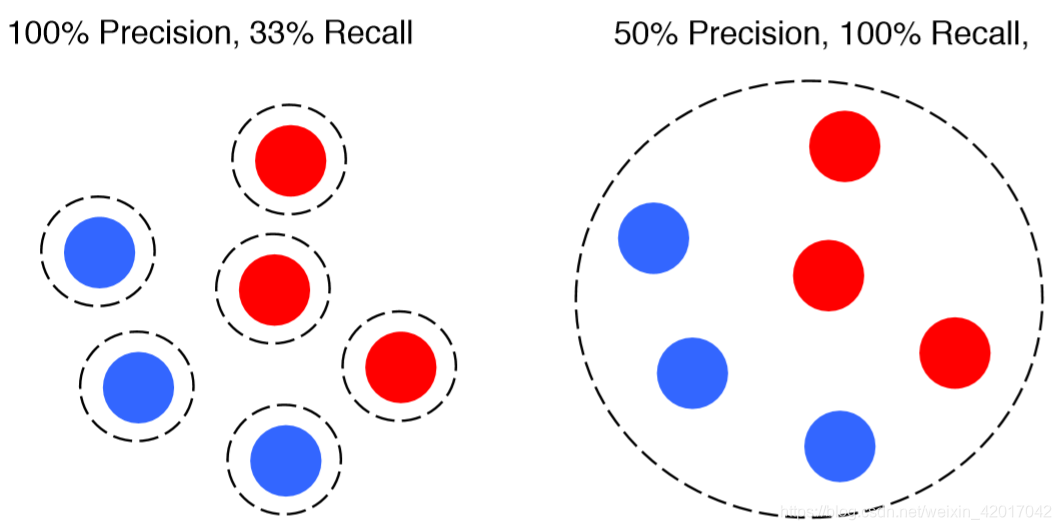
因此需要在准确率和召回率进行折衷
System Performance
- OntoNotesdataset: ~3000 documents labeled by humans
- English and Chinese data
- 报告一个在超过三个共指评测指标上的F1分数
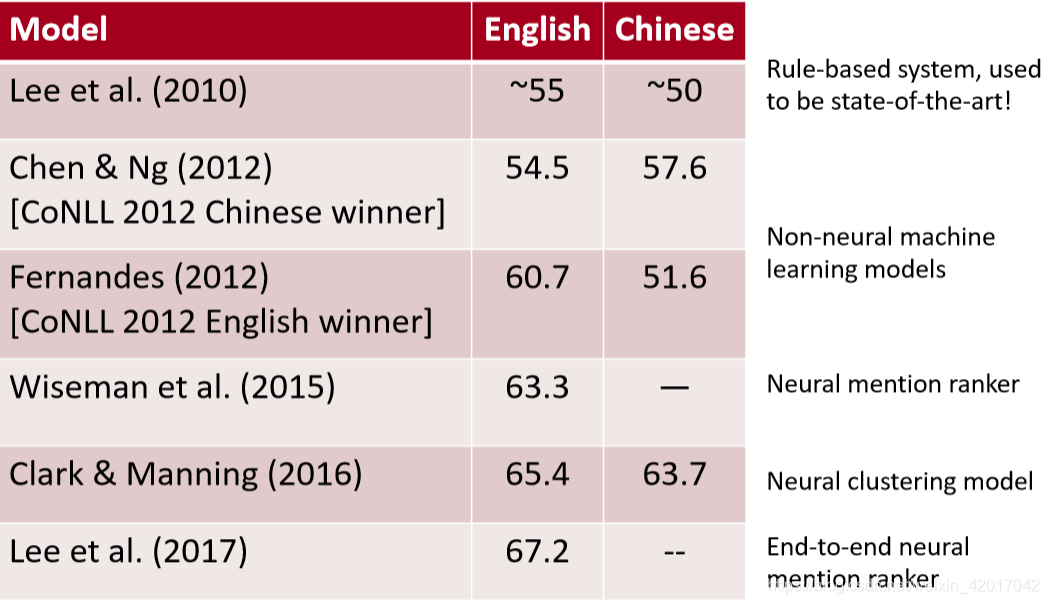
- 从目前的最好结果的评分来看,共指消解是一个很困难的问题。
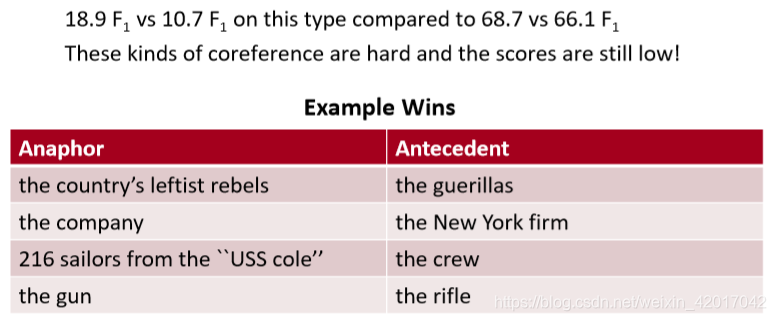
Where do neural scoring models help?
尤其是对于NPs和没有字符串匹配的命名实体。
神经网络得分 VS 无神经网络得分
Conclusion
- 共指是一个有用的、具有挑战性和有趣的语言任务
- 许多不同种类的算法系统
- 系统迅速好转,很大程度上是由于更好的神经模型
- 但总的来说,还没有惊人的结果
- Try out a coreference system yourself
- http://corenlp.run/ (ask for coref in Annotations)
- https://huggingface.co/coref/
总结
- 本节课比较简单(虽然讲义页数很多。。)
- 首先介绍了共指消解的定义,以及在各种NLP任务中的应用
- 共指消解分为两个步骤:mention 检测、共指消解
- mention检测有三种:名词(使用词性标注)、命名实体(使用命名实体识别系统)、名词短语(使用解析器),也可以训练一个分类器来直接确定每个词是否是 mention
- 语言学知识:Anaphora vs. Coreference
- anaphora 指上下文有关联
- coreference 指两个实体指的是同一个事物,与是否在上下文无关,如 特朗普—美国当前的总统
- 四种 coreference模型
- 基于规则(Hobbs’ naive algorithm)
- Mention Pair :训练一个分类器,对每个 mention 判断在其之前的所有 mention 是否是其coreference,然后最后聚类一下
- Mention Ranking :训练一个分类器,对每个 mention 只指定一个 可能性最大的 mention最为其coreference
- 如何对 两个 mention 是否为 coreference 进行打分的方法
- 三种:Non-neural statistical classifier、Simple neural network、More advanced model using LSTMs, attention
- More advanced model using LSTMs, attention:取span的三部分作为对 mention 的表示,使用注意力来编码span中的 head word,最后再进行打分
- Clustering:每次合并一对 cluster
- 评测指标: MUC, CEAF, LEA, B-CUBED, BLANC
- 最后:共指消解问题很难,依旧没有很好的解决


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









