







基于单模式串和Trie树实现的敏感词过滤
我们前面讲了好几种字符串匹配算法,有BF,RK算法,BM算法,KMP算法,还有Trie树,前面四种都是单模式匹配算法,只有Trie树是多模式串匹配算法。
单模式匹配算法,是在一个模式串和一个主串之间进行匹配,也就是说,在一个主串中查找一个模式串。多模式串匹配算法,就是在多个模式串和一个主串之间作匹配。也就是说,在一个主串中查找多个模式串。
我们可以对敏感词进行预处理,构建成trie树结构。这个预处理的操作只需要做一次,如果敏感词字典动态更新了,比如删除,添加了一个敏感词,我们只需要动态更新一下Trie树就行。
当用户输入一个文本内容之后,我们把用户输入的内容作为主串,从第一个字符开始,在Trie树中匹配。当匹配到Trie树的叶子节点或者中途遇到不匹配的字符的时候,我们将主串的开始匹配位置后移一位,也就是在下一位开始。
这种基于Trie树的处理方法,有点类似单模式串匹配的BF算法。我们知道,单模式串匹配算法中,KMP算法对BF进行改进,引入了next数组,让匹配失效的时候,尽可能多移动几位。那么这里的AC自动机也是同样的道理。
经典的多模式串匹配算法:AC自动机
其实Trie树跟AC自动机算法之间的关系,就像单串匹配中朴素的串匹配算法,跟KMP之间的关系一样,只不过前者针对的是多模式串而已。所以,AC自动机实际上就是在Trie树上,加了类似KMP的next数组,只不过此处的next数组是构建在树上罢了。
所以,AC自动机的构建,包含两个操作:
- 将多个模式串构建成Trie树
- 在Trie树上构建失败指针(相当于KMP中的失效函数next数组)
这里给出构建的代码:
class ACNode{
public:
char data;
ACNode** children = new ACNode[26];
bool isEngingChar;
int length;// 当isEndingChar = true时,记录模式串的长度
