







介绍
传统的urllib只能爬取静态网站,像Ajax内容则无法显示。
所以想爬取,可以使用requests方法
代码
示例http://www.kfc.com.cn/kfccda/storelist/index.aspx的爬取
1.打开网站后,打开开发者工具(F12),点击XHR,该栏目只显示ajax的请求

注意到,请求URL是http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname而非上边的URL
查看Form Data
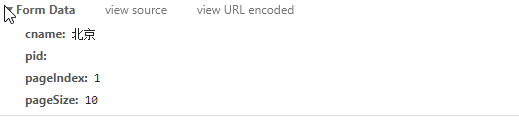
这是要用到的
代码
import requests
import re
class kfc_home(object):
def __init__(self):
self.url = "http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
def get_page(self):
#请求头,浏览器标识
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
#请求的参数
param = {
'cname': '北京',
'pageIndex': '1',
'pageSize': '10',
'pid':''
}
#data = requests.get(self.url,headers=headers,params=param) 也可以不知道为什么
data = requests.post(self.url, headers=headers, params=param)
print(data.text)
return data.text
if __name__ == "__main__":
kfc = kfc_home()
data = kfc.get_page()















 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









