







前言:
机器学习很大一个问题是可解释性较差,虽然在RandomForest、LightGBM等算法中,均有feature_importance可以展现模型最重要的N个特征,但是对于单个样本来说情况可能并不与整体模型一致,所以就需要使用SHAP等算法将每个样本中不同特征的贡献度用数值展现出来。
对于SHAP算法的原理和其它同类算法可以看这2篇博客:
https://blog.csdn.net/weixin_41968505/article/details/119885046
https://zhuanlan.zhihu.com/p/100458526
本文主要使用SHAP完成每个样本不同特征的贡献度计算,并写了个简单的脚本把前N个重要特征提取出来。
准备工作:
首先还是需要传统的数据清洗、建模等,记得安装和导入shap库
pip install shap
注:我安装的shap版本是0.40.0,所有如果你的版本和我不一致,可能会导致后续代码略有差别。
所有样本的shap计算:
我这边的model是lightgbm,也就是树模型,所以使用的是shap.TreeExplainer
import shap
explainer = shap.TreeExplainer(model) #这里的model在准备工作中已经完成建模,模型名称就是model
shap_values = explainer.shap_values(test_data[predictors]) #这里的test_data是我的测试集,predictors是X_train的变量
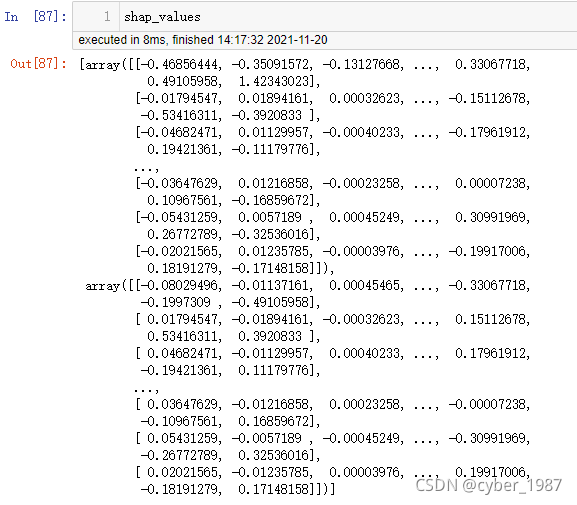
在我的版本里,shap_values是一个list,里面有2个array,第一个array是负向结果的SHAP值,而第二个array是正向结果的SHAP值,需要根据不同的业务场景选择不同的array。
在本次测试中,我做的model是宽带离网预测模型,所以我选择的是第一个array。
注:在做shap计算前,建议仅把有正样本(比如精准营销的话,就是把潜在客户)放入其中,因为shap的计算真的非常慢,我10000个样本跑了大概7分钟。
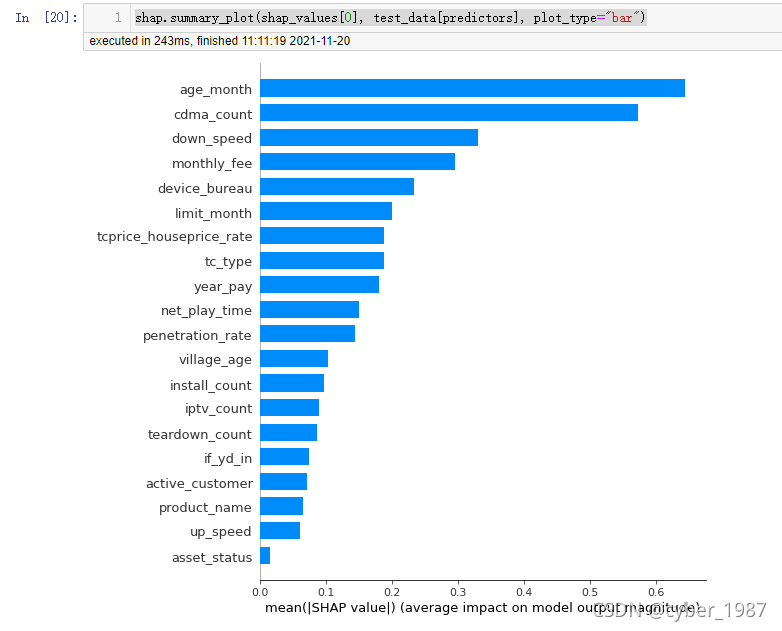
1)、可以输入下列代码显示和feature_importance类似的图片,只是同步会告诉我们不同特征的shap值取值范围是多少。
shap.summary_plot(shap_values[0], test_data[predictors], plot_type="bar")
