







1.为什么需要redis
从电商的业务特点来看,
- CRUD操作中,80%的业务都是查询,20%的业务是新增,修改,删除操作
- 数据不会频繁变更
比如说:我们去京东电商上,做的最多的就是浏览商品,看商品的详细信息,推荐信息,,评价信息,这些都是属于查询动作,所以在电商业务中,80%都是查询操作,其余的才是新增,修改,删除业务,而且数据不会频繁修改,比如说商品的价格,商家不会频繁的去修改商品的价格,基于这两个特点,就有一个东西可以用来提高它们的性能,就是缓存,那么用什么缓存呢? 现在比较常用的就是分布式缓存:Memcached和Redis,现在更流行的是redis
2. 安装,运行,命令
2.1 克隆虚拟机
2.2 Linux基础环境支撑
yum -y install gcc automake autoconf libtool make #gcc编译环境,用来编译redis文件
yum -y install lrzsz #文件上传组件2.3 LInux下安装redis
mkdir -p 6379 /usr/local/src/redis
cd /usr/local/src/redis
wget http://download.redis.io/releases/redis-5.0.0.tar.gz #wget 官网上redis的下载路径,
tar xzf redis-5.0.0.tar.gz #解压文件
cd redis-5.0.0
make #下载后编译,过程稍长
make install #进行安装
make PREFIX=/usr/local/src/redis install #指定安装目录

2.4 启动配置
配置文件: redis.conf
编辑文件: vim redis.conf
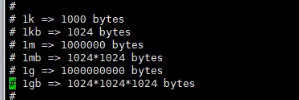
将来配置内存大小

将来绑定ip地址,默认只允许本地访问,将来远程访问的需要特殊的驱动设置

安全模式,意思是是否需要密码
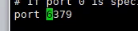
访问端口;默认是6379
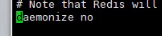
后台运行模式: 默认是关闭的,一般都是需要改为yes的,允许后台运行
![]()
将来配置集群时,需要修改
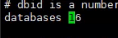
Redis默认开启16个数据库,默认0-15,不能像mysql自定义数据库名称,只能是数值,不能修改。

数据库的持久化方式,RDB方式(另一个是AOF方式)
启动redis: redis-server

但是这个模式有个缺点,就是不能写其他指令了,redis会占用这个窗口,如果我们想要运用这个窗口怎么办呢?那我们还有另一个种运行模式:那就是:
Ctrl + C 退出
redis-server & 启动redis 然后回车就可以继续利用该窗口
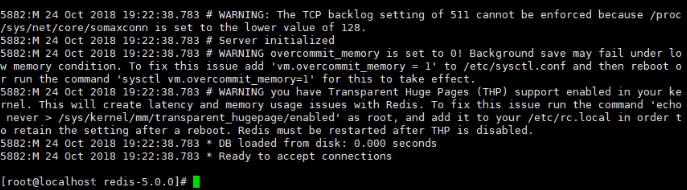
ps -ef | grep redis : 查询redis的进程
redis-cli -p 6379 启动客户端
ping 检测是否运行正常: 如果返回PONG 则表示运行正常
2.5 redis的基本命令
redis-cli 进入客户端
exit/quit/ctrl+c 退出redis

查看版本 : redis-server -v
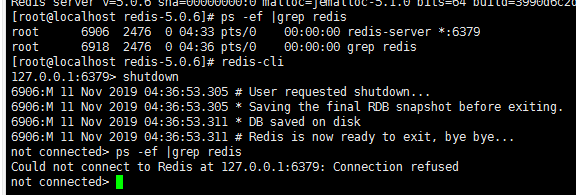
进入redis中,执行shutdown关闭redis
2.5.1 keys
字符串类型时redis中最基础的数据类型,它能存储任何形式的字符串,包括二进制数据,可以存储JSON化的对象,字节数组等,一个字符串类型键允许存储的数据最大容量是512MB
赋值与取值:
set key value
get key


存数据: set key value
取数据: get key
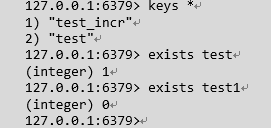
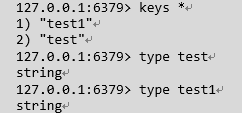
查询所有key: keys *
keys 通配符:
keys * : * 匹配任意个(包括0) 字符
keys ? : ? 匹配一个字符
keys test[_]* : 匹配括号间的任一字符,可以使用'-' 表示范围,如a[a-d]配置aa/ab/ac/ad
keys n\?: \? :匹配字符?,用于转义符合,如果要匹配'?',就需要使用\?
select:
redis默认支持16个数据库,对外都是以一个0开始的递增数字命名,可以通过参数database来修改默认数据库个数,客户端连接redis服务后会自动选择0号数据库,可以通过select命令更换数据库,例如选择1号数据库
clear: 清除屏幕内容
exists:
判断一个键是否存在,如果键存在则返回整数类型1,否则返回0
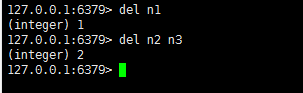
del : 删除键,可以删除一个或者多个键,多个键用空格隔开,返回值是删除的键的个数
type : 获取键值的数据类型,返回值可能是spring(字符串),hash(散列类型),list(列表类型),set(集合类型),zset(有序集合类型)
help: 没什么用:直接用官网的帮助

