







Richard Socher
Motivation
What’s next for NLP & AI?

- NLP发展历史:基于特征工程的机器学习方法,使用深度学习来学习特征(用向量表示词),对特定任务的深度学习架构,接下来是什么····
The Limits of Single-task Learning
- 给出{数据,任务,模型,评测}之后,在某些特定任务中近些年进步很大
- 只要 |数据量| > 1000 × C,那么我们就能获得局部最优的结果,
C
C
C为类别数目
- 如imageNet有1000个类,每个类别有1000张图片,目前已经做的很好
- 对于更一般的人工智能,我们需要在一个模型中不断学习
- 模型通常是从随机开始的,或者只是部分预先训练过的——> 😟
Pre-training and sharing knowledge is great!
计算机视觉:
- ImageNet + CNN ——> huge success

- 分类是视觉上的障碍:如果你甚至都不能把一只猫和一个人区分出来,其他任务就更加难做
NLP:
- Word2Vec,GloVe,Cove,ELMo,BERT ——>beginning success
- 单纯的词向量到后来具有上下文表示的词向量

- 单纯的词向量到后来具有上下文表示的词向量
- 自然语言处理中没有单独的阻碍任务
- 为什么不预训练整个模型呢?
Why has weight & model sharing not happened as much in NLP?
- NLP需要多种推理:逻辑,语言,情感,视觉,++
- 需要短期和长期记忆
- NLP被分为中间任务和单独任务以取得进展
- 在每个社区中追逐基准
- 例如:当你问 general answer 社区,“这条推特的情感如何?”
他们竟然无法回答,说这是情感分析的内容,但这确实是一个问题。
- 一个无人监督的任务可以解决所有问题吗?不可以
- 语言显然需要监督
- 如果一个小孩在一个森林里,那么他可能会对视觉方面发展出非常好的能力,而学不会某种语言
Why a unified multi-task model for NLP?
- 多任务学习是一般NLP系统的阻碍
- 统一模型可以决定如何转移知识(领域适应,权重分享,转移和零射击学习)
- 之前是人工决定,比如说如果要进行命名实体识别,那么如果一个词是名词,那么它就更有可能是一个实体。而使用一个模型,那么它将能够自己决定知识的迁移
- 统一的多任务模型可以
- 更容易适应新任务
- 使部署到生产环境的过程简单数倍
- 降低标准,让更多人解决新任务
- 潜在地转向持续学习
模型构建
How to express many NLP tasks in the same framework?
- 序列标记
命名实体识别,aspect specific sentiment:在一个特定的上下文中,判断一个词是积极的还是消极的 - 文本分类
对话状态跟踪,情感分类 - Seq2seq
机器翻译,摘要,问答
3 equivalent Supertasks of NLP

The Natural Language Decathlon (decaNLP)

- 将十个任务都写成QA的形式,然后统一训练,与测试。
Multitask Learning as Question Answering

- Meta-Supervised learning 元监督学习 :From { x , y } t o { x , t , y } \{x,y\} to \{x,t,y\} {x,y}to{x,t,y} (t 是一个任务)
- 使用问题 q 作为任务 t 的自然描述,以使模型使用语言信息来连接任务
- y 是 q 的答案,x 是回答 q 所必需的上下文
Designing a model for decaNLP
需求:
- 没有任务特定的模块或参数,因为我们假设任务ID是未提供的
- 必须能够在内部进行调整以执行不同的任务
- 应该为看不见的任务留下零射击推断的可能性
- 让模型内部自己去学习,而不是在一开始使用分类器,然后调用子模块去解决不同问题。
A Multitask Question Answering Network for decaNLP
overview

- 以一段上下文开始
- 问一个问题
- 一次生成答案的一个单词,通过
- 指向上下文
- 指向问题
- 或者从额外的词汇表中选择一个单词
- 指针开关为每个输出字选择这三个选项
Multitask Question Answering Network (MQAN)

- code和leaderboard见 www.decaNLP.com
- 整个模型将当前深度学习NLP中所有最佳的组件组合在一起
- 固定的Glove词向量(后来更新为CoVe词向量)+ Charactern-gram embeddings → Linear → Shared BiLSTMwith skip connection
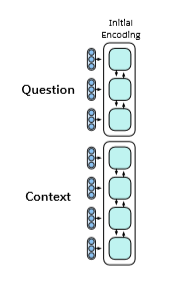
- 从一个序列到另一个序列再到带有跳过连接的序列的注意力总和
- 这两个序列所有隐藏层状态的外积

