






缓存
- Nosql(Not only SQL)系列缓存包括Memcached、MongoDB、Redis、Cas-sandra、Tokyo Tyrant等产品
- 缓存组件都是同时结合内存和硬盘的,当内存满后,将部分数据持久化到硬盘,或定期dump把内存的数据写入硬盘,防止数据丢失
- 缓存三要素:命中率、缓存更新政策、缓存最大数据量
Memcached
- 本质上就是一个内存key-value缓存;
- 协议简单,使用的是基于文本行的协议;
- 不支持数据的持久化,服务器关闭之后数据全部丢失;
- Memcached简洁而强大,便于快速开发,上手较为容易;
- 互不通信的Memcached之间具有分布特征 ;
- 没有安全机制。
Redis
- 有丰富的数据类型:如String、List、Set、Sorted Set、Hash等
- 支持两种数据持久化方式:Snapshotting(快照)和Append-Only file(追加)
- 支持主从复制
缓存如何保证一致性
方案一:采用延时双删策略
基本思路: 在写库前后都进行删除缓存操作,并且设置合理的超时时间
基本步骤: 先删除缓存–再写数据库—休眠一段时间—再次删除缓存
该方案的弊端: 集合双删策略+缓存超时策略设置,这样最差的结果就是在超时时间内数据存在不一致,又增加了写请求的耗时。
方案二:一步更新缓存(基于订阅Binlog的同步机制)
读取binlog后分析 ,利用消息队列,推送更新各台的redis缓存数据。
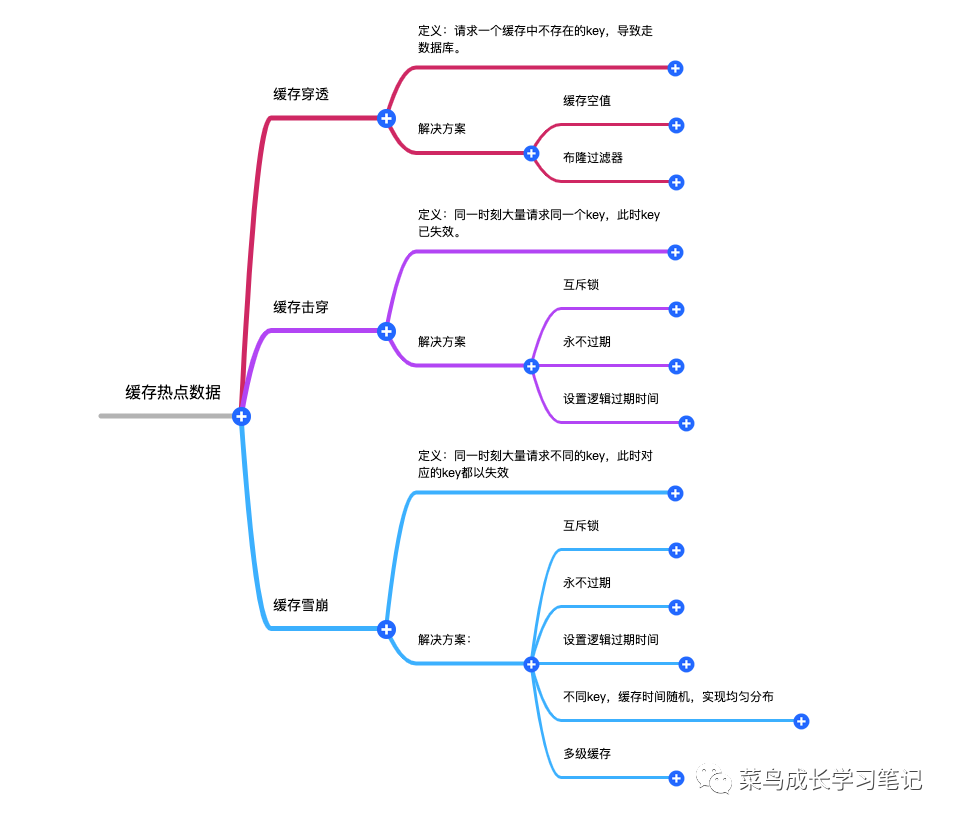
Redis热门问题
数据库
数据库应用优化
- 数据库的优化:一方面是SQL程序语句的优化,另一方面是数据库服务器和配置的优化
- 查询语句的优化:一些普通遵循的的原则,以及怎样对查询语句进行性能分析
基本语句优化10个原则
- 尽量避免在列上进行运算,这样会导致索引失效
- 使用JOIN时,应该用小结果驱动大结果。同时把复杂的JOIN查询拆分成多个查询
- 注意LIKE的使用,避免%%
- 仅列出需要查询的字段,这对速度不会有明显影响,主要考虑节省内存
- 使用批量插入语句节省交互
- limit的基数比较大时使用between
- 不要使用rand函数获取多条随机记录
- 避免使用NULL
- 不要做无谓的排序操作,而应尽可能在索引中完成排序
MySQL数据库索引的设计原则
- 选择唯一性索引
- 为经常需要排序、分组和联合操作的字段建立索引
- 为常作为查询条件的字段建立索引
- 限制索引的数目
- 尽量使用数据量少的索引
- 尽量使用前缀来索引
- 使用最频繁的列放到联合索引的左侧
- 在多个字段都要创建索引的情况下,联合索引优于单值索引
事务隔离级别
- 脏读
读取到其他事务还没有提交的数据 - 不可重复读
同一事务内查询,由于别的事务将数据修改or删除,导致执行两次查询结果可能不一样。 - 幻读
通常针对插入操作,与不可重复读的区别是不可重复读,是由于数据变更导致数据变少。幻读是因为后一次insert操作导致数据增加,先前没有读取到。
隔离级别隔离强度逐渐增强,性能逐渐下降
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(Read Uncommited) | 可能 | 可能 | 可能 |
| 读已提交(Read Commited) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable Read) | 不可能 | 不可能 | 其他引擎可能(innodb 利用间隙锁) |
| 串行化(Serializable) | 不可能 | 不可能 | 不可能 |
数据库的优化方案核心本质有三种: 减少数据量、用空间换性能、选择合适的存储系统,这也对应了开篇讲解的慢的三个原因:数据总量、高负载、查找的时间复杂度。
- 减少数据量
减少数据量类型共有四种方案:数据序列化存储、数据归档、中间表生成、分库分表。 - 分库分表
垂直拆分更多是从业务角度进行拆分
水平拆分更多是从技术角度进行拆分 - 用空间换性能
分布式缓存、一主多从
php-fpm进程数设置多少合适
问题:一个4CPU 8个G的服务器,请问一般配置多少个FPM进程。
经过查找有几下几种答案,以供参考。
1、一般都会推荐设置为n或者n×2 或才nx4(n为cpu数量)
2、按照可用内存/30m (30m为fpm每个进程内存),配置不超过总的70%就基本可以,不考虑其他服务的情况下。