官网: http://www.redis.io 帮助

flushall : 清空所有数据库 ; 最好不要执行此命令
flushdb : 清空当前数据库


Hash 类型
说明: 可以用散列类型保存对象和属性值
例子: User对象(id:2,name:小明,age:19)

List类型:
说明: redis中的list集合是双端循环列表,分别可以从左右两个方向插入数据
List集合可以当做队列使用,也可以当做栈使用
队列:存入数据的方向和获取数据的方向相反
栈: 存入数据的方向和获取数据的方向相同


效果图:

redis数据类型之字符串
存放的字符串为二进制是安全的,字符串长度支持到512M
incr key: 递增数字\
incrby key num : 指定增长数值:(num指定的增长值)
当存储的字符串是整数时,redis提供了一个实用的命令incr ,其作用是让当前键值递增,并返回递增后的值
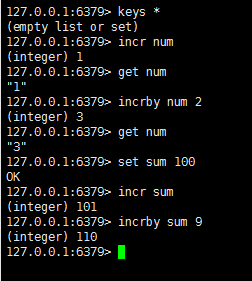
从上面的例子可以看出,如果num不存在,则自动会创建,如果存在则会自动+1
decr key: 递减数值
decrby key num : 减少指定的整数
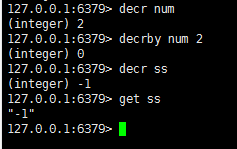
从上面的例子可以看出,如果num不存在,则自动会创建,如果存在则会自动-1
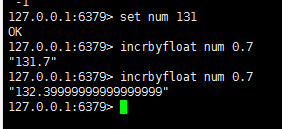
incrbyfloat:
整数时,第一次加可以得到正确结果,浮点数后再加浮点就会出现精度问题
原来下面的例子2.8.7注意在新版本中已经修正了这个浮点精度问题.3.0.7
语法: incrbyfloat key decrement
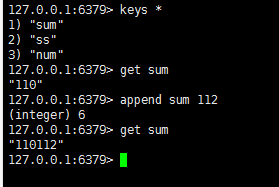
append:
向尾部追加值,如果键不存在则创建该值,其值为写的value,即相当于set key value.返回值是追加后字符串的长度
语法: append key value
strlen :
字符串长度,返回数据的长度,如果键不存在则返回0,注意,如果键值为空串,返回也是0
语法: strlen key

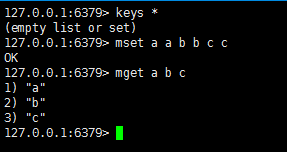
mset/mget
同时设置/获取多个键值
语法: mset key1 value1 key2 value2 key3 value3
mget key1 key2 key3
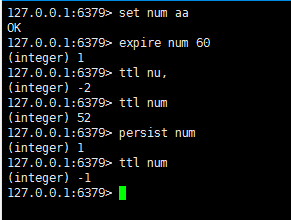
redis 生存时间
expire :
redis在实际使用过程中更多的用作缓存,然而缓存的数据一般都是需要设置生存时间的,即到期后数据自动销毁
语法: expire key seconds

ttl : 查看key的剩余时间,当返回值为-2时,表示键被删除
当key不存在时,返回-2,当key存在但没有设置剩余时间时,返回-1,否则以毫秒为单位,返回key的剩余生存时间
注意: 在redis2.8以前,当key不存在,或者可以没有设置剩余生存时间时,命令都返回-1
persist :
语法: persist key
设置新的数据时需要重新设置该key的生存时间,重新设置值也会清除生存时间
pexpire
语法: pexpire key milliseconds

设置生存时间为毫秒,可以做到更精准的控制
redis高级中的hash结构
在redis中用的最多的就是hash和string类型
问题:
假设有user对象以json序列化的形式存储到redis中,user对象有id,username,password,age,name等属性,存储过程如下:
user对象->json (string)->redis
如果在业务上只是更新age属性,其他的属性并不做更新应该怎么做呢?
redis数据类型之散列类型hash
散列类型存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他类型,也就是说,散列类型不能嵌套其他的数据类型,一个散列类型可以包含最多2的32次幂减1个字段
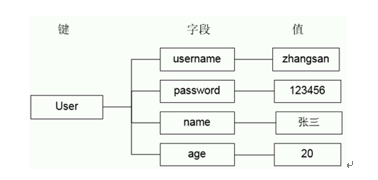
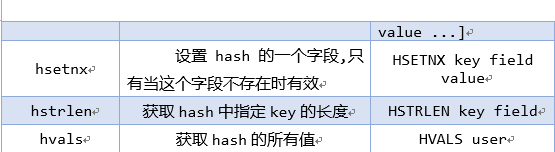
hset/hget
相关命令:
hset key field value
hget key field
hmset key field value[field value...]
hmget key field value[field value...]
hgetall key

hset命令不区分插入和更新操作,当执行插入操作时hset命令返回1,当执行更新操作时返回0
hincrby:
语法: hincrby 散列表名 field 整数(加)/负数(减)

