







字符串匹配怎么能少了大名鼎鼎的kmp算法呢?
概念:
好前缀:直到遇到坏字符为止,最长的前缀子串。
好前缀的所有后缀子串中,最长的可匹配前缀子串的那个后缀子串,叫作最长可匹配后缀子串;对应的前缀子串,叫作最长可匹配前缀子串
直接上思路:
1.KMP算法和bm算法完全相反,kmp算法采用从前到后进行比较。
2.kmp算法主要是为了找:最长可匹配后缀子串(最长可匹配前缀子串)。
3.KMP 算法也可以提前构建一个数组,用来存储模式串中每个前缀(这些前缀都有可能是好前缀)的最长可匹配前缀子串的结尾字符下标。我们把这个数组定义为 next 数组。做预处理操作时,不需要主串,只需要模式串。
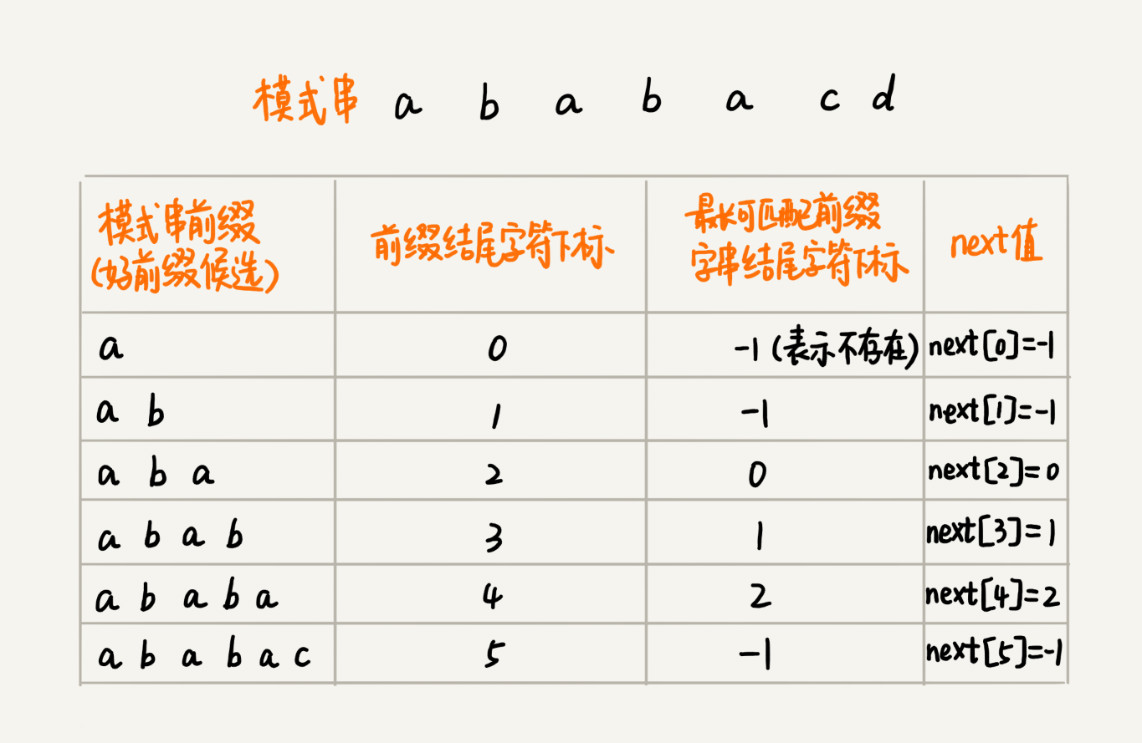
4.有了 next 数组,我们很容易就可以实现 KMP 算法了。
直接上代码:
// a, b分别是主串和模式串;n, m分别是主串和模式串的长度。
public static int kmp(char[] a, int n, char[] b, int m) {
int[] next = getNexts(b, m);
int j = 0;
for (int i = 0; i < n; ++i) {
while (j > 0 && a[i] != b[j]) { // 一直找到a[i]和b[j]
j = next[j - 1] + 1;
}
if (a[i] == b[j]) {
++j;
}
if (j == m) { // 找到匹配模式串的了
return i - m + 1;
}
}
return -1;
}下面到了最难的部分,构建next数组思路如下:
1.如果 next[i-1]=k-1,也就是说,子串 b[0, k-1]是 b[0, i-1]的最长可匹配前缀子串。如果子串 b[0, k-1]的下一个字符 b[k],与 b[0, i-1]的下一个字符 b[i]匹配,那子串 b[0, k]就是 b[0, i]的最长可匹配前缀子串。所以,next[i]等于 k。
2.既然 b[0, i-1]最长可匹配后缀子串对应的模式串的前缀子串的下一个字符并不等于 b[i],那么我们就可以考察 b[0, i-1]的次长可匹配后缀子串 b[x, i-1]对应的可匹配前缀子串 b[0, i-1-x]的下一个字符 b[i-x]是否等于 b[i]。如果等于,那 b[x, i]就是 b[0, i]的最长可匹配后缀子串。
