







文章目录
一、初识Explain
在查询语句前加入Explain关键字,可以模拟出优化器执行SQL语句,是分析SQL语句或语句结构的性能瓶颈重要工具,同时也是优化SQL的重要参考依据
二、Explain涉及字段
2.1 select_type
1、表示查询语句的类型,是简单查询还是复杂查询以及其他类型查询
2、取值包含了一下值域:
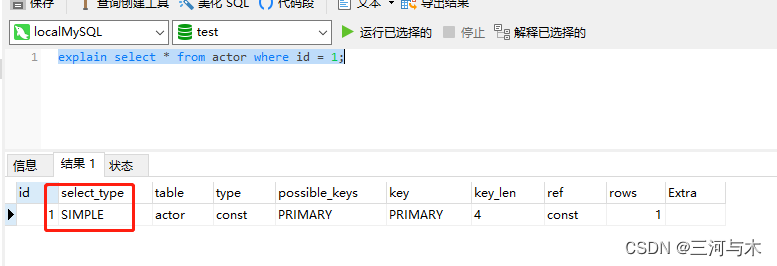
- simple:简单查询,查询语句中不包含子查询和union,如下图简单查询
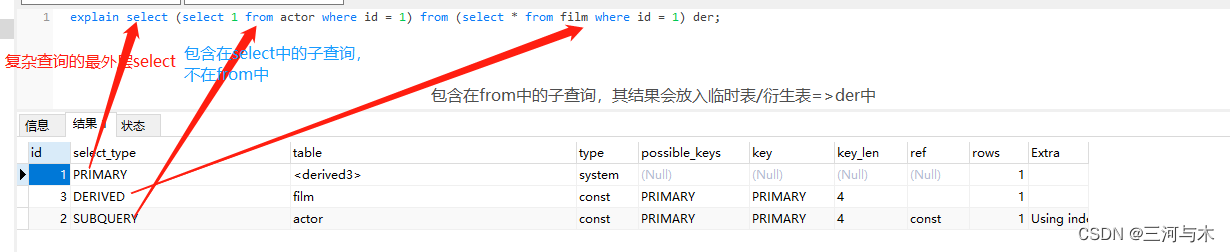
- primary:复杂查询中的最外层
- subquery:包含在select中的子查询,且不在from的子句中
- derived:包含在from中的子查询,这个查询会生成一个临时表,也称为派生表,如下图示:
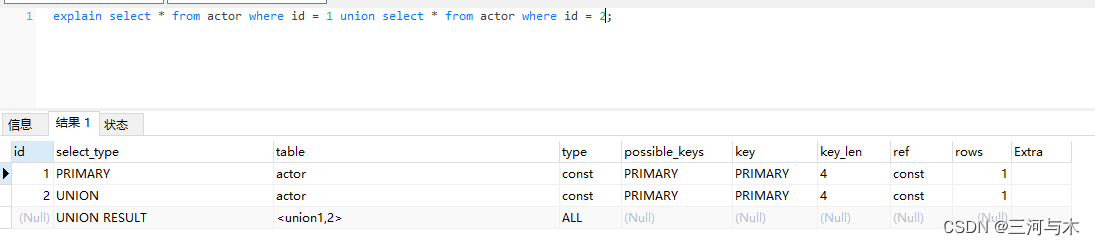
- union:就是将两个select查询的结果集进行合并
2.2 table
1、这一列表示正在访问的是哪个表,当from后有子查询时,其table列的值为:derivedN,其中N表示当前查询依赖于id为N的查询
2、若是查询语句中union,那union result中的table列的值为:unionN,M,其中的N和M表示合并select的id
2.3 type
1、这一列是表示关联的类型和访问的类型,是SQL语句优化的重点关注列,也就是说会体现出SQL是如何去查找表中的行数据的,分别有七个值,依次从优到差为:system>const>eq_ref>ref>rang>index>all,优化时,一般都需要到达rang以上
2、相关值域示例说明:
-
Null:Mysql在SQL优化阶段就可以分解的查询语句,在执行阶段不用访问数据表的索引信息,例如,我们查询表中的最大值和最小值时候,type就没值,如下图:

-
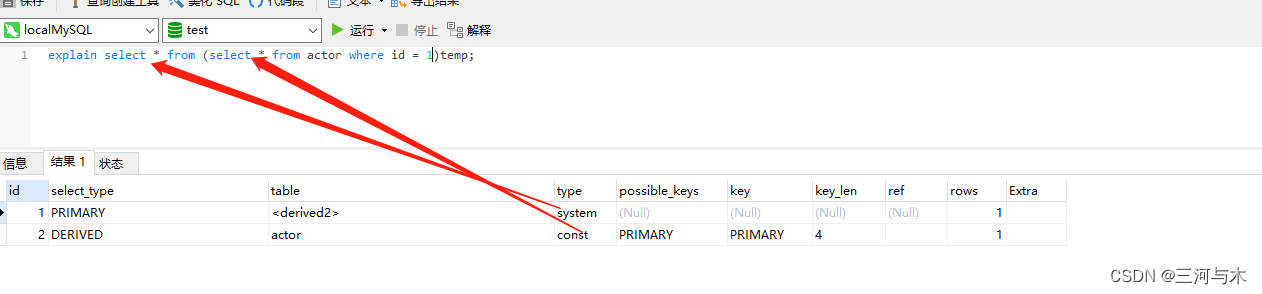
system、const:const是MySQL能对查询的SQL部分进行优化,将其转换为一个常量==>可以通过show warning来查看结果,使用索引查找数据,并且查找到的数据最多就只有一条符合查询条件,读取一次,速度比较快,而system是const的一种特例>就是匹配的数据表中数据只有一条数据时为system=,具体示例如下图:
-
eq_ref:这个是在表连接时,使用了主键作为连接条件,做多返回一条符合条件的数据,详见下图示例:
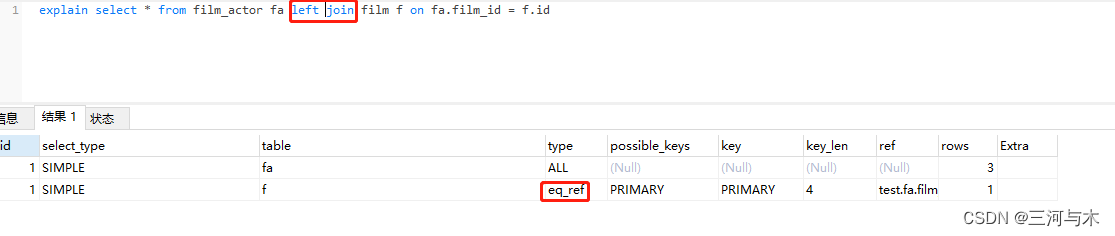
-
ref:相比eq_ref,这里在表连接时,使用的不是唯一索引,而是普通的索引或唯一索引的前缀,导致在匹配数据时,可能会找到多个满足条件的数据,例:

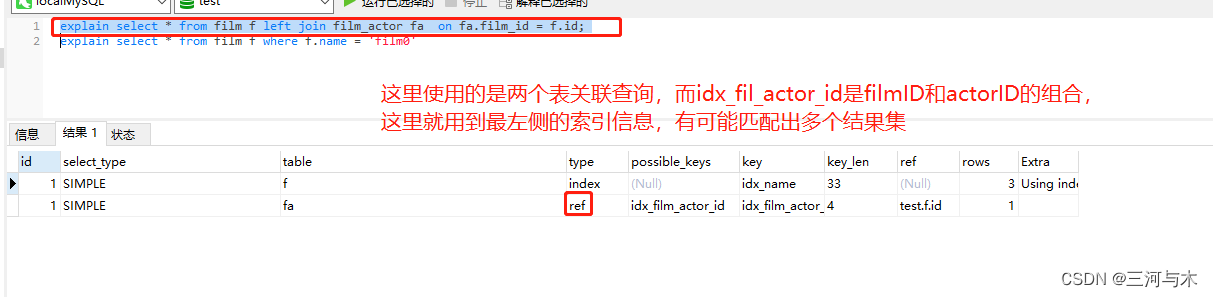
-
rang:范围的扫描通常出现在in()、between、大于、小于、大于等于等操作中,注:范围查询的字段是索引字段,例:

-
index:这种一般是扫描所有的索引才能拿到结果,一般是扫描某个二级辅助索引,因为二级索引比较小,会优先扫描,速度比较慢,这种查询一般情况下为使用覆盖索引,例:

-
all:即为全表扫描,即扫描整个聚集索引的所有叶子节点,这种情况通常是需要优化的,例:
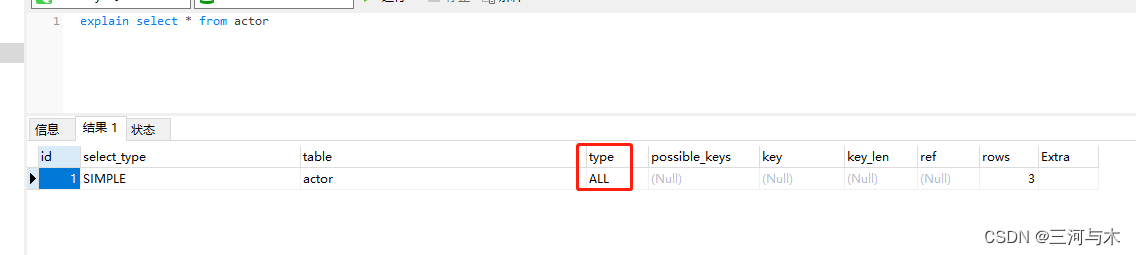
2.4 possible_key
1、表示查询可能会走的索引,但不一定走此索引,具体还需要结合MySQL内部优化器对成本cost字段的估算比对,选择cost较低的为执行时的方案
2.5 key
1、主要是显示实际在执行语句时使用了那些索引对表数据进行访问
2.6 key_len
1、显示的内容为,索引使用的字节数,可以通过这个值算出具体使用了索引中的那些列==>主要是针对联合索引
2、字节数的计算公式详解:
2、MySQL相关类型字节数的计算公式与取值详解:
2.1、 字符类型
- char(n)和varchar(n)。5.0.3以后的版本中,n均代表字符数,而不是字节数,如果是utf8,一个数字或字母占1个字节,一个汉字占3个字节,所以:
- char(n)=>如果是存汉字,key_len就为3n字节;
- varchar(n)=>key_len就为3n + 2 字节,加的2字节用来存储字符串长度,因为varchar是变长字符串
2.2、 数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigInt:8字节
2.3、 时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
2.7 ref
1、这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量),字段名(例:film.id或const)
2.8 rows
1、显示的是估算读取并检测的行数
2.9 Extra
1、主要是展示其他信息
2、取值包含了一下值域:
-
using index:使用了覆盖索引,所谓的覆盖索引,其含义就是select 后面查询的字段都可以从相对于的索引树中获取,这种场景一般是针对辅助索引的,相当于不用回表查询数据,例:

-
using where:使用where语句来处理结果,且查询的列没有被索引覆盖,例:
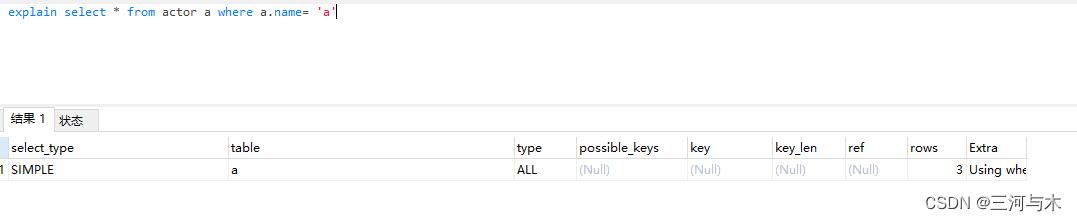
-
Using filesort:将用外部排序而不是索引排序,若文件较小的就采用内存排序,否则就是文件排序,效率低,需考虑使用索引排序来优化
三、导致索引失效部分场景列举
3.1 导致索引失效原因
1、其实导致索引失效的原因就是==>打破了索引的定义,打破了索引树的规则,例如,索引的定义是:是帮助MySQL高效获取数据的排好序的数据结构,但是对索引值做了计算和其他操作后,并不是原先索引树上的值了,那如果拿这种处理后的值去查找数据,其实在索引树上是找不到的,因为排好序已经被打破了,导致的结果就是全表扫描,以下是部分导致索引失效的举例:
- 查询语句的条件使用了联合索引,但是不满足最左前缀原则
- 在索引列上加入额外的一系列操作,例如:计算、函数、类型转换等
- MySQL在查询语句中使用了==>不等于、not in、not exists、is null、is not null时,都会导致索引失效,走的是全表扫描
- 字符串的列如果不加引号也会导致索引失效,以及like使用不当也会到导致索引失效(例如:like “%xx”)
四、拓展—SQL优化的分析方向
1、首先是直观的分析语句,查看SQL语句是否load多余字段信息,如果有无用的,可适当去除
2、将SQL语句复制出来,进行Explain执行计划分析,查看执行过程中使用索引情况,尽可能使查询走索引,且满足小表驱动大表原则
3、如果说对于SQL层面的优化达到了瓶颈,那可以考虑下数据库的数据量是否过于庞大,是否考虑横向/纵向分表存储数据















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