hmset / hmget
hmset 和hmget 设置和获取对象属性
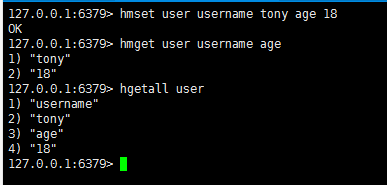
注意: 上面hmget 字段可以自行定义
hexists : 属性是否存在
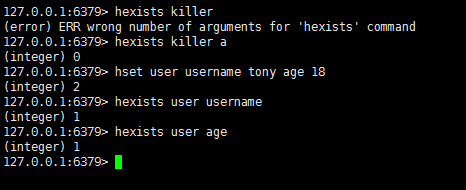
hdel : 删除属性

hkeys/hvals : 只获取字段名hkeys或字段值hvals

hlen : 元素个数

jedis示例:
package com.jt;
import java.util.Map;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolDemoCMD {
@Test
public void test01() {
//构建连接池配置信息
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
//设置最大连接数
jedisPoolConfig.setMaxTotal(50);
//构建连接池对象
JedisPool jedisPool = new JedisPool(jedisPoolConfig, "192.168.21.130", 6379);
Jedis jedis = jedisPool.getResource();
jedis.hset("USER_1", "username", "zhangsan");
jedis.hset("USER_1", "password", "123456");
Map<String, String> val = jedis.hgetAll("user");
for(Map.Entry<String, String> entry: val.entrySet()) {
System.out.println(entry.getKey()+":"+entry.getValue());
}
//将连接返回到连接池中
jedisPool.returnResource(jedis);
//释放连接池
jedisPool.close();
}
}redis 中测试
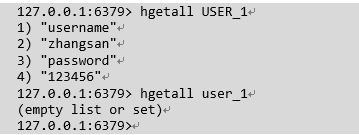
redis高级中的list结构
一个列表最多可以包含2的32次幂-1个元素(4294967295,每个表超过43亿个元素)
问题:
redis的list类型其实就是一个每个子元素都是spring类型的双向链表,可以用过push,pop操作从链表的头部或者尾部添加删除元素,这使得list既可以用作栈,也可以用作队列
有意思的是list的pop操作还有阻塞版本的,当我们[lr]pop一个list对象时,如果list是空,或者不存在,会立即返回nil,但是阻塞版本的b[lr]pop则可以阻塞,当然可以叫超时时间,超时后也会返回nil,为什么要阻塞版本的pop呢?主要是为了避免轮询,举个简单的例子如果我们用list来实现一个工作队列,执行任务的thread可以调用阻塞版本的pop去获取任务这样就可以避免轮询去检查是否有任务存在.当任务来的时候工作线程可以立即返回,也可以避免轮询带来的延迟
lpush : 在key对应的list的头部添加字符串元素

rpush : 在key对应的list的尾部添加字符串元素
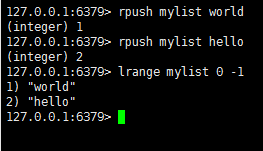
查看list
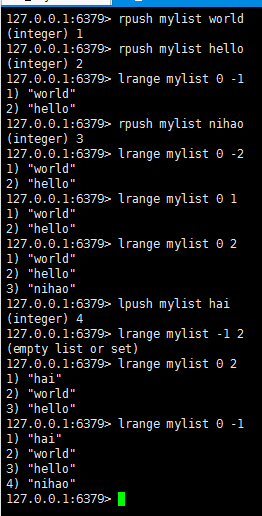
删除list
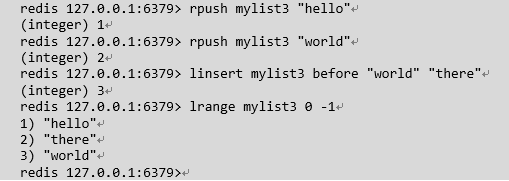
linsert : 在key对应list的特定位置之前或之后添加字符串元素
lset : 设置list中指定下标的元素值
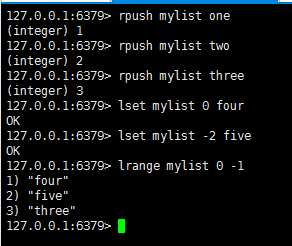
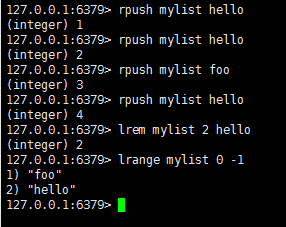
lrem : 从可以对应list中删除count个和value相同的元素,count>0时,按从头到尾的顺序删除
语法: lrem key count value
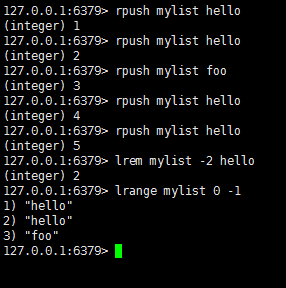
当count<0时,按从尾到头的顺序删除
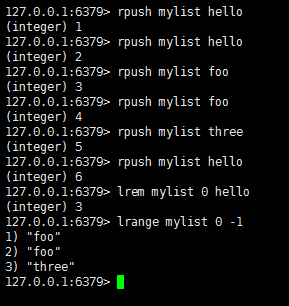
当count=0时,删除全部
ltrim : 保留指定key的值范围内的数据

