







总任务:12天实现数据预处理(TF-IDF与word2vec)、模型实践(NB、SVM、LightGBM)以及模型优化的整套流程
分任务:数据初识—>数据处理—>基本模型—>模型优化
“达观杯”文本智能处理挑战赛:建立模型通过长文本数据正文(article),预测文本对应的类别(class)。
数据初识
1.下载数据,读取数据,观察数据


数据量太大,读取了前50行观察数据:
train_set.csv: 训练数据集,每一行对应一篇文章。在“字”和“词”的级别上做了脱敏处理。第一列为文章的索引;第二列是文章在“字”级别上的表示,字符相隔正文(article);第三列是在“词”级别上的表示,词语相隔正文(word_seg);第四列是文章的标注(class)。
ps:每一个数字对应一个“字”,或“词”,或“标点符号”;“字”的编号与“词”的编号是独立的。
test_set.csv:用于测试,其他与训练数据集相同,但不包含class。
ps:训练集和测试集的编号是独立的。
参考第17名的说法:
1.文本长度不均匀,短的很短,长得很长(由于内存爆掉了,也不知道怎么看)用DL的时候,对文本的截断和padding是一个影响性能的因素(暂时不知道这句话什么意思);
2.脱敏数据很慢做一些传统NLP的数据预处理,如去停用词;同时也没有办法使用已有预训练好的词向量;
3.所有分类标签的占比可以看出没有类别不均衡的现象
突然发现一个可以读取所有数据的blog,有空再看:https://blog.csdn.net/GreatXiang888/article/details/82873435
数据预处理
传统特征的选择
对于一般的中文文本挖掘预处理的步骤:中文分词(jieba)、去停用词、特征处理、建立分析模型。
其中特征处理用两种方法:向量化与Hash trick。常用向量化+TF-IDF,用sklearn的TfidfVectorizer类。(刘建平博客园说的,TF-IDF不是可以用于向量化吗?)
一、TF-IDF
参见http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
对于长文本问题,一个直观的想法:提取文本的关键词,利用关键词建模,而TF-IDF就是用来提取文本的关键词(Keyphrase extraction)。
相对于基于神经网络语言模型NNLM的word2vec,TF-IDF是传统的方法,主要思想:关键词一般在文章中出现次数很多,利用词频TF,用IDF修正改进。
具体地,找到出现次数最多的词,若某个词很重要,应该在文章中多次出现,进行词频(Term Frequency,TF)统计,但像停用词(如”的“、”是“)需要过滤掉;对于词频相同的词,重要性不一定相同,引入重要性调整系数,衡量一个词是不是常见词。若某个词比较少见,但是在这篇文章中出现多次,那么它很可能就反映了这篇文章的特性,即在词频的基础上,对每个词分配一个”重要性“权重,如给停用词给予最小的权重,较少见的词给予较大的权重。这个权重叫做”逆文档频率“(Inverse Document Frequency,IDF),它的大小与一个词的常见程度成反比。
知道了TF和IDF,两值相乘得到TF-IDF值,某个词对文章的重要性越高,它的TF-IDF值就越大,故排在最前面的几个词,就是这篇文章的关键词。
算法细节:
Step1:计算词频TF

