







达梦数据库DM8-多表连接查询
系列文章目录
第九章 达梦数据库DM8-多表连接查询本文仅为粗浅介绍,详细的学习分享建议移步另一篇博文查看。
第十四章 达梦数据库DM8-多表连接学习分享
本文环境
系统环境:
windows 7 sp1
软件镜像:
dm8_20201112_x86_rh7_64_ent_8.1.1.144.iso
1、达梦数据库连接查询介绍
如果一个查询包含多个表(>=2),则称这种方式的查询为连接查询。即<FROM 子句>中使用的是<连接表>。DM 的连接查询方式包括:交叉连接(cross join)、自然连接(naturaljoin)、内连接(inner)、外连接(outer)。
2、交叉连接(cross join)迪卡集
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 11 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | TTT_ID |
| -------- | ----- | ----- |
| 11 | 李宁 | 111 |
| 233 | 刘明 | 233 |
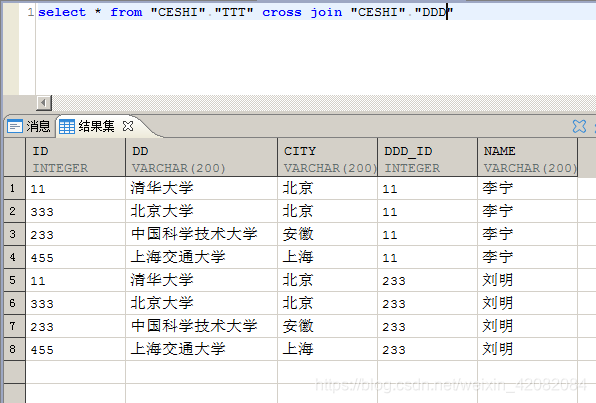
2.1 无过滤条件
对连接的两张表记录做笛卡尔集,产生最终结果输出。
2.1 有过滤条件
对连接的两张表记录做笛卡尔集,根据 WHERE 条件进行过滤,产生最终结果输出。
select * from "CESHI"."TTT" T1 cross join "CESHI"."DDD" T2 where T1.ID=T2.TTT_ID;

3、自然连接
把两张连接表中的同名列作为连接条件,进行等值连接,我们称这样的连接为自然连接。
自然连接具有以下特点:
1. 连接表中存在同名列;
2. 如果有多个同名列,则会产生多个等值连接条件;
3. 如果连接表中的同名列类型不匹配,则报错处理。
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
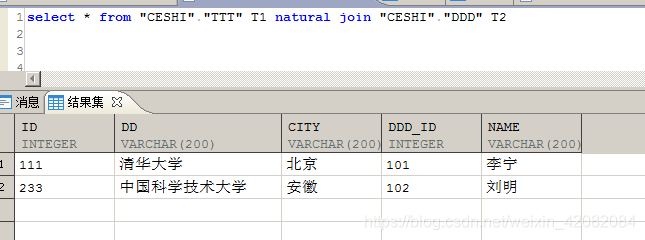
select * from "CESHI"."TTT" T1 natural join "CESHI"."DDD" T2 ;
TTT表和DDD表的同名列为ID,所以自然连接以其作为等值条件进行查询,结果如下。
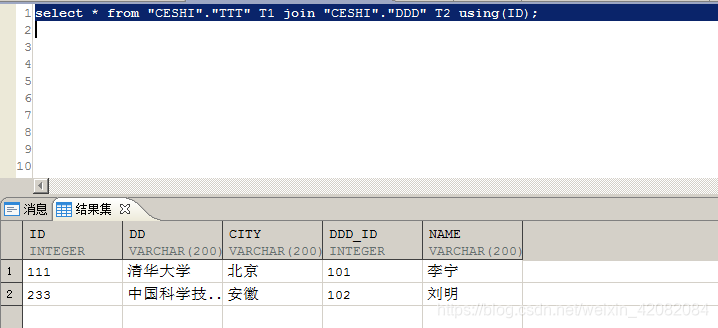
自然连接也可以指定连接列:join…using… 写法
select * from "CESHI"."TTT" T1 join "CESHI"."DDD" T2 using(ID);
