









写在前面
最近找工作写简历,有些公司需要电子版的成绩单,但是正方教务系统好像没有下载电子版成绩单的操作,所以我想能不能自己把成绩爬取并保存下来。
准备工作
- python2.7
- selenium模块
- lxml模块
- 可被selenium控制的谷歌浏览器
- 爬取前要自己先手动登录教务系统,让浏览器保存你的cookie,selenium模拟时就不用登录了,如果要求模拟登录,大家可以自学如何破解验证码。
遇到的问题
- 如果刚登录就爬取网页源代码或者爬取用js渲染的页面代码,发现不能找到有关成绩信息的元素,所以我们用selenium模拟点击页面按钮,但是在点击“个人成绩查询”后,再想点击“历年成绩” 发现找不到那个页面元素,这是因为相应的网页代码块在“#document”下面,所以还需要解决这个问题。

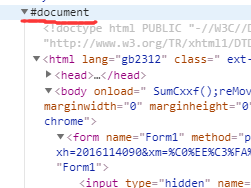 2. 在爬取‘学年’,‘学期’这些字段时,前四个字段和后面的字段所处的结构不一样,所以要分开用xpath表达式爬取,并保存在一个列表里。
2. 在爬取‘学年’,‘学期’这些字段时,前四个字段和后面的字段所处的结构不一样,所以要分开用xpath表达式爬取,并保存在一个列表里。
代码思路及代码
#encoding=utf-8
from selenium import webdriver
from lxml import etree
#防止中文信息写入文件时出错
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
driver=webdriver.Chrome()
driver.get("http://219.245.18.49/(4il4ug55114gla55azydwk2p)/xs_main.aspx?xh=2016114090")
#依次点击‘信息查询’和‘个人成绩查询’
button0=driver.find_element_by_link_text('信息查询').click()
button1=driver.find_element_by_link_text('个人成绩查询').click()
#解决‘#document’下源代码不能直接爬取的问题
driver.switch_to_default_content()
frame=driver.find_elements_by_tag_name('iframe')[0]
driver.switch_to_frame(frame)
#点击‘历年成绩’
button2=driver.find_element_by_name('btn_zcj').click()
#爬取此刻的网页源代码
pageContent=driver.page_source
#将网页源代码封装成html对象
html=etree.HTML(pageContent)
#创建字段列表
title_list=[]
#分别爬去字段信息,原因是前四个字段和后面字段元素结构不一样
titlewitha=html.xpath("//tr[@class='datelisthead']/td/a/node()")[:4:]
titlewithouta=html.xpath("//tr[@class='datelisthead']/td/node()")[4::]
title_list.extend(titlewitha)
title_list.extend(titlewithouta)
#计算表格有多少行数据(包括字段行)
nodeSum=html.xpath("//table[@class='datelist']/tbody/node()")
#创建并打开“success.csv”文件,开启追加模式
with open("success.csv",mode="a") as f:
#写入字段信息
for i in range(len(title_list)):
if i!=len(title_list)-1:
f.write(title_list[i]+',')
else:
f.write(title_list[i]+'\n')
#循环爬取每一行的(学年,学期......)数据并追加入文件
for i in range(len(nodeSum)-1):
information=html.xpath("//table[@class='datelist']/tbody/tr[{0}]/td/node()".format(str(i+2)))
for info in range(len(information)):
if info != len(information) - 1:
f.write(information[info]+',')
else:
f.write(information[info] + '\n')
运行结果
- 运行后会有一个“success.csv”文件,可以用excle的方式打开就可以了。
代码优化
- 可以看到,写入字段时的代码和写入成绩时的代码相似,可以自定义个写入文件的函数,借此优化代码。















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









