







什么是窗口函数
窗口函数在和当前行相关的一组表行上执行计算。 这相当于一个可以由聚合函数完成的计算类型。但不同于常规的聚合函数, 使用的窗口函数不会导致行被分组到一个单一的输出行;行保留其独立的身份。 在后台,窗口函数能够访问的不止查询结果的当前行。
举个例子:
INSERT into score (学号,课程号,成绩) VALUES ('0001','0001',90);
INSERT into score (学号,课程号,成绩) VALUES ('0001','0002',85);
INSERT into score (学号,课程号,成绩) VALUES ('0001','0003',75);
INSERT into score (学号,课程号,成绩) VALUES ('0002','0001',85);
INSERT into score (学号,课程号,成绩) VALUES ('0002','0002',96);
INSERT into score (学号,课程号,成绩) VALUES ('0002','0003',100);
INSERT into score (学号,课程号,成绩) VALUES ('0003','0001',61);
INSERT into score (学号,课程号,成绩) VALUES ('0003','0002',73);
INSERT into score (学号,课程号,成绩) VALUES ('0003','0003',82);
INSERT into score (学号,课程号,成绩) VALUES ('0004','0001',66);
INSERT into score (学号,课程号,成绩) VALUES ('0004','0002',77);
INSERT into score (学号,课程号,成绩) VALUES ('0004','0003',88);
INSERT into score (学号,课程号,成绩) VALUES ('0009','0003',50);
如何比较每个学生的成绩和在他或她的班级的平均成绩:
-- 如何比较每个学生的成绩和在他或她的班级的平均成绩
SELECT 班级,学号,成绩,AVG(成绩)
OVER (PARTITION BY 班级) AS 班级平均成绩
FROM score_new;

这里使用了新的SQL函数,这个函数就是窗口函数。前三输出列直接来自表score,并有一个针对表中的每一行的输出行,第四列将代表所有含有相同的班级的表行的平均值作为当前值。
窗口函数的调用总是包含一个OVER子句,后面直接跟着窗口函数的名称和参数。 这是它在语法上区别于普通函数或聚合功能的地方。 窗口函数基本语法如下:
‹窗口函数› over (partition by ‹用于分组的列名›
order by ‹用于排序的列名›)
日常工作中,我们可以通过窗口函数解决很多问题,比如:分组取每组最大值、最小值,每组最大的N条(top N)记录等,我们都可以使用窗口函数。
如何使用窗口函数
接下来,就结合实例,给大家介绍几种窗口函数的用法:
1.rank():返回数据集中每个值的排名。排名值是根据当前行之前的行数加1,不包含当前行。因此,排序的关联值可能产生顺序上的空隙。 这个排名会对每个窗口分区进行计算;
2.dense_rank():返回一组数值中每个数值的排名。这个函数与 rank() ,相似,除了关联值不会产生顺序上的空隙;
3.percent_rank():返回数据集中每个数据的排名百分比。结果是根据 (r - 1) / (n - 1) 其中 r 是由 rank() 计算 的当前行排名, n 是当前窗口分区内总的行数;
4.row_number():为每行数据返回一个唯一的顺序的行号,从1开始,根据行在窗口分区内的顺序;
5.cume_dist():返回一组数值中每个值的累计分布。 结果返回的是按照窗口分区下窗口排序后的数据集下,当前行前面包括当前行数据的行数。因此,排序中任何关联值均会计算成相同的分布值.。
实例来看:
-- 各窗口函数
SELECT *,
rank() over (ORDER BY 成绩 DESC )as ranking,
dense_rank() over (ORDER BY 成绩 DESC )as dense_ranking,
ROUND(percent_rank() over (ORDER BY 成绩 DESC ),2)as percent_ranking,
row_number() over (ORDER BY 成绩 DESC )as row_num,
cume_dist() over (ORDER BY 成绩 DESC )as cume_d
FROM score_new;