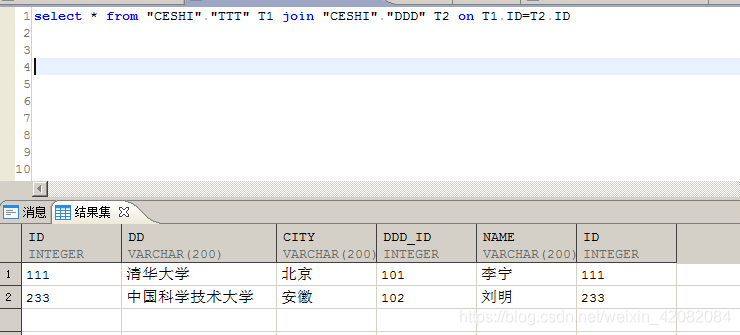
4、join…on 写法
join后接连接表,on接连接条件,是很常见的连接写法,其连接方式是由数据库内部自行决定。
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
select * from "CESHI"."TTT" T1 join "CESHI"."DDD" T2 on T1.ID=T2.ID
5、自连接
数据表与自身进行连接,我们称这种连接为自连接。
自连接查询至少要对一张表起别名,否则,服务器无法识别要处理的是哪张表
创建测试表TTT如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
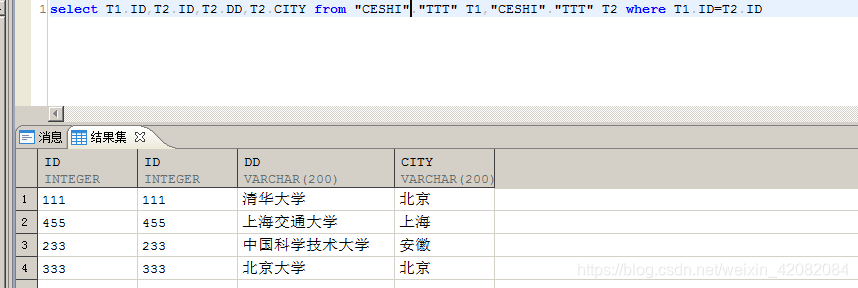
| 加上表别名后,利用TTT表的ID列自己进行等值连接查询。 |
select T1.ID,T2.ID,T2.DD,T2.CITY from "CESHI"."TTT" T1,"CESHI"."TTT" T2 where T1.ID=T2.ID
6、内连接(INNER JOIN)
根据连接条件,结果集仅包含满足全部连接条件的记录,我们称这样的连接为内连接。
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
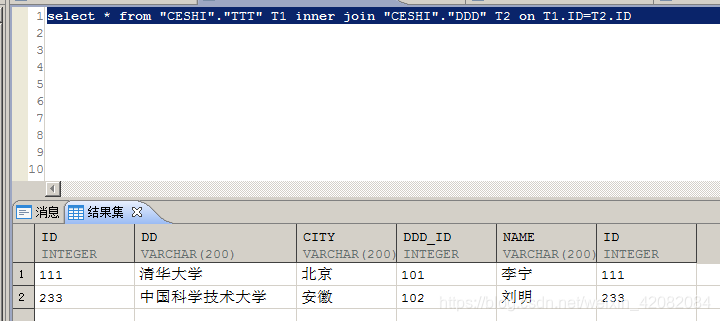
利用ID列作为等值条件查询,结果只包含符合等值条件的值。
select * from "CESHI"."TTT" T1 inner join "CESHI"."DDD" T2 on T1.ID=T2.ID
7、外连接
外连接对结果集进行了扩展,会返回一张表的所有记录,对于另一张表无法匹配的字段用 NULL 填充返回
7.1 left join(左外连接)
返回左表所有内容,右表返回符合条件的内容,不符合条件的以null填充。
创建两张测试表TTT,DDD如下:
TTT表
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
| 103 | 王红 | 888 |
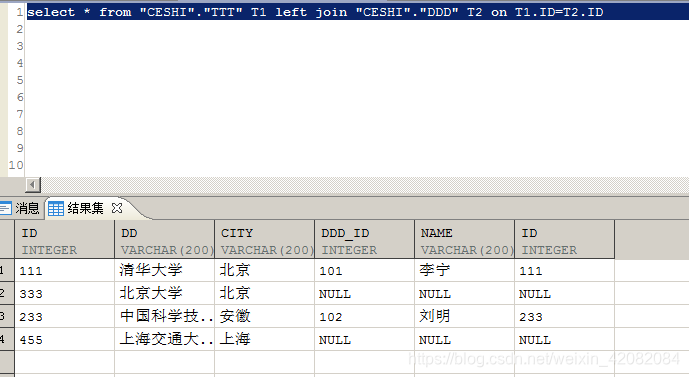
select * from "CESHI"."TTT" T1 left join "CESHI"."DDD" T2 on T1.ID=T2.ID
结果如下,可以看到左表TTT表ID为333和455的内容在右表DDD表没有匹配项,是以NULL填充。
7.2 ritght join(右外连接)
返回右表所以内容,左表返回符合条件的内容,不符合条件的以null填充。