lpop : 从list的头部删除元素,并返回删除元素
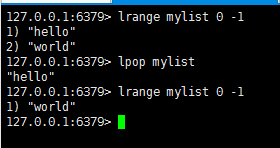
rpop : 从list的尾部删除元素,并返回删除元素
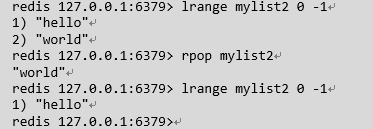
llen : 返回key对应list的长度:

lindex : 返回名称为key的list中index位置的元素
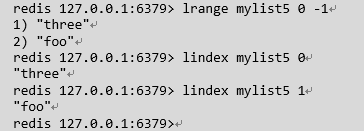
rpoplpush : 从第一个list的尾部移除元素并添加到第二个list的头部,最后返回被移除的元素值,整个操作时原子的,如果第一个list是空或者不存在返回nil:
利用链表形成安全消息队列
rpoplpush 命令实现安全消息队列,redis链表经常会被用于消息队列的服务,以完成多程序之间的消息交换,假设一个应用程序正在执行lpush操作向链表添加新的元素,我们通常将这样的程序称之为生产者(Producer),而另一个应用程勋正在执行rpop操作从链表中取出元素,我们称这样的程序为消费者(Consumer),如果此时,消费者程序在取出消息元素后立刻崩溃,由于该消息已经被取出且没有被正常处理,那么我们就可以认为该消息已经丢失,由此可能会导致业务数据丢失,或业务状态不一致等现象的发生,然而通过rpoplpush命令,消费者程序在从主消息队列中取出消息之后再将其插入到备份队列中,指定消费者程序完成正常的处理逻辑后再将消息从备份队列中删除,同时我们还可以提供一个守护进程,当发现备份队列中的消息过期时,可以重新将其再放回到主消息队列中,以便其他的消费者程序继续处理
redis高级中的set结构
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Redis中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为2的32次幂- 1 (4294967295每个集合可存储40多亿个成员)
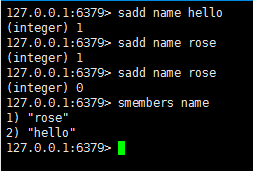
sadd : 添加元素,重复元素添加失败,返回0
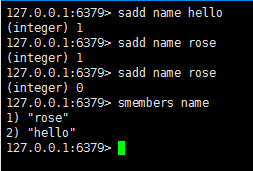
smembers : 获取内容
spop : 随机移除并返回集合中的一个随机元素

scard : 获取成员个数

smove : 移动一个元素到另一个集合

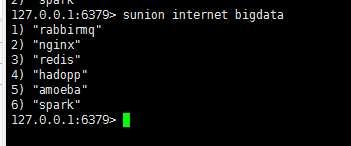
sunion : 并集
redis的两种灾难恢复的模式(持久化方式)
RDB 和 AOF 模式
| RDB | AOF |
| fork一个进程,遍历hash table,利用copy on write,把整个db dump保存下来。 save, shutdown, slave 命令会触发这个操作。粒度比较大,如果save, shutdown, slave 之前crash了,则中间的操作没办法恢复 | 把写操作指令,持续的写到一个类似日志文件里。(类似于从postgresql等数据库导出sql一样,只记录写操作) 粒度较小,crash之后,只有crash之前没有来得及做日志的操作没办法恢复 |
| 一个时平时写操作的时候不触发写,只有手动提交save命令.或者是shutdown关闭命令时,才触发备份操作 | 一个时持续的用日志记录写操作,crash(崩溃)后利用日志恢复 |
redis持久化说明:
redis会根据配置文件的规则,定期将内存中的数据持久化到磁盘中.当redis重新启动时,会根据配置文件,实现内存数据的恢复
RDB模式:
说明: rdb模式是redis默认的持久化策略
特点:
- rdb模式定期实现数据的持久化(可能会丢失数据)
- rdb模式记录的是内存数据的快照,持久化文件较小
- rdb模式在进行持久化操作时是阻塞的(数据安全性考虑)
- 一般使用持久化的策略rdb的效率是最高的,建议使用
rdb模式--save指令
说明: 可以通过客户端执行save指令,实现内存数据的持久化操作
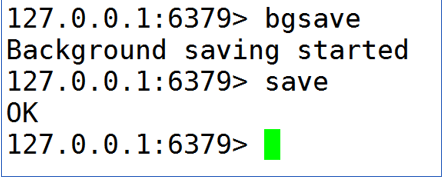
bgsave 表示后台运行,异步操作
save 表示现在立即执行,表示同步操作,会造成线程阻塞
rdb的持久化策略
save 900 1 : 如果用户在900秒内,执行1次更新操作时,则持久化一次
save 300 10 : 在300秒内,执行10更新查找时,则持久化
save 60 10000 : 在60秒内,执行10000次更新操作时,则持久化
save 1 1 : 效率极低
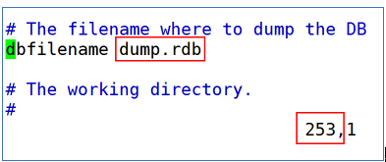
rdb持久化名称配置
AOF模式:
说明: AOF模式默认是关闭的,如果使用需要开启AOF模式做的事数据的追加,所以持久化文件较大
特点:
- AOF 模式默认是关闭的
- AOF模式持久化是记录用户的操作过程,之后追加到持久化文件中
- AOF模式可以实现实时备份,保证数据安全
- AOF模式效率低于rdb模式
- AOF持久化文件需要定期维护
- AOF模式是异步的不会陷入阻塞

