







参考书目:《数据结构教程(第五版)》李春葆 主编
《数据结构》上机实验(第二章) Ⅱ

1.有一个带头结点的单链表 L = ( a 1 , b 1 , a 2 , b 2 , ⋯ , a n , b n ) L=(a_1,b_1,a_2,b_2,\cdots,a_n,b_n) L=(a1,b1,a2,b2,⋯,an,bn),将其拆分成两个带头结点的单链表L1和L2,其中 L 1 = ( a 1 , a 2 , ⋯ , a n ) L1=(a_1,a_2,\cdots,a_n) L1=(a1,a2,⋯,an), L 2 = ( b n , b n − 1 , ⋯ , b 1 ) L2=(b_n,b_{n-1},\cdots,b_1) L2=(bn,bn−1,⋯,b1)。要求L1使用L的头结点。
- 算法思路:利用原单链表L中的所有结点通过改变指针域重组成两个单链表L1和L2。由于L1中结点的相对顺序与L中的相同,所以直接改变结点的指针域即可建立单链表L1;由于L2中结点的相对顺序与L中的相反,所以采用头插法建立单链表L2。
#include<stdio.h>
#include<malloc.h>
typedef int ElemType;
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode,*LinkList;
void InitList(LinkList &L) //初始化单链表
{
L = (LinkList)malloc(sizeof(LNode));
L->next = NULL;
}
void CreateList(LinkList &L) //尾插法创建单链表
{
LNode *p = L,*s;
for (int i = 0; i < 10; i++)
{
s = (LNode*)malloc(sizeof(LNode));
s->data = i;
s->next = p->next;
p->next = s;
p = p->next;
}
}
void PrintList(LinkList &L) //输出函数
{
LNode* p = L->next;
while (p != NULL)
{
printf("%d ", p->data);
p = p->next;
}
}
void SplitList(LinkList& L, LinkList& L1, LinkList& L2) //拆分单链表L
{
LNode* p = L->next, * q, * r1;
L1 = L; //L1使用L的头结点
r1 = L1; //r1指向L1
L2 = (LinkList)malloc(sizeof(LNode*)); //创建L2的头结点
L2->next = NULL; //置L2的指针域为NULL
while (p != NULL)
{
r1->next = p; //采用尾插法将p插入L1中
r1 = p;
q = p->next;
p = q->next;
q->next = L2->next; //采用头插法将结点q插入L2中
L2->next = q;
}
r1->next = NULL; //尾结点next置空
}
int main()
{
LinkList L, L1, L2;
InitList(L); //初始化单链表
CreateList(L); //尾插法创建单链表
printf("L中的值为:");
PrintList(L); //调用函数,输出单链表L
printf("\n");
SplitList(L, L1, L2); //调用函数,拆分单链表L
printf("L1中的值为:");
PrintList(L1); //调用函数,输出单链表L1
printf("\n");
printf("L2中的值为:");
PrintList(L2); //调用函数,输出单链表L2
printf("\n");
return 0;
}
程序分析:
- 由于L2采用尾插法,因此在第一次循环结束时,r1的指针域已经变为NULL。因此指针后移操作应该在r1的指针域变为NULL之前完成,当实现了后移操作后才能将r1的指针域与L2的指针域互换,否则后移操作会指向NULL。
- 运行结果:
- p刚开始指向L链表中的首结点,每一次while循环,p向后移动了两个结点的位置,当q为NULL时修改当前p指向的结点的指针域(置为NULL),此时再循环已经不满足条件了,循环结束。由于L1使用L的头结点,因此L1不需要开辟新的存储单元,而L2则需要开辟新的存储单元。
- 时间复杂度: O ( n 2 ) O(\frac{n}{2}) O(2n);空间复杂度: O ( n 2 ) O(\frac{n}{2}) O(2n)