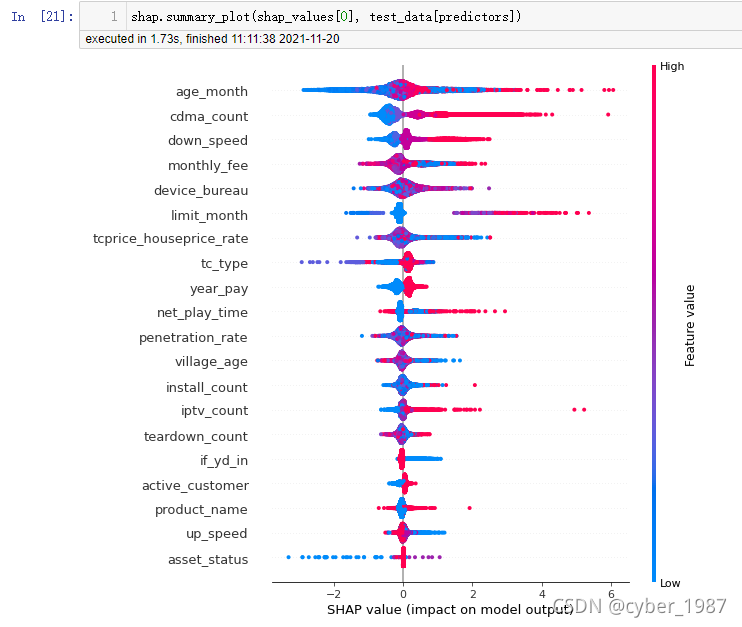
2)、这是另一种可视化
shap.summary_plot(shap_values[0], test_data[predictors])
获得单个样本的TOP N 特征值和对应的SHAP值
总算到正文了,我写成了一个函数,参数主要包括:
old_list:shap_value中某个array的单个元素(类型是list),这里我选择的是array[0]中的590元素
features: 与old_list的列数相同,主要用于输出的特征能让人看得懂
top_num:展示前N个最重要的特征
min_value: 限制了shap值的最小值
def get_topN_reason(old_list,features=predictors[:22],top_num=3, min_value=0.0):
#输出shap值最高的N个标签
feature_importance_dict = {}
for i, f in zip(old_list, features):
feature_importance_dict[f] = i
new_dict = dict(sorted(feature_importance_dict.items(), key=lambda e: e[1],reverse=True))
return_dict = {}
for k, v in new_dict.items():
if top_num>0:
if v>=min_value:
return_dict[k] = v
top_num -= 1
else:
break
else:
break
return return_dict
print(get_topN_reason(shap_values[0][590]))
结果:
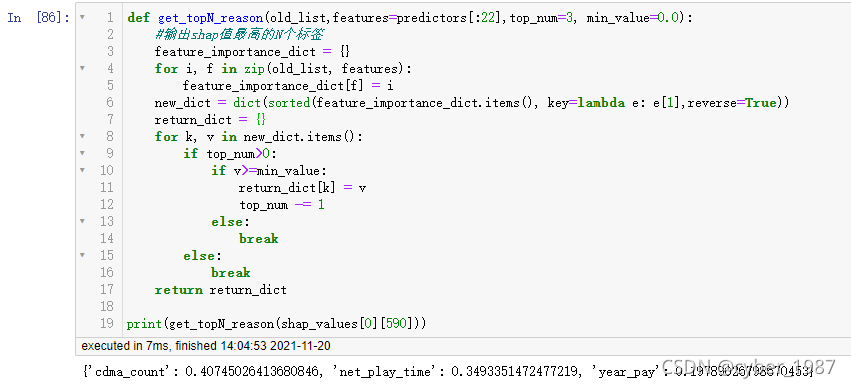
注1:可以简单改造后变成输出值为dataframe的形式,更进一步则是与原有特征的值结合,因为shap值只能作为排序和筛选,真正要让数据使用者理解,还是要转化业务能够理解的内容,比如“cdma_count(当月移动活跃设备数):2”,“net_play_time(上网时长):1”,“year_pay(是否年付):0”
注2:在模型训练中,很多特征并不都是可解释的,但是在训练过程中会很有用,所以在可解释性和实用性上需要平衡和取舍。

















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