AOF 模式持久化策略
配置文件732行
appendfsync always 用户做一次操作,持久化一次
appendfsync everysec 每秒持久化一次
appendfsync no 由操作系统决定何时持久化,一般不用\
两种区别就是,一个是持续的用日志记录写操作,crash(崩溃)后利用日志恢复:一个是平时写操作的时候不触发写,只有手动提交save命令,或者是shutdown关闭命令时,才能触发备份操作
选择的表尊,就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(AOF),还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb),rdb这个就更有些最终一致性(eventually consistent)的意思了
性能比较:
测试方法是用java写的脚本对redis数据库进行写入,看写入速度
100000/300000/1000000是数据量,插入的都是string,第一个数据是最小时间,第二个是平均,第三个是数据大小

从简单分析来看,AOF比RDB慢25-80%,但是大规模数据都比较支持慢25%这端,估计在低数量下,rdb模式更加有优势,数据规模增长时,速度比接近4:5,aof的数据比rdb数据大150%(2.5倍下),这点随着数据增长基本不变
从读性能分析来看,二则差异不大,同样,数据分别是最小时间和平均时间

差异在10%以内,甚至比最小平均差异还弱,基本可以视为一致
关于redis内存策略
规则说明: redis中自己有内存优化策略,能够保证在内存数据即将达到上限时,能够实现自动的优化,但是该策略默认是关闭的
内存优化策略
LRU算法:
LRU是Least Recently Used的缩写,即最近最少使用,是一种常见的页面置换算法,选择最近最久未使用予以淘汰,该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间T,当须淘汰一个页面时,选择现有页面中其T值最大的,即最近最少使用的页面予以淘汰
LFU算法:
LFU(Least frequenty used(LFU) page-replacement algorithm).即最不经常使用页面置换算法,要求在页面置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数,但是有些页在开始时使用次数很多,但以后就不再使用了,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数
内存优化算法:
-
volatile-lru 设定超时时间的数据采用LRU算法进行删除
-
allkeys-lru 所有数据采用LRU算法进行删除
-
volatile-lfu 设定超时时间的数据,采用LFU算法:redis5.0版本以后的算法
-
allkeys-lfu 所有数据采用LFU算法
-
volatile-random 设定超时时间的随机算法
-
allkeys-random 所有数据的随机算法
-
volatile-ttl 设定超时时间的数据按照可存活时间排序删除
-
noeviction 默认设定 如果内存满了不会删除数据,而是报错返回,由使用这自行决定
修改内存策略

redis 官方网站:
1.命令:http://www.redis.cn/commands.html
2.文档:http://www.redis.cn/documentation.html
redis 事务管理
乐观锁:
大多数是基于数据版本(version)的记录机制实现的,即为数据增加一个版本标识,在基于数据库表的版本解决方案中,一般是通过为数据库表增加一个"version"字段来实现读取出数据时,将此版本号一同读出,之后更新时,对此版本加1,此时,将提交数据的版本号与数据库表对应记录的当前版本号进行比对,如果提交的数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据
redis也采用类似的机制,使用watch命令会监视给定的key,当exec时候如果监视的key从调用watch后发生过变化,则整个事务会失败,也可以调用watch多次监视多个key,这样就可以对指定的key加乐观锁了.注意watch的key是对整个连接有效的,事务也一样,如果连接断开,监视和事务都会被自动清除,当然exec,discard,unwatch命令都会清除连接中的所有监视
概念:
redis是单线程,提交命令时,其他命令无法插入其中,轻松利用单线程实现了事务的原子性,那如果执行多个redis命令呢?自然就没有事务保证,于是redis有下列相关的redis命令来实现事务管理

