







导包:
import io.delta.tables._
import org.apache.spark.sql.functions._
创建DeltaTable对象
- 从文件读取
val deltaTable = DeltaTable.forPath("E:\\cache\\sparkCache\\20200420\\delta-table")
注意:以读取文件方式创建的DeltaTable,每次操作都会直接保存到文件!!!
DeltaTable的普通更新
代码:
package demo01
//注意这里的导包,如果直接写代码,在idea里有时候很难找到具体的包,甚至都不显示提示
//所以最好记住它们
import io.delta.tables._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
object Delta04 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Delta04")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
//首先创建一个DeltaTable对象
val deltaTable = DeltaTable.forPath("E:\\cache\\sparkCache\\20200420\\delta-table")
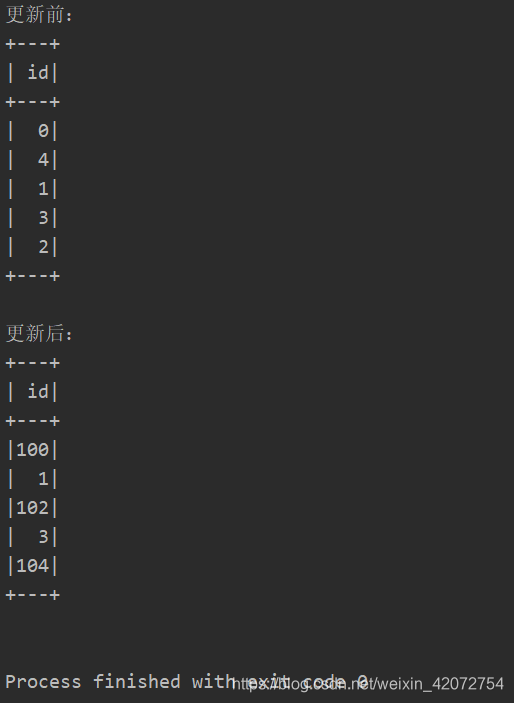
println("更新前:")
deltaTable.toDF.show()
// 把每个偶数都加上100
deltaTable.update(
condition = expr("id % 2 == 0"),
set = Map("id" -> expr("id + 100")))
//第一个参数condition条件,满足条件才更新,第二个参数是操作
println("更新后:")
deltaTable.toDF.show()
}
}
运行结果:
DeltaTable的元素删除
代码:
package demo01
import io.delta.tables._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Delta05 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Delta05")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
val deltaTable = DeltaTable.forPath("E:\\cache\\sparkCache\\20200420\\delta-table")
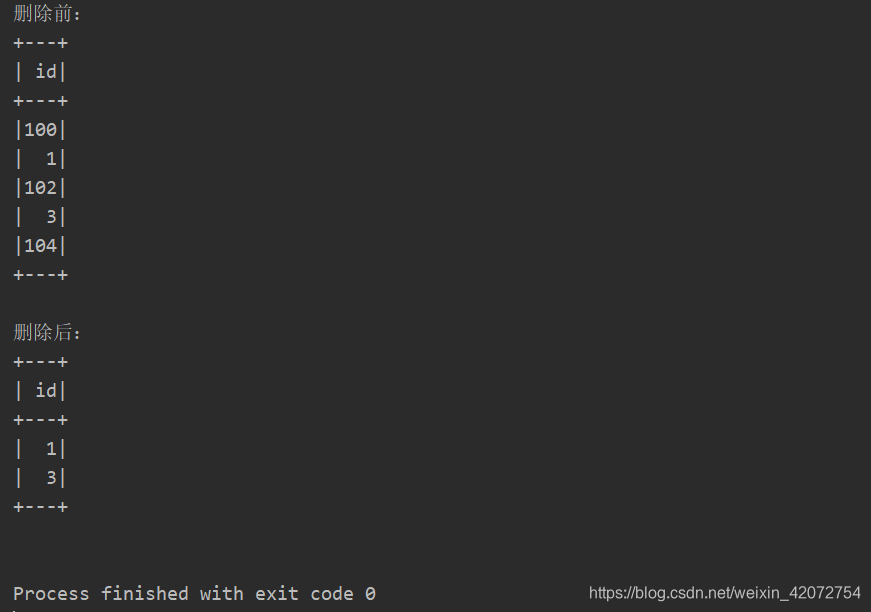
println("删除前:")
deltaTable.toDF.show()
// 删除所有偶数
deltaTable.delete(condition = expr("id % 2 == 0"))
//参数condition条件,满足条件的删除
println("删除后:")
deltaTable.toDF.show()
}
}
运行结果:
DeltaTable的融合更新
package demo01
import io.delta.tables._
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object Delta06 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("Delta06")
.master("local[*]")
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
val deltaTable = DeltaTable.forPath("E:\\cache\\sparkCache\\20200420\\delta-table")
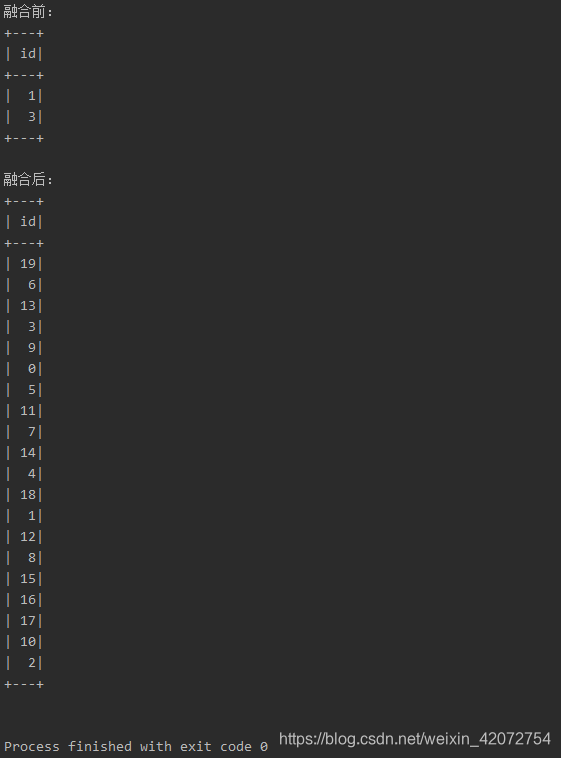
println("融合前:")
deltaTable.toDF.show()
// Upsert (merge) new data (融合式更新插入新数据)
val newData = spark.range(0, 20).toDF
deltaTable.as("oldData")
.merge(
newData.as("newData"),
"oldData.id = newData.id")
.whenMatched
.update(Map("id" -> col("newData.id")))
.whenNotMatched
.insert(Map("id" -> col("newData.id")))
.execute()
//merge是融合两个DeltaTable,第一个参数是要融合的DeltaTable,第二个参数是融合条件
//whenMatched是满足后执行某种操作,这里执行更新操作
//whenNotMatched是不满足时执行某种操作,这里执行插入操作
//execute是执行的意思,没有它相当于定义了操作而没有执行。
//这段话的意思是,如果旧Table里有和新Table里id相同的元素,就把旧Table里的元素替换为id相同的新Table里的元素
//如果旧Table里没有发现新Table里元素的这个id,就把新Table里的元素插入到旧Table里
//这段操作执行完之后,这个deltaTable就融合完了。
println("融合后:")
deltaTable.toDF.show()
//融合完输出看一下
}
}
运行结果:这个可能因为是数字的缘故,结果不太直观,你可以用其他数据试一下,直观感受一下

















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









