







表达能力
MapReduce需要将所有计算转换为Map和Reduce,难以描述复杂处理过程;
Spark除Map和Reduce外,还支持RDD/DataFrame/DataSet等多种数据模型操作,编程模型更加灵活。
磁盘IO
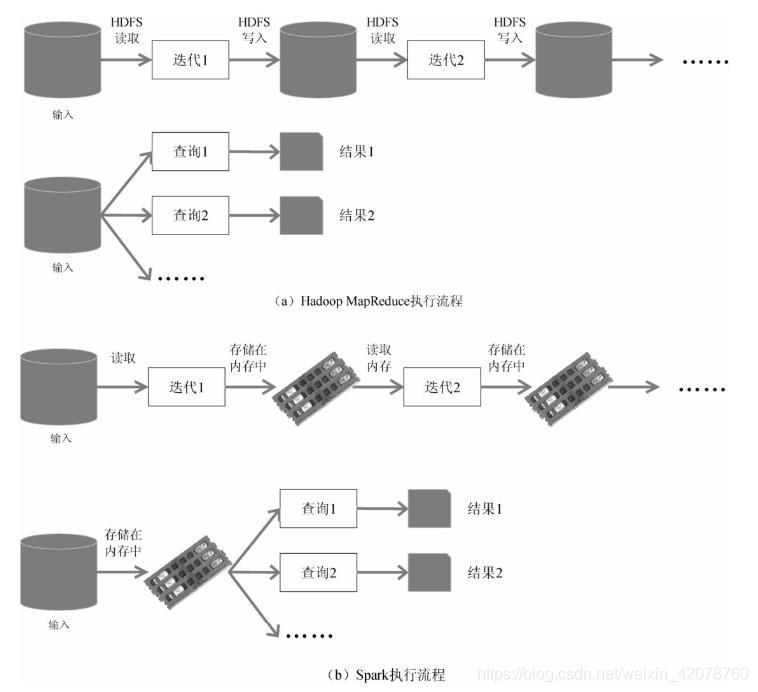
MapReduce每步运算都要从磁盘读取数据,结束后写入磁盘数据,仅有小部分数据作为临时缓存放入内存,磁盘IO开销比较大;
Spark将中间结果直接放入内存,既提高了迭代运算效率,又避免了大量的重复计算,据官方提供数据,同样迭代运算效率Spark:Hadoop=110:0.9。
任务延迟
MapReduce将任务分成一系列运算顺序执行,每次运算涉及磁盘IO,任务间衔接不及时,需要等上步完成才能进行下步运算,无法满足复杂任务和多阶段计算任务需求;
Spark基于DAG任务调度执行机制,不涉及磁盘IO延迟,迭代运算更快。
内存管理
MapReduce任务在启动时已经在JVM内指定了最大内存,不能超过指定的最大内存;
Spark在超过指定最大内存后,会使用操作系统内存,既保证了内存的基本使用,又避免了提早分配过多内存带来的资源浪费
并行处理
MapReduce中一个进程运行一个task,按序执行;
Spark中一个线程运行一个task,增加了并行度。

















 835
835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