ACNode* fail;// fail指针
ACNode(){
}
};
class AC{
public:
ACNode* root;
public:
AC(){
root->data = '/';
root->fail = NULL;
root->isEngingChar = false;
root->length = -1;
for(int i=0;i<26;++i){
root->children[i] = NULL;
}
}
void insert(char* text,int size){
ACNode* p = root;
for(int i=0;i<size;++i){
int index = text[i] - 'a';
if(p->children[index] == NULL){
ACNode* NewNode = new ACNode;
NewNode->data = text[i];
p->children[index] = NewNode;
}
p = p->children[index];
}
p->isEngingChar = true;
p->length = size;
}
};那么,如何构建失败指针?
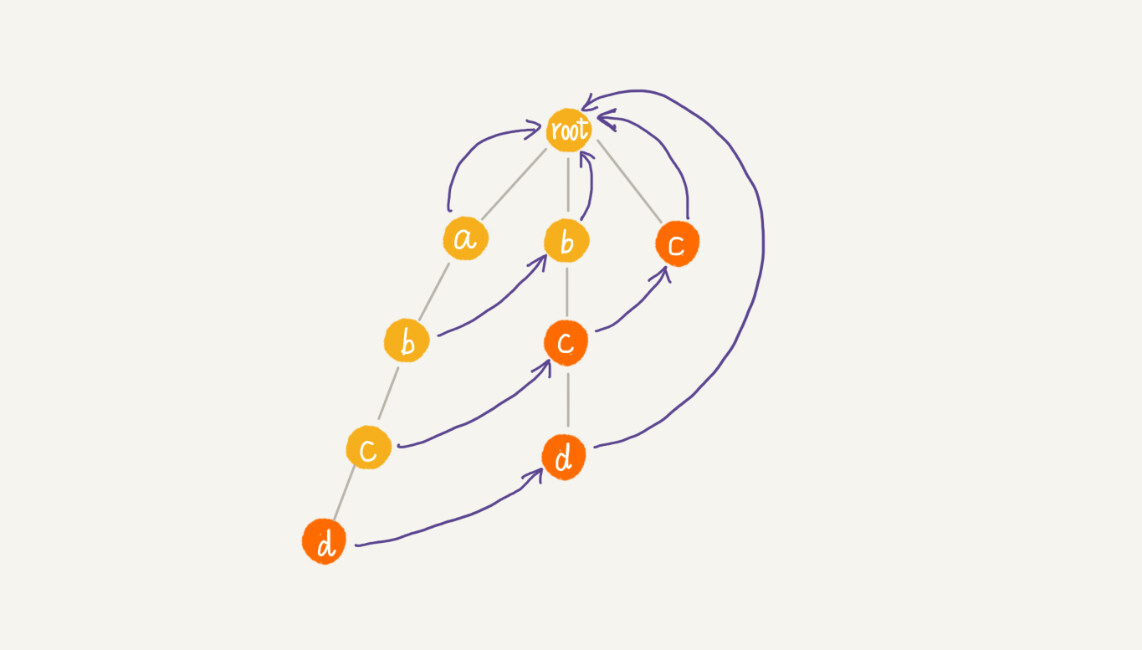
举个例子,这里有4个模式串,分别是c,bc,bcd,abcd。主串是abcd。
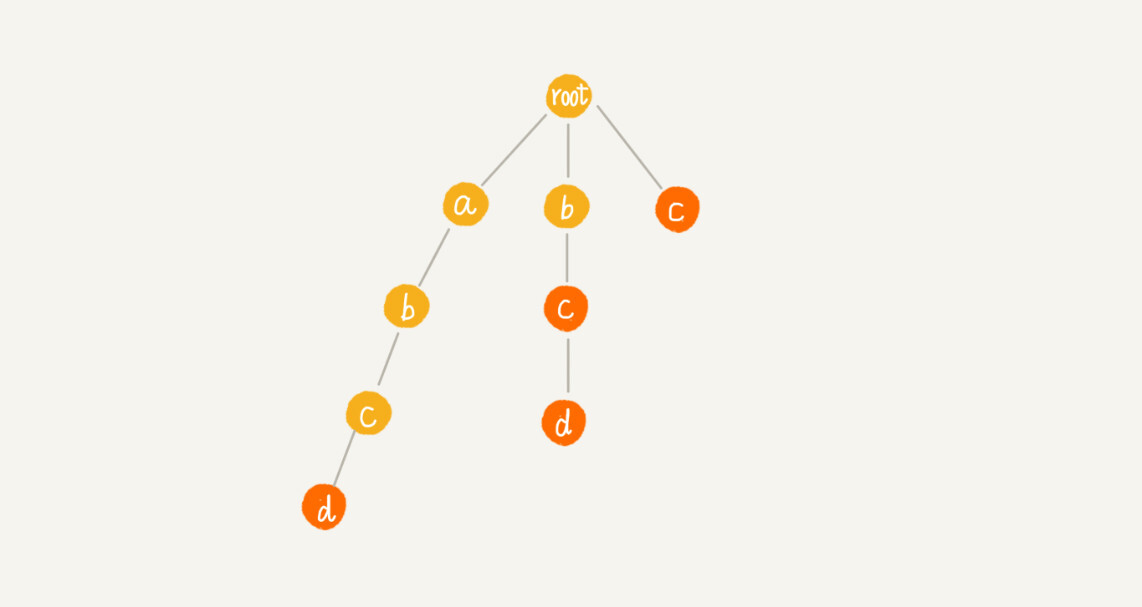
假设我们沿Trie树走到p节点,也就是紫色的节点,那P的失败指针就是从root走到紫色节点形成的字符串abc,跟所有模式串前缀匹配的最长可匹配后缀子串,就是箭头指的bc模式串。我们从可匹配后缀子串中,找出最长的一个,就是刚刚讲到的最长可匹配后缀子串。我们将p节点的失败指针指向那个最长匹配后缀子串对应的模式串的前缀的最后一个节点。
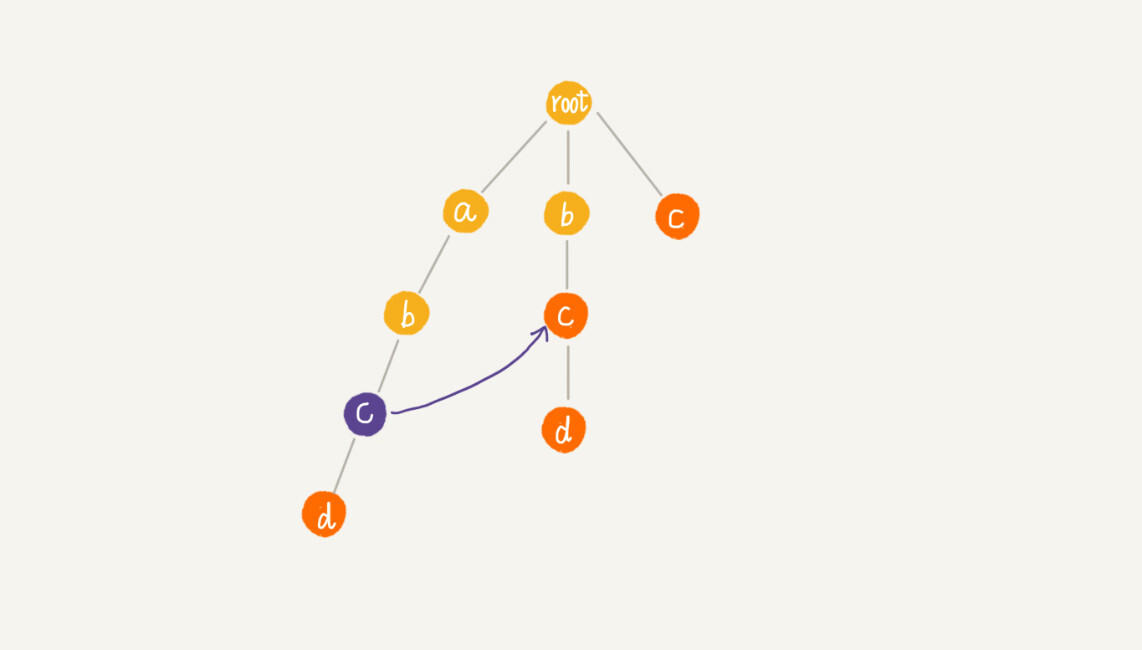