考虑文章字数不同,便于比较不同文章,进行”词频“标准化

或者

Step2:计算逆文档频率IDF
需要一个语料库(corpus),模拟语言的使用环境
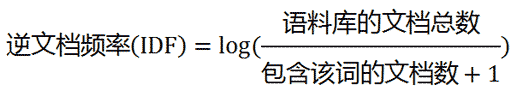
若一个词越常见,分母越大,逆文档频率就越小越接近0,分母加1防止分母为0
Step3:计算TF-IDF
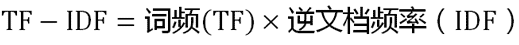
TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比(从公式可以看出)。故自动提取关键词就是计算出文档的每个词的TF-IDF,按降序排列,取排在最前面的几个词。(所以可以不用去掉停用词,因为一般情况下停用词也不会排在前几个词)
TF-IDG算法优缺点:
优点:简单快速,符合直观想法;
缺点:单纯以”词频“衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多,而且无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都认为重要性是相同的,这是不正确的。
对文本数据进行TF-IDF,代码如下:
# -*- coding: utf-8 -*-
"""
@brief : 将原始数据数字化为tfidf特征,并将结果保存至本地
@author: Jian
"""
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
import pickle
import time
t_start = time.time()
"""=====================================================================================================================
1 数据预处理
"""
print("1 数据预处理")
df_train = pd.read_csv('train_set.csv')
df_test = pd.read_csv('test_set.csv')
df_train.drop(columns='article', inplace=True)
df_test.drop(columns='article', inplace=True)
f_all = pd.concat(objs=[df_train, df_test], axis=0, sort=True)
y_train = (df_train['class'] - 1).values
"""=====================================================================================================================
2 特征工程
"""
print("2 特征工程")
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9, sublinear_tf=True)
vectorizer.fit(df_train['word_seg'])
x_train = vectorizer.transform(df_train['word_seg'])
x_test = vectorizer.transform(df_test['word_seg'])
"""=====================================================================================================================
3 保存至本地
"""
print("3 保存至本地")
data = (x_train, y_train, x_test)
fp = open('F:/MyJupyterNotebook/Datawhale达观杯/new_data/new_data/data_w_tfidf.pkl', 'wb')
pickle.dump(data, fp)
fp.close()
t_end = time.time()
print("已将原始数据数字化为tfidf特征,共耗时:{}min".format((t_end-t_start)/60))
代码详见:原文地址
具体说明代码参数:
sklearn中TF-IDF权重计算方法主要用到的两个类:CountVectorizer和TfidfTransformer
1.CountVectorizer
将文本中的词语转换为词频矩阵,通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()获取词袋中所有文本的关键字,由toarray()得到词频矩阵结果。
from sklearn.feature_extraction.text import CountVectorizer
#语料
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.'
'Is this the first document?'
]
# 将文本中的词语,转换成词频矩阵,创建一个对象
vectorizer = CountVectorizer()
# 计算词语出现的频率
X = vectorizer.fit_transform(corpus) #print出来的东西看不懂?
# 获取词袋中所有文本关键词
words = vectorizer.get_feature_names()
print(words)
# 查看词频结果
print(X.toarray())
结果如下:

2.TfidfTransformer
统计vectorizer中每个词语的TF-IDF值

详细参见:https://blog.csdn.net/Eastmount/article/details/50323063
TfidfTransformer + CountVectorizer = TfidfVectorizer
具体参数含义:https://blog.csdn.net/laobai1015/article/details/80451371
二、word2vec
1.原理部分
主要参考:
Xin Rong——word2vec parameter learning explained
https://blog.csdn.net/lanyu_01/article/details/80097350 上一篇对应的中文翻译
Google在2013年率先提出把词语表示为数值向量的工具,即word2vec。而由word2vec生成的词向量受欢迎的原因是多用于处理NLP的问题,例如词性标注、文本分析,以及高效性,使用word2vec工具包一天可训练上千亿单词。
NLP的相关问题要利用深度学习的方法解决,首先要进行数学化,直观的想法是用向量表示每个词,即词向量问题。
One-hot编码:是一种localist representation,词表的大小决定向量的维度,词表大小因语料的不同而不同。向量只有一个元素为1,其余值为0,取值为1的位置正好是词处于词表的位置。One-hot representation优点是简洁,一个最大的问题是由于one-hot向量是正交的,所以使用符号表示不能通过计算(如:余弦距离)求出词与词的相似度,也就体现不出词之间的关系,而且对于词汇量大的语料库,词语向量的维度会很大,易发生维数灾难。
Distributed representation:语言学家提出,一个单词的含义可由上下文得出,该词与上下文有相类似的语义。Distributed representation正是基于这样说法的词向量表示。具体地说,词语用一个较低维度(比如:50、100)的向量表示,每一个维度表示一定的语义和句法,视为一个特定的特征。把词语映射成为V维向量,从而词之间的相似度可经空间距离等向量操作运算判断得到。Word2vec应用这种方法表示词向量。
Word2vec是基于神经网络语言模型和Log-Bilinear等模型提出来的,由单词和上下文彼此预测,包括Continuous Bag-of-Word Model (CBOW模型)和Skip-Gram(SG模型),以及有效的优化参数的训练方法:Hierarchical Softmax即分层softmax,Negative Sampling负采样,共四种组合方法。
实现word2vec:
"""
1 简介 :根据官方给的数据集中'的word_seg'内容,训练词向量,生成word_idx_dict和vectors_arr两个结果,并保存
2 注意 :1)需要16g内存的电脑,否则由于数据量大,会导致内存溢出。(解决方案:可通过迭代器的格式读入数据。
见https://rare-technologies.com/word2vec-tutorial/#online_training__resuming)
"""
import pandas as pd
import gensim
import time
import pickle
import numpy as np
import csv,sys
vector_size = 100
maxInt = sys.maxsize
decrement = True
while decrement:
# decrease the maxInt value by factor 10
# as long as the OverflowError occurs.
decrement = False
try:
csv.field_size_limit(maxInt)
except OverflowError:
maxInt = int(maxInt/10)
decrement = True
#=======================================================================================================================
# 0 辅助函数
#=======================================================================================================================
def sentence2list(sentence):
return sentence.strip().split()
start_time = time.time()
#=======================================================================================================================
# 1 准备训练数据
#=======================================================================================================================
print("准备数据................ ")
df_train = pd.read_csv('train_set.csv',nrows=5000,engine='python')
df_test = pd.read_csv('test_set.csv',nrows=5000,engine='python')
sentences_train = list(df_train.loc[:, 'word_seg'].apply(sentence2list))
sentences_test = list(df_test.loc[:, 'word_seg'].apply(sentence2list))
sentences = sentences_train + sentences_test
print("准备数据完成! ")
#=======================================================================================================================
# 2 训练
#=======================================================================================================================
print("开始训练................ ")
model = gensim.models.Word2Vec(sentences=sentences, size=vector_size, window=5, min_count=5, workers=8, sg=0, iter=5)
print("训练完成! ")
#=======================================================================================================================
# 3 提取词汇表及vectors,并保存
#=======================================================================================================================