负载均衡
并发
clickhouse
列式存储数据库,可以做用户行为分析
clickhouse特点
列式存储:
支持5种数据库引擎:
Ordinary:默认引擎
MySQL:MySQL引擎,Mysql引擎用于将远程mysql库中的表映射到clickhouse中,并允许clickhouse对表进行select和insert操作,以方便clickhouse和mysql之间进行数据的交换。
Dictionary:字典引擎
Memory:内存引擎,用于存放临时数据
Lazy:日志引擎
MaterializeMySQL:MySQL数据同步;将MySQL数据全量或增量方式同步到clickhouse中,解决mysql服务并发访问压力过大的问题
不足:
- 不支持事务、异步删除与更新
- 不适用高并发场景
衡量一个应用指标
- TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
Tps即每秒处理事务数,包括了
1)用户请求服务器
2)服务器自己的内部处理
3)服务器返回给用户
这三个过程,每秒能够完成N个这三个过程,Tps也就是N;
-
QPS:Queries Per Second,意思是每秒查询率。指一台服务器每秒能够响应的查询次数,用于衡量特定的查询服务器在规定时间内所处理流量多少,主要针对专门用于查询的服务器的性能指标
-
区别:
QPS 基本类似于 TPS,但是不同的是,对于一个事务访问,会形成一个 “ T ”;但一次 " T " 中,可能产生多次对服务器的请求,服务器对这些请求,就可计入 QPS 之中。
(1)如果是对一个查询接口压测,且这个接口内部不会再去请求其它接口,那么 TPS = QPS,否则,TPS ≠ QPS
(2)如果是容量场景,假设 N 个接口都是查询接口,且这个接口内部不会再去请求其它接口,QPS = N * TPS
1、当QPS小于50时
优化方案:为一般小型网站,不用考虑优化
2、当QPS达到100时,遇到数据查询瓶颈
优化方案: 数据库缓存层,数据库的负载均衡
3、当QPS达到800时, 遇到带宽瓶颈
优化方案:CDN加速,负载均衡
4、当QPS达到1000时
优化方案: 做html静态缓存
5、当QPS达到2000时
优化方案: 做业务分离,分布式存储
高并发解决方案案例
-
流量优化
防盗链处理(去除恶意请求) -
前端优化
减少HTTP请求[将css,js等合并]
添加异步请求(先不将所有数据都展示给用户,用户触发某个事件,才会异步请求数据)
启用浏览器缓存和文件压缩
CDN加速
建立独立的图片服务器(减少I/O) -
服务端优化
页面静态化
并发处理
队列处理
控制大文件的下载,建议将大文件放在另外一台服务器上 -
数据库优化
数据库缓存
分库分表,分区
读写分离
负载均衡
查询尽量不用select *
避免相关子查询
给经常查询的添加索引
web服务器优化
nginx反向代理实现负载均衡
lvs实现负载均衡 -
PV(Page View):综合浏览量,即页面浏览量或者点击量,一个访客在24小时内访问的页面数量
-
吞吐量(fetches/sec) :单位时间内处理的请求数量 (通常由QPS和并发数决定)
-
响应时间:从请求发出到收到响应花费的时间
RPC协议
- RPC(Remote Procedure Call)是一种远程过程调用的协议,是分布式常用的一种通信方式
- RPC 主要是基于 TCP/IP 协议的,而 HTTP 服务主要是基于 HTTP 协议的。 HTTP 协议是在传输层协议 TCP 之上的,所以效率来看的话,RPC 当然是要更胜一筹啦,RPC主要是用在大型网站里面,因为大型网站里面系统繁多,业务线复杂,而且效率优势非常重要的一块,这个时候RPC的优势就比较明显了。
- OSI 的七层网络结构模型
第一层:应用层。定义了用于在网络中进行通信和传输数据的接口。
第二层:表示层。定义不同的系统中数据的传输格式,编码和解码规范等。(实际无)
第三层:会话层。管理用户的会话,控制用户间逻辑连接的建立和中断。(实际无)
第四层:传输层。管理着网络中的端到端的数据传输。
第五层:网络层。定义网络设备间如何传输数据。
第六层:链路层。将上面的网络层的数据包封装成数据帧,便于物理层传输。
第七层:物理层。这一层主要就是传输这些二进制数据。















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