计算每个节点的失败指针这个过程看起来有些复杂,其实,如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在的上一层。
我们可以像KMP算法一样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。所以,我们是按层依次来求解每个节点的失败指针,所以,失败指针的构建过程,是一个按层遍历树的过程。
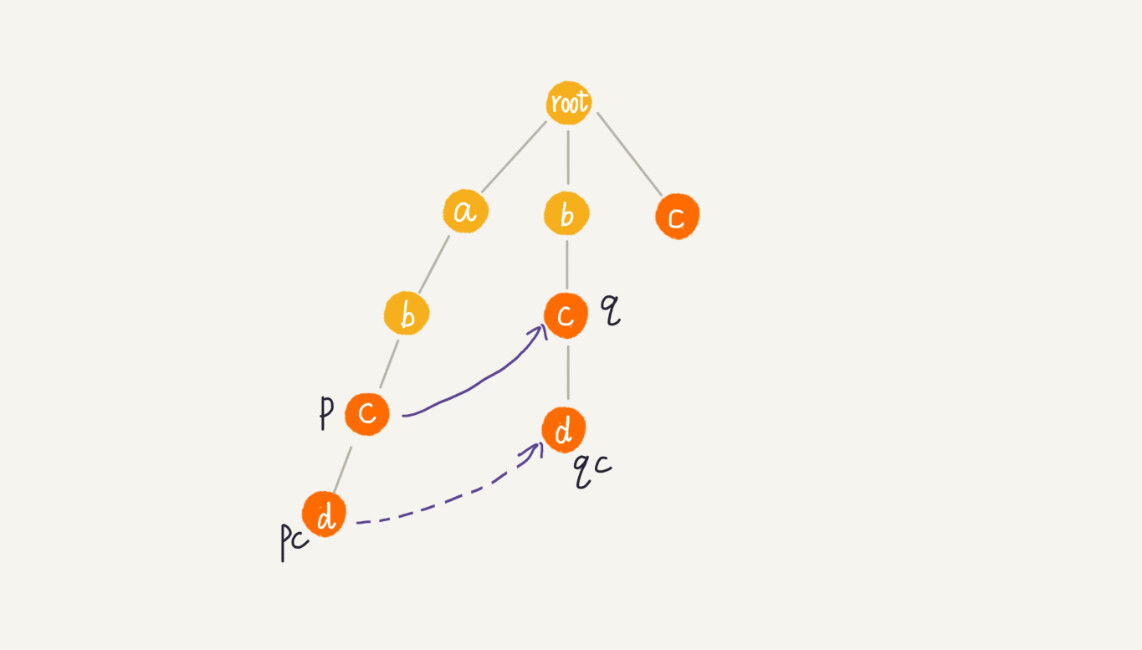
那么,当我们已经求得某个节点p的失败指针之后,如何寻找它的子节点的失败指针?
我们假设节点p的失败指针指向节点q,我们看节点p的子节点pc对应的字符,是否也可以在节点q的子节点中找到。如果找到了节点q的一个子节点qc,对应的字符跟节点pc对应的字符相同,则将节点pc的失败指针指向节点qc。
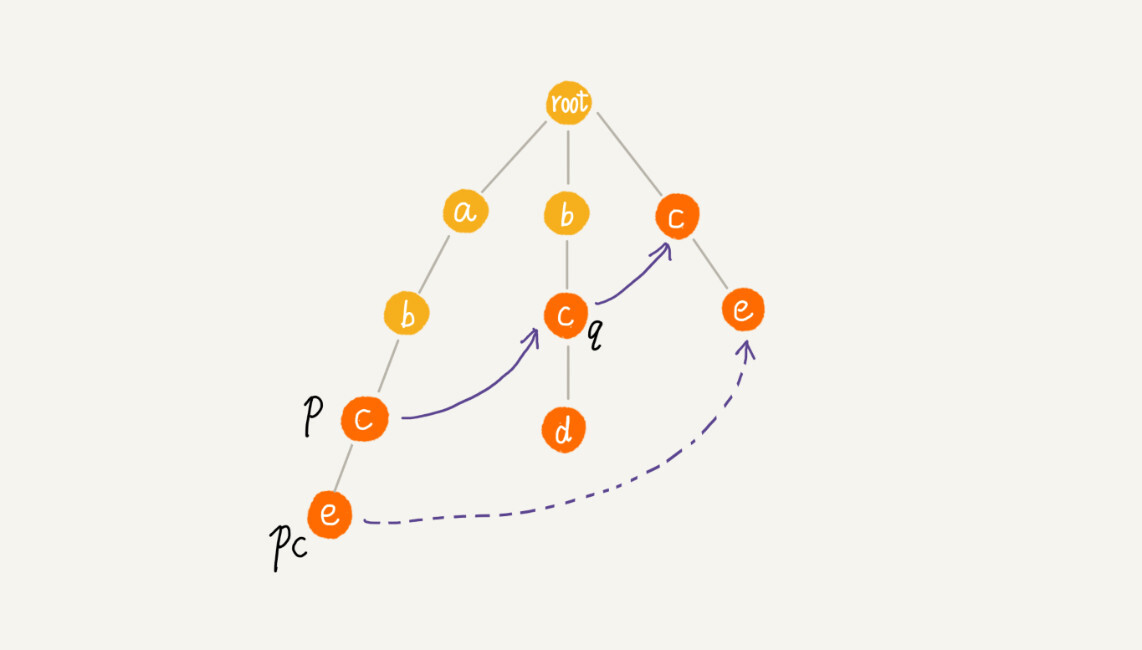
如果节点p中没有子节点的字符等于节点pc包含的字符,则令q = q->fail(fail表示失败指针),继续上面的查找,直到q为root为止,如果还没有找到,就让节点pc的失败指针指向root。
这里把构建失败指针的代码给出:
void buildFailurePointer(){
queue<AcNode*> que;// 按层遍历需要一个队列来实现
que.push(root);
while(!que.empty()){
AcNode* p = que.pop();// 取出每一个节点,对这个节点的孩子节点全部考察
for(int i=0;i<26;++i){
AcNode* pc = p->children[i];
if(pc == NULL) continue;
if(p == root){// 当取出的节点是root的时候,全部的子节点的fail指针都指向root
pc->fail = root;
}else{
