






共享单车是一种新兴的出行方式,共享单车的出现,很好地解决了我们出行的“最后一公里”的难题。那么,共享单车的使用量是否和季节存在一定的关系呢?现在,我们就对这一问题做一个简单探讨。
我们选取的数据集依然是kaggle上的共享单车数据集,这一数据集的描述如下所示:

现在,我们使用R语言对其做一个简单的分析,以初步确定共享单车的使用量是否和季节有关。
首先,我们需要读入数据。代码如下:
train=read.csv("E:bikesharingtrain.csv")
head(train)结果如下所示:
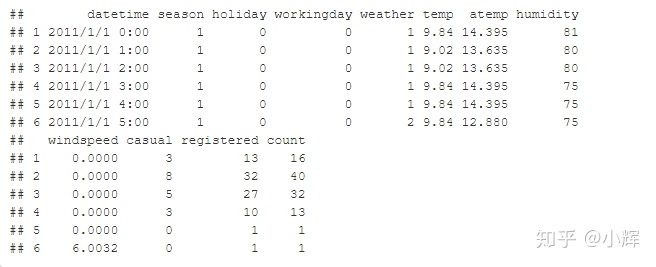
我们发现,R语言读入的结果是正确的。
现在,我们来确定一下数据的类型。代码如下:
str(train)数据类型如下所示:
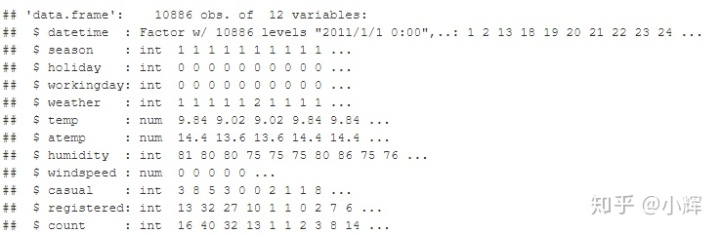
我们,可以发现season这一变量,应该是因子型,而不是整数型。因此,我们对season进行因子化处理,代码如下:
train$season=factor(train$season)
str(train)新的数据类型如下所示:
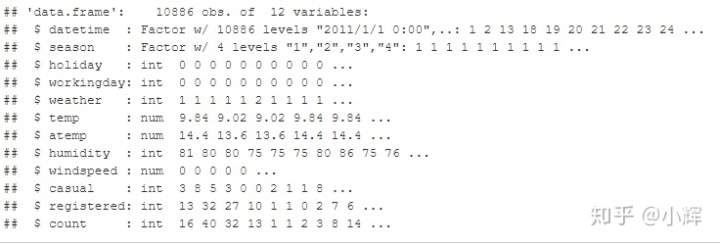
现在,我们已经把数据类型给调整好了。
首先,我们通过采用绘制条形图的方式,看一下是否存在着显著的差异。首先是要按照季节进行分类整理:
sum(is.na(train)) #查看缺失值的情况
aggregate(train[c(12)],by=list(train$season),FUN=mean) #按季节计算共享单车使用次数的平均数发现没有缺失值。
整理的结果如下所示:

现在,我们就可以开始绘制条形图了:
w=data.frame(season=c("第一季度","第二季度","第三季度","第四季度"),count=c(116.34,215.2514,234.4171,198.99)) #构造一个数据框
library("ggplot2") #加载绘图的ggplot2包
w$count=round(w$count,2) #对count取两位小数
w #显示这一个数据框
ggplot(data=w,aes(x=season,y=count)) #绘图的数据集,横纵坐标
+geom_bar(fill="blue",stat="identity") #绘制条形图,填充的颜色为蓝色
+geom_text(aes(label=count),vjust=-0.2) #插入数据标签,并设置数据标签的位置
+labs(x="季度",y="平均使用次数") #更改横纵坐标的名称
+scale_x_discrete(limits=c("第一季度","第四季度","第二季度","第三季度")) #设置横坐标标签的排列顺序结果如下:
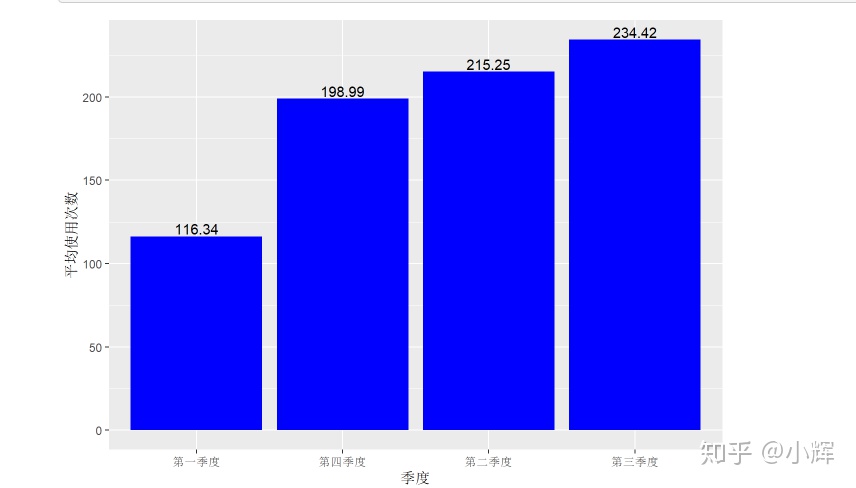
从图上,我们可以看出来,第一季度的日均租车量明显小于另外三个季度。另外三个季度的日均租车量则相差不大,因此,我们初步判断共享单车的使用量和季度存在一定的关系。为了得到更为详细的验证,我们需要使用方差分析法进行验证:
summary(aov(train$count~train$season))结果如下:

通过方差分析,我们可以发现,季度确实会对共享单车的使用量产生影响。那么这种具体影响关系是什么呢,我们用图基检验来验证一下。
plot(TukeyHSD(aov(train$count~train$season)))结果如下:
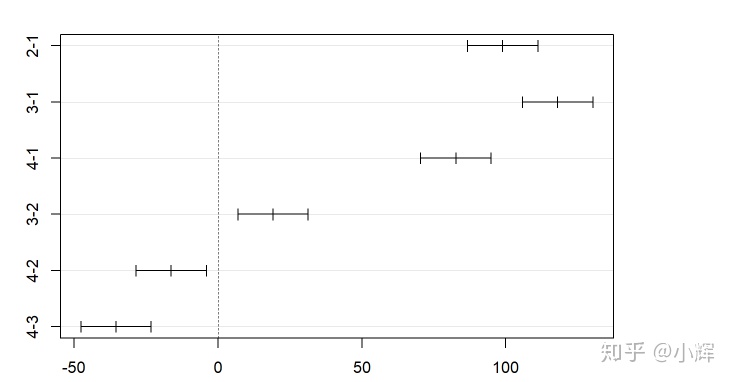
我们可以发现,所有的组合都存在着显著差异。因此,季节应该确实会对共享单车的使用量产生影响。在拟合共享单车的使用量的函数中,季节变量应该包含在其中。
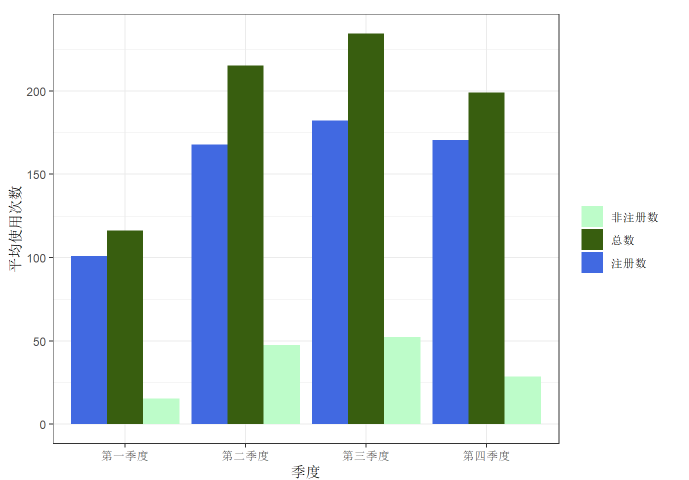
最后,我们来绘制一下,分季度的日均共享单车总使用次数、注册共享单车的使用次数、非注册共享单车使用次数的条形图
第一步,先进行准备工作:
m=train[c(2,11,12)] #选取train中的部分数据
library("plyr") #加载包
m=rename(m,c(season="季度",registered="注册数",count="总数")) #更改列的名称
m$非注册数=m$总数-m$注册数 #计算非注册数
m_pivot=aggregate(m[c(2,3,4)],by=list(m$季度),FUN=mean) #按季节进行汇总工作
library("reshape2") #加载包
m_melt=melt(m_pivot,id.vars="Group.1") #将数据由“宽”变“长”第二步,开始绘图:
theme_set(theme_bw()) #更改绘图区的背景
ggplot(data=m_melt,aes(x=Group.1,y=value,fill=variable)) #设置绘图的数据集
+geom_bar(stat="identity",position="dodge") #绘制条形图,并并列排列
+scale_x_discrete(breaks=c("1","2","3","4"),labels=c("第一季度","第二季度","第三季度","第四季度"),limits=c("1","2","3","4")) #更改横坐标的标签名称与排列顺序
+labs(x="季度",y="平均使用次数",fill=" ") #设置横纵坐标的名称,并取消图例的名称
+scale_fill_manual(values=c("#4169E1","#385E0F","#BDFCC9")) #设置图例的颜色
+guides(fill=guide_legend(reverse=TRUE)) #反转图例的顺序结果如下所示:
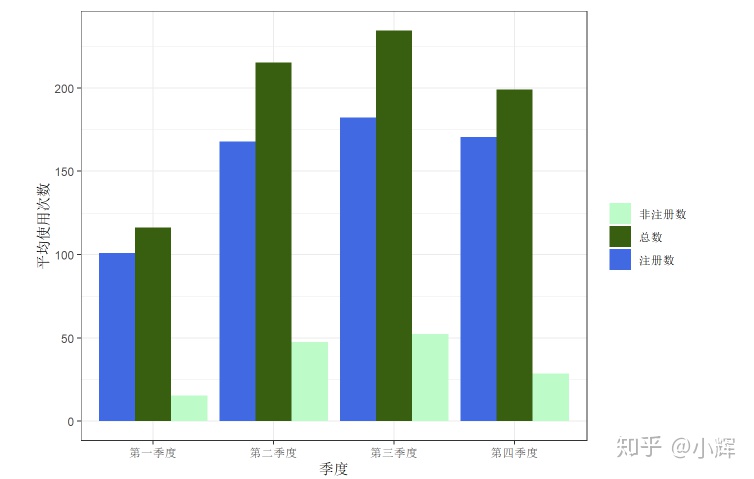















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