2.删除一个单链表L中最大的结点(假设这样的结点唯一)。
- 算法思路:在单链表中删除一个结点先要找到它的前驱结点,用指针p扫描整个单链表,pre指向结点p的前驱结点,在扫描时用max指向data域值最大的结点,mapre指向max所指结点的前驱结点。当单链表扫描完毕后,通过maxpre所指结点删除其后的结点,即删除了结点值最大的结点。
void CreateList(LinkList& L) //尾插法创建单链表
{
LNode *p = L,*s;
int num;
printf("输入:\n");
scanf("%d ", &num);
while(num != 999)
{
s = (LNode*)malloc(sizeof(LNode));
s->data = num;
s->next = p->next;
p->next = s;
p = p->next;
scanf("%d", &num);
}
}
void MaxNum(LinkList &L)
{
LNode* p = L->next, * pre = L, * max=p, * maxpre=L;
ElemType maxnum=max->data;
while (p != NULL)
{
if (p->data > maxnum)
{
max = p;
maxnum = max->data;
maxpre = pre;
}
pre = p;
p = p->next;
}
maxpre->next = max->next;
free(max);
}
CreateList(L);
MaxNum(L);
程序分析:
- 通过scanf函数来给链表中各结点的数据域赋值,当输入999时,表示结束,不再开辟新的单元。
- !要注意最大值在首结点的情况。
- 运行结果:
- 时间复杂度: O ( n ) O(n) O(n);空间复杂度: O ( 1 ) O(1) O(1)


3.有一个带头结点的单链表L(至少有一个数据结点),使其递增有序排列。
- 算法思路:由于单链表L中有一个以上的数据结点,首先构造一个只含头结点和首结点的有序单链表(只含一个数据结点的单链表一定是有序的)。然后扫描单链表L余下的结点(由p指向),有序单链表中通过比较找插入结点p的前驱结点(由pre指向它),在pre结点之后插入p结点。
void SortNumber(LinkList &L)
{
LNode* p = L->next->next, * s, * pre;
L->next->next = NULL;
while (p != NULL)
{
s = p->next;
pre = L;
while (pre->next != NULL && pre->next->data < p->data)
pre = pre->next;
p->next = pre->next;
pre->next = p;
p = s;
}
}
程序分析:
- 运行结果:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2);空间复杂度: O ( 1 ) O(1) O(1)
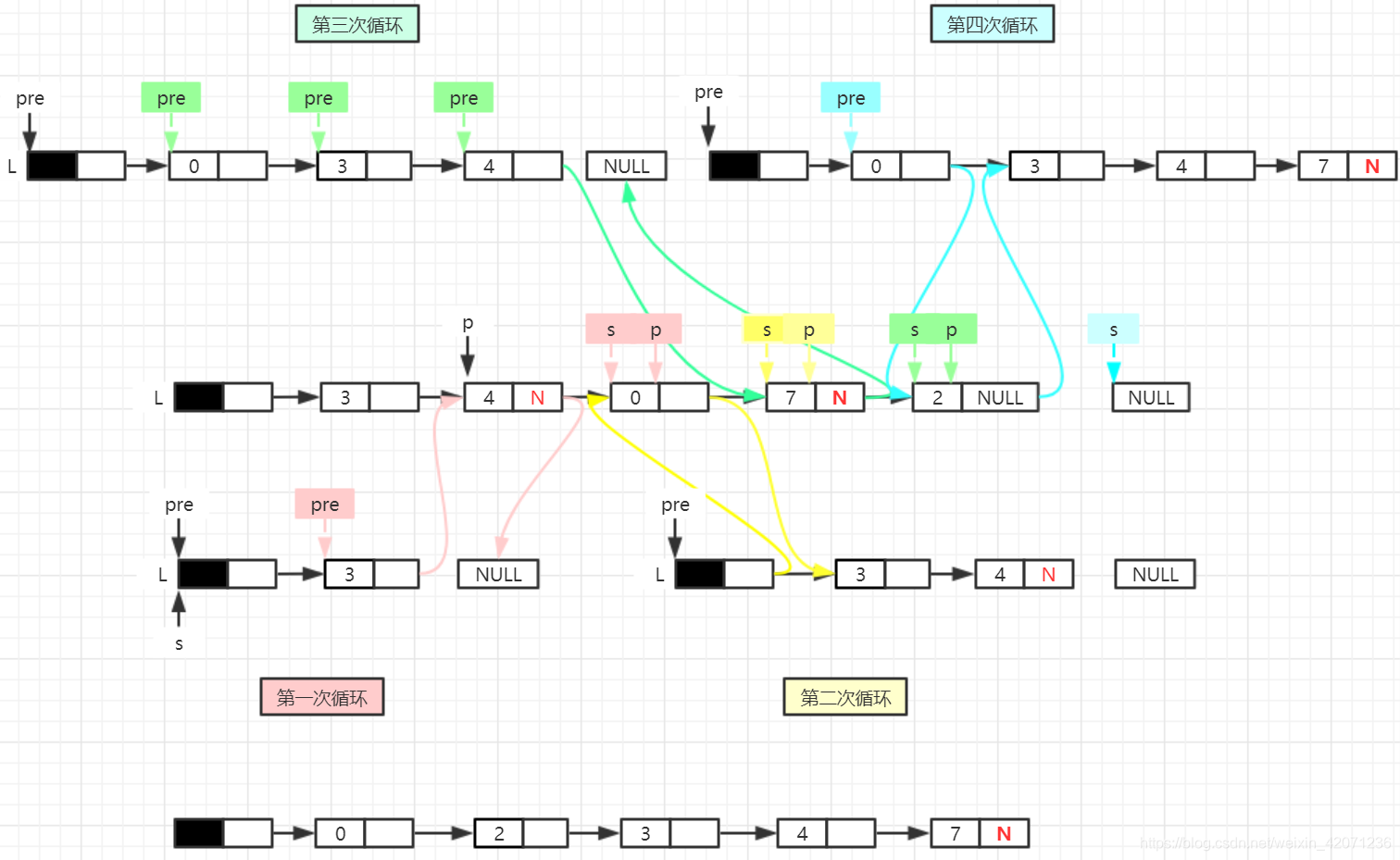