AcNode* q = p->fail;// 先看父节点p的fail指向的下一个字符是否跟p的字节点一样
while(q != NULL){
AcNode* qc = q.children[pc->data - 'a'];// 判断是否相同
if(qc != NULL){
pc->fail = qc;// 相同的情况
break;
}
q = q->fail;// 不相同,继续找之前的后缀子串,直到root退出
}
if(q == NULL){// 找不到,fail 指向root
pc->fail = root;
}
}
que.add(pc);
}
}
}通过按层来计算每个节点的子节点的失败指针,刚刚举例,最后构建完成之后的AC自动机就是下面这样:
如何在AC自动机上匹配主串?
在匹配过程中,主串从i = 0开始,AC自动机从指针p = root 开始,假设模式串是b,主串是a。
- 如果p指向的节点有一个等于 b[i] 的子节点x,我们就更新p 指向 x。这个时候,我们需要通过失败指针,检测一系列失败指针为结尾的路径是否是模式串。处理完之后,我们将i 加1,继续这两个过程。
- 如果p指向的节点没有等于b [i] 的子节点,那失败指针就派上用场,我们让p = p->fail。继续这2个过程。
这里给出代码:
void match(char* text,int size){
AcNode* p = root;
for(int i=0;i<size;++i){
int index = text[i] - 'a';// 得到索引
while(p->children[index] == NULL && p!=root){
p = p->fail;// fail 指针派上用场
}
p = p->children[index];
if (p == NULL) p = root;// 没有匹配的,就重新在root开始匹配
AcNode* tmp = p;
while(tmp != root){// 找出一系列失败指针结尾的路径是否是模式串
