







- 需求描述
本次实验需要以2020年美国新冠肺炎疫情数据作为数据集,以Python为编程语言,使用Spark对数据进行分析,并对分析结果进行可视化。原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame。
首先使用Python将us-counties.csv转换为.txt格式文件us-counties.txt,然后使用本地文件系统上传到HDFS文件系统中,由于本实验中使用的数据为结构化数据,因此可以使用spark读取源文件生成DataFrame以方便进行后续分析实现。由于使用Python读取HDFS文件系统不太方便,故将HDFS上结果文件转储到本地文件系统中, 选择使用python第三方库pyecharts作为可视化工具,可视化结果是.html格式的。
本实验主要统计以下8个指标,分别是:
1) 统计美国截止每日的累计确诊人数和累计死亡人数。
2) 统计美国每日的新增确诊人数和新增死亡人数。
3) 统计截止5.19日,美国各州的累计确诊人数和死亡人数。
4) 统计截止5.19日,美国确诊人数最多的十个州。
5) 统计截止5.19日,美国死亡人数最多的十个州。
6) 统计截止5.19日,美国确诊人数最少的十个州。
7) 统计截止5.19日,美国死亡人数最少的十个州。
8) 统计截止5.19日,全美和各州的病死率。
在计算以上几个指标过程中,根据实现的简易程度,既采用了DataFrame自带的操作函数,又采用了spark sql进行操作。
- 环境介绍
操作系统:Ubuntu 20.04.2 LTS
1. 安装好的VMware Workstation Player虚拟机软件
请确认安装好VMware Workstation Player,如仍未安装VMware Workstation Player,请点击下载地址安装。
点击这里VMware Workstation Player官网下载地址
2. Ubuntu 20.04.2 LTS映像文件
点击这里从 Ubuntu官网下载,进入网页以后,找到下载Ubuntu桌面版Ubuntu 20.04.2.0 LTS ,请点击“下载”按钮下载“ubuntu-20.04.2.0-desktop-amd64.iso”镜像。
Hadoop版本:3.1.3
Hadoop安装文件,可以到Hadoop官网下载hadoop-3.1.3.tar.gz。也可以直接点击这里从百度云盘下载软件(提取码:lnwl),进入百度网盘后,进入“软件”目录,找到hadoop-3.1.3.tar.gz文件,下载到本地。我们选择将 Hadoop 安装至 /usr/local/ 中。
Java版本:1.8.0_292
Hadoop3.1.3需要JDK版本在1.8及以上。需要按照下面步骤来自己手动安装JDK1.8。已经把JDK1.8的安装包jdk-8u162-linux-x64.tar.gz放在了百度云盘,可以点击这里到百度云盘下载JDK1.8安装包(提取码:lnwl)。请把压缩格式的文件jdk-8u162-linux-x64.tar.gz下载到本地电脑,假设保存在“/home/linziyu/Downloads/”目录下。
Python版本:3.8.5
系统自带,无需安装
Pip版本:20.0.2
在终端输入以下命令即可安装:
sudo apt-get install python3-pip
Spark版本:3.1.2
需要下载Spark安装文件。访问Spark官方下载地址
也可以直接点击这里从百度云盘下载软件(提取码:ziyu)。进入百度网盘后,进入“软件”目录,找到spark-2.4.0-bin-without-hadoop.tgz文件,下载到本地。
- 数据来源描述
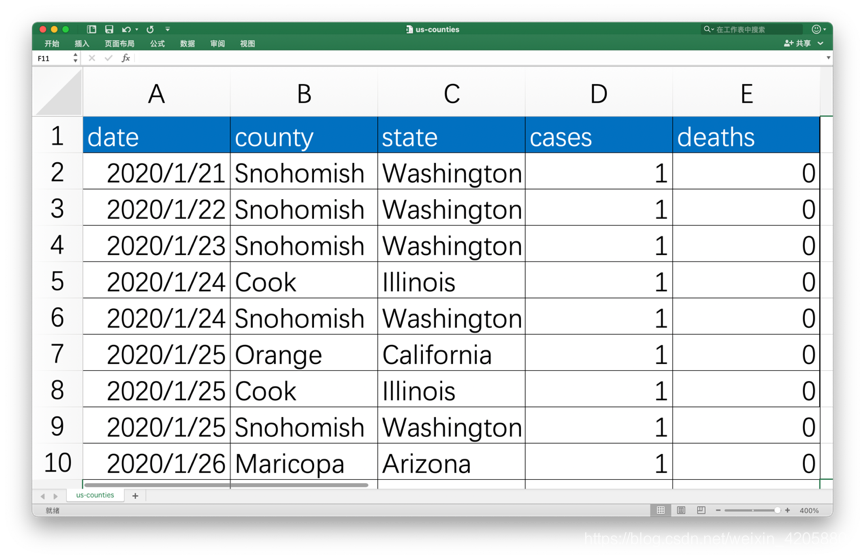
本次作业使用的数据集来自数据网站Kaggle的美国新冠肺炎疫情数据集(从百度网盘下载,提取码:t7tu),该数据集以数据表“us-counties.csv”组织,其中包含了美国发现首例新冠肺炎确诊病例至今(2020-05-19)的相关数据。数据包含以下字段:
字段名称 字段含义 例子
date 日期 2020/1/21;2020/1/22;etc
county 区县(州的下一级单位) Snohomish;
state 州 Washington
cases 截止该日期该区县的累计确诊人数 1,2,3…
deaths 截止该日期该区县的累计确诊人数 1,2,3…
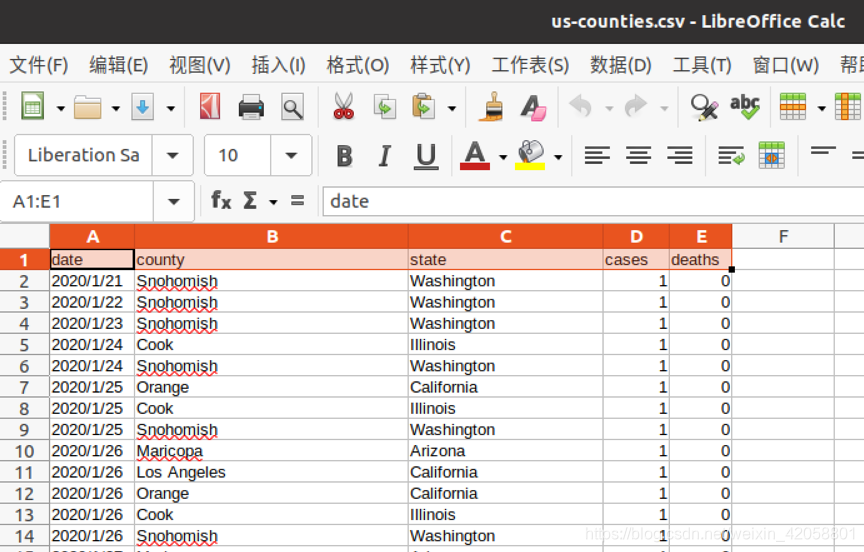
- 数据上传及上传结果查看
数据集(从百度网盘下载,提取码:t7tu)
us-counties.csv:
5、数据处理过程描述
1.格式转换
原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









