







时间转换
时间转换,是指将字符型的时间格式数据转化为时间型数据的过程。
- 时间转化函数:
datetime = pandas.to_datetime(dateString,format)
- dateString: 字符型的时间格式数据
- format: 转化的时间型数据,该参数有以下几种选项
| 属性 | 含义 |
|---|---|
| %Y | 代表年份 |
| %m | 代表月份 |
| %d | 代表日期 |
| %H | 代表小时 |
| %M | 代表分钟 |
| %S | 代表秒 |
时间格式化,是指将时间型数据按照指定格式,转化为字符型数据。
- 时间格式化函数:
dateTimeFormat = datetime.dt.strftime(format)
format参数与上述相同。
日期抽取,是指从日期格式里面,抽取出需要的部分属性。
- 抽取函数:
datetime.dt.property
| 属性 | 注释 |
|---|---|
| second | 1-60:秒,从1开始,到60 |
| minute | 1-60: 分钟,从1开始,到60 |
| hour | 1-24: 小时,从1开始,到24 |
| day | 1-31: 一个月中的第几天,从1开始,最大为31 |
| month | 1-12: 月份,从1开始,到12 |
| year | 年份 |
| weekday | 1-7:一周中的第几天(星期几),从1开始,最大为7 |
举例

- 首先将注册时间转化为时间型数据。
data['registertime'] = pandas.to_datetime(data.注册时间,format='%Y/%m/%d')
data.iloc[0,3]
Out: Timestamp('2011-01-01 00:00:00')
输出:

现在的日期格式为’Timestamp’,想要去掉后面的时分秒,可以转化为’datetime.date’格式。
data['registertime2'] = pandas.to_datetime(data.注册时间,format='%Y/%m/%d').dt.date
data.iloc[0,4]
Out: datetime.date(2011, 1, 1)

链接去掉时分秒提供另外两种方法:dt.normalize()、dt.floor('d')
df = pandas.Series(pandas.date_range('20130101 09:10:12',periods=4),name='DATE')
df1 = df.dt.date
df2 = df.dt.normalize()
df3 = df.dt.floor('d')
输出:

注意,.dt.date输出的object类,其他两种输出为datetime64。
这里介绍下.dt访问器的使用。
官方文档的介绍:
Series has an accessor to succinctly return datetime like properties for the values of the Series, if it is a datetime/period like Series. This will return a Series, indexed like the existing Series.
根据官方文档,.dt访问器的对象是Series,因此在处理单条日期数据时无需使用。直接to_datetime(单条日期).date即可。
import pandas
d = pandas.to_datetime('2020/7/25 10:40',format='%Y/%m/%d %H:%M').date
d()
Out: datetime.date(2020, 7, 25)
注意,这里如果直接print(d),得到的结果是时间戳内置方法<built-in method date of Timestamp object at 0x000002188A3E6DE0>,print(d())才可以将d中的值显示出来。
- 时间格式化
dt.strftime(format)
import pandas
data = pandas.read_csv('D://Data Analysis//4.16//data.csv',sep=',')
data['registertime'] = pandas.to_datetime(data.注册时间,format='%Y/%m/%d')
# 将日期型数据转化为字符型
d = data['registertime'].dt.strftime('%Y-%m-%d')
输出:

- 日期抽取
import pandas
data = pandas.read_csv('D://Data Analysis//4.16//data.csv',sep=',')
data['registertime'] = pandas.to_datetime(data.注册时间,format='%Y/%m/%d')
data['rt.y'] = data['registertime'].dt.year
data['rt.m'] = data['registertime'].dt.month
data['rt.d'] = data['registertime'].dt.day
data['rt.h'] = data['registertime'].dt.hour
data['rt.M'] = data['registertime'].dt.minute
data['rt.s'] = data['registertime'].dt.second
输出:

时间抽取
时间抽取,是指根据一定的条件,对时间格式的数据进行抽取。
- 根据索引进行抽取
DataFrame.ix[start,end]、DataFrame.ix[dates] - 根据时间列进行抽取
DataFrame[condition]
举例说明,针对如下的DataFrame。
第一步,需要将date列的时间数据转化为datetime格式。

第一种方法,在读取时就转化数据格式。
pandas.read_csv()函数包含众多参数,这里介绍相关的两个参数:parse_dates、date_parser
parse_dates参数实际上是说明解析哪一列数据为日期格式。
parse_dates官方文档的介绍:
parse_dates: bool or list of int or names or list of lists or dict, default False
The behavior is as follows:
boolean. If True -> try parsing the index.
list of int or names. e.g. If [1, 2, 3] -> try parsing columns 1, 2, 3 each as a separate date column.
list of lists. e.g. If [[1, 3]] -> combine columns 1 and 3 and parse as a single date column.
dict, e.g. {‘foo’ : [1, 3]} -> parse columns 1, 3 as date and call result ‘foo’
If a column or index cannot be represented as an array of datetimes, say because of an unparseable value or a mixture of timezones, the column or index will be returned unaltered as an object data type. For non-standard datetime parsing, use pd.to_datetime after pd.read_csv. To parse an index or column with a mixture of timezones, specify date_parser to be a partially-applied pandas.to_datetime() with utc=True. See Parsing a CSV with mixed timezones for more.
Note: A fast-path exists for iso8601-formatted dates.
翻译一下文档:
parse_dates格式:bool或list或int或names或list of lists或dict,默认False
每个格式对应的操作:
布尔值。如果为True,解析index为日期格式。
例如