可以看出:
rank()函数,例子中存在名次是并列的情况时,会占用下一名次位置。比如说,正常排名1,2,3,4,5,6······但是使用rank()函数,结果就是1,2,3,4,4,6······;
dense_rank()函数,例子中存在名次是并列的情况时,不会占用下一名次位置。比如说,正常排名1,2,3,4,5,6······但是使用dense_rank()函数,结果就是1,2,3,4,4,5······;
percent_rank()函数,例子中percent_rank函数是在rank()函数基础上进行百分比计算排名百分比,比如第4名的排名百分比 = (r - 1) / (n - 1) = (4 - 1) / (20 - 1) =0.16;
row_number()函数,例子中存在名次是并列的情况,但也不会对并列名次考虑,比如说,正常排名1,2,3,4,5,6······使用row_number()函数,结果就是1,2,3,4,5,6······;
cume_dist()函数,例子中返回的都是落在每个成绩中的累积概率,比如说,有20个学生成绩每个成绩概率是0.5,但是有存在相同成绩n个,那这个成绩的概率是0.5*n,那累计概率就是说落在了这个成绩上的概率面积,这里因为成绩是降序的我们可以理解为成绩>=该成绩的所有概率和。
下面我们举例来看:查找每个班级成绩最高的2个学生成绩数据。
在这之前,我们先想一下,查找每个班级最大成绩的学生数据怎么查询?
-- 按班级号分组取成绩最大值所在行的数据
/*
SELECT MAX(成绩) FROM score_new GROUP BY 班级;
SELECT * FROM score WHERE 成绩 = <关联子查询>;
*/
SELECT *
FROM score_new as a
WHERE 成绩 =
(SELECT MAX(成绩) FROM score_new AS b WHERE a.班级=b.班级 GROUP BY 班级);

查找每个班级成绩最高的2个学生成绩数据:
拆分两步:
1.先按班级分组,并按照成绩降序排列,查看各班成绩排名:
/*
先按班级分组,并按照成绩降序排列
SELECT *, row_number() over ( PARTITION BY 班级 ORDER BY 成绩 DESC) AS row_num FROM score_new;
*/
SELECT *,
row_number() over ( PARTITION BY 班级 ORDER BY 成绩 DESC) AS row_num
FROM score_new;

2.只要我们筛选row_num值<=2即可,我们可以用子查询:
SELECT *
FROM
(SELECT *,
row_number() over ( PARTITION BY 班级 ORDER BY 成绩 DESC) AS row_num
FROM score_new) AS a
WHERE row_num <=2;

这里我们使用了partition by ,在over子句中,partition by 列表指定将行划分成组或分区, 组或分区共享相同的partition by表达式的值,意思就是可以分组。但是需要注意的是,partition by与group by 不同:
partition by相比group by,能够在保留全部数据的基础上对其中某些字段做分组排序;
但group by则只保留参与分组的字段和聚合函数的结果;
聚合函数作为窗口函数
窗口函数,除了可以使用刚才提到的专用窗口函数外,还可以使用聚合函数。
所有聚合函数可以通过添加 OVER 子句来作为窗口函数使用。这些聚合函数会基于当前滑动窗口内的数据行计算每一行数据。
我们可以实例来看一下:
-- 各窗口函数-聚合函数
SELECT *,
SUM(成绩) over (PARTITION BY 班级 ORDER BY 成绩 DESC )as score_sum,
AVG(成绩) over (PARTITION BY 班级 ORDER BY 成绩 DESC )as score_avg,
MIN(成绩) over (PARTITION BY 班级 ORDER BY 成绩 DESC )as score_min,
MAX(成绩) over (PARTITION BY 班级 ORDER BY 成绩 DESC )as score_max
FROM score_new;

我们可以看的到,不管是sum()、avg(),还是min()、max(),他们在窗口函数中,都是对自身记录以及位于自身记录之前的数据进行聚合,求和、求平均、最小值、最大值。
所以,聚合函数作为窗口函数的时候可以在每一行的数据里直观的看到,截止到本行数据统计数据是多少,也可以看出每一行数据对整体的影响。
窗口函数的移动平均
先说一下移动平均数:
若依次得到测定值(x1,x2,x3···,xn)时,按顺序取一定个数所做的全部算术平均值。 例如:
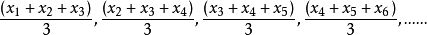
那移动平均数有什么用呢?我们可以通过移动平均,直观地查看到与相邻数据的平均、求和等统计数据。移动平均可以进行即期预测,当产品需求既不快速增长也不快速下降的时候(不存在季节因素),移动平均能有效的消除预测中的随机波动。
-- 窗口的移动平均
select *,
avg(成绩) over (order by 班级 rows 2 preceding )as current_avg
from score_new;

总结:
窗口函数原则上只能写在select子句中。
大家在以下场景中,就可以使用我们的窗口函数哟:
① 经典的TopN问题;比如像前边我们查找每个班级成绩最高的2个学生成绩数据;
② 经典排名问题:比如按班级对学生成绩进行排名;
③ 在每个组里的比较问题:比如查找每个班级里成绩大于该班级平均成绩的学生排名。















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