redis保证一个事务中的所有命令要么都要执行,要么都不执行,如果在发送exec命令前客户端断线了.则redis会清空事务队列,事务中的所有命令都不会执行,而一旦客户端发送了exec命令,所有的命令就都会被执行,即使此后客户端断线了也没关系,因为redis中已经记录了所有要执行的命令
exec 提交事务
例如: 模式转账,王有200,张有700,张给王转100
127.0.0.1:6379> clear
127.0.0.1:6379> set w 200
OK
127.0.0.1:6379> set z 700
OK
127.0.0.1:6379> mget w z
1) "200"
2) "700"
127.0.0.1:6379> multi # 开启事务
OK
127.0.0.1:6379> decrby z 100
QUEUED #注意此命令根本没有执行,而是把其放入一个队列中
127.0.0.1:6379> incrby w 100
QUEUED
127.0.0.1:6379> mget w z
QUEUED
127.0.0.1:6379> get w # 同时,这些相关的变量也不能在读取
QUEUED
127.0.0.1:6379> get z
QUEUED
127.0.0.1:6379> exec # 提交事务
1) (integer) 600
2) (integer) 300
3) 1) "300"
2) "600"
4) "300"
5) "600"
127.0.0.1:6379> mget w z
1) "300"
2) "600"
127.0.0.1:6379> 如果有错误命令,自动取消
127.0.0.1:6379> mget w z
1) "300"
2) "600"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> get w
QUEUED
127.0.0.1:6379> set w 100
QUEUED
127.0.0.1:6379> abc #错误命令
(error) ERR unknown command `abc`, with args beginning with:
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> mget w z #查看数据,可以看出数据并未变化
1) "300"
2) "600"
127.0.0.1:6379>
discard 取消事务
注意:redis事务太简单,没有回滚,只有取消
127.0.0.1:6379> mget w z
1) "300"
2) "600"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> incrby z 100
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> get z
"600"
127.0.0.1:6379> exec
(error) ERR EXEC without MULTI
127.0.0.1:6379>
秒杀抢票事务处理
客户端1:
127.0.0.1:6379> set ticket 1
OK
127.0.0.1:6379> set money 0
OK
127.0.0.1:6379> watch ticket #乐观锁 ,对值进行观察,改变则事务失败
OK
127.0.0.1:6379> multi #开启事务
OK
127.0.0.1:6379> decr ticket
QUEUED
127.0.0.1:6379> incrby moeny 100
QUEUED
客户端2:还没有等客户端1提交事务,此时客户端2把票买到了
127.0.0.1:6379> get ticket #获取票
"1"
127.0.0.1:6379> decr ticket #票数减1
(integer) 0
127.0.0.1:6379>
客户端1:
127.0.0.1:6379> exec
(nil) #提交事务失败
127.0.0.1:6379> get ticket
"0"
127.0.0.1:6379> unwatch #取消监控
OK
127.0.0.1:6379>
管道-海量数据导入:
由于做性能测试,需要往redis中导出千万级的数据,得知redis-cli工具支持pipeline导入可以达到最佳性能,测试下500万条命令导入耗时43秒
格式要求:
官方文档:http://redis.io/topics/mass-insert
数据格式要求:
- 以*开始
- *n n代表此条命令分成n个部分
- 每个部分以\r\n结束
set name tony 表达为:
*3\r\n
$3\r\n
set\r\n
$4\r\n
name\r\n
$4\r\n
tony\r\n
注意: 此处的\r\n为换行符,不是输入的字符

示例:
package redis;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import org.junit.Test;
public class TestRedisPipe {
/**
* 格式化成输入字符串
*/
private String getString(String... args) {
StringBuilder sb = new StringBuilder();
sb.append("*").append(args.length).append("\r\n");
for (String arg : args) {
sb.append("$").append(arg.length()).append("\r\n");
sb.append(arg).append("\r\n");
}
return sb.toString();
}
@Test
public void initFile2() {
Long startTime = System.currentTimeMillis();
String file = "d:\\d.txt";
BufferedWriter w = null;
StringBuilder sb = new StringBuilder();
try {
w = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file), "utf-8"));
for(int i=100000000 ;i < 100100000;i++){
//for (int i = 1; i <= 100; i++) {
if (i / 30000 == 0) {
w.flush();
}
sb.setLength(0);
sb.append(this.getString("set", "u" + i, "name" + i));
//sb.append(this.getString("hmset", "usr" + i, "userid", "usr" + i, "username", "usrname" + i));
w.append(sb.toString());
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
w.flush();
w.close();
} catch (IOException e) {
e.printStackTrace();
}
}
long endTime = System.currentTimeMillis();
System.out.println("耗时: "+(endTime - startTime)/1000+" s。");
}
}
数据导入: 将d.txt文件放入redis文件下
[root@localhost redis]# cat d.txt |redis-cli --pipe
[root@localhost redis]# redis-cli
127.0.0.1:6379> keys *
99995) "u100064163"
99996) "u100073657"
99997) "u100017436"
99998) "u100033362"
99999) "u100028853"
100000) "u100004041"
(2.42s)
查看命令都耗时2.42秒,可以看到管道命令有多快,令人乍舌!
缓存预热
有人说这个有什么作用呢? 作用太大了.,可以做数据的缓存预热!
那什么是缓存预热呢?例如:当数据量达几百g时,如果让其程序来缓存,无疑对数据库会造成比较大的压力,而实现对热点数据生成这样的导入文件,执行管道命令快速导入,这样就减少了对数据库的压力,让整个程序更加稳健的接收海量用户的访问
常见问题:
[root@localhost redis]# cat d.txt |redis-cli --pipe
ERR Protocol error: too big mbulk count string
Error writing to the server: Connection reset by peer
文件太大,和所分配的内存大小密切相关,内存太少则会导致文件太大导入失败。
安装两个服务:
1.关闭防火墙:
[root@localhost ~]# systemctl stop firewalld #关闭防火墙
[root@localhost ~]# systemctl disable firewalld #开机禁用
2.简介开启实例
参数:port 端口,daemonize 后台运行,protected-mode 保护模式
[root@localhost redis]# ps -ef|grep redis
root 10299 9794 0 08:24 pts/1 00:00:00 grep redis
[root@localhost redis]# ls
d.txt redis-5.0.6 redis-5.0.6.tar.gz
[root@localhost redis]# pwd
/usr/local/src/redis
[root@localhost redis]# redis-server --port 6379 --daemonize yes --protected-mode no
10301:C 12 Nov 2019 08:25:32.019 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
10301:C 12 Nov 2019 08:25:32.019 # Redis version=5.0.6, bits=64, commit=00000000, modified=0, pid=10301, just started
10301:C 12 Nov 2019 08:25:32.019 # Configuration loaded
[root@localhost redis]# redis-server --port 6380 --daemonize yes --protected-mode no
10306:C 12 Nov 2019 08:25:49.546 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
10306:C 12 Nov 2019 08:25:49.546 # Redis version=5.0.6, bits=64, commit=00000000, modified=0, pid=10306, just started
10306:C 12 Nov 2019 08:25:49.546 # Configuration loaded
[root@localhost redis]# ps -ef|grep redis
root 10302 1 0 08:25 ? 00:00:00 redis-server *:6379
root 10307 1 0 08:25 ? 00:00:00 redis-server *:6380
root 10312 9794 0 08:25 pts/1 00:00:00 grep redis
[root@localhost redis]#
redis分片
redis支持分布式内存数据库(把多个节点结合成一个大区域一起使用)
理论上有了分片操作,形成分布式内存数据库,理论上它的内存是无限的
访问redis的驱动包。