将rq列作为index,并解析。
data1 = pandas.read_csv('D://Data Analysis//4.17//data1.csv',sep=',',parse_dates=True,index_col=0)
输出:
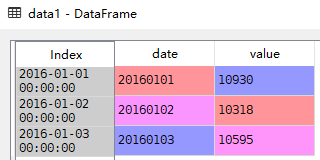
parse_dates格式:bool或list或int或names或list of lists或dict,默认False
每个格式对应的操作:
list of int or names。如果为[1,2,3],则分别解析1,2,3列为date数据。
例如:
data2 = pandas.read_csv('D://Data Analysis//4.17//data1.csv',sep=',',parse_dates=[0,1])
输出:
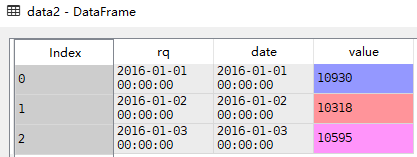
parse_dates格式:bool或list或int或names或list of lists或dict,默认False
每个格式对应的操作:
list of lists。如果为[[1,2]],则将1,2两列合并后解析数据,然后返回一个合并的date列。
例如
csv数据:
rq,time,value
20160101,100234,10930
20160102,100235,10318
20160103,100236,10595
data3 = pandas.read_csv('D://Data Analysis//4.17//data1.csv',sep=',',parse_dates=[[0,1]])
输出:
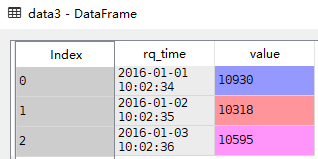
根据数据可以看出,合并后的列名直接是在两个列名之间加’_’。如果需要自己定义列名,则用到最后dict形式。
parse_dates格式:bool或list或int或names或list of lists或dict,默认False
每个格式对应的操作:
dict。如果为{‘foo’:[1,3]},则将1,3两列合并后解析数据,然后返回一个合并的date列,并将列名改为foo。
data4 = pandas.read_csv('D://Data Analysis//4.17//data1.csv',sep=',',parse_dates={'newdate':[0,1]})
输出:
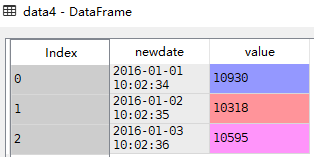
注意,这里额外介绍另一个参数infer_datetime_format,这个参数格式为bool,默认False。当parse_dates可以解析列时,设置这个参数为True,某些情况下可以加快5~10倍。
date_parser参数: function, optional。实际上可以是一个函数,指定处理时间格式数据的方法。例如指定用strptime函数处理日期数据。
dateparser = lambda dates:pandas.datetime.strptime(dates,'%Y%m%d')
data5 = pandas.read_csv('D://Data Analysis//4.17//data.csv',
sep=',',
parse_dates=['date'],
date_parser=dateparser,
index_col='date')
输出:
第二种,在读取后转化格式,to_datetime()即可做到。
接下来,要选择抽取的时间段。
# 例如抽取2016-2-1至2016-2-5的数据
import datetime
dateparser = lambda dates:pandas.datetime.strptime(dates,'%Y%m%d')
data = pandas.read_csv('D://Data Analysis//4.17//data.csv',
sep=',',
parse_dates=['date'],
date_parser=dateparser,
index_col='date')
dt1 = datetime.date(year=2016,month=2,day=1)
dt2 = datetime.date(year=2016,month=2,day=5)
# 取两个日期之间的数据
data.ix[dt1:dt2]
#取这两个数据
data.ix[[dt1,dt2]]
# 按列抽取
data = pandas.read_csv('D://Data Analysis//4.17//data.csv',
sep=',',
parse_dates=['date'],
date_parser=dateparser)
data[(data.date>=dt1)&(data.date<=dt2)]
输出:
Out[155]:
value
date
2016-02-01 11261
2016-02-02 8713
2016-02-03 7299
2016-02-04 10424
2016-02-05 10795
data.ix[[dt1,dt2]]
Out[156]:
value
date
2016-02-01 11261
2016-02-05 10795
Out[157]:
date value
31 2016-02-01 11261
32 2016-02-02 8713
33 2016-02-03 7299
34 2016-02-04 10424
35 2016-02-05 10795















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