可是,如何求得 b[0, i-1]的次长可匹配后缀子串呢?次长可匹配后缀子串肯定被包含在最长可匹配后缀子串中,而最长可匹配后缀子串又对应最长可匹配前缀子串 b[0, y](两个完全一样,次长可匹配前缀子串和次长可匹配后缀字串也完全相同)。于是,查找 b[0, i-1]的次长可匹配后缀子串,这个问题就变成,查找 b[0, y]的最长匹配后缀子串的问题了。
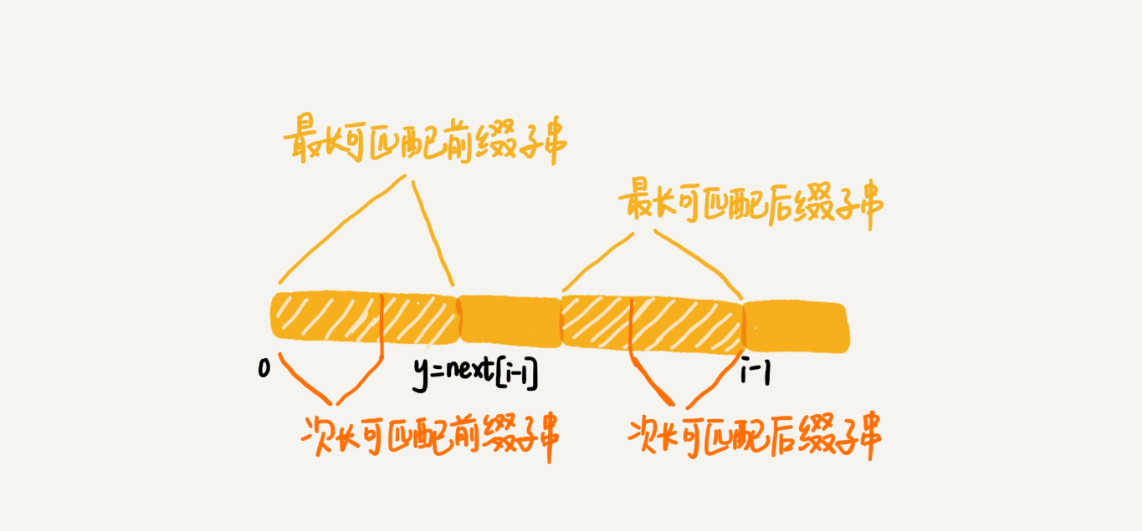
3.按照这个思路,我们可以考察完所有的 b[0, i-1]的可匹配后缀子串 b[y, i-1],直到找到一个可匹配的后缀子串,它对应的前缀子串的下一个字符等于 b[i],那这个 b[y, i]就是 b[0, i]的最长可匹配后缀子串。
最后,上代码:
// b表示模式串,m表示模式串的长度
private static int[] getNexts(char[] b, int m) {
int[] next = new int[m];
next[0] = -1;//next[0]表示好前缀的尾字符下标是 0 的时候,也即好前缀长度为 1 的时候,好前缀没有前缀子串、后缀子串,所以赋值为 -1,表示这时的好前缀不存在公共子串。
int k = -1;//k记录的都是最长可匹配前缀的结尾下标
for (int i = 1; i < m; ++i) {
while (k != -1 && b[k + 1] != b[i]) {//对应步骤2
k = next[k]; //对应步骤3
}
//如果上一次for循环还没有最长前缀子串,则本次最长前缀子串只可能是1(反证法:如果本次最长前缀子串不是1,比如是2,去掉最后一位,那上次应该至少是1,与假设上次没有是矛盾的)
if (b[k + 1] == b[i]) {
++k;
}
next[i] = k;
}
return next;
}完结!















 418
418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