使用最为广泛的是Jedis和Redisson(官方推荐),在企业中采用最多的是Jedis,
Jedis官网地址:https://github.com/xetorthio/jedis

创建MavenJava工程:使用Jedis需要在pom.xml文件中添加依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.tedu</groupId>
<artifactId>hello</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.4</version>
</dependency>
</dependencies>
</project>
案例:
package redis;
import java.util.List;
import redis.clients.jedis.Jedis;
public class TestRedis {
public static void main(String[] args) {
//设置连接服务器IP地址和访问端口
Jedis jedis = new Jedis("192.168.115.115",6379);
//单个值
//jedis.set("test", "456789"); //设置值
//System.out.println(jedis.get("test")); //获取值
//多个值
//jedis.mset("test1","1","test2","2");
List<String> oList = jedis.mget("test1","test2");
for(String s : oList){
System.out.println(s);
}
jedis.close(); //关闭
}
}
命令窗口:
127.0.0.1:6379> keys *连接池JedisPool创建jedis连接
package cn.redis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolDemo {
public static void main(String[] args) {
// 构建连接池配置信息
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 设置最大连接数
jedisPoolConfig.setMaxTotal(200);
// 构建连接池
JedisPool jedisPool = new JedisPool(jedisPoolConfig, " 192.168.163.101", 6379);
// 从连接池中获取连接
Jedis jedis = jedisPool.getResource();
// 读取数据
System.out.println(jedis.get("name"));
// 将连接还回到连接池中
jedisPool.returnResource(jedis);
// 释放连接池
jedisPool.close();
}
}
三个节点分片
实现分布式缓存,redis多个节点的透明访问
@Test //分片
public void shard(){
//构造各个节点链接信息,host和port
List<JedisShardInfo> infoList = new ArrayList<JedisShardInfo>();
JedisShardInfo info1 = new JedisShardInfo("192.168.163.200",6379);
//info1.setPassword("123456");
infoList.add(info1);
JedisShardInfo info2 = new JedisShardInfo("192.168.163.200",6380);
infoList.add(info2);
JedisShardInfo info3 = new JedisShardInfo("192.168.163.200",6381);
infoList.add(info3);
//分片jedis
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(500); //最大链接数
ShardedJedisPool pool = new ShardedJedisPool(config, infoList);
//ShardedJedis jedis = new ShardedJedis(infoList);
ShardedJedis jedis = pool.getResource(); //从pool中获取
for(int i=0;i<10;i++){
jedis.set("n"+i, "t"+i);
}
System.out.println(jedis.get("n9"));
jedis.close();
}
底层原理:
分片原理:

在分布式集群中,对机器的添加删除或机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能,如果采用常用的hash(object)%N算法,那么在有机器添加或删除后,很多原来的数据就无法找到了,这样严重的违反了单调性原则
hash 一致性算法
一致性哈希算法在1997年由麻省理工学院提出。
hash取余产生的问题: 新增节点,删除节点 会让绝大多数的缓存失效,除了导致性能骤降外很有可能会压垮后台服务器
解决点1:
集群中节点挂掉或新增节点的时候,要对已有节点的影响降到最小,其解决思路,就是对缓存的object和node使用同一个hash函数(实际上不需要完全一致,但至少保证产生的hash空间相同),让他们映射到同一个hash空间中去,当然这很容易实现,因为大多数的hash函数都是返回uin32类型,其空间即为1~2的32次幂-1(2^32=4294967296接近43亿),然后各个node就 将整个hash空间分割成多个interval空间,然后对于每个缓存对象object,都按照顺时针方向遇到的第一个node负责缓存它,通过这个方法,在新增node和删除node的时候,只会对顺时针方法遇到的一个node负责的空间造成影响,其余的空间都任然有效