if(tmp->isEngingChar == true){
int pos = i-tmp->length+1;
cout << "匹配起始下标:" << pos << "长度:" << tmp->length << endl;
}
tmp = tmp->fail;
}
}
}测试的代码:
char* s[5] = {"fuck","fuckyou","cao","nimabi","nmasile"};
Ac Ac_Auto;
for(int i=0;i<5;++i){
cout << s[i] << endl;
Ac_Auto.insert(s[i]);
}
char* text = "fuckyouaaaaa";
Ac_Auto.buildFailurePointer();
Ac_Auto.match(text,9);AC自动机复杂度分析
我们上一节讲过,Trie树构建的时间复杂度是O(m*len),其中len表示敏感词的平均长度,m表示敏感词的个数。那构建失败指针的时间复杂度是多少呢?
假设Trie树总的节点个数是k,每个节点构建失败指针的时候,最耗时的是while循环中的q = q->fail,每运行一次,q指向节点的深度都会减小1,而树的最大高度不会超过len,所以,整个失败指针的构建过程就是O(k*len)。
不过,AC自动机的构建过程都是预先处理的,构建完之后,并不会频繁地更新,所以不会影响敏感词过滤的运行效率。
跟刚构建失败指针的分析类似,for循环依次遍历主串中的每个字符,for循环内部最耗时的是while循环,而这一部分的时间复杂度也是O(len),所以总的匹配的时间为O(n*len),可能近似与O(n)。实际上,大部分情况失败指针都指向root,所以绝大部分情况下,在AC自动机上作匹配的效率要远高与刚刚算出来的时间复杂度。














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