print(" 保存训练结果........... ")
wv = model.wv
vocab_list = wv.index2word
word_idx_dict = {}
for idx, word in enumerate(vocab_list):
word_idx_dict[word] = idx
vectors_arr = wv.vectors
vectors_arr = np.concatenate((np.zeros(vector_size)[np.newaxis, :], vectors_arr), axis=0)#第0位置的vector为'unk'的vector
f_wordidx = open('word_seg_word_idx_dict.pkl', 'wb')
f_vectors = open('word_seg_vectors_arr.pkl', 'wb')
pickle.dump(word_idx_dict, f_wordidx)
pickle.dump(vectors_arr, f_vectors)
f_wordidx.close()
f_vectors.close()
print("训练结果已保存到该目录下! ")
end_time = time.time()
print("耗时:{}s ".format(end_time - start_time))
参考https://github.com/Heitao5200/DGB/blob/master/feature/feature_code/train_word2vec.py
具体看如何用genism实现word2vec,一个列子:
from gensim.models import word2vec
sentences = word2vec.Text8Corpus("C:/traindataw2v.txt") # 加载语料
model = word2vec.Word2Vec(sentences, size=200) # 训练skip-gram模型; 默认window=5
#获取“学习”的词向量
print("学习:" + model["学习"])
# 计算两个词的相似度/相关程度
y1 = model.similarity("不错", "好")
# 计算某个词的相关词列表
y2 = model.most_similar("书", topn=20) # 20个最相关的
# 寻找对应关系
print("书-不错,质量-")
y3 = model.most_similar(['质量', '不错'], ['书'], topn=3)
# 寻找不合群的词
y4 = model.doesnt_match("书 书籍 教材 很".split())
# 保存模型,以便重用
model.save("db.model")
# 对应的加载方式
model = word2vec.Word2Vec.load("db.model")
默认参数如下:
sentences=None
size=100
alpha=0.025
window=5
min_count=5
max_vocab_size=None
sample=1e-3
seed=1
workers=3
min_alpha=0.0001
sg=0
hs=0
negative=5
cbow_mean=1
hashfxn=hash
iter=5
null_word=0
trim_rule=None
sorted_vocab=1
batch_words=MAX_WORDS_IN_BATCH
参数含义:
sentences:就是每一行每一行的句子,但是句子长度不要过大,简单的说就是上图的样子
sg:这个是训练时用的算法,当为0时采用的是CBOW算法,当为1时会采用skip-gram
size:这个是定义训练的向量的长度
window:是在一个句子中,当前词和预测词的最大距离
alpha:是学习率,是控制梯度下降算法的下降速度的
seed:用于随机数发生器。与初始化词向量有关
min_count: 字典截断.,词频少于min_count次数的单词会被丢弃掉
max_vocab_size:词向量构建期间的RAM限制。如果所有不重复单词个数超过这个值,则就消除掉其中最不频繁的一个,None表示没有限制
sample:高频词汇的随机负采样的配置阈值,默认为1e-3,范围是(0,1e-5)
workers:设置多线程训练模型,机器的核数越多,训练越快
hs:如果为1则会采用hierarchica·softmax策略,Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。如果设置为0(默认值),则负采样策略会被使用
negative:如果大于0,那就会采用负采样,此时该值的大小就表示有多少个“noise words”会被使用,通常设置在(5-20),默认是5,如果该值设置成0,那就表示不采用负采样
cbow_mean:在采用cbow模型时,此值如果是0,就会使用上下文词向量的和,如果是1(默认值),就会采用均值
hashfxn:hash函数来初始化权重。默认使用python的hash函数
iter: 迭代次数,默认为5
trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受(word, count, min_count)并返回utils.RULE_DISCARD,utils.RULE_KEEP或者utils.RULE_DEFAULT,这个设置只会用在构建词典的时候,不会成为模型的一部分
sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
batch_words:每一批传递给每个线程单词的数量,默认为10000,如果超过该值,则会被截断
参考链接:https://www.jianshu.com/p/972d0db609f2
对于word2vec的理解就是弄清楚了CBOW和Skip-gram的公式推导及反向传播,理解了这两个模型而已,具体的实现要清楚理解估计还得看源码解析。
Q:字典截断那部分看不是很懂,分层softmaxt哈夫曼树和负采样后面再看吧。
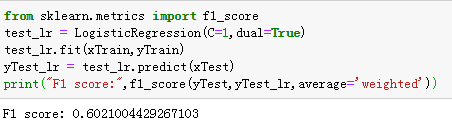
LR实现
代码如下:
import pickle
import pandas as pd
import time
from sklearn.externals import joblib
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
time_start = time.time()
print("0 读取特征")
data_fp = open("data_w_tfidf1.pkl", 'rb')
x_train, y_train, x_test = pickle.load(data_fp)
xTrain, xTest, yTrain, yTest = train_test_split(x_train, y_train, test_size=0.30, random_state=531)
from sklearn.metrics import f1_score
test_lr = LogisticRegression(C=1,dual=True)
test_lr.fit(xTrain,yTrain)
yTest_lr = test_lr.predict(xTest)
print("F1 score:",f1_score(yTest,yTest_lr,average='weighted'))
得到如下结果
SVM实现
F1得分如下:

稍微调参了一下感觉得分也没有相差很大。
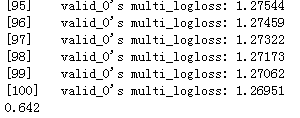
Lightgbm
1.理论部分
2.代码实现
import pickle
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
data_fp = open("data_w_tfidf1.pkl", 'rb')
x_train, y_train, x_test = pickle.load(data_fp)
xTrain, xTest, yTrain, yTest = train_test_split(x_train, y_train, test_size=0.30, random_state=531)
import lightgbm as lgb
train_data = lgb.Dataset(xTrain,yTrain)
validation_data = lgb.Dataset(xTest,yTest)
params={
'learning_rate':0.1,
'lambda_l1':0.1,
'lambda_l2':0.2,
'max_depth':4,
'objective':'multiclass',
'num_class':19
}
clf = lgb.train(params,train_data,valid_sets=[validation_data])
from sklearn.metrics import roc_auc_score,accuracy_score
y_pred = clf.predict(xTest)
y_pred = [list(x).index(max(x)) for x in y_pred]
print(y_pred)
print(accuracy_score(yTest,y_pred))
结果如下:
模型优化——调参
import pickle
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
data_fp = open("data_w_tfidf1.pkl", 'rb')
x_train, y_train, x_test = pickle.load(data_fp)
xTrain, xTest, yTrain, yTest = train_test_split(x_train, y_train, test_size=0.30, random_state=531)
tuned_parameters = [{'penalty':['l1','l2'],
'C':[0.01,0.1,0.5],
'solver':['liblinear'],
'multi_class':['ovr']},
{'penalty':['l2'],
'C':[0.01,0.1,0.5],
'solver':['lbfgs'],
'multi_class':['ovr','multinomial']}]
clf = svm.LinearSVC()
gsearch = GridSearchCV(clf,tuned_parameters,scoring='f1_weighted',cv=5)
gsearch.fit(xTrain,yTrain)
print('Best score:%0.3f' % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('\t%s:%r' %(param_name,best_parameters[param_name]))
2.SVM
import pickle
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
data_fp = open("data_w_tfidf1.pkl", 'rb')
x_train, y_train, x_test = pickle.load(data_fp)
xTrain, xTest, yTrain, yTest = train_test_split(x_train, y_train, test_size=0.30, random_state=531)
tuned_parameters = [{'kernel':['rbf'],'gamma':[1e-3,1e-4],'C':[1,10,100,1000]},
{'kernel':['linear'],'C':[1,10,10,1000]}]
clf = svm.LinearSVC()
gsearch = GridSearchCV(clf,tuned_parameters,scoring='f1_weighted',cv=5)
gsearch.fit(xTrain,yTrain)
print('Best score:%0.3f' % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('\t%s:%r' %(param_name,best_parameters[param_name]))
3.Lightgbm
import pickle
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
data_fp = open("data_w_tfidf1.pkl", 'rb')
x_train, y_train, x_test = pickle.load(data_fp)
xTrain, xTest, yTrain, yTest = train_test_split(x_train, y_train, test_size=0.30, random_state=531)
train_data = lgb.Dataset(xTrain,yTrain)
validation_data = lgb.Dataset(xTest,yTest)
parameters={
'learning_rate':[0.01,0.05,0.1],
'lambda_l1':[0.1,0.2,0.4],
'lambda_l2':[10,15],
'max_depth':[4,6]
}
gbm = lgb.LGBMClassifier(objective = 'multiclass',num_class=19)
gsearch = GridSearchCV(gbm,param_grid=parameters,scoring='f1_weighted',cv=3)
gsearch.fit(xTrain,yTrain)
print('Best score:%0.3f' % gsearch.best_score_)
print("Best parameters set:")
best_parameters = gsearch.best_estimator_.get_params()
for param_name in sorted(parameters.keys()):
print('\t%s:%r' %(param_name,best_parameters[param_name]))
电脑要爆炸了,还在跑。。。















 3032
3032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









