






写在前面:
第一篇讲解Spring时,重点提到过Spring事务,Spring事务本质上是数据库事务,而数据库事务是基于并发。此时数据库引用了一套锁机制来解决并发问题。在介绍锁机制之前,就不得不提数据库索引。此文以目前市场主流的MySQL数据库为例。
Mysql索引
一、存储引擎:
1)MyISAM :不支持事务、支持表锁、索引方式为非聚簇索引
2)InnoDB(MySQL默认):支持事务、支持行锁、索引方式为聚簇索引(主键索引)和非聚簇索引(唯一索引 普通索引等)
3)Memory:不支持事务、Hash索引
二、索引存储方式:
1)聚簇索引 :索引和数据均存储在B tree中
2)非聚簇索引:索引存储在B tree中与数据块分开存储
三、索引存储结构:
1)B tree
2)Hash索引
三、数据存储位置:数据库数据量大,以文件形式存储于磁盘空间
四、访问数据方式:IO方式访问磁盘,每次IO大小为一页,不同的操作系统有所不同,一般为4k或8k或16k。
五、访问磁盘更快的方式:减少IO次数
六、问题
理解上述概念后,会出现一个疑问,为什么InnoDB会使用聚簇索引和非聚簇索引的方式,即为什么会使用B tree的索引存储结构?同样是树结构 为什么不使用AVL 、红黑树?
七、分析:
1.AVL平衡二叉树:
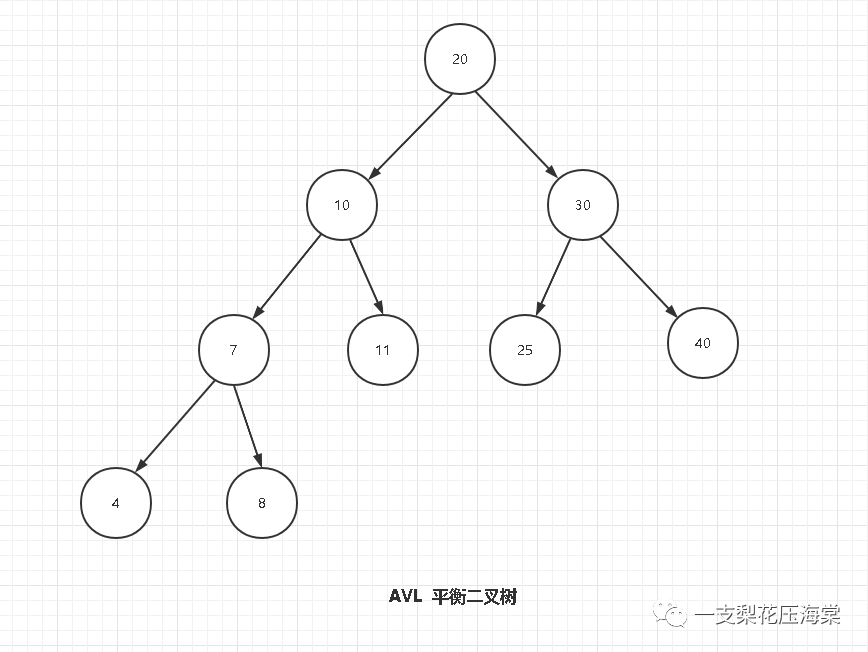
特点:
1)通过旋转保持平衡
2)高度相对较大为 log n(底数为2)
3)每个节点只有两个子节点
4)其他
2.RBT红黑树
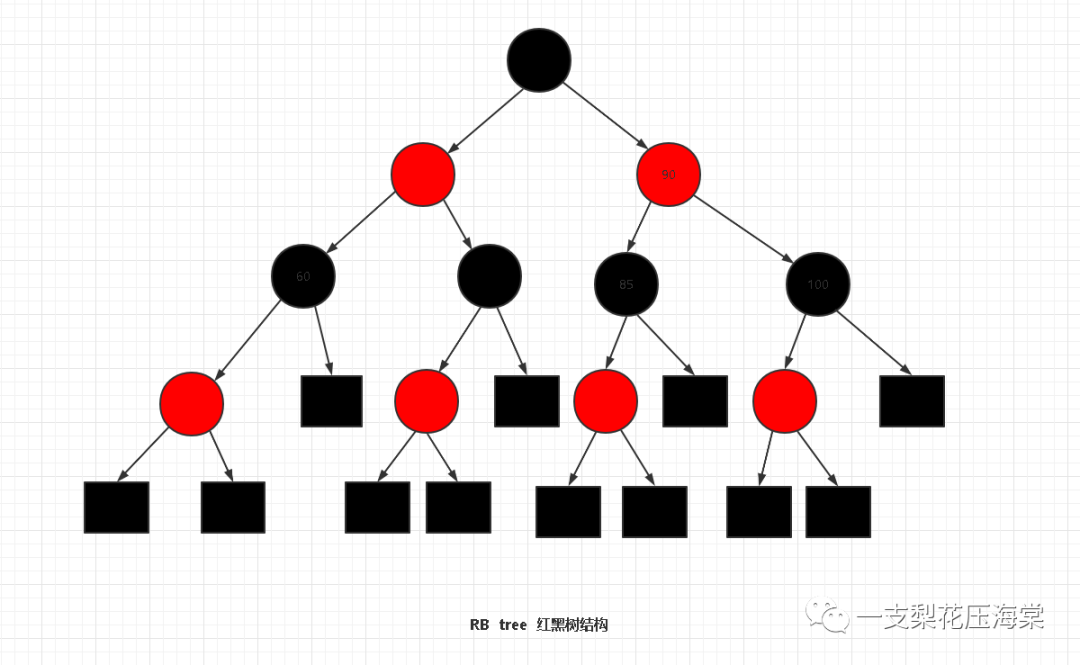
特点:
1)根节点为黑色
2)每个节点不是红色即是黑色
3)叶子节点为黑色 值为NULL
4)一个节点是红色 子节点必须是黑色
5)从根节点到所有子孙节点的路劲黑节点数量相同
6)每个节点只有两个子节点
3.B 树
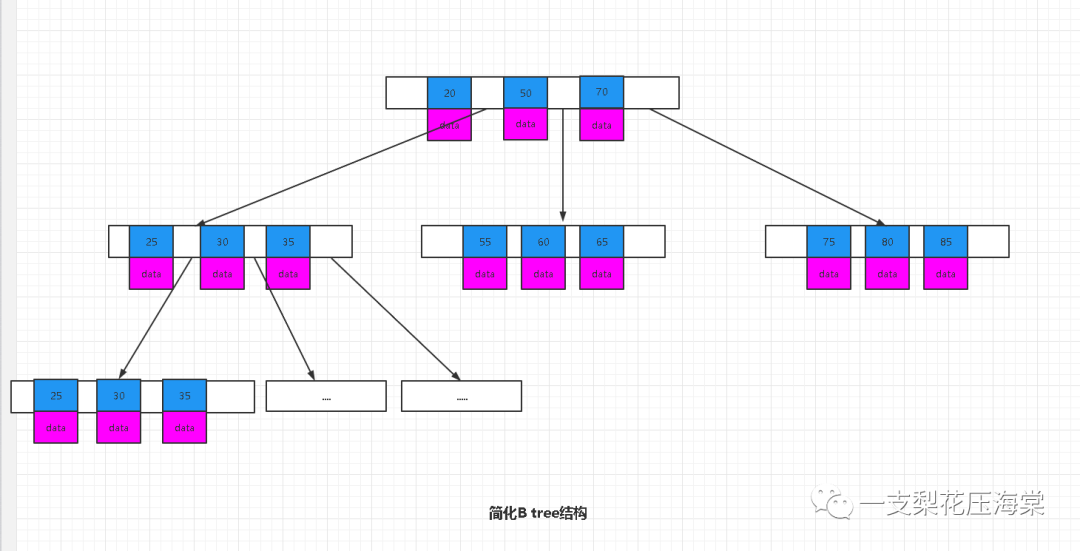
特点:
1)每个节点有大于2的子节点
2)每个节点存储索引和data数据
3)深度相对较小 通常为3
4)搜索可能在非叶子节点结束
5)每个节点大小刚好为一页,即每次IO大小
4.B+树
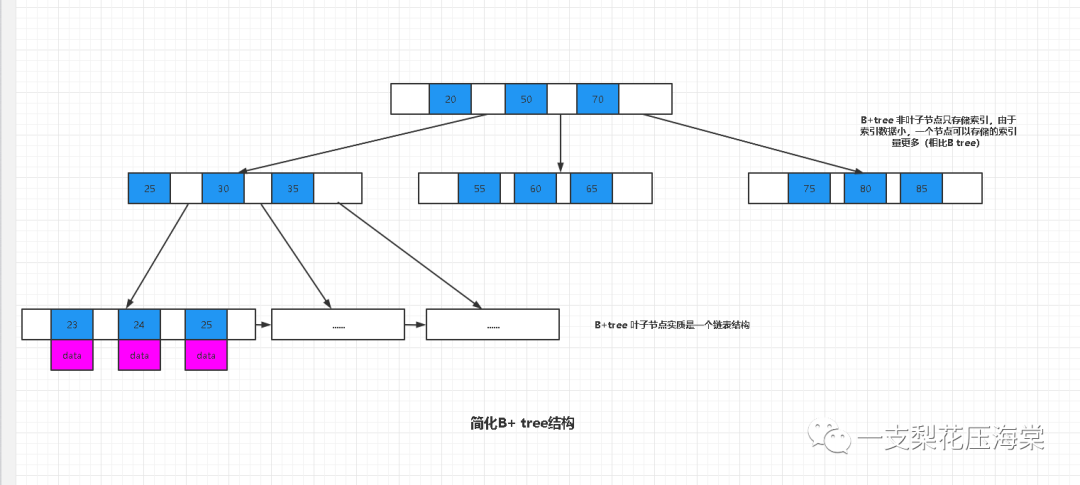
特点:
1)非叶子节点只存储索引
2)叶子节点存储索引和data数据
3)叶子节点是一个链表结构 可以通过轮询链表查询到任何一个数据
4)非叶子节点相对B树能够存储更多的索引
5)每个节点大小刚好为一页,即每次IO大小
八、总结:
为什么不用AVL平衡二叉树或者红黑树?
因为两者的深度过深,访问磁盘空间时IO次数过多,每次IO的时间过长,效率过低,平衡二叉树或者红黑树通常作为内存的数据存储结构。而数据库的存储方式由于数据量过大限制为磁盘存储,因此不使用平衡二叉树和红黑树。而B类型的树结构树高小,并且每个节点大小刚好是一次IO,因此使用B类型结构存储索引。
为什么使用B+树而不是B树?
根据B树和B+树结构可知,B+树非叶子节点的索引数量更多,每次能过索引到的范围更大,数据量更大,即同一次IO,B+树的访问量更大。根据空间局部性原理:如果一个存储器的某个位置被访问,那么这个位置的附近位置也会被访问,然后加载到内存中,B+树的叶子节点是连续的,在索引时,能够被加载到内存的数据量更大,因此效率更高。
生活的悲欢离合永远在地平线以外,而眺望是一种 青春的姿态...
PS:
文章是笔者分享的学习笔记,若你觉得可以、还行、 过得去、甚至不太差的话,可以“推荐”一下的哦。就此谢过!
另外,关注我的公众号回复“资料”还可以获取更多java学习资料哦,包括阿里腾讯等面试题库等。



















 2488
2488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









