







简介
正则表达式是一种进行模式匹配和文本操纵的复杂而又强大的工具。虽然正则表达式比纯粹的文本匹配效率低,但是它却更灵活。按照它的语法规则,随需构造出的匹配模式就能够从原始文本中筛选出几乎任何你想要得到的字符组合。
Go语言通过regexp标准包为正则表达式提供了官方支持,如果你已经使用过其他编程语言提供的正则相关功能,那么你应该对Go语言版本的不会太陌生,但是它们之间也有一些小的差异,因为Go实现的是RE2标准,除了\C,详细的语法描述参考:正则表达式语法
其实字符串处理我们可以使用strings包来进行搜索(Contains、Index)、替换(Replace)和解析(Split、Join)等操作,但是这些都是简单的字符串操作,他们的搜索都是大小写敏感,而且固定的字符串,如果我们需要匹配可变的那种就没办法实现了,当然如果strings包能解决你的问题,那么就尽量使用它来解决。因为他们足够简单、而且性能和可读性都会比正则好。
常用的正则标识符

Go语言使用正则表达式
简单来说,Go语言中使用正则表达式只需要两步即可:
1、解析、编译正则表达式使用regexp.MustCompile()函数
func MustCompile(str string) *Regexp
函数的主要作用是将正则表达式中,奇形怪状的读好转换成Go语言能识别的格式,并将其保存成结构体格式,方便编译器识别。
参数:正则表达式字串。建议使用反引号(``)。
返回值:编译后的结构体。解析式失败是会产生panic错误。
2、根据解析好的规则(结构体形式),从指定字符串中提取需要的信息。使用FindAllStringSubmatch()函数
func (re *Regexp) FindAllStringSubmatch(s string, n int) [][]string
参数1:待解析的字符串
参数2:匹配的次数。通常传-1,表示匹配所有。
返回值:返回成功匹配的[][]string
import (
"fmt"
"regexp"
)
func main(){
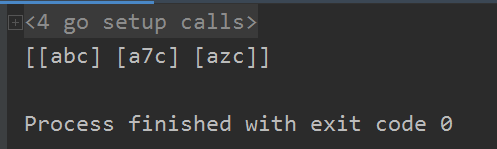
str := "abc a7c mfc cat 8ca azc cba"
//`[0-9]+\.[0-9]+`或者`\d+\.\d+` 小数的正则表达式
//``
ret := regexp.MustCompile(`a.c`) //参数是一个正则表达式 ``:表示使用原生字符串
alls := ret.FindAllStringSubmatch(str,-1)
fmt.Println(alls)
}
常用的正则表达式:
[0-9]+\.[0-9]+或者\d+\.\d+ 小数的正则表达式
提取网页中<div>(.*)</div> 这个可以爬出标签之间没有换行的,无法匹配换行符
<div>(?s:(.*?))</div>
?s表示单号模式
x*? 重复>=0次匹配x,越少越好(优先跳出重复)
测试发现,新添加的<div></div>标签中,如果出现换行,则原正则表达式<div>(.*)</div> 不能正确提取数据。因此需要调整正则表达式:<div>(?s:(.*?))</div> 。分析这个表达式,有两部分内容。
(?s)是正则表达式的模式修饰符。即单行模式。更改.的含义。使它与每一个字符匹配(包括换行符\n)
(.?)是一个单元分组。“.”匹配任意字符。“?”表重复>=0次匹配。
注:将<div>(?s:(.*?))</div> 元组放置于某一特征字符串中,可以提取带有这一特征字符串的内容。
返回值
存储匹配结果的[][]string
数组的每一个成员都有string1和string2两个元素
string1:表示,带有匹配参考项的字符串
string2:表示,不包含匹配参考项的字符串内容
for _ , one := range alls{
fmt.Println("one[0]=",one[0])
fmt.Println("one[1]=",one[1])
}















 7492
7492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