4.一个带头结点的双链表L,将其所有元素逆置。
算法思路:先构造只有一个头结点的空双链表L(利用原来的头结点),用p扫描双链表的所有数据结点,采用头插法将所指结点插入到L中。
void DiverseDList(DLinkList &L)
{
DNode* p = L->next, * s;
L->next = NULL;
int i = 1;
while (p!=NULL)
{
s = p->next;
p->next = L->next;
if (L->next != NULL)
L->next->prior = p;
p->prior = L;
L->next = p;
p = s;
}
}
程序分析:
- 运行结果:
- 时间复杂度: O ( n ) O(n) O(n);空间复杂度: O ( 1 ) O(1) O(1)

5.有一个带头结点的双链表L(至少有一个数据结点),使其元素递增有序排列。
- 算法思路:参考第三题。
程序分析:
- 运行结果:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2);空间复杂度: O ( 1 ) O(1) O(1)

6.有一个带头结点的循环单链表L,统计其data域值为x的结点个数。
- 算法思路:扫描整个循环单链表,用count累计data域值为x的结点个数。
#include<stdio.h>
#include<malloc.h> //用malloc函数开辟新单元时需用此头文件
typedef int ElemType;
typedef struct LNode //定义单链表结点类型
{
ElemType data; //数据域
struct LNode* next; //指针域
}LNode, *LinkList;
void InitList(LNode * &L) //初始化线性表
{
L = (LNode *)malloc(sizeof(LNode)); //创建头结点
L->next = L; //其next域置为NULL
}
void CreateListR(LinkList &L) //头插法创建单链表
{
LNode* s;
int num;
printf("输入:\n");
scanf("%d", &num);
while (num != 999)
{
s = (LNode*)malloc(sizeof(LNode)); //分配一个新的结点
s->data = num;
s->next = L->next;
L->next = s;
scanf("%d", &num);
}
}
void DispList(LinkList &L) //输出单链表
{
LNode* p = L->next; //p指向首结点
while (p->next!=L)
{
printf("%d ", p->data); //输出p结点的data域
p = p->next; //p移向下一个结点
}
}
int CountNum(LinkList &L, ElemType num)
{
LNode* p=L->next;
int count = 0; //用来计数
while (p != L) //当前结点不是尾结点
{
if (p->data == num) count++; //如果data域的值与num相等,计数值+1
p = p->next; //指针后移
}
return count;
}
int main()
{
LNode* L;
InitList(L);
CreateListR(L);
printf("循环单链表中各元素的值为:");
DispList(L);
printf("\n");
printf("单链表中与该数相等的数有:%d个",CountNum(L, 2));
}
程序分析:
- 运行结果:

7.有一个带头结点的循环双链表L,删除第一个data域值为x的结点。
- 算法思路:指针扫描整个循环双链表来查找data值为x的结点,找到后删除p结点,并返回true,若未找到这样的结点返回false。
#include<iostream>
using namespace std;
#include<malloc.h> //用malloc函数开辟新单元时需用此头文件
typedef int ElemType;
typedef struct DNode //定义双链表结点类型
{
ElemType data; //数据域
struct DNode* prior; //指针域
struct DNode* next; //指针域
}DNode, *DLinkList;
void InitList(DNode * &L) //初始化线性表
{
L = (DNode *)malloc(sizeof(DNode)); //创建头结点
L->prior = L; //其next域置为NULL
L->next = L; //其next域置为NULL
}
int ListLength(DLinkList &L)
{
DNode* p = L->next;
int length = 0;
while (p != L)
{
length++;
p = p->next;
}
return length;
}
void CreateListF(DLinkList &L) //头插法创建双链表
{
DNode* s;
int num;
printf("输入:\n");
scanf("%d", &num);
while (num != 999)
{
s = (DNode*)malloc(sizeof(DNode));
s->data = num;
s->next = L->next;
s->next->prior = s;
s->prior = L;
L->next = s;
scanf("%d", &num);
}
}
void DispList(DLinkList &L) //输出双链表
{
DNode* p = L->next; //p指向首结点
while (p!=L)
{
printf("%d ", p->data); //输出p结点的data域
p = p->next; //p移向下一个结点
}
}
bool DeleteElem(DLinkList& L, ElemType num)
{
DNode* p = L->next;
while (p != L)
{
if (p->data == num)
{
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
return true;
}
p = p->next;
}
return false;
}
int main()
{
DNode* L;
InitList(L);
CreateListF(L);
printf("循环单链表中各元素的值为:");
DispList(L);
printf("\n");
printf("当前循环双链表的长度为:%d",ListLength(L));
printf("\n");
cout << boolalpha << "删除成功了吗?——" << DeleteElem(L, 2) << endl;
printf("当前循环双链表的长度为:%d", ListLength(L));
printf("\n");
printf("循环单链表中各元素的值为:");
DispList(L);
printf("\n");
}
程序分析:
- 该算法利用循环双链表L的特点,通过L->prior直接找到尾结点,然后进行结点值的比较,从而判断L的数据结点是否对称。如果是非循环双链表,需要通过遍历查找尾结点,显然不如循环链表的性能好。
- 运行结果:

8. 判断带头结点的循环双链表L(含两个以上的结点)中的数据结点是否对称。
- 算法思路:用p从左向右扫描L,q从右向左扫描L,然后循环。若p、q所指结点的data域不相等,则退出循环,返回false;否则继续比较,直到p==q(数据结点个数为奇数的情况)或者p.next==q(数据结点个数为偶数的情况)为止,这时返回true。
bool SymmElem(DLinkList& L)
{
DNode* p = L->next, * q = L->prior;
bool same = true;
while (same)
{
if (p->data != q->data) same = false;
else
{
if (p == q || p->next == q) break;
p = p->next;
q = q->prior;
}
}
return same;
}
程序分析:
- 运行结果:

9. 假设有两个表A和B,分别是 m 1 m_1 m1行、 n 1 n_1 n1列和 m 2 m_2 m2行、 n 2 n_2 n2列,它们简单自然连接结果C=A(自然链接i=j)B,其中i表示表A中列号,j表示表B中的列号,C为A和B的笛卡儿积中满足指定连接条件的所有记录组,该连接条件为表A的第i列与表B的第j列相等。
#include<stdio.h>
#include<malloc.h>
#define MaxCol 10 //最大列数
typedef int ElemType;
typedef struct Nodel //定义数据结点类型
{
ElemType data[MaxCol]; //存放一行的数据
struct Nodel* next; //指向后继数据节点
}DList; //行结点类型
typedef struct Node2
{
int Row, Col; //行数和列数
DList* next; //指向第一个数据结点
}HList; //头结点的类型
void CreateTable(HList* &h) //采用交互式方式建立单链表
{
int i, j;
DList * r, * s;
h = (HList *)malloc(sizeof(HList)); //创建头结点
h->next = NULL;
printf("表的行数、列数:");
scanf("%d%d", &h->Row, &h->Col); //输入表的行数和列数
for (i = 0; i < h->Row; i++) //输入所以行的数据
{
printf("第%d行:", i + 1);
s = (DList*)malloc(sizeof(DList));
for (j = 0; j < h->Col; j++) //创建数据结点s
scanf("%d", &s->data[j]); //输入一行的数据
if (h->next == NULL) h->next = s; //插入第一个数据结点的情况
else r->next = s; //插入其他数据结点的情况
r = s; //r始终指向尾结点
}
r->next = NULL; //尾结点的next域置空
}
void DispTable(HList*& h)//输出单链表
{
int j = 0;
DList* p = h->next; //p指向开始行结点
while (p != NULL) //扫描所有行
{
for (j = 0; j < h->Col; j++) //输出一行的数据
printf("%4d", p->data[j]);
printf("\n");
p = p->next; //p指向下一个行节点
}
}
void DestroyTable(HList*& h) //销毁单链表
{
DList* pre = h->next, * p = pre->next;
while (p != NULL)
{
free(pre);
pre = p;
p = p->next;
}
free(pre);
free(h);
}
void LinkTable(HList *h1,HList* h2, HList*& h) //表连接
{
int i, j, k;
DList* p = h1->next, * q, * s, * r;
printf("连接字段是:第1个表序号,第2个表序号:");
scanf("%d%d", &i, &j);
h = (HList*)malloc(sizeof(HList)); //创建结果表头结点
h->Row = 0; //置行数为0
h->Col = h1->Col + h2->Col; //置列数为表1和表2的列数和]
h->next = NULL; //置next域为NULL
while (p != NULL) //扫描表1
{
q = h2->next; //q指向表2的首结点
while (q != NULL) //扫描表2
{
if (p->data[i - 1] == q->data[j - 1]) //对应字段值相等
{
s = (DList*)malloc(sizeof(DList)); //创建一个数据结点s
for (k = 0; k < h1->Col; k++) //复制表1的当前行
s->data[k] = p->data[k];
for (k = 0; k < h2->Col; k++)