虽然虚拟并不能百分百的解决缓存命中失效的问题,但把问题缩小化,这样影响面小,即使缓存失效,数据库也能承受起用户的负载,从而稳定过度
hash一致性的特性
平衡性(Balance)
平衡性也就是说负载均衡,是指客户端hash后的请求应该能够分散到不同的服务器上去,一致性hash可以做到每个服务器都进行处理请求,但是不能保证每个服务器处理的请求的数量大致相同
单调性(Monotonicity)
单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,应保证原有的请求可以被映射到原来的或者新的服务器中去,而不会被映射到原来的其他服务器上去
分散性(Spread)
分布式环境下,客户端请求时候可能不知道所有服务器的存在,可能只知道其中一部分服务器,在客户端看来他看到的部分服务器会形成一个完整的hash环,如果多个客户端都把部分服务器作为一个完整hash环,那么可能会导致,同一个用户的请求被路由到不同的服务器进行处理,这种情况显示是应该避免的,因为它不能保证同一个的请求落到同一个服务器,所谓分散性是指上述情况发生的严重程度,好的哈希算法应尽量避免尽量减低分散性,一致性hash具有很低的分散性
负载(Load)
负载问题实际上是从另一个角度看待分散性问题,既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的客户端映射为不同的内容,与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷
在分布式集群中,对及其的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能,如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原来的数据就无法找到了,这样严重的违反了单调性的原则
总结:平衡性:尽量分散,单调性:已经分配的数据不能换地方,负载和分散性都应该避免
数据倾斜
3个节点,可以看到n为key时会发生数据倾斜,而换成text就缓解很多
redis CRC16
name+I 43/29/27 38/26/35
text+I 29/34/36 28/35/36
CRC16hash 测试
package redis;
import java.util.ArrayList;
import java.util.List;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPoolConfig;
import redis.clients.jedis.JedisShardInfo;
import redis.clients.jedis.ShardedJedis;
import redis.clients.jedis.ShardedJedisPool;
public class Crc16Mod {
@Test
public void runCrc() {
for (int i = 1; i < 100; i++) {
System.out.println(this.getCrc(("name" + i).getBytes()) % 3);
}
}
private static Integer getCrc(byte[] data) {
int high;
int flag;
// 16位寄存器,所有数位均为1
int wcrc = 0xffff;
for (int i = 0; i < data.length; i++) {
// 16 位寄存器的高位字节
high = wcrc >> 8;
// 取被校验串的一个字节与 16 位寄存器的高位字节进行“异或”运算
wcrc = high ^ data[i];
for (int j = 0; j < 8; j++) {
flag = wcrc & 0x0001;
// 把这个 16 寄存器向右移一位
wcrc = wcrc >> 1;
// 若向右(标记位)移出的数位是 1,则生成多项式 1010 0000 0000 0001 和这个寄存器进行“异或”运算
if (flag == 1)
wcrc ^= 0xa001;
}
}
// return Integer.toHexString(wcrc);
return wcrc;
}
}
面试总结:
Redis 和 MemCache 的区别

缓存穿透:
缓存穿透,即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常
缓存穿透解决方案:
- 利用互斥锁,缓存失效的时候,失去获锁,得到锁了,再去请求数据库,没得到锁,则休眠一段时间重试
- 采用异步更新策略,无论key是否取到值,都直接返回,value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存,需要做缓存预热(项目启动前,先加载缓存)操作
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key,迅速判断出,请求所携带的key是否合法有效,如果不合法,则直接返回
缓存雪崩
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常
缓存雪崩解决方案
- 给缓存的失效时间,加上一个随机值,避免集群失效
- 使用互斥锁,但是该方案吞吐量明显下降
- 双缓存,我们有两个缓存,缓存A或缓存B,缓存A的失效时间为20分钟,缓存B不设定失效时间,自己做缓存预热操作
双缓存的实现过程: 从缓存A 读取数据库,有则直接返回,A 没有数据,直接从B读取数据,直接返回,并且异步启动一个更新线程,更新线程同时更新缓存A和缓存B
实战:
| 序号 | 知识点 | 类型 | 难度系数 | 掌握程度 |
| 1 | 缓存的作用 | 说明 | 1 | 熟练 |
| 2 | 什么是nosql和传统关系型数据库的差异 | 说明 | 1 | 熟练 |
| 3 | 同类缓存的比较,MemCache和Redis 区别 | 说明 | 1 | 熟练 |
| 4 | Linux CentOS下安装Redis | 代码 | 1 | 熟练 |
| 5 | Redis数据持久化的两种方式:RDB和AOF比较 | 说明 | 1 | 熟练 |
| 6 | Redis启动,常用命令 | 代码 | 1 | 熟练 |
| 7 | Redis高级中的hash结构 | 代码 | 1 | 会用 |
| 8 | Redis高级中的list结构 | 代码 | 1 | 会用 |
| 9 | Redis高级中的set结构 | 代码 | 1 | 会用 |
| 10 | Redis的事务管理 | 代码 | 3 | 熟练 |
| 11 | Redis的管道 | 代码 | 3 | 会用 |
| 12 | Redis的分片 | 代码 | 2 | 熟练 |
| 13 | Jedis 实现Spring整合Redis | 代码 | 1 | 熟练 |















 2012
2012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