- 单独的BiLSTM降低维度,两个 Transformer 层,另一个BiLSTM

- 自回归译码器使用固定 GloVe 和字符n-gram嵌入、两个Transformer 层和一个LSTM层来处理编码器最后三层的输出

- LSTM解码器状态用于计算上下文上的注意力分布和用作指针的问题

- 关注上下文和问题会影响两个开关:gamma决定是从外部词汇表中复制还是选择,lambda决定是从上下文还是问题中复制

评测与结果分析


- decaScore是其他特定任务评分的加和

- S2S = Seq2Seq
- +SelfAtt = plus self attention
- +CoAtt = plus coattention
- +QPtr= plus question pointer == MQAN
- 左边是单任务,右边是多任务。左边虽然是同样的架构,但左边相当于40个模型,右边只有4个模型。

- 单任务转为多任务时,一开始性能会下降(在论文中很少见,因为如果结果不好一般不会被发表)。还有,如果序列训练不同的任务,一般会认为在训练后面任务时,模型会将之前的任务“忘掉”,但实验发现,虽然会忘掉一些,但只需很少的训练,模型在这个任务上就又会表现良好。
- Transformer 层在单任务和多任务设置中有收益
- QA和SRL有很强的关联性(看QA和SRL两行数据)
- Pointing很重要(看MultiNLI单任务最后三个数字,和Winograd Schemas任务)
- 多任务有助于zero-shot(QA-ZRE行)
- 组合的单任务模型和单个多任务模型之间存在差距
Training Strategies: Fully Joint


- 按照顺序,每次从一个Task中取出一个mini-batch来训练
Training Strategies: Anti-Curriculum Pre-training





- 首先在困难的任务中进行训练(红色的任务)(例如SQuAD和机器翻译),然后加入简单的任务。
- 困难: 在单任务设置中收敛多少次迭代
- 对比 fully joint 方式,anti-curriculum 训练提高了QA任务的性能,但MT 性能依旧很差
- 一个解释:其他任务只需要使用 answer module 从得到的隐藏层表示中指出答案,而 MT需要在一个很大的词表上使用softmax来生成结果,因为其他任务训练得到的 softmax 对于MT来说可能不太有用
Closing the Gap: Some Recent Experiments

- 经过一系列优化(变换训练方式、更换词向量、在MT上训练更多),最终MQAN总分与单独的十个模型分数总和只差了一个点

Pretraining on decaNLPimproves final performance
- 例如:增加 IWSLT 语言对
- 或者新的任务,比如命名实体识别

- 都能在短时间内快速收敛,并且预训练会提高模型表现
Zero-Shot Domain Adaptation of pretrained MQAN
- 在 Amazon 和 Yelp reviews 上实现了80%的准确率
- 在 SNLI上实现了 62%的准确率(经过 fine-tuning可以达到 87%的准确率)
Zero-Shot Classification
- question pointer能够使模型可选择的从问题中找出答案,而不经过任何fine-tuning(例如,将标签 positive 转为 happy/supportive,将 negative 转为 sad/unsupportive)
- 能使模型不经过任何训练就能回应新的任务

decaNLP: A Benchmark for Generalized NLP
- 为多NLP任务(问题)训练一个单独的问答模型
- 需要处理的框架
- 更泛化的语言理解
- 多任务学习
- 领域适应(domain adaptation )
- 迁移学习
- 权重分享、预训练、微调
- zero-shot 学习
Related Work (tiny subset)

What’s next for NLP?

总结
- 作者提出了继机器学习、深度学习、对特定任务研究特定的神经网络架构之后,单个多任务模型是以后研究的热点
- 讲了一个模型,将十个任务混合在一起,组织成统一的QA模式。
- 对具体模型分别训练,和将所有任务混合在一起训练进行了对比,起初两者差距很大,后来进行了一系列优化使得两种方式的性能都提高了,并且两者分差不大
- 作者的思想是,构建一个更加泛化的模型,不同任务学习到的知识可能能够相互促进。其中包含了很多要处理的问题:多任务学习、领域适应、迁移学习、权重分享等等。















 2039
2039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