s->data[h1->Col + k] = q->data[k]; //复制表2的当前行
if (h->next == NULL) //若插入的是第一个数据结点
h->next = s; //将s结点插入到头结点之后将s结点插入到结点r之后
else
r->next = s; //若插人其他数据结点
r = s; //r始终指向尾结点
h->Row++; //表行数增1
}
q = q->next; //表2后移一个结点
}
p = p->next; //表1后移一个结点
}
r->next = NULL; //表尾结点的next域置空
}
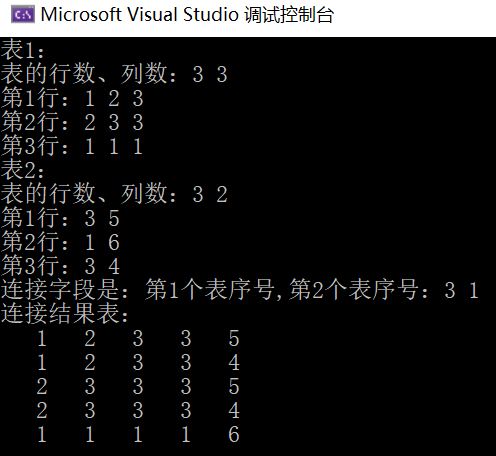
int main()
{
HList* h1, * h2, * h;
printf("表1:\n");
CreateTable(h1); //创建表1
printf("表2:\n");
CreateTable(h2); //创建表2
LinkTable(h1, h2, h); //连接两个表
printf("连接结果表:\n");
DispTable(h); //输出连接结果
DestroyTable(h1); //销毁单链表h1
DestroyTable(h2); //销毁单链表h2
DestroyTable(h); //销毁单链表h
return 0;
}
程序分析:
- 建立单链表的时间复杂度为 O ( m × n ) O(m×n) O(m×n),其中m为表的行数、n为表的列数。
- 销毁单链表的时间复杂度为 O ( m ) O(m) O(m),其中m为表的行数。
- 输出单链表的时间复杂度为 O ( m × n ) O(m×n) O(m×n),其中m为表的行数、n为表的列数。
- 运行结果:
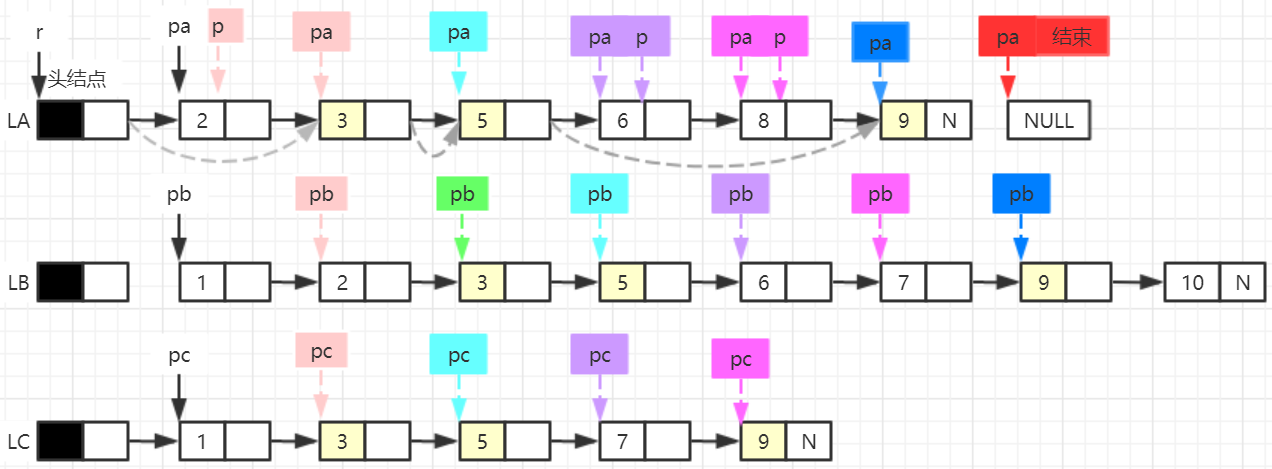
10. 已知3个带头结点的单链表LA、LB和LC中的结点均依元素值递增排列(假设每个单链表不存在数据值相同的结点,但3个单链表中可能存在数据值相同的结点),设计一个算法对LA链表进行如下操作:使操作后的链表LA中仅留下3个表中均包含的数据元素的结点,且没有数据值相同的结点,并释放LA中所有的无用结点。
- 算法思想:先以单链表LA的头结点作为一个空表,r指向这个新建单链表的尾结点。以pa扫描单链表LA的数据结点,判断它是否在单链表LB和LC中,若同时在LB和LC中,表示pa所指结点是公共元素,则将其链接到r所指结点之后,否则删除之。
void CommNode(LinkList& LA, LinkList& LB, LinkList& LC)
{
LNode* pa = LA->next, * pb = LB->next, * pc = LC->next, * r = LA, * p ;
LA->next = NULL; //此时LA作为新建单链表的头结点
while (pa != NULL)
{
while (pb != NULL && pa->data > pb->data) //pa结点与LB中的pb结点进行比较
pb = pb->next;
while (pc != NULL && pa->data > pc->data) //pa结点与LC中的pc结点进行比较
pc = pc->next;
if (pb != NULL && pc != NULL &&
pa->data == pb->data && pa->data == pc->data) //若pa是公共结点
{
r->next = pa; //将pa结点插入到LA中
r = pa;
pa = pa->next; //pa移向下一个结点
}
else //若pa结点不是公共结点,则删除
{
p = pa;
pa = pa->next; //pa移向下一个结点
free(p); //释放非公共结点
}
}
r->next = NULL;
}
程序分析:
- 在上述算法中,指向LA、LB、LC单链表的指针pa、pb、pc都没有出现回溯过程,即每个单链表均只扫描一遍,所以算法的时间复杂度为O(m+n+p),空间复杂度O(1)。其中m、n、p分别是3个表的长度。
- 运行结果:
















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