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
| 103 | 王红 | 888 |
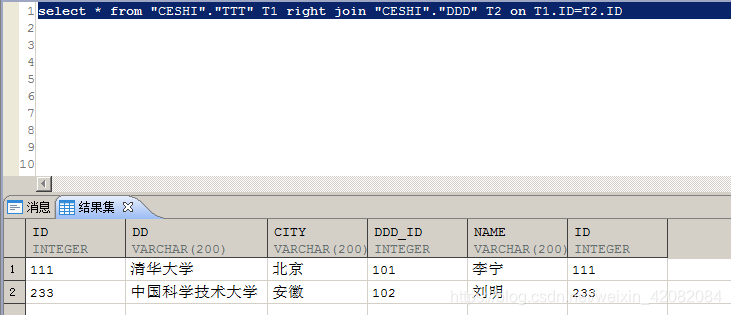
select * from "CESHI"."TTT" T1 right join "CESHI"."DDD" T2 on T1.ID=T2.ID
结果如下,可以看到右表DDD表的内容TTT表都有匹配项。所以没有NULL填充
7.3 full join(全外连接)
左外连接+右外连接
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
| 103 | 王红 | 888 |
select * from "CESHI"."TTT" T1 full join "CESHI"."DDD" T2 on T1.ID=T2.ID
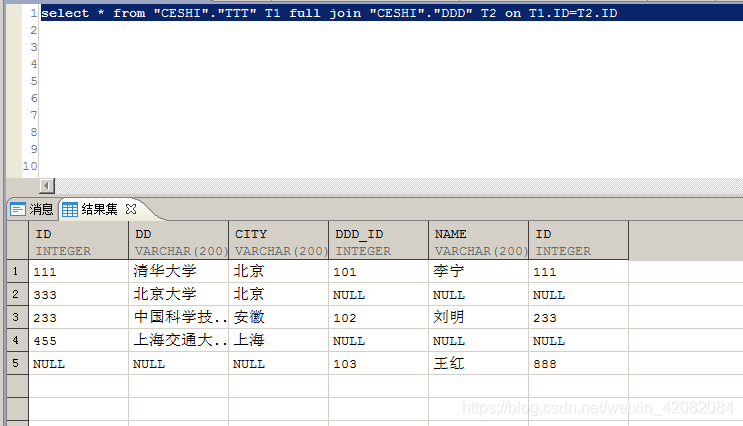
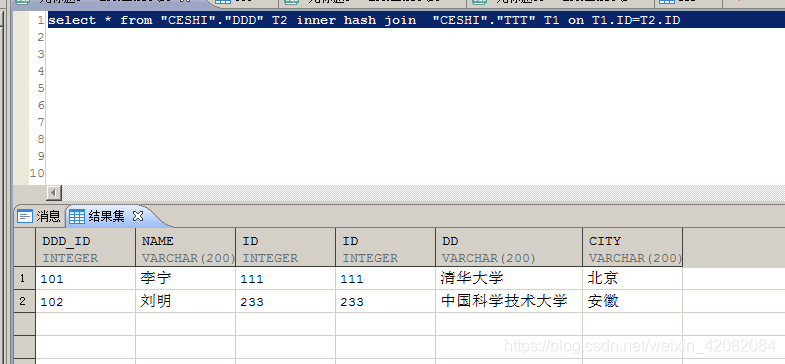
8、hash join
优化器 CBO,根据小表的连接列生成 hash 值,根据 hash 值去连接大表,扫描大表。一般小表放在前面。
创建两张测试表TTT,DDD如下:
TTT表
| ID | DD | CITY |
|---|---|---|
| 111 | 清华大学 | 北京 |
| 333 | 北京大学 | 北京 |
| 233 | 中国科学技术大学 | 安徽 |
| 455 | 上海交通大学 | 上海 |
| DDD表 | ||
| DDD_ID | NAME | ID |
| -------- | ----- | ----- |
| 101 | 李宁 | 111 |
| 102 | 刘明 | 233 |
| 103 | 王红 | 888 |
select * from "CESHI"."DDD" T2 inner hash join "CESHI"."TTT" T1 on T1.ID=T2.ID
9、union 和union all
UNION 和 UNION ALL 的区别是前者会过滤掉值完全相同的元组,为此 UNION 操作符需要建立 HASH 表缓存所有数据并去除重复,当 HASH 表大小超过了 INI 参数指定的限制时还会做刷盘。
因此如果应用场景并不关心重复元组或者不可能出现重复,那么 UNION ALL 无疑优于UNION
本文参考文档:DM8_SQL语言使用手册.pdf

















 5223
5223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









